当前位置:网站首页>Statistical machine learning 】 【 linear regression model
Statistical machine learning 】 【 linear regression model
2022-08-03 19:43:00 【Fish and Yu meet the rain】
相关知识
概率论,是Study the law of quantity of random phenomena的数学分支.随机现象是相对于决定性现象而言的,For example, the sun rises in the east and sets in the west.Random phenomena refer to the case where the basic conditions remain unchanged,每一次试验或观察前,不能肯定会出现哪种结果,呈现出偶然性.例如,掷一硬币,可能出现正面或反面.
数理统计是数学的一个分支,分为描述统计和推断统计.It is based on probability theory,研究大量随机现象的统计规律性.描述统计的任务是搜集资料,进行整理、分组,编制次数分配表,绘制次数分配曲线,计算各种特征指标,以描述资料分布的集中趋势、离中趋势和次数分布的偏斜度等.推断统计是在描述统计的基础上,根据样本资料归纳出的规律性,对总体进行推断和预测.
(描述统计——>推断统计)
Machine Learning from a Computer Perspective and Machine Learning from a Statistical Perspective,Some names may be defined differently.
例如
| 机器学习 | 统计机器学习 |
|---|---|
| Unsupervised Learning (无监督学习) | Clustering 聚类 |
| Supervised Learning 监督学习 | 回归分析 |
| Semi-Supervised Learning | … |
| Reinforcement Learning | … |
| … | … |
变量类型
分类数据:职业、地址、性别
连续数据:年龄、收入
分类数据(But there are sequential implications):High school ,BSc,MSc,PhD
YThe type of variable determines the problem,and how to solve the problem
When to use statistical methods、When to use machine learning、When to use machine learning?
Only the features and sample size are large(样本量超过200,Features exceed20)的时候,We consider methods of machine learning.
除此之外,Classical statistical methods or statistical learning methods can solve almost all problems.(当然了,Machine learning can also be used,But it's not necessary for engineering)
The effect of the model in different data volume scenarios:
线性回归模型实例
心法:定(任务,The method is the same as the data preparation stage,Judging by the amount of data and the prediction task)、数、模、训、测、上
数:分析(任务)、理解、清晰、构建、选择、提取
模:模型、损失、优化器 (Choose a model based on the amount of data and type of prediction.)
训练:迭代、调参、降损失
定(问题定义)
预测房价、Obvious linear regression task,And the number of features is less20,Linear regression is preferred.
数(数据准备)
1,2 分析(问题,看Y)和 理解(特征,看X)
#1 问题分析
#(房价预测,回归任务,)
from sklearn import datasets
boston = datasets.load_boston()
print(boston.DESCR)
boston.shape
#分析(分析Y的类型,判断问题类型)
y = boston.target
y = pd.DataFrame(y)
y.describe()
# 理解
house = boston.data
house = pd.DataFrame(house,columns=['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD',
'TAX', 'PTRATIO', 'B', 'LSTAT'])
house.info()# View basic descriptive statistics
house.describe()
Data Set Characteristics:
:Number of Instances: 506
:Number of Attributes: 13 numeric/categorical predictive. Median Value (attribute 14) is usually the target.
:Attribute Information (in order):
- CRIM per capita crime rate by town
- ZN proportion of residential land zoned for lots over 25,000 sq.ft.
- INDUS proportion of non-retail business acres per town
- CHAS Charles River dummy variable (= 1 if tract bounds river; 0 otherwise)
- NOX nitric oxides concentration (parts per 10 million)
- RM average number of rooms per dwelling
- AGE proportion of owner-occupied units built prior to 1940
- DIS weighted distances to five Boston employment centres
- RAD index of accessibility to radial highways
- TAX full-value property-tax rate per $10,000
- PTRATIO pupil-teacher ratio by town
- B 1000(Bk - 0.63)^2 where Bk is the proportion of black people by town
- LSTAT % lower status of the population
- MEDV Median value of owner-occupied homes in $1000's
- The first is to analyze the data labels,To understand the needs of the task.Data mining tasks are mainly divided into two categories:回归与分类.
- Regression refers to tasks where the label values are continuous values,For example, the datasets used,Request forecast house price information,House prices are a continuous variable,So such a task is a regression problem(Regression)
- Classification refers to tasks where label values are discrete,For example irises(Iris)数据集,The sepal lengths of three irises were collected,宽度等信息,Based on this information, you are asked to predict which class an iris falls into,So the label is1,2,3,Represents three types of irises.Such tasks are classified as classification tasks.


通过分析可知,The house price labels are continuous data,Hence the regression task.
