当前位置:网站首页>json 数据展平pd.json_normalize
json 数据展平pd.json_normalize
2022-07-07 04:35:00 【欧晨eli】
pandas中有一个牛逼的内置功能叫 .json_normalize。
pandas的文档中提到:将半结构化JSON数据规范化为平面表。
def _json_normalize(
data: Union[Dict, List[Dict]],
record_path: Optional[Union[str, List]] = None,
meta: Optional[Union[str, List[Union[str, List[str]]]]] = None,
meta_prefix: Optional[str] = None,
record_prefix: Optional[str] = None,
errors: str = "raise",
sep: str = ".",
max_level: Optional[int] = None,
) -> "DataFrame":
"""
Normalize semi-structured JSON data into a flat table.
Parameters
----------
data : dict or list of dicts
Unserialized JSON objects.
record_path : str or list of str, default None
Path in each object to list of records. If not passed, data will be
assumed to be an array of records.
meta : list of paths (str or list of str), default None
Fields to use as metadata for each record in resulting table.
meta_prefix : str, default None
If True, prefix records with dotted (?) path, e.g. foo.bar.field if
meta is ['foo', 'bar'].
record_prefix : str, default None
If True, prefix records with dotted (?) path, e.g. foo.bar.field if
path to records is ['foo', 'bar'].
errors : {'raise', 'ignore'}, default 'raise'
Configures error handling.
* 'ignore' : will ignore KeyError if keys listed in meta are not
always present.
* 'raise' : will raise KeyError if keys listed in meta are not
always present.
sep : str, default '.'
Nested records will generate names separated by sep.
e.g., for sep='.', {'foo': {'bar': 0}} -> foo.bar.
max_level : int, default None
Max number of levels(depth of dict) to normalize.
if None, normalizes all levels.
.. versionadded:: 0.25.0
Returns
-------
frame : DataFrame
Normalize semi-structured JSON data into a flat table.
Examples
--------
>>> data = [{'id': 1, 'name': {'first': 'Coleen', 'last': 'Volk'}},
... {'name': {'given': 'Mose', 'family': 'Regner'}},
... {'id': 2, 'name': 'Faye Raker'}]
>>> pd.json_normalize(data)
id name.first name.last name.given name.family name
0 1.0 Coleen Volk NaN NaN NaN
1 NaN NaN NaN Mose Regner NaN
2 2.0 NaN NaN NaN NaN Faye Raker
>>> data = [{'id': 1,
... 'name': "Cole Volk",
... 'fitness': {'height': 130, 'weight': 60}},
... {'name': "Mose Reg",
... 'fitness': {'height': 130, 'weight': 60}},
... {'id': 2, 'name': 'Faye Raker',
... 'fitness': {'height': 130, 'weight': 60}}]
>>> pd.json_normalize(data, max_level=0)
id name fitness
0 1.0 Cole Volk {'height': 130, 'weight': 60}
1 NaN Mose Reg {'height': 130, 'weight': 60}
2 2.0 Faye Raker {'height': 130, 'weight': 60}
Normalizes nested data up to level 1.
>>> data = [{'id': 1,
... 'name': "Cole Volk",
... 'fitness': {'height': 130, 'weight': 60}},
... {'name': "Mose Reg",
... 'fitness': {'height': 130, 'weight': 60}},
... {'id': 2, 'name': 'Faye Raker',
... 'fitness': {'height': 130, 'weight': 60}}]
>>> pd.json_normalize(data, max_level=1)
id name fitness.height fitness.weight
0 1.0 Cole Volk 130 60
1 NaN Mose Reg 130 60
2 2.0 Faye Raker 130 60
>>> data = [{'state': 'Florida',
... 'shortname': 'FL',
... 'info': {'governor': 'Rick Scott'},
... 'counties': [{'name': 'Dade', 'population': 12345},
... {'name': 'Broward', 'population': 40000},
... {'name': 'Palm Beach', 'population': 60000}]},
... {'state': 'Ohio',
... 'shortname': 'OH',
... 'info': {'governor': 'John Kasich'},
... 'counties': [{'name': 'Summit', 'population': 1234},
... {'name': 'Cuyahoga', 'population': 1337}]}]
>>> result = pd.json_normalize(data, 'counties', ['state', 'shortname',
... ['info', 'governor']])
>>> result
name population state shortname info.governor
0 Dade 12345 Florida FL Rick Scott
1 Broward 40000 Florida FL Rick Scott
2 Palm Beach 60000 Florida FL Rick Scott
3 Summit 1234 Ohio OH John Kasich
4 Cuyahoga 1337 Ohio OH John Kasich
>>> data = {'A': [1, 2]}
>>> pd.json_normalize(data, 'A', record_prefix='Prefix.')
