当前位置:网站首页>详解AST抽象语法树
详解AST抽象语法树
2022-08-03 19:36:00 【马踏飞燕&lin_li】
AST抽象语法树
文章目录
一、AST的作用
(一)简介
抽象语法树(abstract syntax code,AST)是源代码的抽象语法结构的树状表示,树上的每个节点都表示源代码中的一种结构,这所以说是抽象的,是因为抽象语法树并不会表示出真实语法出现的每一个细节,比如说,嵌套括号被隐含在树的结构中,并没有以节点的形式呈现。抽象语法树并不依赖于源语言的语法,也就是说语法分析阶段所采用的上下文无文文法,因为在写文法时,经常会对文法进行等价的转换(消除左递归,回溯,二义性等),这样会给文法分析引入一些多余的成分,对后续阶段造成不利影响,甚至会使合个阶段变得混乱。因些,很多编译器经常要独立地构造语法分析树,为前端,后端建立一个清晰的接口。
抽象语法树在很多领域有广泛的应用,比如浏览器,智能编辑器,编译器。
(二)抽象语法树实例
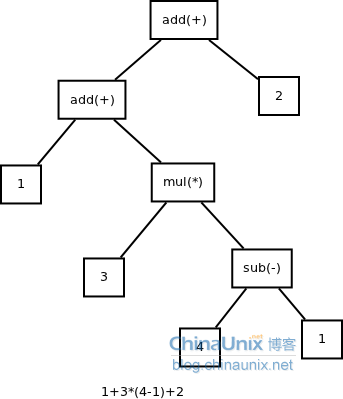
(1)四则运算表达式
表达式: 1+3*(4-1)+2
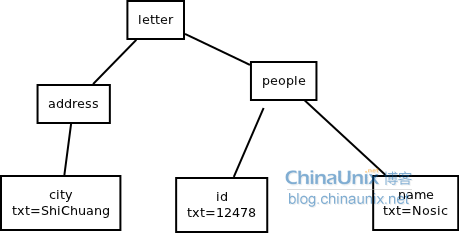
(2)xml
<letter>
<address>
<city>ShiChuang</city>
</address>
<people>
<id>12478</id>
<name>Nosic</name>
</people>
</letter>
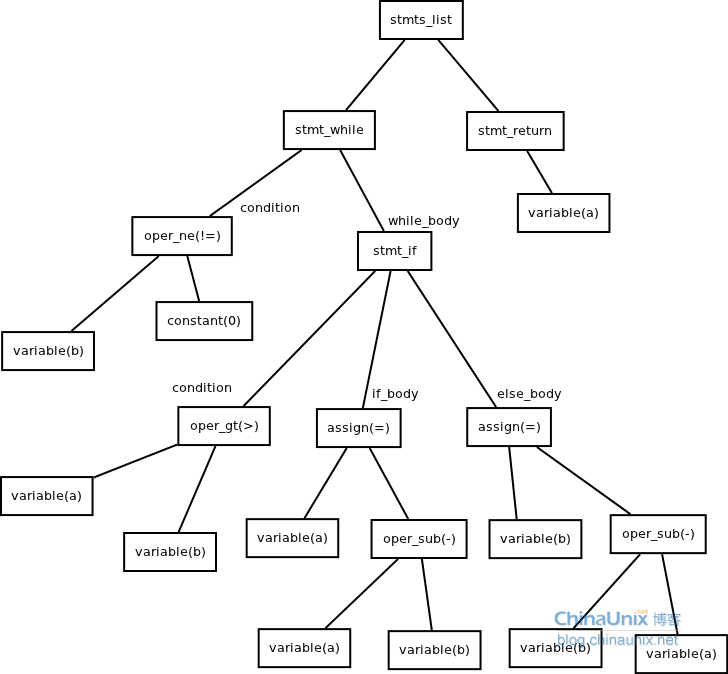
(3)程序1
while b != 0
{
if a > b
a = a-b
else
b = b-a
}
return a
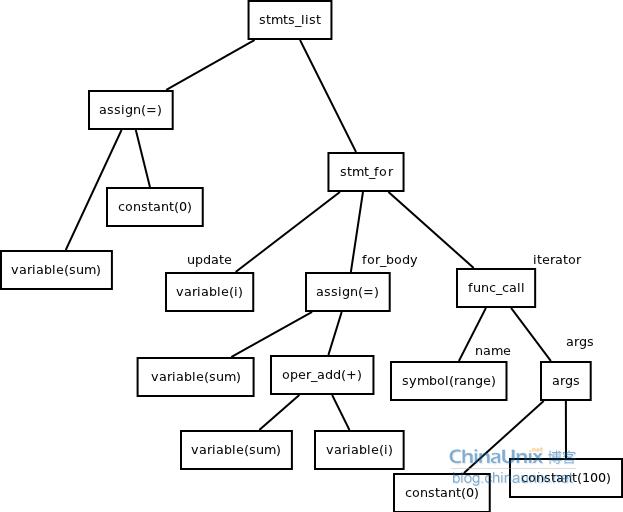
(4)程序2
sum=0
for i in range(0,100)
sum=sum+i
end
(三)为什么需要抽象语法树
