当前位置:网站首页>Troubleshooting ideas that can solve 80% of faults
Troubleshooting ideas that can solve 80% of faults
2022-07-02 18:27:00 【androidstarjack】
Click on the top “ Terminal R & D department ”
Set to “ Star standard ”, Master more database knowledge with you Explaining the event 、 Before troubleshooting , Let's start with a fault scenario ( Take the call center system as an example ):
The business personnel reported that the call center system was running slowly , Part of the phones in the self-service language link system processing timeout , Traffic transfer to manual seat , There is a wire burst in the manual seat .
The operation and maintenance personnel are busy , Check resource usage 、 Check whether the service is normal 、 Check whether the log reports an error 、 Check whether the trading volume still has …… Time is unconsciously typing on the keyboard 、 Tap the keyboard 、 Hit the keyboard , But the reason has not been located .
The manager came to know the situation :“ Has the system recovered ?”、“ What is the effect of the failure ?”、“ Is the transaction interrupted ?”……
The operation and maintenance personnel quickly hit the keyboard , Write SQL, Look at the trading volume ; Tap the keyboard , Write orders , Look at system resources 、 situation ……
Final , The problem is located because one of the functions does not control the number of returns , Causing a memory leak .
For this fault , The business hopes that the operation and maintenance can solve the fault recovery faster , The manager wants to develop and optimize the call center fault handling process , I did the following things :
Time of priority fault handling process :” Work that can be done with the mouse , Don't use the keyboard “
Find the fault in advance , Strengthen monitoring :“ Technology finds problems before business , Monitoring is more than just an alarm , Also assist in fault location ”
Improve the fault emergency plan :“ The emergency plan is up-to-date 、 accurate 、 Simple and clear ”
Long term goals : Fault self healing :“ Operation automation that can cure , Let the machine do what the machine can do ”
The following will start with the common troubleshooting methods , Then start from the preparation before the fault ( Perfect monitoring 、 Formulate emergency plans, etc ) To solve the problems raised by the manager , And put forward the idea of solving the fault in the future .
One 、 Common methods
1、 Determine the fault phenomenon and preliminarily determine the influence of the problem
Before dealing with the fault , The operation and maintenance personnel should first know the fault phenomenon , The fault phenomenon directly determines the formulation of fault emergency plan , This depends on the fact that the operation and maintenance personnel need to be familiar with the overall function of the application system .
After confirming the fault phenomenon , To guide the operation and maintenance personnel to initially judge the impact of the fault .
2、 Emergency recovery
The most basic indicator of operation and maintenance is system availability , The timeliness of emergency recovery is the key index of system availability .
With the judgment of the above fault phenomena and effects , The emergency operation plan can be formulated , There are a lot of fault emergency , such as :
The overall service performance is degraded or abnormal , Consider restarting the service ;
The application has changed , You can consider whether you need to change back ;
Insufficient resources , Emergency expansion can be considered ;
Application performance problems , You can consider adjusting the application parameters 、 Log parameters ;
Database busy , Consider database snapshot analysis , Optimize SQL;
Error in application function design , Consider the emergency shutdown function menu ;
There are still a lot of it ……
in addition , What needs to be added is , Before failure emergency , If conditions permit, you need to save the current system scenario , For example, before killing the process , You can catch one first CORE File or database snapshot file .
3、 Quickly locate the cause of the fault
1) Whether it is accidental 、 Is it reproducible
Whether the fault phenomenon can be reproduced , It's important to solve problems quickly , Can reproduce that there will always be ways or tools to help us locate the cause of the problem , Moreover, the faults that can be reproduced may often be service exceptions 、 Problems caused by changes and other work .
But if the fault is accidental , There is a very small probability , It is more difficult to check , This depends on whether the system has enough on-site information during the failure to determine whether the cause can always be located .
Whether relevant changes have been made .
Most failures are caused by changes , After determining the fault phenomenon , If there are changes that should be made , It is helpful to analyze whether it is caused by change from the perspective of change , Then quickly locate the fault and prepare emergency plans such as failback .
2) Whether relevant changes have been made
Most failures are caused by changes , After determining the fault phenomenon , If there are changes that should be made , It is helpful to analyze whether it is caused by change from the perspective of change , Then quickly locate the fault and prepare emergency plans such as failback .
