当前位置:网站首页>On Data Mining
On Data Mining
2022-07-03 17:55:00 【Data digger】
The authors introduce
@ Cat ears
Focus on data analysis ;
“ DataMan creators Alliance ” member .
Doudou and Huahua opened a flower shop . Doudou said to Huahua :“ Valentine's Day is coming , What kind of Valentine's Day bouquets do we need to prepare ? How much need to be prepared for each kind of bouquet ?……” Hua Hua replied ,“ According to customer classification , It can be roughly divided into confidence and love 、 Sweet heart 、 Xinghe beloved, etc 8 class . The first three categories sold very well last year , This year we need to provide more than last year 30% Of flowers ,……”.
Doudou theory :“ The shelf life of flowers is very short , therefore , Buy more flowers only from 30% Down to 10%, It can control the cost , You can also accumulate public praise .……”
In the case above , Huahua makes a purchase plan and first classifies customers , In the field of data mining , You can use an unsupervised model ( for example k-means), You can also use a classification model ( for example KNN、 Decision tree 、 Logical regression, etc ) Group users . Huahua estimation “ This year needs to provide higher than the previous year 30% Of flowers ”, In the field of data mining , Regression models can be used to predict .
Next , The author will talk about data mining with you .
01 The difference and connection between machine learning and data mining
1.1 Concept
First , Let's summarize the definitions of machine learning and data mining :
Data mining refers to data mining from a large number of 、 Not completely 、 Noisy 、 Vague 、 The process of searching information hidden in random data by algorithm . let me put it another way , Data mining attempts to find useful information from massive data .
Machine learning is a kind of automatic analysis and acquisition of rules from data , And using the law to predict the unknown data algorithm . in other words , Machine learning is to abstract real-life problems into mathematical models , The mathematical model is solved by mathematical method , So as to solve the problems in real life .
1.2 Connection and difference
1.2.1 contact
Data mining is influenced by many disciplines , Including databases 、 machine learning 、 statistical 、 Domain knowledge and pattern recognition . In short , For data mining , Database provides data storage technology , Machine learning and statistics provide data analysis techniques .

Statistics often ignores the actual utility and is obsessed with the beauty of theory , therefore , Most of the technologies provided by statistics need to be further studied in the field of machine learning , Only when it becomes a machine learning algorithm can it enter the field of data mining . In this respect , Statistics mainly affects data mining through machine learning , Machine learning and database are the two supports of data mining .
in short , Machine learning provides data mining with methods to solve practical problems , The successful application of algorithms in data mining , It shows that machine learning has practical application value to the research of Algorithm .
1.2.2 difference
In terms of data analysis , Most data mining techniques come from machine learning , But machine learning research does not treat massive data as the processing object , therefore , Data mining needs to transform the algorithm , Make the algorithm performance and space occupation reach the practical level . meanwhile , Data mining has its own unique content —— Correlation analysis .
as for , Data mining and pattern recognition , Conceptually distinguish , Data mining focuses on discovering knowledge , Pattern recognition focuses on recognizing things .
in short , Machine learning pays attention to the theoretical research and algorithm improvement of relevant machine learning algorithms , More theoretical and academic ; Data mining focuses on using algorithms or some other pattern to solve practical problems , More inclined to practice and Application .
02 Classification of machine learning
The method of machine learning is based on data generation “ Model ” The algorithm of , Also known as “ Learning algorithms ”. Machine learning methods include supervised learning 、 Unsupervised learning 、 Semi supervised learning and reinforcement learning .

2.1 Supervised learning
Supervised learning refers to the process of modeling the relationship between several features of data and labels . Its main goal is to learn models from labeled training data , In order to predict the unknown or future data .
Take whether users will repurchase flowers as an example , Supervised learning algorithm can be used in tagged ( Correctly mark yes or no ) Training model on data , Then the model is used to predict whether new users belong to sticky users .
The supervised learning task labeled with discrete values is called 「 Classification task 」, For example, the above example of whether users will re purchase flowers . Common classification models include KNN、 Decision tree 、 Logical regression, etc .
The supervised learning task labeled with continuous values is called 「 Return to the task 」, For example, predict future sales based on historical data . The commonly used regression model is linear regression 、 Nonlinear regression and ridge regression .
Be careful : Predictive variables in machine learning are often called features , The response variable is usually called the target variable or tag .
2.1 Unsupervised learning
Unsupervised learning refers to modeling data features without any labels , It is usually regarded as a kind of “ Let the data introduce themselves ” The process of . in other words , Use unsupervised learning , It can be done without the guidance of target variables or reward functions , Explore data structures to extract meaningful information .
Such models include 「 Clustering tasks 」 and 「 Dimensionality reduction task 」. among , Clustering algorithm can divide data into different groups , The dimensionality reduction algorithm seeks to represent the data in a more concise way .
1.3 Semi-supervised learning
Semi supervised learning method is between supervised learning and unsupervised learning , It is usually used when the data is incomplete .
1.4 Reinforcement learning
Reinforcement learning is different from supervised learning , It regards learning as a tentative evaluation process , With “ Trial and error ” The way of learning , And interact with the environment has been rewarded and punished to guide behavior , Take it as an evaluation . in other words , Emphasis on how to act based on context , In order to maximize the expected benefits .
here , The system learns by its own state and action , So as to improve the action plan to adapt to the environment .
03 Data mining modeling process
Consider from the data itself , Data mining modeling process usually requires an understanding of business 、 Understand the data 、 Prepare the data 、 Build a model 、 Evaluation model and deployment model 6 A step .