当在源程序语法分析工作时,是在相应程序设计语言的语法规则指导下进行的。语法规则描述了该语言的各种语法成分的组成结构,通常可以用所谓的前后文无关文法或与之等价的Backus-Naur范式(BNF)将一个程序设计语言的语法规则确切的描述出来。前后文无关文法有分为这么几类:LL(1),LR(0),LR(1), LR(k) ,LALR(1)等。每一种文法都有不同的要求,如LL(1)要求文法无二义性和不存在左递归。当把一个文法改为LL(1)文法时,需要引入一些隔外的文法符号与产生式。
抽象语法树的第一个特点为:不依赖于具体的文法。无论是LL(1)文法,还是LR(1),或者还是其它的方法,都要求在语法分析时候,构造出相同的语法树,这样可以给编译器后端提供了清晰,统一的接口。即使是前端采用了不同的文法,都只需要改变前端代码,而不用连累到后端。即减少了工作量,也提高的编译器的可维护性。
抽象语法树的第二个特点为:不依赖于语言的细节。在编译器家族中,大名鼎鼎的gcc算得上是一个老大哥了,它可以编译多种语言,例如c,c++,java,ADA,Object C, FORTRAN, PASCAL, COBOL等等。在前端gcc对不同的语言进行词法,语法分析和语义分析后,产生抽象语法树形成中间代码作为输出,供后端处理。要做到这一点,就必须在构造语法树时,不依赖于语言的细节,例如在不同的语言中,类似于if-condition-then这样的语句有不同的表示方法
在c中为:
if(condition)
{
do_something();
}
在fortran中为:
If condition then
do_somthing()
end if
在构造if-condition-then语句的抽象语法树时,只需要用两个分支节点来表于,一个为condition,一个为if_body。如下图:
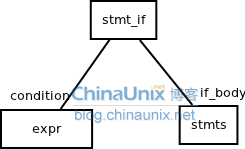
在源程序中出现的括号,或者是关键字,都会被丢掉。
二、AST流程
纯文本转AST的实现
第一步:词法分析,也叫扫描scanner
它读取我们的代码,然后把它们按照预定的规则合并成一个个的标识 tokens。同时,它会移除空白符、注释等。最后,整个代码将被分割进一个 tokens 列表(或者说一维数组)。