3) Whether the scope can be reduced
On the one hand, the application system advocates decoupling , A trade fair flows through different application systems and modules ; On the other hand , The failure may be due to the application 、 Systems software 、 Hardware 、 Problems in network and other links . Comprehensive troubleshooting should be avoided when troubleshooting the causes of faults , It is suggested to narrow down the scope of the problem to a certain procedure before coordinating the related team for troubleshooting .
Related parties cooperate to analyze problems
With the first (3) At the same time, it is necessary to avoid that all related teams have no clue at the same time , The leader needs to be open to ask related parties to cooperate in positioning after narrowing the scope , For related parties, they need to have a positive working attitude .
4) Are there enough logs
Locating fault cause , The most common method is to analyze the application log , The operation and maintenance personnel not only need to know which service process the business function corresponds to , You also need to know which application logs correspond to this service process , It also has the ability to judge some simple application log abnormal errors .
5) Is there a core or dump Wait for the documents
The system site during failure is very important , It is suggested to leave the documents of the system site if possible before the failure emergency , such as CORE\DUMP, or TRACE Collect information, etc , Back up some logs that may be overwritten .
The above are common methods for general faults , In case of major failure or failure handled by multiple parties , Often, small-scale troubleshooting is not conducive to rapid resolution , The process of emergency treatment needs to be started , It is suggested to consider the following communication :
Gather relevant personnel
Describe the fault status
Explain the normal application logic flow
State changes
Investigation progress , Display information
Leading decision-making
Two 、 Perfect monitoring
1、 Improve the monitoring and visualization
A perfect monitoring strategy needs a unified visual operation interface , After formulating a sound monitoring strategy , Fault handling personnel need to be able to quickly see the corresponding operation data , such as : Can see the trend over time 、 Data performance during failure 、 Performance analysis and other data , And these data can formulate strategies in advance and directly launch the analysis results to the fault handling personnel , This greatly improves the fault processing efficiency , Take the call center system as an example , The following real-time transaction data should be configured in advance , For fault location :
Transaction performance data : Average transaction time 、 The transaction time of the internal module of the system is long (IVR The transaction takes 、 Interface bus transactions take time )、 Related system transactions take time ( Core transactions take time 、 Transaction time of work order system, etc )
Important transaction indicator data : Trading volume 、IVR Trading volume 、 Traffic 、 Seat call rate 、 Number of core transactions 、 Transaction volume of work order and other systems
Transaction exception data : Deal success rate 、 Failure rate 、 The maximum number of error codes is
Analyze transaction data by server : Press server Count the number of transactions processed by each service , The transaction always takes time
With the above transaction data , And make statistics according to a certain frequency through monitoring , Operation and maintenance personnel in case of failure , You can see when the fault starts by clicking the mouse , Is there a problem in the system or in the associated system , Which is the most prominent deal , Whether the transaction volume of each server is balanced .
2、 Improve from the aspect of monitoring
The most basic work of monitoring is to realize the load balancing equipment 、 Network devices 、 The server 、 The storage device 、 Safety equipment 、 database 、 Middleware and application software, etc IT Comprehensive monitoring and management of resources . In the monitoring of application software , Not just a service process 、 Port monitoring , There needs to be business 、 Monitoring at the transaction level .
Comprehensive application monitoring can give early warning of faults , And save the data affecting the application running environment , To shorten the troubleshooting time .
3、 Improve from monitoring alarm
A perfect monitoring strategy requires clear monitoring alarm prompt , The personnel on duty can make a simple problem location and emergency treatment plan according to the monitoring alarm . For example, the following monitoring SMS :
22 when ,【 Financial management application system 】 in 【 application server LC_APPsvrA 10.2.111.111】 Of 【 Front application module 】 appear 【 Application port :9080】 non-existent , This port is used for 【 Provide financial application processing ( Load balancing deployment )】, The reason may be 【SERVER1 Service stopped abnormally 】, The monitoring system has carried out the following emergency treatment 【 Auto execute port process startup 】, The urgency of the incident 【 high 】.
The administrator can see which system through the SMS content 、 Which application 、 What's wrong with which module , What might be the reason , What's the impact on the business , Whether it needs to be handled immediately ( For example, if this alert appears in the early morning, can it be delayed to the next day ) Etc .
4、 Improve from monitoring and analysis
A perfect monitoring strategy not only needs real-time data alarm , There should also be an analysis alarm for summarizing data , The importance of alarms for real-time data analysis goes without saying , For the data collected and analyzed, potential risks can be found , At the same time, it also provides help for the analysis of difficult and miscellaneous diseases .
