当前位置:网站首页>Autorf: learn the radiation field of 3D objects from single view (CVPR 2022)
Autorf: learn the radiation field of 3D objects from single view (CVPR 2022)
2022-06-24 13:51:00 【3D vision workshop】
Click on the above “3D Visual workshop ”, choice “ Star standard ”
The dry goods arrive at the first time

The author 丨 paopaoslam
Source Bubble robot SLAM
title : AutoRF: Learning 3D Object Radiance Fields from Single View Observations
author :Norman Muller, Andrea Simonelli, Lorenzo Porzi, Samuel Rota Bulo, Matthias Niener , Peter Kontschieder
source :CVPR2022
compile :cristin
to examine : zhh

Abstract

Hello everyone , Today's article for you NeRFReN: Neural Radiance Fields with Reflections.
We introduced AutoRF: A learning nerve 3D object A new method of representation , Each object in the training set is observed through only one view . This setup is similar to most existing multiple views that utilize the same object 、 The work of using explicit priors or requiring perfect annotation of pixels during training is in sharp contrast . To solve this challenging setup , We suggest learning a standardized 、 With Object Centered representation , Its embedded description and decomposition shape 、 Appearance and Pose. Each code provides information about Object The generality of 、 Compact information , This information is decoded into a new target view in one shot , Thus, a new view composition . We further improve the quality of reconstruction , By optimizing the shape and appearance code during the test , Fit the representation closely to the input image . In a series of experiments , We show that our method can be well extended to invisible objects , Even different datasets across challenging real-world street scenes , Such as nuScenes、KITTI and Mapillary metropolis.
Github: https://sirwyver.github.io/AutoRF/
Main work and contribution
in summary , Our main contributions and differences from existing work are :
1. We've introduced based on 3D New visual angle synthesis of object a priori , Only from a single perspective 、in-the-wild Learning from observation , The object may be blocked , There is great variability in scale , May be affected by the degradation of image quality . We do not use multiple views of the same object , And don't take advantage of large CAD model base , Or build a specific 、 Predefined shapes ;
2. We have successfully utilized the machine generated 3Dbox And panoramic segmentation mask , Thus, it provides incomplete annotations for learning implicit object representation , Novel view composition that can be applied to real-world data . Most previous works have shown experiments on synthetic data , Or require the object of interest to be non occluded , And the main content of the image ( except [13] utilize [11] A new mask );
3. Our method effectively encodes the shape and appearance properties of the object of interest , We can decode a new view in a single shot , And optionally further fine tune during testing . This makes it possible to correct potential domain shifts , And generalize on different data sets , This has not yet been confirmed .
Algorithm flow
1. problem
Given a single input image , Our goal is to integrate every existing in the scene 3D The object is encoded as a compact representation , for example , Allow objects to be effectively stored in the database , And later from different views / Recombine them in context . Although this problem in the past [15, 41] China has been solved , But when training such an encoder , We focus on more challenging scenarios . Contrary to most methods of training such encoders that assume access to at least a second view of the same object instance , We focus on solving more challenging settings , That is only Estimate the object from a single perspective 3D Model . Besides , No other prior knowledge about the geometry of the object is used ( for example CAD Model 、 Symmetry, etc ).
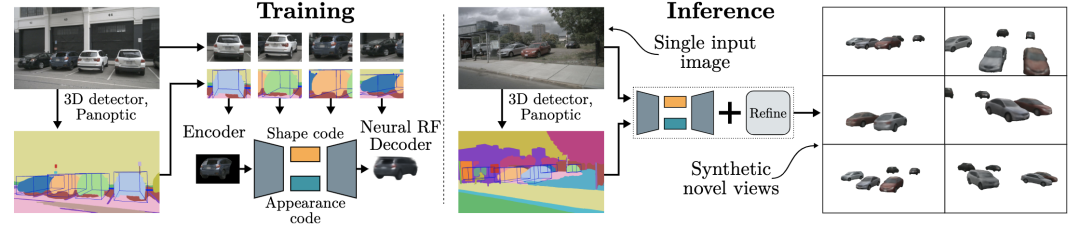
chart 1 AutoRF Overview . Our model consists of an encoder , The coder extracts shape and appearance codes from object images , It can be decoded as a hidden luminance field operating in the normalized object space , And used for new view composition . Through the use of machine generated three-dimensional object detection and panoramic segmentation , Generate object images from real world images .
2. Method
In order to be able to train the encoder in the above limited scenario , We take advantage of pre trained Instance or panoramic splitter The algorithm recognizes the objects belonging to the same object instance in the image 2D Pixels , And pre trained Monocular 3D Object detector , In order to obtain The object is in 3D A priori information of attitude in space . therefore , In training and testing , Let's assume that for each image we get a set of images with correlation 2D Masked 3D Bounding box , They represent detected object instances , And camera calibration information .
By making use of relevant objects 3D Bounding box information , We can separate the object representation from the actual object pose and scale . We got a standardized 、 Object centric coding , It is decomposed into a shape and an appearance component . Similar to condition NeRF Model , The shape code is used to adjust the occupied network , It outputs a given... In the normalized object space 3D The density of points , Skin code is used to adjust skin network , In the given 3D Point in case of RGB Color And normalizing the viewing direction in the object space . These two networks produce 3D An implicit representation of an object .
2.1 preparation
2.11 Images
Given there are multiple interiest Object's 2D Images , We run 3D Object detector and panoramic segmentation , To extract... For each object instance 3D Bounding box and instance mask ( See the picture 2). Bounding boxes and masks are used to generate masks for detected object instances 2D Images I, Suitable for fixed input resolution . Besides ,3D Bounding box captures the extent of an object in camera space 、 Position and rotation , The segmentation mask provides information about possible occlusion w.r.t Per pixel information of . Other objects in the scene . Images I Medium pixels u ∈ U Of RGB Color by Iu ∈ R3 Express , among U Represents its pixel set .
2.1.2 Normalization target 3D Coordinate space
Each object instance has an associated 3D Bounding box β, It recognizes a rectangular box in camera space , Describe the attitude and range of the related objects . Contained in a 3D bounding box β 3D points in can be mapped to by isomorphism ( center ) Unit cube O:=[−1,2]3 It is called normalized object coordinate space (NOCS). in fact , Every 3D Bounding boxes can be converted 、 Rotate and scale into a unit cube . In view of this fact , We will use it directly β To denote the above-mentioned abnormity , therefore , Map points from camera space to NOCS
2.1.3 The object is the center γ The camera
Each 3D scene image has a related camera , use ρ Express .ρ The camera will be pixels u∈u Mapped to... In camera space ρu: R+→R3, among ρu(t) given t Time along the ray 3D spot . By using the bounding box of a given object β, We can put each ρu Rays are mapped from camera space to NOCS, Produce a ray centered on an object γu. say concretely ,γu Is a unit velocity remapping ray β◦ρu. We put γ An object centric camera called a given object
2.1.4 Occupancy Mask Y
We use panoramic segmentation to generate an image with an object i The associated 2D Occupy the mask Y. Occupy the mask Y For each pixel u∈u Provides a class tag Yu∈{+ 1,0,1}. Foreground pixels , That is, the pixels belonging to the object instance mask , Assigned tags +1. Background pixels , That is, the pixels of the object of interest are not occluded , Assigned tags −1. Pixels that cannot be determined whether to occlude the object are assigned as labels 0. If a pixel belongs to a semantic category that should not be occluded , Then the pixel is assigned as the background label