const a = 5;
// 转换成
[{value: 'const', type: 'keyword'}, {value: 'a', type: 'identifier'}, ...]
当词法分析源代码的时候,它会一个一个字母地读取代码,所以很形象地称之为扫描 - scans。当它遇到空格、操作符,或者特殊符号的时候,它会认为一个话已经完成了。
第二步:语法分析,也称解析器
它会将词法分析出来的数组转换成树形的形式,同时,验证语法。语法如果有错的话,抛出语法错误。
[{value: 'const', type: 'keyword'}, {value: 'a', type: 'identifier'}, ...]
// 语法分析后的树形形式
{
type: "VariableDeclarator",
id: {
type: "Identifier",
name: "a"
},
...
}
当生成树的时候,解析器会删除一些没必要的标识 tokens(比如:不完整的括号),因此 AST 不是 100% 与源码匹配的。
解析器100%覆盖所有代码结构生成树叫做CST。
现在,我们拆解一个简单的add函数
function add(a, b) {
return a + b
}
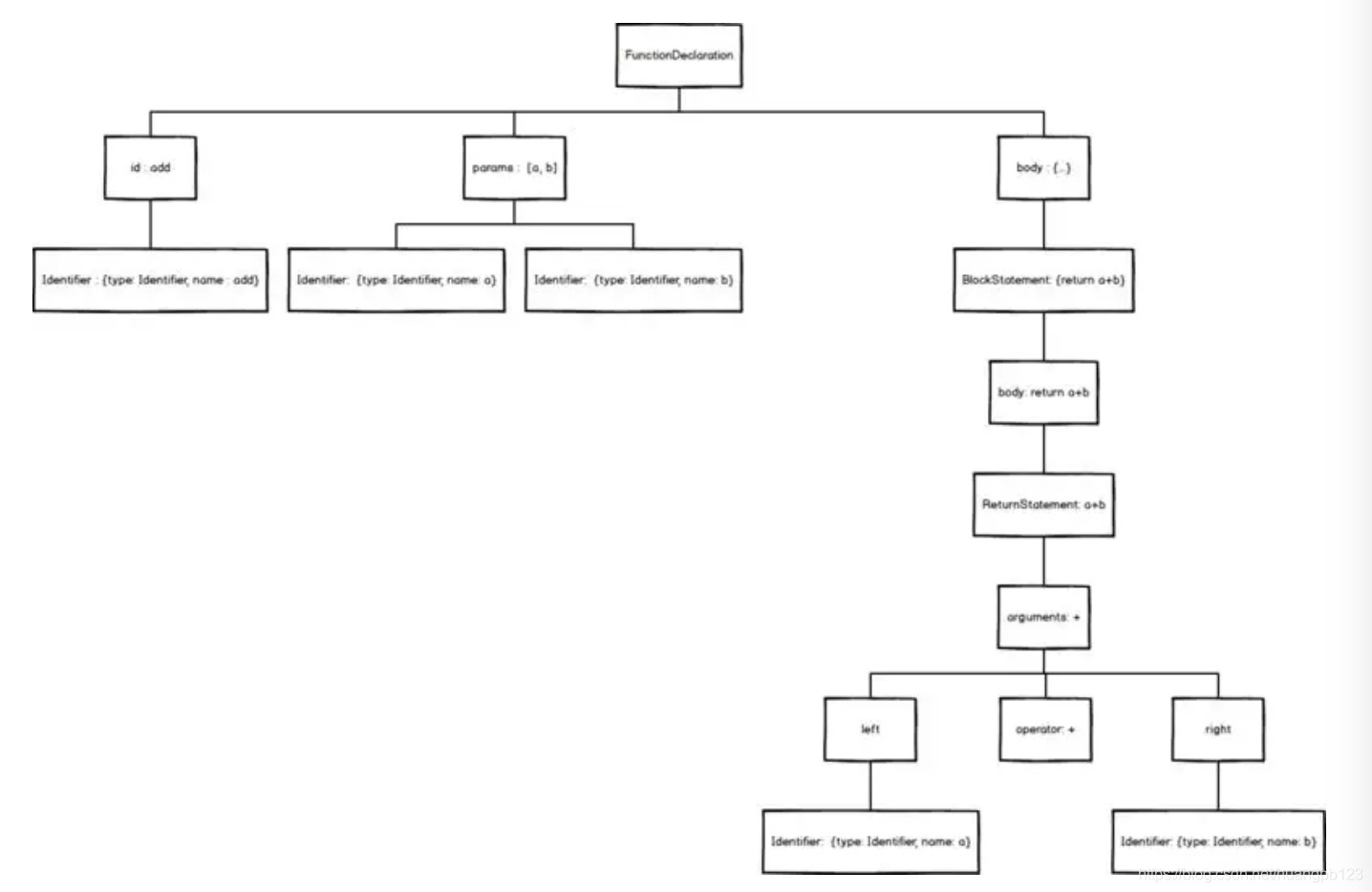
首先,我们拿到的这个语法块,是一个FunctionDeclaration(函数定义)对象。
用力拆开,它成了三块:
- 一个id,就是它的名字,即add
- 两个params,就是它的参数,即[a, b]
- 一块body,也就是大括号内的一堆东西
add没办法继续拆下去了,它是一个最基础Identifier(标志)对象,用来作为函数的唯一标志,就像人的姓名一样。
{
name: 'add'
type: 'identifier'
...
}
params继续拆下去,其实是两个Identifier组成的数组。之后也没办法拆下去了。
[
{
name: 'a'
type: 'identifier'
...
},
{
name: 'b'
type: 'identifier'
...