5、 Improve the monitoring initiative
Monitoring is more than just an alarm , It can do more , As long as we find a way to give it the rules to actively solve events , It has the ability to handle faults for Administrators .
3、 ... and 、 Emergency plan
It is necessary to make a fault emergency plan in advance , But in the process of daily work, our emergency plan encounters some problems :
The emergency plan lacks continuous maintenance , Lack of drills , Information is not timely 、 inaccurate ;
The emergency plan is too big and comprehensive , It is not conducive to reading and using ;
The form of emergency plan is greater than the actual effect , The program is not targeted ;
Focus only on the content of the emergency plan , But they didn't pay attention to the understanding of the operation and maintenance personnel on the scheme ;
For the above common problems , The emergency plan needs to do the following :
1、 The content is concise
Many people may think that there are various forms of failure , Therefore, the emergency plan needs to involve all aspects . But in the actual fault handling process , We can find that our emergency measures often reuse several common steps , So I think the emergency plan should be focused , If an emergency plan can deal with ordinary faults 80% Scene , Then this emergency manual should be qualified . Too much pursuit of content that affects all aspects of the application system , This will lead to poor readability of the scheme , Finally change a document to be checked . The following is what I think the application system emergency plan should have :
1) The system level
Know the role of the current application system in the whole transaction , When there are problems in the current system or problems in the upstream and downstream , You can know how to cooperate with upstream and downstream analysis of problems , such as : How the upstream and downstream systems communicate , Whether the communication has a unique keyword, etc .
in addition , Some basic emergency operations are also involved at the system level , Such as capacity 、 System and network parameter adjustment, etc .
2) Service level
Can know what business this service affects , Logs involved in the service 、 Program 、 Where is the configuration file , How to check whether the service is normal , How to restart the service , How to adjust application level parameters, etc .
3) Transaction level
Can know how to find out that there is a problem with a certain transaction or a certain type of transaction , It's a large area 、 Local , Or an occasional problem , Data can be used to illustrate the impact of transactions , Can locate the information of transaction error report . The most commonly used method here is database query or the use of tools .
Know how to check whether the most important transaction is normal , Emergency response plan for important scheduled tasks , For example, opening 、 Change day 、 Time requirements for reconciliation and emergency measures .
4) Use of auxiliary tools
occasionally , Some tools or automated tools are needed to assist in analysis and emergency response , At this time, we need to have the method of how to use auxiliary tools .
5) Communication plan
Address book involved in communication scheme , Including upstream and downstream systems 、 Third party units 、 Business departments and other channels .
6) Other
Above 5 How complete the content is , I believe this emergency manual can solve 80% Fault recovery work .
2、 Emergency plan is an ongoing work
With an emergency plan , How to make the operation and maintenance personnel update continuously is the difficulty . I think we should solve this difficulty , The operation and maintenance personnel need to use this manual frequently first . If a manual has no scenes to use , Then managers need to create opportunities for operation and maintenance personnel to use this manual , Such as emergency drill .
3、 Pay attention to the understanding of operation and maintenance personnel on key application information
The first two points focus on the manual , Finally, I think it is necessary to pay attention to the people who use this manual . Some operation and maintenance personnel think that the application operation and maintenance personnel do not have the ability to understand the content of the application system itself very thoroughly , Therefore, the position of application operation and maintenance personnel in the process of fault handling is very embarrassing , The operation and maintenance personnel have the right to operate , But I don't know what to do .
Regarding this , I agree that application operation and maintenance personnel do not need to master the business functions of the application system , But I think for the application system itself, the application operation and maintenance personnel need to have the following basic abilities :
Know what the application system does , What is the basic business ;
Know the application architecture deployment 、 Logical relationship between upstream and downstream systems ;
Know the role of services under the application 、 port 、 Service level emergency treatment , How to find and simply locate data information such as logs ;
Know the important time points and tasks of the application system , For example, opening 、 Shut down 、 Change day 、 The time point of scheduled tasks and how to judge whether these tasks are correct ;
Know the process of the most important transactions ;
Know the common database table structure , And can use .
Four 、 Intelligent event processing
The processing method is shown in the figure below ( Detailed intellectualization involves monitoring 、 Rules engine 、 Configuration tool 、CMDB、 Application configuration library and other modules work together ).