chart 2 Given a with the corresponding 3D The object bounding box and the RGB Images , Our automatic coder learns to encode shapes and appearances in separate code . These codes enable each decoder to re render the input image for a given view .
2.2 Network structure
2.2.1 Input
Our architecture will have detected images of objects 、NOCS The corresponding camera in γ( By taking advantage of 3D The information of the bounding box is exported ) And using the occupancy mask obtained by panoramic segmentation as input ,
2.2.2 Shape and appearance encoder ΦE
We use neural networks ΦE The input image of a given object of interest will be described I Code as shape code φS And appearance code φA; namely (φS, φA):= ΦE(I). The encoder comprises CNN Feature extractor , The CNN Feature extractor outputs intermediate features , These intermediate features are fed into two parallel heads , Responsible for generating shape and appearance codes respectively . The implementation details of the encoder and decoder below can be found in the supplementary materials .
2.2.3 decoder ΨS shape
Put the shape code φS Into the decoder network ΨS, The decoder implicitly outputs the occupied network σ; namely σ:= ΨS(φS). Take up the network σ: O→R+ Output a given 3D spot x∈O The density of the , use NOCS Express .
2.2.4 Appearance decoder Ψ
Different from shape decoder , Appearance decoder ΨA Accept the input of shape code and appearance code at the same time , Implicit output appearance network ξ, namely ξ:= ΨA(φA, φS). Appearance network ξ ξ: O×S2→R3 For a given 3D spot x∈O Output RGB Color , And in the unit 3D sphere S2 Viewing direction on d Upper output .
2.2.5 Volume Renderer V
Placeholder network σ And the network of appearances ξ It forms a brightness field , On behalf of NOCS An object in . We can do that by using [26] To render object centered rays γu To calculate and u Related colors . However , Because we only model objects of interest , So the object centered light is limited to o At the point of intersection . This produces the following volume rendering formula :

