当前位置:网站首页>Research on multi model architecture of ads computing power chip
Research on multi model architecture of ads computing power chip
2022-07-01 16:00:00 【Advanced engineering intelligent vehicle】
author :Nathan J, Chief architect of Furui microelectronics UK R & D Center , Resident in Cambridge, England . I was in ARM The headquarters has been engaged in high performance for more than ten years CPU Architecture research and AI architecture research .
In the past decade , Deep neural network (DNN) It has been widely used , For example, mobile phones ,AR/VR,IoT And automatic driving . Complex use cases lead to many DNN The emergence of model application , for example VR The application of contains many subtasks : Avoid collision with nearby obstacles through target detection , Predict input through the tracking of opponents or gestures , Through the eye tracking to complete the center point rendering , These subtasks can use different DNN Model to complete . Like autonomous vehicle, it also uses a series of DNN Algorithm to realize the perception function , Every DNN To accomplish a specific task . But different DNN The network layer and operator of the model are also very different , Even in a DNN Heterogeneous operators and types may also be used in the model .
Besides ,Torch、TensorFlow and Caffe Wait for the mainstream deep learning framework , It is still handled in a sequential way inference Mission , One process per model . Therefore, it also leads to the current NPU Architecture is still focused on a single DNN Task acceleration and optimization , This is far from enough DNN Performance requirements of model application , There is an urgent need for new models at the bottom NPU Computing architecture accelerates and optimizes multi model tasks . And reconfigurable NPU Although it can adapt to the diversity of neural network layer , But additional hardware resources are needed to support ( For example, switching unit , Interconnection and control module ), It will also lead to additional power consumption caused by reconfiguration of the network layer .

Development NPU To support multitasking models faces many challenges :DNN The diversity of load is improved NPU The complexity of design ; Multiple DNN Linkage between , Lead to DNN Scheduling between becomes difficult ; How to balance reconfigurability and customization becomes more challenging . In addition, this kind of NPU Additional performance criteria are also introduced in the design : Because of multiple DNN Delay caused by data sharing between models , Multiple DNN How to allocate resources effectively between models .
The current direction of design research can be roughly divided into the following points : Multiple DNN Parallel execution between models , The redesign NPU Architecture to effectively support DNN Diversity of models , Optimization of scheduling strategy .

Edit search map
DNN Parallelism and scheduling strategy :
Parallel strategies such as time division multiplexing and spatial cooperative positioning can be used . Scheduling algorithm can be roughly divided into three directions : Static and dynamic scheduling , Scheduling for time and space , And scheduling based on software or hardware .
Time division multiplexing It is an upgraded version of the traditional priority preemption strategy , allow inter-DNN Assembly line operation , To improve the utilization of system resources (PE and memory etc. ). This strategy focuses on the optimization of scheduling algorithm , The advantage is to NPU There are few changes to the hardware .
Spatial collaborative positioning Focus on multiple DNN Parallelism of model execution , That's different DNN The model can occupy NPU Different parts of hardware resources . It requires design NPU Each stage should be predicted DNN Network characteristics and priorities , Take the predefined part NPU Hardware units are assigned to specific DNN Internet use . The assigned strategy can be selected DNN Dynamic allocation during operation , Or static allocation . Static allocation depends on the hardware scheduler , Less software intervention . The advantage of spatial collaborative positioning is that it can better improve the performance of the system , But the hardware changes are relatively large .
Dynamic scheduling and static scheduling Dynamic scheduling or static scheduling is selected according to the specific goals of user use cases .
Dynamic scheduling is more flexible , According to the reality DNN Reallocate resources according to the needs of the task . Dynamic scheduling mainly depends on time division multiplexing , Or use a dynamically composable engine ( You need to add a dynamic scheduler to your hardware ), Most algorithms choose preemptive Strategy or AI-MT Early expulsion algorithm of .
For customized static scheduling strategy , Can better improve NPU Performance of . This scheduling strategy refers to NPU At the design stage, specific hardware modules have been customized to deal with specific neural network layers or specific operations . This scheduling strategy has high performance , But the hardware changes are relatively large .
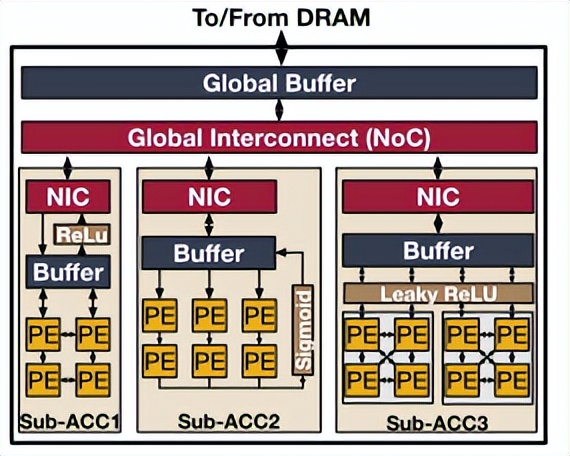
Edit search map
isomerism NPU framework :
Static scheduling strategy combining dynamic reconfiguration and customization , stay NPU Design multiple sub accelerators in , Each sub accelerator is targeted at a specific neural network layer or specific network operations . In this way, the scheduler can adapt to multiple DNN The network layer of the model runs on the appropriate sub accelerator , You can also schedule from different DNN The network layer of the model runs synchronously on multiple sub accelerators . This can not only save the additional hardware resource consumption brought by the reconfiguration architecture , It can also improve the flexibility of processing in different network layers .
isomerism NPU The research and design of architecture can be mainly considered from these three aspects :
1) How to design multi seed accelerator according to the characteristics of different network layers ;
2) How to distribute resources among different sub accelerators ;
3) How to schedule the specific network layer that meets the memory limit to execute on the appropriate sub accelerator .
reference :
[1] Stylianos I. Venieris, and etc.“Multi-DNN Accelerators for Next-Generation AI Systems”
https://arxiv.org/pdf/2205.09376.pdf
[2] Hyoukjun K. Liangzhen L and etc. “Heterogeneous Dataflow Accelerators for Multi-DNN- Workloads”
https://arxiv.org/abs/1909.07437
边栏推荐
- laravel的模型删除后动作
- Advanced cross platform application development (24): uni app realizes file download and saving
- ATSS:自动选择样本,消除Anchor based和Anchor free物体检测方法之间的差别
- Crypto Daily: Sun Yuchen proposed to solve global problems with digital technology on MC12
- 超视频时代,什么样的技术会成为底座?
- 【php毕业设计】基于php+mysql+apache的教材管理系统设计与实现(毕业论文+程序源码)——教材管理系统
- July 1, 2022 Daily: Google's new research: Minerva, using language models to solve quantitative reasoning problems
- Équipe tensflow: Nous ne sommes pas abandonnés
- 她就是那个「别人家的HR」|ONES 人物
- 【OpenCV 例程200篇】216. 绘制多段线和多边形
猜你喜欢