}
]
接下来,我们继续拆开body
我们发现,body其实是一个BlockStatement(块状域)对象,用来表示是{return a + b}
打开Blockstatement,里面藏着一个ReturnStatement(Return域)对象,用来表示return a + b
继续打开ReturnStatement,里面是一个BinaryExpression(二项式)对象,用来表示a + b
继续打开BinaryExpression,它成了三部分,left,operator,right
- operator 即+
- left 里面装的,是Identifier对象 a
- right 里面装的,是Identifer对象 b
就这样,我们把一个简单的add函数拆解完毕,用图表示就是
三、在 Python 中生成 AST
在 Python 的底层实现中已经包含了源码到 AST 到 CodeObject 的转换过程,实际上 Python 也提供了一组工具,帮助我们直接控制 AST,如果熟练掌握的话,可以实现一些很有意思的魔法。
(一)从源码到 AST
Python官方提供的CPython解释器对python源码的处理过程如下:
Parse source code into a parse tree (Parser/pgen.c)
Transform parse tree into an Abstract Syntax Tree (Python/ast.c)
Transform AST into a Control Flow Graph (Python/compile.c)
Emit bytecode based on the Control Flow Graph (Python/compile.c)
即实际python代码的处理过程如下:
源代码解析 --> 语法树 --> 抽象语法树(AST) --> 控制流程图 --> 字节码
AST官方文档 https://docs.python.org/zh-cn/3/library/ast.html
AST源码 https://github.com/python/cpython/blob/3.10/Lib/ast.py
Compile函数
compile(source, filename, mode[, flags[, dont_inherit]])
- source – 字符串或者AST(Abstract Syntax Trees)对象。一般可将整个py文件内容file.read()传入。
- filename – 代码文件名称,如果不是从文件读取代码则传递一些可辨认的值。
- mode – 指定编译代码的种类。可以指定为 exec, eval, single。
- flags – 变量作用域,局部命名空间,如果被提供,可以是任何映射对象。
- flags和dont_inherit是用来控制编译源码时的标志。
>>> cm = compile(func_def, '<string>', 'exec')
>>> exec cm
==
ast.parse(source, filename='<unknown>', mode='exec')
demo2.py
import types
func_def = \
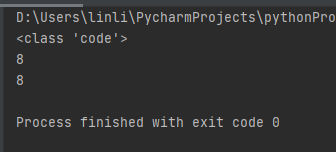
""" def add(x, y): return x + y print(add(3, 5)) """
cm = compile(func_def, '<string>', 'exec')
print(type(cm))
isinstance(cm, types.CodeType)
exec(func_def) #传入的类型可以是str、bytes或code。
exec(cm) #传入的类型可以是str、bytes或code。
上面func_def经过compile编译得到字节码。
生成ast
Python 已经内置了 ast 模块,可以直接从源码生成 AST,另外还有一组工具可以对 AST 做一些调整。首先从最基本的开始,从源码获得 AST 对象。
ast.parse(source, filename='<unknown>', mode='exec', *, type_comments=False, feature_version=None)
主要参数:
- source,待编译代码,字符串;
- filename,运行时错误信息会被输出到这个文件;
- mode,如果是单行代码为 “eval”,多行代码则为 “exec”;
其返回值为 AST 对象。
AST 对象是一个树状结构,每一个 Node 可能会有多个子节点,通过 ast.dump 可以方便的查看 AST 的内部。
import ast
src=''' a = 1 b = 2 c = a + b '''
ast_node = ast.parse(src, "msg.log", mode="exec")
print(ast.dump(ast_node))
这样就可以得到输出:
Module(body=[Assign(targets=[Name(id='a', ctx=Store())], value=Num(n=1)), Assign(targets=[Name(id='b', ctx=Store())], value=Num(n=2)), Assign(targets=[Name(id='c', ctx=Store())], value=BinOp(left=Name(id='a', ctx=Load()), op=Add(), right=Name(id='b', ctx=Load())))])
除了ast.dump,有很多dump ast的第三方库,如astunparse, codegen, unparse等。这些第三方库不仅能够以更好的方式展示出ast结构,还能够将ast反向导出python source代码。
源码分析:
ast.parse(可以直接查看ast模块的源代码)方法实际上是调用内置函数compile进行编译,源码如下所示:
def parse(source, filename='<unknown>', mode='exec'):
""" Parse the source into an AST node. Equivalent to compile(source, filename, mode, PyCF_ONLY_AST). """
return compile(source, filename, mode, PyCF_ONLY_AST)
传递给compile特殊的flag = PyCF_ONLY_AST, 来通过compile返回抽象语法树。
astpretty 优雅输出
AST 本质上是树状结构的数据,上面的输出不是很方便观察,astpretty 提供了更加优雅的输出。
Module(
body=[
Assign(
lineno=2,
col_offset=0,
end_lineno=2,
end_col_offset=5,
targets=[Name(lineno=2, col_offset=0, end_lineno=2, end_col_offset=1, id='a', ctx=Store())],
value=Constant(lineno=2, col_offset=4, end_lineno=2, end_col_offset=5, value=1, kind=None),
type_comment=None,
),
Assign(
lineno=3,
col_offset=0,
end_lineno=3,
end_col_offset=5,
targets=[Name(lineno=3, col_offset=0, end_lineno=3, end_col_offset=1, id='b', ctx=Store())],
value=Constant(lineno=3, col_offset=4, end_lineno=3, end_col_offset=5, value=2, kind=None),
type_comment=None,
),
Assign(
lineno=4,
col_offset=0,
end_lineno=4,
end_col_offset=9,
targets=[Name(lineno=4, col_offset=0, end_lineno=4, end_col_offset=1, id='c', ctx=Store())],
value=BinOp(
lineno=4,
col_offset=4,
end_lineno=4,
end_col_offset=9,
left=Name(lineno=4, col_offset=4, end_lineno=4, end_col_offset=5, id='a', ctx=Load()),
op=Add(),
right=Name(lineno=4, col_offset=8, end_lineno=4, end_col_offset=9, id='b', ctx=Load()),
),
type_comment=None,
),
],
type_ignores=[],
)
ast树解析
语法树中的每个节点都对应ast下的一种类型,根节点是ast.Moudle类型,在分析的时候可以通过isinstance函数方便的进行节点类型的判断。
import ast
root_node = ast.parse("print('hello world')")
print(ast.dump(root_node))
print(isinstance(root_node,ast.Module))
print(isinstance(root_node,ast.Expr))
print(isinstance(root_node.body[0],ast.Expr))
ast.expr 和 ast.stmt 子类的实例有 lineno、col_offset、end_lineno 和 end_lineno 属性。lineno 和 end_lineno 是源代码的第一行行数和最后一行行数(从1开始, 所以第一行行数是1),而 col_offset 和 end_col_offset 是该生成节点第一个和最后一个 token 的 UTF-8 字节偏移量。记录下 UTF-8 偏移量的原因是 parser 内部使用 UTF-8 。
抽象语法定义的每个左侧符号(比方说, ast.stmt 或者 ast.expr)定义了一个类。另外,在抽象语法定义的右侧,对每一个构造器也定义了一个类;这些类继承自树左侧的类。比如,ast.Assign 继承自 ast.stmt。
每个具体类的实例对它每个子节点都有一个属性,对应类型如文法中所定义。比如,ast.Assign 的实例有个属性 target,类型是 ast.stmt.