Prefix.0
0 1
1 2
Returns normalized data with columns prefixed with the given string.
"""
def _pull_field(
js: Dict[str, Any], spec: Union[List, str]
) -> Union[Scalar, Iterable]:
"""Internal function to pull field"""
result = js
if isinstance(spec, list):
for field in spec:
result = result[field]
else:
result = result[spec]
return result
def _pull_records(js: Dict[str, Any], spec: Union[List, str]) -> List:
"""
Internal function to pull field for records, and similar to
_pull_field, but require to return list. And will raise error
if has non iterable value.
"""
result = _pull_field(js, spec)
# GH 31507 GH 30145, GH 26284 if result is not list, raise TypeError if not
# null, otherwise return an empty list
if not isinstance(result, list):
if pd.isnull(result):
result = []
else:
raise TypeError(
f"{js} has non list value {result} for path {spec}. "
"Must be list or null."
)
return result
if isinstance(data, list) and not data:
return DataFrame()
# A bit of a hackjob
if isinstance(data, dict):
data = [data]
if record_path is None:
if any([isinstance(x, dict) for x in y.values()] for y in data):
# naive normalization, this is idempotent for flat records
# and potentially will inflate the data considerably for
# deeply nested structures:
# {VeryLong: { b: 1,c:2}} -> {VeryLong.b:1 ,VeryLong.c:@}
#
# TODO: handle record value which are lists, at least error
# reasonably
data = nested_to_record(data, sep=sep, max_level=max_level)
return DataFrame(data)
elif not isinstance(record_path, list):
record_path = [record_path]
if meta is None:
meta = []
elif not isinstance(meta, list):
meta = [meta]
_meta = [m if isinstance(m, list) else [m] for m in meta]
# Disastrously inefficient for now
records: List = []
lengths = []
meta_vals: DefaultDict = defaultdict(list)
meta_keys = [sep.join(val) for val in _meta]
def _recursive_extract(data, path, seen_meta, level=0):
if isinstance(data, dict):
data = [data]
if len(path) > 1:
for obj in data:
for val, key in zip(_meta, meta_keys):
if level + 1 == len(val):
seen_meta[key] = _pull_field(obj, val[-1])
_recursive_extract(obj[path[0]], path[1:], seen_meta, level=level + 1)
else:
for obj in data:
recs = _pull_records(obj, path[0])
recs = [
nested_to_record(r, sep=sep, max_level=max_level)
if isinstance(r, dict)
else r
for r in recs
]
# For repeating the metadata later
lengths.append(len(recs))
for val, key in zip(_meta, meta_keys):
if level + 1 > len(val):
meta_val = seen_meta[key]
else:
try:
meta_val = _pull_field(obj, val[level:])
except KeyError as e:
if errors == "ignore":
meta_val = np.nan
else:
raise KeyError(
"Try running with errors='ignore' as key "
f"{e} is not always present"
) from e
meta_vals[key].append(meta_val)
records.extend(recs)
_recursive_extract(data, record_path, {}, level=0)
result = DataFrame(records)
if record_prefix is not None:
result = result.rename(columns=lambda x: f"{record_prefix}{x}")
# Data types, a problem
for k, v in meta_vals.items():
if meta_prefix is not None:
k = meta_prefix + k
if k in result:
raise ValueError(
f"Conflicting metadata name {k}, need distinguishing prefix "
)
result[k] = np.array(v, dtype=object).repeat(lengths)
return result
json_normalize()函数参数讲解
| 参数名 | 解释 |
|---|---|
| data | 未解析的Json对象,也可以是Json列表对象 |
| record_path | 列表或字符串,如果Json对象中的嵌套列表未在此设置,则完成解析后会直接将其整个列表存储到一列中展示 |
| meta | Json对象中的键,存在多层数据时也可以进行嵌套标记 |
| meta_prefix | 键的前缀 |
| record_prefix | 嵌套列表的前缀 |
| errors | 错误信息,可设置为ignore,表示如果key不存在则忽略错误,也可设置为raise,表示如果key不存在则报错进行提示。默认值为raise |
| sep | 多层key之间的分隔符,默认值是.(一个点) |
| max_level | 解析Json对象的最大层级数,适用于有多层嵌套的Json对象 |
在进行代码演示前先导入相应依赖库,未安装pandas库的请自行安装(此代码在Jupyter Notebook环境中运行)。
from pandas import json_normalize
import pandas as pd
1. 解析一个最基本的Json
a. 解析一般Json对象
a_dict = {
'school': 'ABC primary school',
'location': 'London',
'ranking': 2
}
pd.json_normalize(a_dict)
输出结果为:

b. 解析一个Json对象列表
json_list = [
{'class': 'Year 1', 'student number': 20, 'room': 'Yellow'},
{'class': 'Year 2', 'student number': 25, 'room': 'Blue'}
]
pd.json_normalize(json_list)
输出结果为:

2. 解析一个带有多层数据的Json
a. 解析一个有多层数据的Json对象
json_obj = {
'school': 'ABC primary school',
'location': 'London',
'ranking': 2,
'info': {
'president': 'John Kasich',
'contacts': {
'email': {
'admission': '[email protected]',
'general': '[email protected]'
},
'tel': '123456789',
}
}
}
pd.json_normalize(json_obj)
输出结果为:
多层key之间使用点隔开,展示了所有的数据,这已经解析了3层,上述写法和pd.json_normalize(json_obj, max_level=3)等价。
如果设置max_level=1,则输出结果为下图所示,contacts部分的数据汇集成了一列
如果设置max_level=2,则输出结果为下图所示,contacts 下的email部分的数据汇集成了一列
b. 解析一个有多层数据的Json对象列表
json_list = [
{
'class': 'Year 1',
'student count': 20,
'room': 'Yellow',
'info': {
'teachers': {
'math': 'Rick Scott',
'physics': 'Elon Mask'
}
}
},
{
'class': 'Year 2',
'student count': 25,
'room': 'Blue',
'info': {
'teachers': {
'math': 'Alan Turing',
'physics': 'Albert Einstein'
}
}
}
]
pd.json_normalize(json_list)
输出结果为:

若分别将max_level设置为2和3,则输出结果应分别是什么?请自行尝试~
3. 解析一个带有嵌套列表的Json
json_obj = {
'school': 'ABC primary school',
'location': 'London',
'ranking': 2,
'info': {
'president': 'John Kasich',
'contacts': {
'email': {
'admission': '[email protected]',
'general': '[email protected]'
},
'tel': '123456789',
}
},
'students': [
{'name': 'Tom'},
{'name': 'James'},
{'name': 'Jacqueline'}
],
}
pd.json_normalize(json_obj)
此例中students键对应的值是一个列表,使用[]括起来。直接采用上述的方法进行解析,则得到的结果如下:

students部分的数据并未被成功解析,此时可以为record_path设置值即可,调用方式为pd.json_normalize(json_obj, record_path='students'),在此调用方式下,得到的结果只包含了name部分的数据。