STM32F1与STM32CubeIDE编程实例-PWM驱动蜂鸣器生产旋律
Redis high availability principle
![[pyGame practice] do you think it's magical? Pac Man + cutting fruit combine to create a new game you haven't played! (source code attached)](/img/0a/c1a4b57b9729e0cf9de1feae9f8c19.png)
[pyGame practice] do you think it's magical? Pac Man + cutting fruit combine to create a new game you haven't played! (source code attached)
【Pygame实战】你说神奇不神奇?吃豆人+切水果结合出一款你没玩过的新游戏!(附源码)

There will be a gap bug when the search box and button are zoomed

Nuxt. JS data prefetching

综述 | 激光与视觉融合SLAM
【LeetCode】43. 字符串相乘

高端程序员上班摸鱼指南

如何写出好代码 - 防御式编程指南
随机推荐
2023 spring recruitment Internship - personal interview process and face-to-face experience sharing
2022 Moonriver global hacker song winning project list
Smart Party Building: faith through time and space | 7.1 dedication
揭秘慕思“智商税”:狂砸40亿搞营销,发明专利仅7项
Detailed explanation of stm32adc analog / digital conversion
[pyGame practice] do you think it's magical? Pac Man + cutting fruit combine to create a new game you haven't played! (source code attached)
Huawei issued hcsp-solution-5g security talent certification to help build 5g security talent ecosystem
ATSS:自动选择样本,消除Anchor based和Anchor free物体检测方法之间的差别
She is the "HR of others" | ones character
When ABAP screen switching, refresh the previous screen
Tanabata confession introduction: teach you to use your own profession to say love words, the success rate is 100%, I can only help you here ~ (programmer Series)
Nuxt.js数据预取
Pocket network supports moonbeam and Moonriver RPC layers
Redis high availability principle
Hardware development notes (9): basic process of hardware development, making a USB to RS232 module (8): create asm1117-3.3v package library and associate principle graphic devices
TensorFlow團隊:我們沒被拋弃
ATSs: automatically select samples to eliminate the difference between anchor based and anchor free object detection methods
你TM到底几点下班?!!!
Task.Run(), Task.Factory.StartNew() 和 New Task() 的行为不一致分析
【开源数据】基于虚拟现实场景的跨模态(磁共振、脑磁图、眼动)人类空间记忆研究开源数据集