比如 a = 10这样一条语句对应ast.Assign节点类型,而Assign节点类型分别有两个子节点, 分别为ast.Name类型的a和ast.Num类型的10等。我们可以通过ast.dump(node)函数来将node格式化,并进行打印,以查看节点内容,以“a = 10”这行代码为例。
Module(body=[Assign(targets=[Name(id=‘a’, ctx=Store())], value=Num(n=10))])
(1) root节点
Module(body=[Assign(targets=[Name(id=‘a’, ctx=Store())], value=Num(n=10))])
root节点是Module类型,由于只有一行代码,所有root节点只有Assign这样一个子节点。
(2) 子节点
Assign(targets=[Name(id=‘a’, ctx=Store())], value=Num(n=10))
上述的Assign节点有三个子节点,分别是Name, Store和Num.
Name(id=‘a’, ctx=Store())
Num(n=10)
而Name有一个子节点,Store.
Store()(Store表示Name中操作时赋值, 类型的有Load,del, 具体参考节点类型的文档)
一个简单的“a = 10”的这样一行代码,我们就可以通过上述的这种ast tree去分析和修改代码结构。
附:摘取抽象文法目前定义如下:
module Python
{
mod = Module(stmt* body, type_ignore* type_ignores)
| Interactive(stmt* body)
| Expression(expr body)
| FunctionType(expr* argtypes, expr returns)
stmt = FunctionDef(identifier name, arguments args,
stmt* body, expr* decorator_list, expr? returns,
string? type_comment)
| AsyncFunctionDef(identifier name, arguments args,
stmt* body, expr* decorator_list, expr? returns,
string? type_comment)
| ClassDef(identifier name,
expr* bases,
keyword* keywords,
stmt* body,
expr* decorator_list)
| Return(expr? value)
| Delete(expr* targets)
| Assign(expr* targets, expr value, string? type_comment)
| AugAssign(expr target, operator op, expr value)
-- 'simple' indicates that we annotate simple name without parens
| AnnAssign(expr target, expr annotation, expr? value, int simple)
-- use 'orelse' because else is a keyword in target languages
| For(expr target, expr iter, stmt* body, stmt* orelse, string? type_comment)
| AsyncFor(expr target, expr iter, stmt* body, stmt* orelse, string? type_comment)
| While(expr test, stmt* body, stmt* orelse)
| If(expr test, stmt* body, stmt* orelse)
| With(withitem* items, stmt* body, string? type_comment)
| AsyncWith(withitem* items, stmt* body, string? type_comment)
| Match(expr subject, match_case* cases)
| Raise(expr? exc, expr? cause)
| Try(stmt* body, excepthandler* handlers, stmt* orelse, stmt* finalbody)
| Assert(expr test, expr? msg)
| Import(alias* names)
| ImportFrom(identifier? module, alias* names, int? level)
| Global(identifier* names)
| Nonlocal(identifier* names)
| Expr(expr value)
| Pass | Break | Continue
-- col_offset is the byte offset in the utf8 string the parser uses
attributes (int lineno, int col_offset, int? end_lineno, int? end_col_offset)
-- BoolOp() can use left & right?