- 特征X理解
house_data.head()
house_data.info()
house_data.describe()
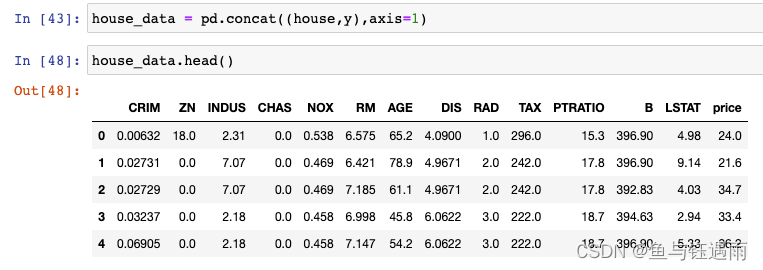
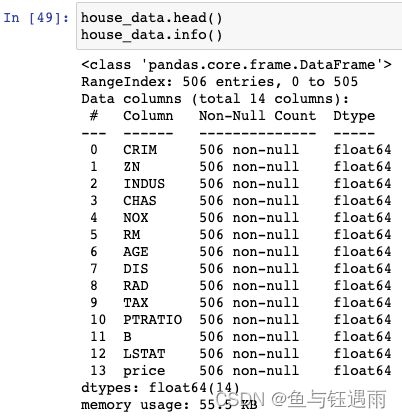
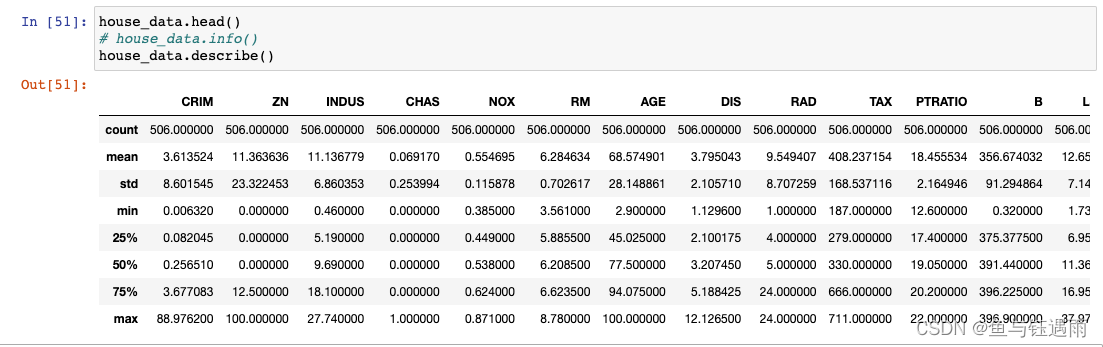
through these basic statistics,我们可以看:
- 是否有缺失值
- Whether the data is different from what we understand,例如处于[0-1]the value of>1
- Features with particularly small variance are also considered for deletion,In other words, it is meaningless to have a unique feature.(举例,If in an exam,Everyone's math scores are the same100分,Then there is no way to distinguish the ability of each student by their math scores,That is to say, there is no distinction in the subject of mathematics,Not analytically meaningful,可以删掉.)
- A variance that is too large indicates that the data are unlikely to be normal,because of lack of concentration.(补充说明:Standard deviation is the root of the variance,标准差越大,For the normal distribution,The more chunky the distribution image is,Therefore the data is not concentrated.The standard deviation is smaller,For the normal distribution,The image is shorter and thinner,数据集中.
- For whether there are outliers, we need to know through visual analysis such as box plots or scatter plots.
继续,We plot histograms of all features as follows,to analyze the distribution of each feature.And then through the distribution to observe the correlation between variables.(这部分可以在scatter plot matrixdraw together,We first draw a separate analysis here,以后就直接用scatter plot matrix就可以了)
https://blog.csdn.net/laffycat/article/details/125883973
http://t.csdn.cn/lGF1A
https://blog.csdn.net/qq_37596349/article/details/105378996
研究思路:
4. Let's first look at the data types of univariate first、分布情况、Whether there are outliers, etc,
Then study the relationship between the variables:相关性分析、分组统计等
3 特征清洗
Missing value statistics and handling
边栏推荐
- 力扣刷题之数组序号计算(每日一题7/28)
- Postgresql source code (65) analysis of the working principle of the new snapshot system Globalvis
- 七夕之前,终于整出了带AI的美丽秘笈
- Jingdong cloud released a new generation of distributed database StarDB 5.0
- matplotlib画polygon, circle
- 阿里巴巴政委体系-第六章、阿里政委体系运作
- 京东云发布新一代分布式数据库StarDB 5.0
- MySQL基础
- 从文本匹配到语义相关——新闻相似度计算的一般思路
- net-snmp私有mib动态加载到snmpd
猜你喜欢


随机推荐
Shell编程之循环语句
阿里巴巴政委体系-第七章、阿里政委培育
ScrollView嵌套RV,滑动有阻力不顺滑怎么办?
net-snmp私有mib动态加载到snmpd
Matlab论文插图绘制模板第42期—气泡矩阵图(相关系数矩阵图)
软件测试技术之如何编写测试用例(3)
Postgresql snapshot optimization Globalvis new system analysis (performance greatly enhanced)
力扣解法汇总899-有序队列
阿里巴巴政委体系-第六章、阿里政委体系运作
Postgresql-xl global snapshot and GTM code walking (branch line)
JS 内置构造函数 扩展 prototype 继承 借用构造函数 组合式 原型式creat 寄生式 寄生组合式 call apply instanceof
SQL server 实现触发器备份表数据
pg_memory_barrier_impl in Postgresql and C's volatile
Interview Blitz: What Are Sticky Packs and Half Packs?How to deal with it?
ERROR: You don‘t have the SNMP perl module installed.
622 设计循环队列——Leetcode天天刷【循环队列,数组模拟,双指针】(2022.8.2)
149. 直线上最多的点数-并查集做法
epoll + 线程池 + 前后置服务器分离
tensorflow-gpu2.4.1安装配置详细步骤
LeetCode 622. 设计循环队列