Author programmer interview
Source: Website :https://blog.csdn.net/Dou_Hua_Hua/article/details/108829245
Write it at the end
You can leave a message below to discuss what you don't understand , You can also ask me by private message. I will reply after seeing it . Finally, if the article is helpful to you, please remember to give me a like , Pay attention and don't get lost
@ Terminal R & D department
Fresh dry goods are shared every day !
reply 【idea Activate 】 You can get idea How to activate
reply 【Java】 obtain java Relevant video tutorials and materials
reply 【SpringCloud】 obtain SpringCloud Many relevant learning materials
reply 【python】 Get the full set 0 Basics Python Knowledge Manual
reply 【2020】 obtain 2020java Related interview questions tutorial
reply 【 Add group 】 You can join the technical exchange group related to the terminal R & D department
Read more
use Spring Of BeanUtils front , I suggest you understand these pits first !
lazy-mock , A lazy tool for generating backend simulation data
In Huawei Hongmeng OS Try some fresh food , My first one “hello world”, take off !
The byte is bouncing :i++ Is it thread safe ?
One SQL Accidents caused by , Colleagues are fired directly !!
Too much ! Check Alibaba cloud ECS Of CPU Incredibly reach 100%
a vue Write powerful swagger-ui, A little show ( Open source address attached )
Believe in yourself , Nothing is impossible , Only unexpected, not only technology is obtained here !
If you like, just give me “ Looking at ”边栏推荐
- Graduation summary
- 微信小程序视频分享平台系统毕业设计毕设(3)后台功能
- Detailed explanation of map set
- In Linux, MySQL sets the job task to start automatically
- Wechat applet video sharing platform system graduation design (2) applet function
- Chrome 正式支持 MathML,默认在 Chromium Dev 105 中启用
- Iframe nesting details
- Unity学习shader笔记[八十一]简单的颜色调整后处理(亮度,饱和度,对比度)