若要增加其他字段的信息,则需为meta参数赋值,例如下述调用方式下,得到的结果如下:
pd.json_normalize(json_obj, record_path='students', meta=['school', 'location', ['info', 'contacts', 'tel'], ['info', 'contacts', 'email', 'general']])

4. 当Key不存在时如何忽略系统报错
data = [
{
'class': 'Year 1',
'student count': 20,
'room': 'Yellow',
'info': {
'teachers': {
'math': 'Rick Scott',
'physics': 'Elon Mask',
}
},
'students': [
{ 'name': 'Tom', 'sex': 'M' },
{ 'name': 'James', 'sex': 'M' },
]
},
{
'class': 'Year 2',
'student count': 25,
'room': 'Blue',
'info': {
'teachers': {
# no math teacher
'physics': 'Albert Einstein'
}
},
'students': [
{ 'name': 'Tony', 'sex': 'M' },
{ 'name': 'Jacqueline', 'sex': 'F' },
]
},
]
pd.json_normalize(
data,
record_path =['students'],
meta=['class', 'room', ['info', 'teachers', 'math']]
)
在class等于Year 2的Json对象中,teachers下的math键不存在,直接运行上述代码会报以下错误,提示math键并不总是存在,且给出了相应建议:Try running with errors='ignore'。

添加errors条件后,重新运行得出的结果如下图所示,没有math键的部分使用NaN进行了填补。
pd.json_normalize(
data,
record_path =['students'],
meta=['class', 'room', ['info', 'teachers', 'math']],
errors='ignore'
)

5. 使用sep参数为嵌套Json的Key设置分隔符
在2.a的案例中,可以注意到输出结果的具有多层key的数据列标题是采用.对多层key进行分隔的,可以为sep赋值以更改分隔符。
json_obj = {
'school': 'ABC primary school',
'location': 'London',
'ranking': 2,
'info': {
'president': 'John Kasich',
'contacts': {
'email': {
'admission': '[email protected]',
'general': '[email protected]'
},
'tel': '123456789',
}
}
}
pd.json_normalize(json_obj, sep='->')
输出结果为:

6. 为嵌套列表数据和元数据添加前缀
在3例的输出结果中,各列名均无前缀,例如name这一列不知是元数据解析得到的数据,还是通过student嵌套列表的的出的数据,因此为record_prefix和meta_prefix参数分别赋值,即可为输出结果添加相应前缀。
json_obj = {
'school': 'ABC primary school',
'location': 'London',
'ranking': 2,
'info': {
'president': 'John Kasich',
'contacts': {
'email': {
'admission': '[email protected]',
'general': '[email protected]'
},
'tel': '123456789',
}
},
'students': [
{'name': 'Tom'},
{'name': 'James'},
{'name': 'Jacqueline'}
],
}
pd.json_normalize(json_obj, record_path='students',
meta=['school', 'location', ['info', 'contacts', 'tel'], ['info', 'contacts', 'email', 'general']],
record_prefix='students->',
meta_prefix='meta->',
sep='->')
本例中,为嵌套列表数据添加students->前缀,为元数据添加meta->前缀,将嵌套key之间的分隔符修改为->,输出结果为:

7. 通过URL获取Json数据并进行解析
通过URL获取数据需要用到requests库,请自行安装相应库。
import requests
from pandas import json_normalize
# 通过天气API,获取深圳近7天的天气
url = 'https://tianqiapi.com/free/week'
# 传入url,并设定好相应的params
r = requests.get(url, params={"appid":"59257444", "appsecret":"uULlTGV9 ", 'city':'深圳'})
# 将获取到的值转换为json对象
result = r.json()
df = json_normalize(result, meta=['city', 'cityid', 'update_time'], record_path=['data'])
df
result的结果如下所示,其中data为一个嵌套列表:
{'cityid': '101280601',
'city': '深圳',
'update_time': '2021-08-09 06:39:49',
'data': [{'date': '2021-08-09',
'wea': '中雨转雷阵雨',
'wea_img': 'yu',
'tem_day': '32',
'tem_night': '26',
'win': '无持续风向',
'win_speed': '<3级'},
{'date': '2021-08-10',
'wea': '雷阵雨',
'wea_img': 'yu',
'tem_day': '32',
'tem_night': '27',
'win': '无持续风向',
'win_speed': '<3级'},
{'date': '2021-08-11',
'wea': '雷阵雨',
'wea_img': 'yu',
'tem_day': '31',
'tem_night': '27',
'win': '无持续风向',
'win_speed': '<3级'},
{'date': '2021-08-12',
'wea': '多云',
'wea_img': 'yun',
'tem_day': '33',
'tem_night': '27',
'win': '无持续风向',
'win_speed': '<3级'},
{'date': '2021-08-13',
'wea': '多云',
'wea_img': 'yun',
'tem_day': '33',
'tem_night': '27',
'win': '无持续风向',
'win_speed': '<3级'},
{'date': '2021-08-14',
'wea': '多云',
'wea_img': 'yun',
'tem_day': '32',
'tem_night': '27',
'win': '无持续风向',
'win_speed': '<3级'},
{'date': '2021-08-15',
'wea': '多云',
'wea_img': 'yun',
'tem_day': '32',
'tem_night': '27',
'win': '无持续风向',
'win_speed': '<3级'}]}
解析后的输出结果为:

8. 探究:解析带有多个嵌套列表的Json
当一个Json对象或对象列表中有超过一个嵌套列表时,record_path无法将所有的嵌套列表包含进去,因为它只能接收一个key值。此时,我们需要先根据多个嵌套列表的key将Json解析成多个DataFrame,再将这些DataFrame根据实际关联条件拼接起来,并去除重复值。
json_obj = {
'school': 'ABC primary school',
'location': 'shenzhen',
'ranking': 2,
'info': {
'president': 'John Kasich',
'contacts': {
'email': {
'admission': '[email protected]',
'general': '[email protected]'
},
'tel': '123456789',
}
},
'students': [
{'name': 'Tom'},
{'name': 'James'},
{'name': 'Jacqueline'}
],
# 添加university嵌套列表,加上students,该JSON对象中就有2个嵌套列表了
'university': [
{'university_name': 'HongKong university shenzhen'},
{'university_name': 'zhongshan university shenzhen'},
{'university_name': 'shenzhen university'}
],
}
# 尝试在record_path中写上两个嵌套列表的名字,即record_path = ['students', 'university],结果无济于事
# 于是决定分两次进行解析,分别将record_path设置成为university和students,最终将2个结果合并起来
df1 = pd.json_normalize(json_obj, record_path=['university'],
meta=['school', 'location', ['info', 'contacts', 'tel'],
['info', 'contacts', 'email', 'general']],
record_prefix='university->',
meta_prefix='meta->',
sep='->')
df2 = pd.json_normalize(json_obj, record_path=['students'],
meta=['school', 'location', ['info', 'contacts', 'tel'],
['info', 'contacts', 'email', 'general']],
record_prefix='students->',
meta_prefix='meta->',
sep='->')
# 将两个结果根据index关联起来并去除重复列
df1.merge(df2, how='left', left_index=True, right_index=True, suffixes=['->', '->']).T.drop_duplicates().T
输出结果为:

途中红框标出来的部分为Json对象中所对应的两个嵌套列表。
总结
json_normalize()方法异常强大,几乎涵盖了所有解析JSON的场景,涉及到一些更复杂场景时,可以给予已有的功能进行发散整合,例如8. 探究中遇到的问题一样。
拥有了这个强大的Json解析库,以后再也不怕遇到复杂的Json数据了!
参考:
边栏推荐
- Codeforces Global Round 19
- You Li takes you to talk about C language 6 (common keywords)
- 微博发布案例
- paddlepaddle 29 无模型定义代码下动态修改网络结构(relu变prelu,conv2d变conv3d,2d语义分割模型改为3d语义分割模型)
- [UTCTF2020]file header
- Shell 脚本的替换功能实现
- 【斯坦福计网CS144项目】Lab3: TCPSender
- PHP exports millions of data
- What is the difference between TCP and UDP?
- [2022 actf] Web Topic recurrence
猜你喜欢

Ansible
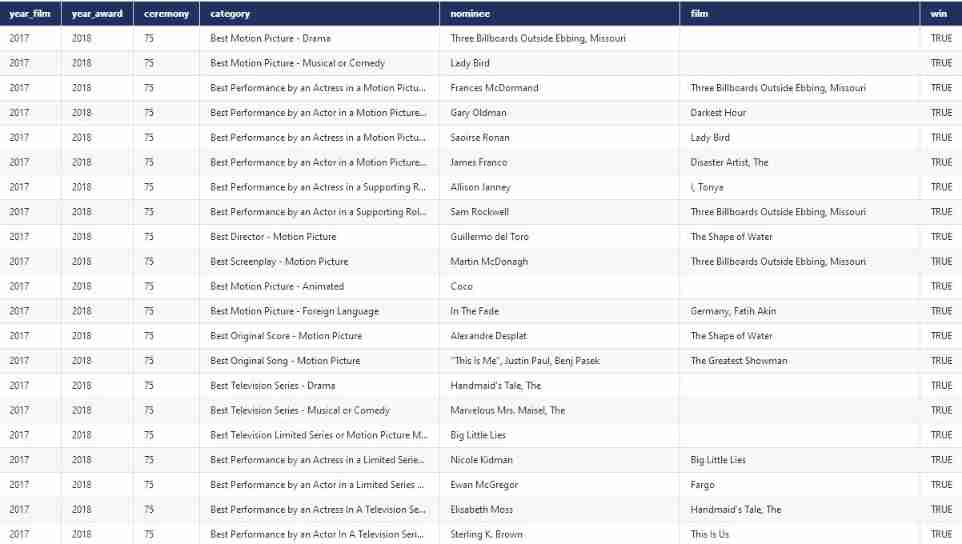
Cnopendata American Golden Globe Award winning data
![[unity] several ideas about circular motion of objects](/img/84/e70c6696629dbe17ace011553f43ff.png)
[unity] several ideas about circular motion of objects