3.1 Understanding business
Understanding business is the most important part of data mining , At this stage, we need to clarify our business objectives 、 Assess the business environment 、 Determine the mining target and generate a project plan .
In short , For different business scenarios , You need to understand what the goal of mining is , What kind of effect needs to be achieved . Speak in big white , Is what you want to do .
Still take the fresh flower shop as an example , In order to increase sales , The clerk can help the customer quickly find the bouquet he is interested in , While ensuring the user experience , Attach an acceptable trinket to it , Such as a vase 、 snacks 、 Perfume, etc .
3.2 Understand the data
Data mining process “ raw material ”, In the process of data understanding, we need to know what data we have , What are the characteristics of these data , The characteristics of the data can be obtained by describing and analyzing the data . among , Knowing what data is particularly important , It determines the smooth progress of the later work .
For example, data related to flower shops :
1) Flower data : Name of flowers 、 Flower category 、 Purchase time 、 Purchase quantity 、 Purchase amount, etc .
2) Business data : Business hours 、 Scheduled time 、 Booking category 、 Scheduled number of people, etc .
3) Other data : Whether it's a holiday or not 、 User reputation 、 Competitor trends 、 Weather conditions, etc .
3.3 Prepare the data
In the data preparation stage, we need to clean the data 、 The reconstruction 、 Merge and so on . Select the data to be analyzed , And standardize the data that does not meet the requirements of model input . It is mainly to prepare data for modeling , Can be preprocessed from data 、 feature extraction 、 Feature selection and other aspects , It is arranged as follows :
1) Missing value : Due to personal privacy or equipment failure, some observations are missing at some latitudes , It is often called missing value . The existence of missing values may lead to errors in the model results , Therefore, you can consider deleting the missing value 、 Mode or mean filling, etc .
2) outliers : Because it is far away from the observation point of the normal sample , Their existence will also affect the accuracy of the model . You can use quadrant diagram or 3sigma( Normal distribution ) Judge , If it is , Consider deleting or processing separately .
3) Dimensional inconsistency : Models are susceptible to different dimensions , Therefore, we need to adopt standardized methods ( Normalization is usually used 、Normalization Something like that ) Transform the data .
4) Dimension disaster : When the data set contains hundreds or even tens of millions of variables , It often increases the complexity of the model , Thus affecting the operation efficiency of the model , So we need to use analysis of variance 、 Correlation analysis 、 Principal component analysis and other means to achieve dimensionality reduction .
3.4 Build a model
In general , Preprocessing will occupy the whole data mining process 80% About time . In ensuring data “ clean ” Under the premise of , You need to choose the right model . The following are commonly used machine algorithms .
1) Classification model :KNN、 Decision tree 、 Logical regression, etc .
2) The regression model : Linear regression 、 Ridge return 、 Support vector regression, etc .
3) Unsupervised model :k-means etc. .
Most models in data mining are not specially designed to solve a certain problem , Models are not mutually exclusive . It cannot be said that a problem can only adopt a certain model , Nothing else can be used . Generally speaking , For a data analysis project , There is no such thing as the best model , Before deciding which model to choose , Try all kinds of models , Then choose a better . Various models in different environments , The advantages and disadvantages will be different .
3.5 Evaluation model
The evaluation stage is mainly to evaluate the modeling results , The purpose is to choose the best model , Let this model better reflect the authenticity of the data . Not every modeling can meet our goals , Analyze the reasons for the poor results , Occasionally, I will return to the previous steps to redefine the mining process .
such as , For decision tree or logistic regression , Even if you do well in training , But the results in the test set are poor , It shows that the model has over fitting .
3.6 Model deployment
The established model needs to solve practical problems , It also includes supervision 、 The process of generating reports and re evaluating models . Modeling is often used spss、python、r etc. , In the process of modeling, only the usability of the model is considered , In the production environment, we usually use Java or C++ Wait for language to rewrite the model , So as to improve the operation performance .
I wish you all a happy Valentine's day !
边栏推荐
- How to purchase Google colab members in China
- Keepalived 设置不抢占资源
- 1147_ Makefile learning_ Target files and dependent files in makefile
- [combinatorics] recursive equation (case where the non-homogeneous part is exponential | example where the non-homogeneous part is exponential)
- PUT vs. POST for Uploading Files - RESTful API to be Built Using Zend Framework
- Applet with multiple tabs and Swipers + paging of each tab
- 一入“远程”终不悔,几人欢喜几人愁。| 社区征文
- [教程]在 CoreOS 上构建你的第一个应用
- (9) Opencv Canny edge detection
- 1146_ SiCp learning notes_ exponentiation
猜你喜欢