- pycharm 修改 pep8 E501 line too long > 0 characters
- [games101] operation 4 B é zier curve
猜你喜欢
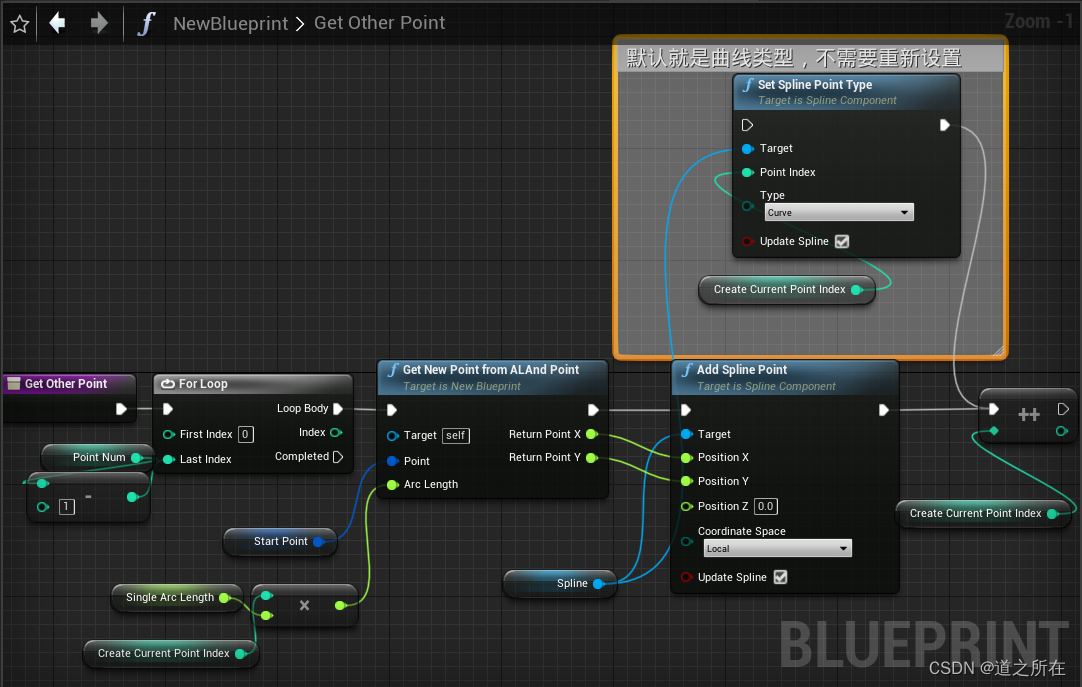
UE4 用spline画正圆
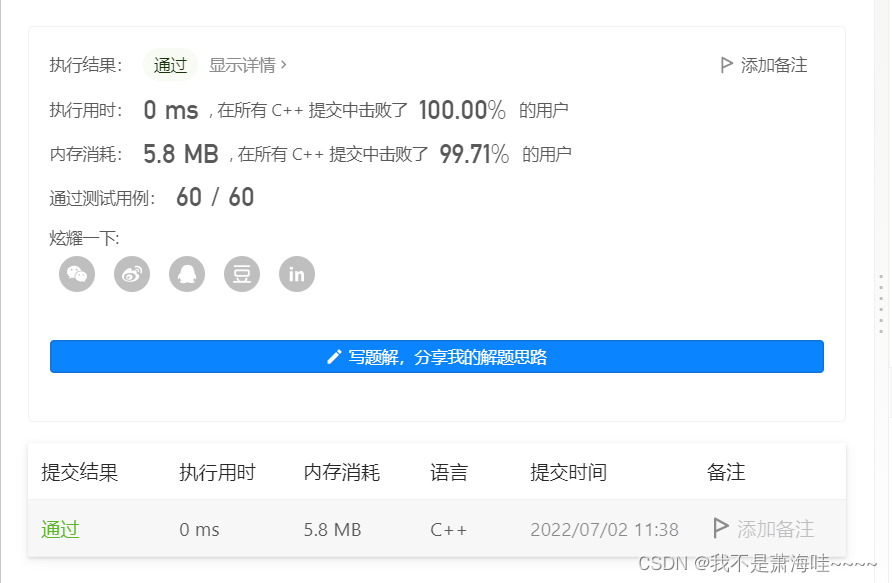
Leetcode 面试题 16.15. 珠玑妙算

Relax again! These fresh students can settle directly in Shanghai

27:第三章:开发通行证服务:10:【注册/登录】接口:注册/登录OK后,把用户会话信息(uid,utoken)保存到redis和cookie中;(一个主要的点:设置cookie)
Wechat applet video sharing platform system graduation design (3) background function

微信小程序视频分享平台系统毕业设计毕设(2)小程序功能
Wechat applet video sharing platform system graduation design (2) applet function
Ue4 dessine un cercle avec une ligne de contour
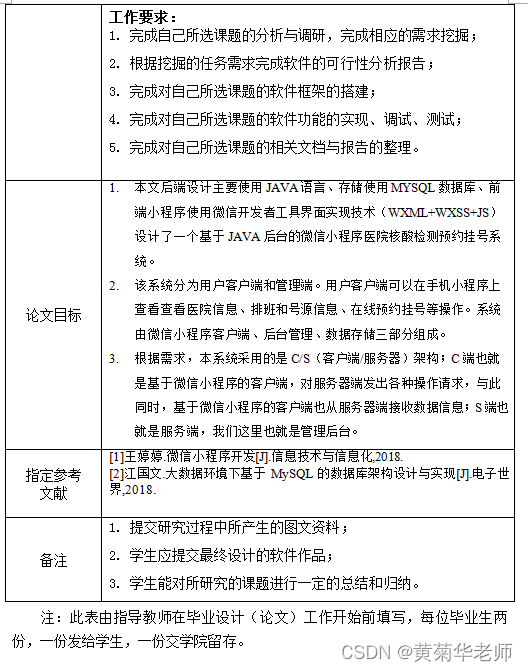
微信核酸检测预约小程序系统毕业设计毕设(5)任务书

Wechat nucleic acid detection appointment applet system graduation design completion (4) opening report
随机推荐
719. Find the distance of the number pair with the smallest K
Chrome officially supports MathML, which is enabled in chromium dev 105 by default
微信小程序视频分享平台系统毕业设计毕设(2)小程序功能
初夏,开源魔改一个带击杀音效的电蚊拍!
Wechat applet video sharing platform system graduation design completion (8) graduation design thesis template
Memory mapping of QT
RDK simulation experiment
微信核酸检测预约小程序系统毕业设计毕设(1)开发概要
[golang | grpc] use grpc to realize simple remote call
UE4 用spline画正圆
Pit encountered during installation of laravel frame
NVIDIA graphics card failed to initialize nvml driver/library version mismatch error solution
1288_ Implementation analysis of vtask resume() interface and interrupt Security version interface in FreeRTOS
QT official example: QT quick controls - Gallery
Win10 uninstall CUDA
利用DOSBox运行汇编超详细步骤「建议收藏」
Tower safety monitoring system unattended inclination vibration monitoring system
Design of the multi live architecture in different places of the king glory mall
【Oracle 期末复习】表空间、表、约束、索引、视图的增删改
Detailed explanation of map set