KBU1510-ASEMI电源专用15A整流桥KBU1510

leetcode:105. 从前序与中序遍历序列构造二叉树

Jenkins remote build project timeout problem
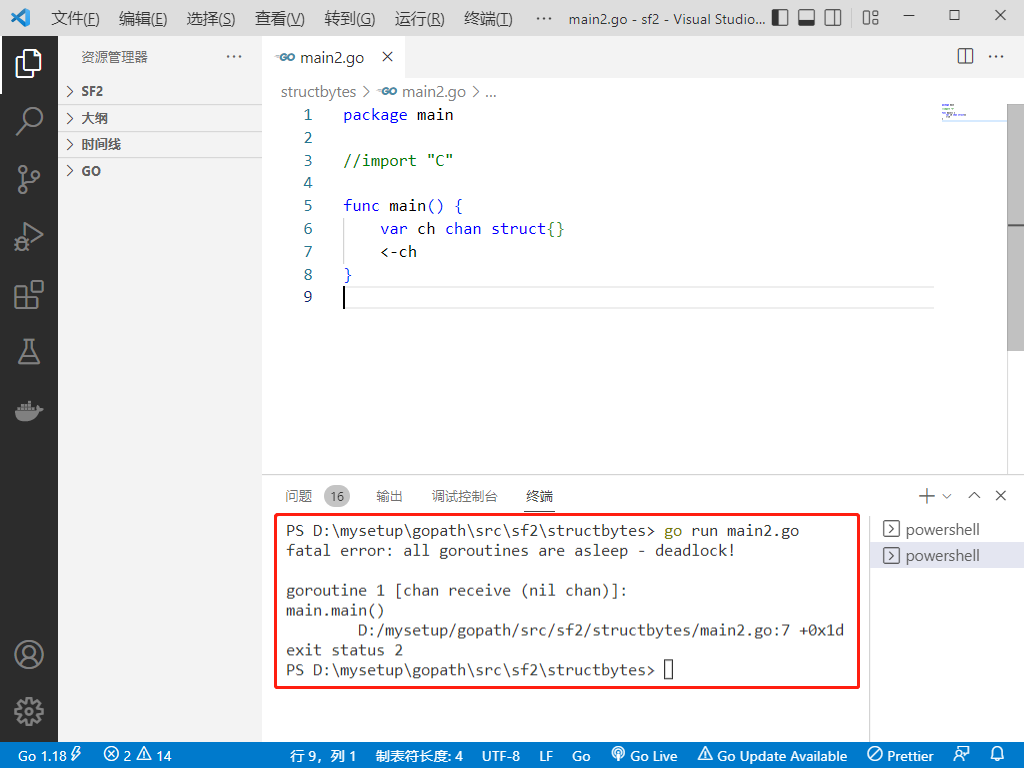
2022-07-06: will the following go language codes be panic? A: Meeting; B: No. package main import “C“ func main() { var ch chan struct

LeetCode 40:组合总和 II
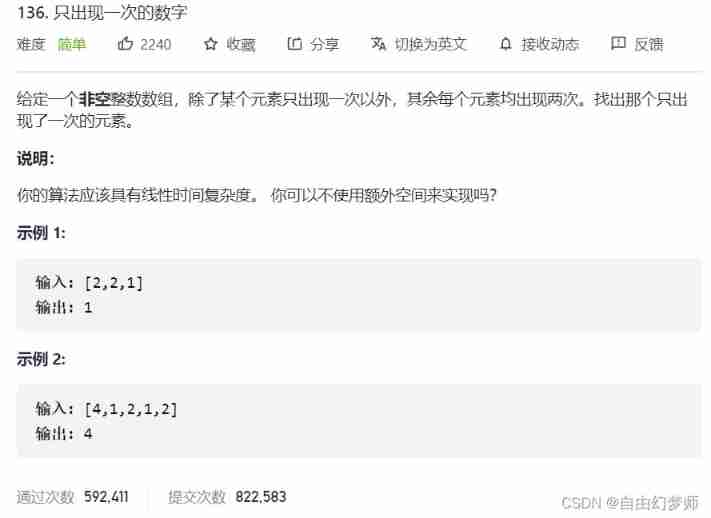
Numbers that appear only once
Is the test cycle compressed? Teach you 9 ways to deal with it
随机推荐
What is the difference between TCP and UDP?
buuctf misc USB
Zhilian + AV, AITO asked M7 to do more than ideal one
nacos
Button wizard script learning - about tmall grabbing red envelopes
直播平台源码,可折叠式菜单栏
[Stanford Jiwang cs144 project] lab3: tcpsender
[performance pressure test] how to do a good job of performance pressure test?
Idea add class annotation template and method template
What is the interval in gatk4??
gslx680触摸屏驱动源码码分析(gslX680.c)
[SUCTF 2019]Game
paddlepaddle 29 无模型定义代码下动态修改网络结构(relu变prelu,conv2d变conv3d,2d语义分割模型改为3d语义分割模型)
【VHDL 并行语句执行】
[UVM foundation] what is transaction
【Unity】物体做圆周运动的几个思路
在线直播系统源码,使用ValueAnimator实现view放大缩小动画效果
[2022 actf] Web Topic recurrence
探索干货篇!Apifox 建设思路
Live broadcast platform source code, foldable menu bar