expr = BoolOp(boolop op, expr* values)
| NamedExpr(expr target, expr value)
| BinOp(expr left, operator op, expr right)
| UnaryOp(unaryop op, expr operand)
| Lambda(arguments args, expr body)
| IfExp(expr test, expr body, expr orelse)
| Dict(expr* keys, expr* values)
| Set(expr* elts)
| ListComp(expr elt, comprehension* generators)
| SetComp(expr elt, comprehension* generators)
| DictComp(expr key, expr value, comprehension* generators)
| GeneratorExp(expr elt, comprehension* generators)
-- the grammar constrains where yield expressions can occur
| Await(expr value)
| Yield(expr? value)
| YieldFrom(expr value)
-- need sequences for compare to distinguish between
-- x < 4 < 3 and (x < 4) < 3
| Compare(expr left, cmpop* ops, expr* comparators)
| Call(expr func, expr* args, keyword* keywords)
| FormattedValue(expr value, int conversion, expr? format_spec)
| JoinedStr(expr* values)
| Constant(constant value, string? kind)
-- the following expression can appear in assignment context
| Attribute(expr value, identifier attr, expr_context ctx)
| Subscript(expr value, expr slice, expr_context ctx)
| Starred(expr value, expr_context ctx)
| Name(identifier id, expr_context ctx)
| List(expr* elts, expr_context ctx)
| Tuple(expr* elts, expr_context ctx)
-- can appear only in Subscript
| Slice(expr? lower, expr? upper, expr? step)
-- col_offset is the byte offset in the utf8 string the parser uses
attributes (int lineno, int col_offset, int? end_lineno, int? end_col_offset)
expr_context = Load | Store | Del
boolop = And | Or
ast反编译工具 astunparse
安装astunparse:pip install astunparse
astunparse官网:https://pypi.org/project/astunparse/
import ast
import astunparse
src = '''
a = 1
b = 2
c = a + b
print("hello world")
'''
# get back the source code
print(astunparse.unparse(ast.parse(src)))
输出结果:
a = 1
b = 2
c = (a + b)
print('hello world')
(二)语法树的遍历分析
使用NodeVisitor主要是通过修改语法树上节点的方式改变AST结构,NodeTransformer主要是替换ast中的节点。
1. visitor的定义
可以通过ast模块的提供的visitor来对语法树进行遍历。
ast.NodeVisitor是一个专门用来遍历语法树的工具,我们可以通过继承这个类来完成对语法树的遍历以及遍历过程中的处理。
import ast
import astunparse
func_def = \
""" a = 3 b = 5 def add(x, y): return x + y print(add(a,b)) """
# class CodeVisitor(ast.NodeVisitor):
# def generic_visit(self, node):
# print(type(node).__name__,end=', ')
# ast.NodeVisitor.generic_visit(self, node)
#
# def visit_FunctionDef(self, node):
# print(type(node).__name__,end=', ')
# ast.NodeVisitor.generic_visit(self, node)
#
# def visit_Assign(self, node):
# print(type(node).__name__,end=', ')
# ast.NodeVisitor.generic_visit(self, node)
# r_node = ast.parse(func_def)
# visitor = CodeVisitor()
# visitor.visit(r_node)
class CodeVisitor(ast.NodeVisitor):
def generic_visit(self, node):
print(type(node).__name__)
ast.NodeVisitor.generic_visit(self, node)
def visit_FunctionDef(self, node):
print(type(node).__name__)
ast.NodeVisitor.generic_visit(self, node)
def visit_Assign(self, node):
print(type(node).__name__)
ast.NodeVisitor.generic_visit(self, node)
r_node = ast.parse(func_def)
visitor = CodeVisitor()
visitor.visit(r_node)
如上述代码,定义类CodeVisitor,继承自NodeVisitor,这里面主要有两种类型的函数,一种的generic_visit,一种是"visit_" + “Node类型”。
visitor首先从根节点root进行遍历,在遍历的过程中,假设节点类型为Assign,如果存在visit_Assign类型的函数,则调用visit_Assgin函数,如果不存在则调用generic_visit函数。
在每个函数处理中,根据需求需要加上ast.NodeVisitor.generic_visit(self, node)这段代码,否则visitor不会继续访问当前节点的子节点。
e.g. 如果定义如下的函数:
def visit_Moudle(self, node):
print type(node).name
那么,首先访问根节点root,root为Moudle类型,会调用visit_Moudle函数,由于visit_Moudle函数中没有调用NodeVisitor.generic_visit(self, node),所以此次遍历只遍历了根节点root,并没有遍历其他节点。
2. visitor方法示例
将def中的add函数中的加法运算改为减法。
import ast
import astunparse
func_def = \
""" a = 3 b = 5 def add(x, y): return x + y print(add(a,b)) """
class CodeVisitor(ast.NodeVisitor):
def generic_visit(self, node):
print(type(node).__name__)
ast.NodeVisitor.generic_visit(self, node)
def visit_FunctionDef(self, node):