2.3 Loss
To train our architecture , We rely on two loss items : Photometric loss and occupancy loss . Let's take a given training example Ω = (I, γ, Y) Provision loss , Include images I, Occupy the mask Y, Object centric camera γ. Besides , We assume that from I Encoder for departure ΦE And decoder ΨS and ΨA The radiance field of the object is calculated (σ, ξ). Last , We use it Θ Represent all learnable parameters involved in the architecture .
2.3.1 luminosity LRGB Loss

2.3.1 Occupancy rate LOCC Loss .

experimental result

chart 3 stay nuScenes After specially training our model on the test data , from nuScenes( On )、KITTI( in ) and Mapillary Metropolis( Next ) A new view of the complete scene is synthesized from a single unseen image of the . Please note that for different scales 、 Aspect ratio 、 High fidelity reconstruction results of image quality objects

chart 4 NuScenes Qualitative comparison of : A new perspective of single instance composite instance .

chart 5 And NerfingMVS[29] Qualitative comparison of depth estimation .NerfingMVS It fails in such a scene with severe reflection , Behave like NeRF.
chart 6 stay SRN-Cars Qualitative comparison on data sets , contrast 2 View pixelNeRF The baseline , It shows our high fidelity 、 Single view reconstruction results .

chart 7 An example of scenario editing is in nuScenes. Start with the input view , We can change the code of the object , Compose a new scene layout .
Click on Read the original , You can get a link to download this article .
This article is only for academic sharing , If there is any infringement , Please contact to delete .
3D Visual workshop boutique course official website :3dcver.com
1. Multi sensor data fusion technology for automatic driving field
2. For the field of automatic driving 3D Whole stack learning route of point cloud target detection !( Single mode + Multimodal / data + Code )
3. Thoroughly understand the visual three-dimensional reconstruction : Principle analysis 、 Code explanation 、 Optimization and improvement
4. China's first point cloud processing course for industrial practice
5. laser - Vision -IMU-GPS The fusion SLAM Algorithm sorting and code explanation
6. Thoroughly understand the vision - inertia SLAM: be based on VINS-Fusion The class officially started
7. Thoroughly understand based on LOAM Framework of the 3D laser SLAM: Source code analysis to algorithm optimization
8. Thorough analysis of indoor 、 Outdoor laser SLAM Key algorithm principle 、 Code and actual combat (cartographer+LOAM +LIO-SAM)
10. Monocular depth estimation method : Algorithm sorting and code implementation
11. Deployment of deep learning model in autopilot
12. Camera model and calibration ( Monocular + Binocular + fisheye )
13. blockbuster ! Four rotor aircraft : Algorithm and practice
14.ROS2 From entry to mastery : Theory and practice
15. The first one in China 3D Defect detection tutorial : theory 、 Source code and actual combat
blockbuster !3DCVer- Academic paper writing contribution Communication group Established
Scan the code to add a little assistant wechat , can Apply to join 3D Visual workshop - Academic paper writing and contribution WeChat ac group , The purpose is to communicate with each other 、 Top issue 、SCI、EI And so on .
meanwhile You can also apply to join our subdivided direction communication group , At present, there are mainly 3D Vision 、CV& Deep learning 、SLAM、 Three dimensional reconstruction 、 Point cloud post processing 、 Autopilot 、 Multi-sensor fusion 、CV introduction 、 Three dimensional measurement 、VR/AR、3D Face recognition 、 Medical imaging 、 defect detection 、 Pedestrian recognition 、 Target tracking 、 Visual products landing 、 The visual contest 、 License plate recognition 、 Hardware selection 、 Academic exchange 、 Job exchange 、ORB-SLAM Series source code exchange 、 Depth estimation Wait for wechat group .
Be sure to note : Research direction + School / company + nickname , for example :”3D Vision + Shanghai Jiaotong University + quietly “. Please note... According to the format , Can be quickly passed and invited into the group . Original contribution Please also contact .

