当前位置:网站首页>scrapy爬虫框架
scrapy爬虫框架
2022-07-27 14:36:00 【fresh_nam】
前言
Scrapy是一个非常好用的爬虫框架,其异步处理特性使我们更快的获取想要的内容,现在就让我们使用它来爬取一些图片。
一、目标
我现在想要爬取一些图片,网上找了一下,决定爬取的网站为http://www.mmonly.cc/mmtp/,里面有很多好看的图片,爬取其主页上的所有图片。
二、使用步骤
1.下载scrapy
使用pip下载即可
pip install scrapy
2.创建项目
使用cmd进入你想创建爬虫的文件夹后,输入如下命令:
scrapy startproject scrapy_demo
就会在对应文件夹下创建一个名为scrapy_demo的文件夹,里面就是爬虫文件,使用pychram打开其目录结构如下:
然后cd命令进入爬虫文件夹,输入如下命令:
scrapy genspider MMspider www.mmonly.cc/mmtp/
其中MMspider是爬虫名,启动爬虫时要使用,后面的网站就是要爬取的网站。执行命令后会在spiders文件夹下生成一个名为MMspide的py文件,之后的爬虫逻辑都要写到里面,生成的域名要改下,修改后结果如下:
MMspider.py
# -*- coding: utf-8 -*-
import scrapy
class MmspiderSpider(scrapy.Spider):
name = 'MMspider' # 爬虫名
allowed_domains = ['mmonly.cc'] # 允许爬虫的域名
start_urls = ['http://www.mmonly.cc/mmtp//'] # 爬虫爬取信息的起始网页网址
def parse(self, response):
pass

2.分析网页结构
要爬取某一个网页,先要了解它的结构:

目标页面有很多个页面,每一个页面都有很多个写真集,每个写真集也会有多张图片,每个图片也是一页。所以要获取所有写真集图片,爬虫应该这样设计:在主页面获取所有写真集链接,再通过链接爬取每个写真集所有的图片,再判断主页面有没有下一页,如果有则继续爬取,直到爬取所有主页对应的写真页的所有图片为止。
3编写爬虫
首先再items.py里面定义要爬取的信息:
items.py
import scrapy
class ScrapyDemoItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
siteURL = scrapy.Field() # 图片网站地址
detailURL = scrapy.Field() # 图片原图地址
title = scrapy.Field() # 图片系列名称
fileName = scrapy.Field() # 图片存储全路径名称
path = scrapy.Field() # 图片系列存储路径
然后编写爬虫解析页面:
MMspider.py
import os
import scrapy
import datetime
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import Rule
from scrapy_demo.items import ScrapyDemoItem
#继承CrawlSpider
class MmspiderSpider(CrawlSpider):
name = 'MMspider' #爬虫名
base = r'D:\python抓取图片\MMspider\ ' # 定义图片存储路径
allowed_domains = ['mmonly.cc'] # 爬虫允许爬取信息的域名
start_urls = ['http://www.mmonly.cc/mmtp//']
# 定义主页面爬取规则,有下一页则继续深挖,其他符合条件的链接则调用parse_item解析原图地址
rules = (
Rule(LinkExtractor(allow=('https://www.mmonly.cc/(.*?).html'), restrict_xpaths=(u"//div[@class='ABox']")),
callback="parse_item", follow=False),
Rule(LinkExtractor(allow=(''), restrict_xpaths=(u"//a[contains(text(),'下一页')]")), follow=True),
)
def parse_item(self, response):
item = ScrapyDemoItem()
item['siteURL'] = response.url
item['title'] = response.xpath('//h1/text()').extract_first() # xpath解析标题
item['path'] = self.base + item['title'] # 定义存储路径,同一系列存储在同一目录
path = item['path']
if not os.path.exists(path):
os.makedirs(path) # 如果存储路径不存在则创建
item['detailURL'] = response.xpath('//a[@class="down-btn"]/@href').extract_first() # 解析原图URL
num = response.xpath('//span[@class="nowpage"]/text()').extract_first() # 解析同一系列图片编号
item['fileName'] = item['path'] + '/' + str(num) + '.jpg' # 拼接图片名称
print(datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S'), item['fileName'], u'解析成功!')
yield item
try:
# 判断当前页是否为最后一页,如果不是,则获取下一页
if num != total_page:
# 传入的解析item的链接如果有下一页的话,继续调用parse_item
next_page = response.xpath(u"//a[contains(text(),'下一页')]/@href").extract_first()
if next_page is not None:
next_page = response.urljoin(next_page)
yield scrapy.Request(next_page, callback=self.parse_item)
except:
pass
看到这一串代码是不是有点懵,没事,听我慢慢解释。
rule是我定义的爬虫规则,我定义了两条爬虫规则:第一条是从每个页面中所有class为’ABOX’的div标签中请求里面的满足’https://www.mmonly.cc/(.*?).html’正则表达式的链接,实现了获取每一页写真集链接的目的。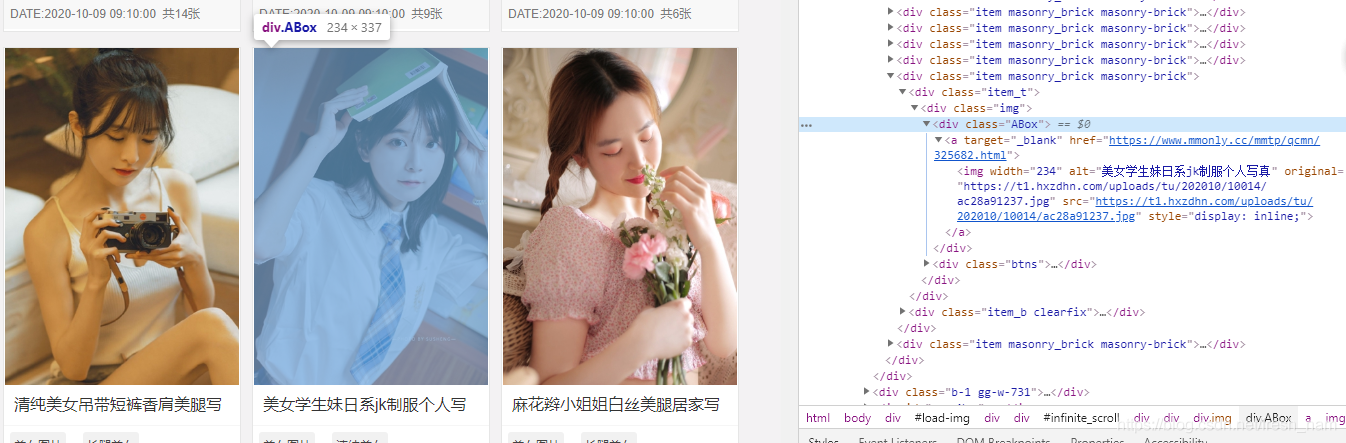
callback="parse_item"的意思是使用parse_item()函数去解析请求页面。
第二条规则是的作用是获取下一页的链接并请求,寻找页面的所有的a标签中对应的文本为下一页的a标签,请求其对应的链接,实现了下一页面的获取。
follow参数是一个布尔(boolean)值,指定了根据该规则从response提取的链接是否需要跟进。 如果callback 为空,follow 默认设置为True,否则默认为False。
Xpath是html的解析器,使用它可以快速定位html中的某个元素,例如response.xpath(’//a[@class=“down-btn”]/@href’).extract_first()就是获取所有class为down-btn的a标签对应的href里的内容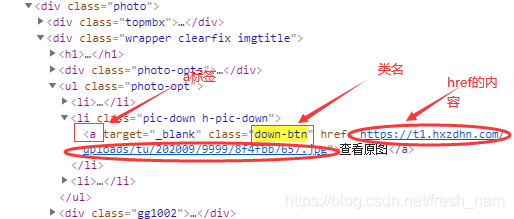
要下载图片的代码写在管道文件中。其中使用requests库请求图片链接并保存图片,先要下载requests:
pip install requests
代码如下:
pipelines.py
import requests
import datetime
class ScrapyDemoPipeline(object):
def process_item(self, item, spider):
detailURL = item['detailURL'] #获取图片链接
fileName = item['fileName'] #获取文件保存的完整路径
try:
print(datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S'), u'正在保存图片:', detailURL)
print(u'文件:', fileName)
image = requests.get(detailURL) # 根据解析出的item原图链接下载图片
f = open(fileName, 'wb') # 打开图片
f.write(image.content) # 写入图片
f.close()
print(datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S'), fileName, u'保存成功!')
except Exception:
print(fileName, 'other fault:', Exception)
return item
最后,还要再配置中打开管道文件:
settings.py
# Obey robots.txt rules
ROBOTSTXT_OBEY = False #True改成False
#去掉注释
ITEM_PIPELINES = {
'scrapy_demo.pipelines.ScrapyDemoPipeline': 300,
}
最后输入命令:
scrapy crawl MMspider
爬虫可以跑起来,大功告成!
图片也有保存:

总结
scrapy是个非常强大的框架,在这里我只是使用了其一部分的功能。其中我对代码做了些修改才能让爬虫启动,可能没有写在上面的步骤,如果有问题欢迎再评论区留言。
边栏推荐
- 台积电的反击:指控格芯侵犯25项专利,并要求禁售!
- [sword finger offer] interview question 45: arrange the array into the smallest number
- 折半插入排序
- [sword finger offer] interview question 39: numbers that appear more than half of the time in the array
- Spark 3.0 testing and use
- Division of entity classes (VO, do, dto)
- Go language slow start - package
- Under the ban, the Countermeasures of security giants Haikang and Dahua!
- 接连取消安富利/文晔/世平代理权,TI到底打的什么算盘?
- 网络设备硬核技术内幕 路由器篇 小结(下)
猜你喜欢

网络原理(2)——网络开发
![[sword finger offer] interview question 54: the k-largest node of the binary search tree](/img/13/7574af86926a228811503904464f3f.png)
[sword finger offer] interview question 54: the k-largest node of the binary search tree

数据表的约束以及设计、联合查询——8千字攻略+题目练习解答
![[sword finger offer] interview question 41: median in data flow - large and small heap implementation](/img/c3/7caf008b3bd4d32a00b74f2c508c65.png)
[sword finger offer] interview question 41: median in data flow - large and small heap implementation
C language: data storage
![[sword finger offer] interview question 50: the first character that appears only once - hash table lookup](/img/72/b35bdf9bde72423410e365e5b6c20e.png)
[sword finger offer] interview question 50: the first character that appears only once - hash table lookup

CAS compares the knowledge exchanged, ABA problems, and the process of lock upgrading

Three uses of static keyword

synchronized和ReentrantLock的区别

线程中死锁的成因及解决方案
随机推荐
C语言:动态内存函数
Learn parquet file format
C语言:自定义类型
[系统编程] 进程,线程问题总结
C:浅谈函数
语音直播系统——提升云存储安全性的必要手段
Static关键字的三种用法
CAS compares the knowledge exchanged, ABA problems, and the process of lock upgrading
leetcode25题:K 个一组翻转链表——链表困难题目详解
[tensorboard] oserror: [errno 22] invalid argument processing
接连取消安富利/文晔/世平代理权,TI到底打的什么算盘?
Inter thread wait and wake-up mechanism, singleton mode, blocking queue, timer
C语言:三子棋游戏
【云享读书会第13期】FFmpeg 查看媒体信息和处理音视频文件的常用方法
传美国政府将向部分美企发放对华为销售许可证!
台积电6纳米制程将于明年一季度进入试产
减小程序rom ram,gcc -ffunction-sections -fdata-sections -Wl,–gc-sections 参数详解
Spark RPC
[sword finger offer] interview question 46: translating numbers into strings - dynamic programming
Go language slow start - Basic built-in types