print(type(node).__name__)
ast.NodeVisitor.generic_visit(self, node)
def visit_Assign(self, node):
print(type(node).__name__)
ast.NodeVisitor.generic_visit(self, node)
def visit_BinOp(self, node):
if isinstance(node.op, ast.Add):
node.op = ast.Sub()
self.generic_visit(node)
r_node = ast.parse(func_def)
visitor = CodeVisitor()
visitor.visit(r_node)
print(astunparse.unparse(r_node))
exec(compile(r_node, '<string>', 'exec'))

3. walk方式遍历
for node in ast.walk(tree):
if isinstance(node, ast.FunctionDef):
print(node.name)
4.NodeTransfomer定义
使用NodeVisitor主要是通过修改语法树上节点的方式改变AST结构,NodeTransformer主要是替换ast中的节点。
ast模块同样提供了一个NodeTransfomer节点来支持对node的修改,NodeTransfomer继承自NodeVisitor,并重写了generic_visit函数。
对于NodeTransfomer的generic_visit以及visit_ + 节点类型的函数,都需要返回一个node,可以返回原始node,一个新的替代的node,或者是返回Node代表remove掉这个节点。
假设我们有如下的代码:
"""ast test code"""
a = 10
b = "test"
print(a)
我们定义一个NodeTransform的visitor如下:
class ReWriteName(ast.NodeTransformer):
def generic_visit(self, node):
has_lineno = getattr(node, "lineno", "None")
col_offset = getattr(node, "col_offset", "None")
print type(node).__name__, has_lineno, col_offset
ast.NodeTransformer.generic_visit(self, node)
return node
def visit_Name(self, node):
new_node = node
if node.id == "a":
new_node = ast.Name(id = "a_rep", ctx = node.ctx)
return new_node
def visit_Num(self, node):
if node.n == 10:
node.n = 100
return node
file = open("code.py", "r")
source = file.read()
visitor = ReWriteName()
root = ast.parse(source)
root = visitor.visit(root)
ast.fix_missing_locations(root)
code_object = compile(root, "<string>", "exec")
exec(code_object)
在visit_Name中,将变量"a"替换成了变量"a_rep",执行到a = 10以及print a的时候,都会将a替换成a_rep,并返回一个新节点。
在visit_Num中,简单粗暴的将10替换成了100,返回修改后的原节点。
ast作用在python解析语法之后,编译成pyCodeObject字节码结构之前,通过NodeTransformer修改后,返回修改后的语法树,我们通过内置模块compile编译成pyCodeObject对象,交给python虚拟机执行。
执行结果:100
可以看到,我们同时将a = 10和print a两处将a名字换成了a_rep,并将10替换成了100,最后打印的结果是100,成功修改了语法树的节点。
注意:
修改语法树节点,尤其是删除一个语法树节点时要慎重,因为修改或者删除后有可能返回错误的语法树,直到compile或者执行的时候才会发现问题。
通过节点修改python code就可以通过上述方法进行,不过请注意,在运用visitor的代码中有ast.fix_missing_locations(root)这样一行代码,这是因为我们自己创建的节点是不包含lineno以及col_offset这些必要的属性,必须手动修改添加指定,新添加的节点代码的行位置以及偏移位置。
5.NodeTransfomer方法示例
关于节点的修改,这里有比较好的例子可以参考:https://greentreesnakes.readthedocs.org/en/latest/examples.html
把def中定义的add改成一个减函数了,把函数名和参数以及被调用的函数都在ast中改掉。
import ast
import astunparse
func_def = \
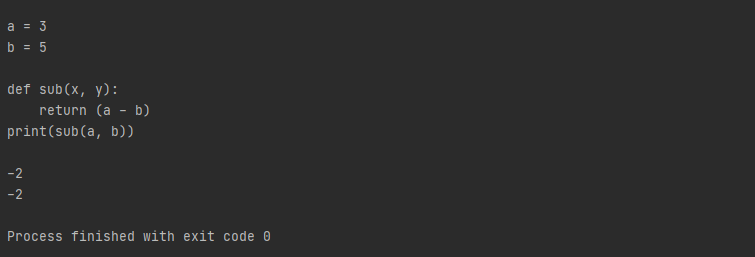
""" a = 3 b = 5 def add(x, y): return x + y print(add(a,b)) """
class CodeTransformer(ast.NodeTransformer):
def visit_BinOp(self, node):
if isinstance(node.op, ast.Add):
node.op = ast.Sub()
self.generic_visit(node)
return node
def visit_FunctionDef(self, node):
self.generic_visit(node)
if node.name == 'add':
node.name = 'sub'
args_num = len(node.args.args)
print(node.args.args)
# args = tuple([arg.id for arg in node.args.args])
# func_log_stmt = ''.join(["print 'calling func: %s', " % node.name, "'args:'", ", %s" * args_num % args])
# node.body.insert(0, ast.parse(func_log_stmt))
return node
def visit_Name(self, node):
replace = {
'add': 'sub', 'x': 'a', 'y': 'b'}
re_id = replace.get(node.id, None)
node.id = re_id or node.id
self.generic_visit(node)
return node
r_node = ast.parse(func_def)
transformer = CodeTransformer()
r_node = transformer.visit(r_node)
# print astunparse.dump(r_node)
source = astunparse.unparse(r_node)
print(source)
# exec compile(r_node, '<string>', 'exec') # 新加入的node func_log_stmt 缺少lineno和col_offset属性
exec(compile(source, '<string>', 'exec'))
exec(compile(ast.parse(source), '<string>', 'exec'))
四、AST的应用
AST模块实际编程中很少用到,但是作为一种源代码辅助检查手段是非常有意义的;语法检查,调试错误,特殊字段检测等。
(一)汉字检测
下面是中日韩字符的unicode编码范围
CJK Unified Ideographs
Range: 4E00— 9FFF
Number of characters: 20992
Languages: chinese, japanese, korean, vietnamese
使用 unicode 范围 \u4e00 - \u9fff 来判别汉字,注意这个范围并不包含中文字符(e.g. u’;’ == u’\uff1b’) .