▲ Long press and add wechat group or contribute
▲ The official account of long click attention
3D Vision goes from entry to mastery of knowledge : in the light of 3D In the field of vision Video Course cheng ( 3D reconstruction series 、 3D point cloud series 、 Structured light series 、 Hand eye calibration 、 Camera calibration 、 laser / Vision SLAM、 Automatically Driving, etc )、 Summary of knowledge points 、 Introduction advanced learning route 、 newest paper Share 、 Question answer Carry out deep cultivation in five aspects , There are also algorithm engineers from various large factories to provide technical guidance . meanwhile , The planet will be jointly released by well-known enterprises 3D Vision related algorithm development positions and project docking information , Create a set of technology and employment as one of the iron fans gathering area , near 4000 Planet members create better AI The world is making progress together , Knowledge planet portal :
Study 3D Visual core technology , Scan to see the introduction ,3 Unconditional refund within days
There are high quality tutorial materials in the circle 、 Answer questions and solve doubts 、 Help you solve problems efficiently
Feel useful , Please give me a compliment ~
边栏推荐
- The first open source MySQL HTAP database in China will be released soon, and the three highlights will be notified in advance
- 一个团队可以既做项目又做产品吗?
- Kotlin asynchronous flow
- Activity lifecycle
- 黄楚平主持召开定点联系珠海工作视频会议 坚决落实省委部署要求 确保防疫情、稳经济、保安全取得积极成效
- Google Earth Engine——1999-2019年墨累全球潮汐湿地变化 v1 数据集
- Talk about GC of JVM
- PM should also learn to reflect every day
- kotlin 数组、集合和 Map 的使用
- kotlin 组合挂起函数
猜你喜欢

黄金年代入场券之《Web3.0安全手册》

The research on the report "market insight into China's database security capabilities, 2022" was officially launched

数据科学家面临的七大挑战及解决方法

知识经济时代,教会你做好知识管理

【R语言数据科学】(十四):随机变量和基本统计量

Gatling performance test

常识知识点

【5G NR】5G NR系统架构

Tupu software is the digital twin of offshore wind power, striving to be the first
Hands on data analysis unit 3 model building and evaluation
随机推荐
Evolution of the message module of the play live series (3)
kotlin 共享可变状态和并发性
华为 PC 逆势增长,产品力决定一切
[one picture series] one picture to understand Tencent Qianfan ipaas
万用表的使用方法
Troubleshooting the kubernetes problem: deleting the rancher's namespace by mistake causes the node to be emptied
CPU status information us, sy and other meanings
kotlin 组合挂起函数
Redis面试题
位于相同的分布式端口组但不同主机上的虚拟机无法互相通信
Home office should be more efficient - automated office perfectly improves fishing time | community essay solicitation
Yyds dry goods counting solution sword finger offer: adjust the array order so that odd numbers precede even numbers (2)
Liux command
2022 coal mine gas drainage operation certificate examination questions and simulation examination
Tupu software is the digital twin of offshore wind power, striving to be the first
Why does the kubernetes environment require that bridge NF call iptables be enabled?
Opengauss kernel: simple query execution
kotlin 关键字 扩展函数
In the era of knowledge economy, it will teach you to do well in knowledge management
[R language data science] (XIV): random variables and basic statistics