下面是一个判断字符串中是否包含中文字符的一个类CNCheckHelper:
class CNCheckHelper(object):
# 待检测文本可能的编码方式列表
VALID_ENCODING = ('utf-8', 'gbk')
def _get_unicode_imp(self, value, idx = 0):
if idx < len(self.VALID_ENCODING):
try:
return value.decode(self.VALID_ENCODING[idx])
except:
return self._get_unicode_imp(value, idx + 1)
def _get_unicode(self, from_str):
if isinstance(from_str, unicode):
return None
return self._get_unicode_imp(from_str)
def is_any_chinese(self, check_str, is_strict = True):
unicode_str = self._get_unicode(check_str)
if unicode_str:
c_func = any if is_strict else all
return c_func(u'\u4e00' <= char <= u'\u9fff' for char in unicode_str)
return False
接口is_any_chinese有两种判断模式,严格检测只要包含中文字符串就可以检查出,非严格必须全部包含中文。
下面我们利用ast来遍历源文件的抽象语法树,并检测其中字符串是否包含中文字符。
class CodeCheck(ast.NodeVisitor):
def __init__(self):
self.cn_checker = CNCheckHelper()
def visit_Str(self, node):
self.generic_visit(node)
# if node.s and any(u'\u4e00' <= char <= u'\u9fff' for char in node.s.decode('utf-8')):
if self.cn_checker.is_any_chinese(node.s, True):
print 'line no: %d, column offset: %d, CN_Str: %s' % (node.lineno, node.col_offset, node.s)
project_dir = './your_project/script'
for root, dirs, files in os.walk(project_dir):
print root, dirs, files
py_files = filter(lambda file: file.endswith('.py'), files)
checker = CodeCheck()
for file in py_files:
file_path = os.path.join(root, file)
print 'Checking: %s' % file_path
with open(file_path, 'r') as f:
root_node = ast.parse(f.read())
checker.visit(root_node)
五、参考文献
https://www.jb51.net/article/257225.htm
https://greentreesnakes.readthedocs.io/en/latest/examples.html
https://www.cnblogs.com/us-wjz/articles/11013200.html
https://docs.python.org/zh-cn/3/library/ast.html#node-classes
https://github.com/python/cpython/blob/3.10/Lib/ast.py
边栏推荐
- Postgresql snapshot optimization Globalvis new system analysis (performance greatly enhanced)
- 虚拟机vmware设置桥接模式上网
- X86 function call model analysis
- 云图说丨初识华为云微服务引擎CSE
- ECCV2022 | 用于视频问题回答的视频图Transformer
- 软件测试回归案例,什么是回归测试?
- 国产虚拟化云宏CNware WinStack安装体验-5 开启集群HA
- Force is brushed buckle problem for the sum of two Numbers
- 傅里叶变换(深入浅出)
- CS免杀姿势
猜你喜欢






随机推荐
Shell编程之循环语句
阿里巴巴政委体系-第八章、阿里政委工作方法论
阿洛的反思
【QT】入门心法
MySQL读写分离的三种实现方案
epoll + 线程池 + 前后置服务器分离
MySQL 主从,6 分钟带你掌握!
The effective square of the test (one question of the day 7/29)
matplotlib画polygon, circle
软件测试回归案例,什么是回归测试?
redis常用命令,HSET,XADD,XREAD,DEL等
flex布局
ECCV 2022 Oral | 满分论文!视频实例分割新SOTA: IDOL
go语言实现导出string字符串到文件中
开源生态研究与实践| ChinaOSC
建模该从哪一步开始?给你分析,给零基础的你一些学习建议
余弦距离介绍
力扣刷题之移动零
如何理解即时通讯开发移动网络的“弱”和“慢”
高效目标检测:动态候选较大程度提升检测精度(附论文下载)