Interviewer: why is the value nil not equal to nil?
Draw some simple graphics with MFC

win32:堆破坏的dump文件分析
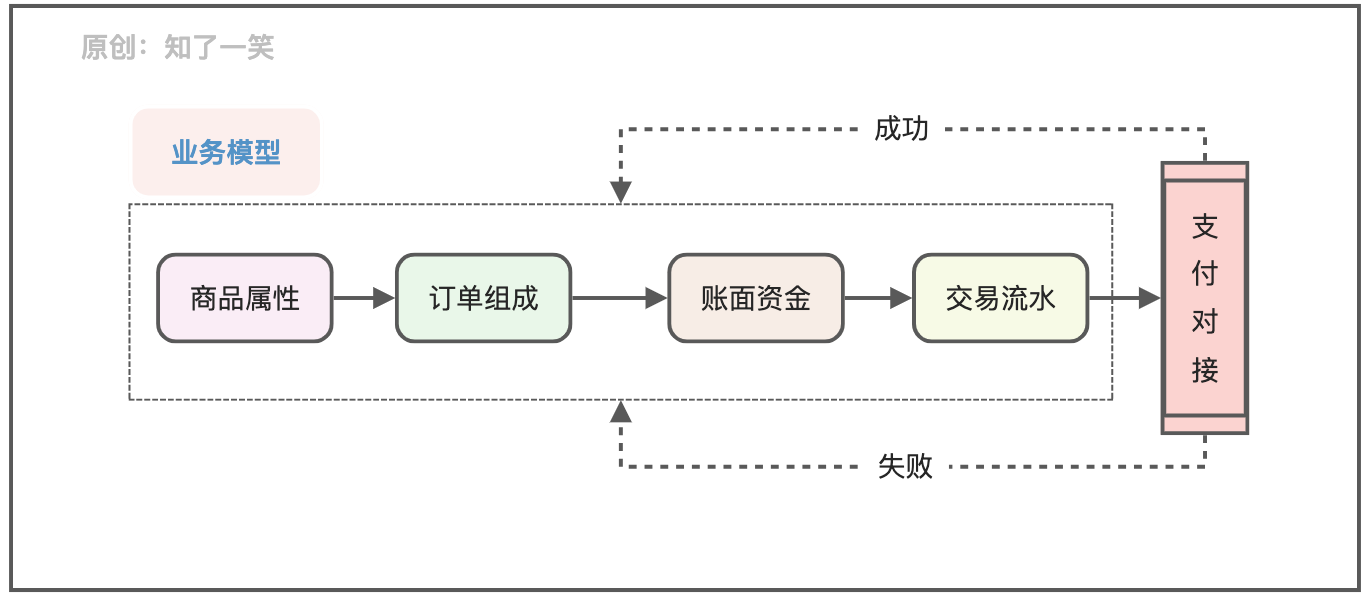
聊聊支付流程的设计与实现逻辑

TCP拥塞控制详解 | 3. 设计空间
模块九作业
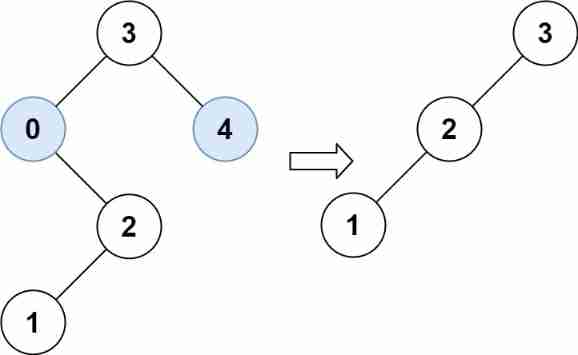
Leetcode 669 pruning binary search tree -- recursive method and iterative method
互联网医院HIS管理平台源码,在线问诊,预约挂号 智慧医院小程序源码
Notes on problems -- watching videos on edge will make the screen green
![[combinatorics] generating function (summation property)](/img/74/e6ef8ee69ed07d62df9f213c015f2c.jpg)
[combinatorics] generating function (summation property)
随机推荐
c# . Net tool ecosystem
[set theory] order relation: summary (partial order relation | partial order set | comparable | strictly less than | covering | hasto | total order relation | quasi order relation | partial order rela
小程序 多tab 多swiper + 每个tab分页
Redis core technology and practice - learning notes (VIII) sentinel cluster: sentinel hung up
Five problems of database operation in commodity supermarket system
Write a program to process a list container of string type. Find a special value in the container 9.27: and delete it if found. Rewrite the above procedure with deque container.
Research Report on investment trends and development planning of China's thermal insulation material industry, 2022-2028
Gear2021 monthly update - December
The gbase 8A database does not support the DB2 function value (column_name, 0) cluster syntax
远程办公工具分享|社区征文
PHP MySQL Update
Talk about the design and implementation logic of payment process
Inheritance of ES6 class
[combinatorics] recursive equation (the non-homogeneous part is an exponential function and the bottom is the characteristic root | example of finding a special solution)
PHP MySQL create database
Classroom attendance system based on face recognition tkinter+openpyxl+face_ recognition
As soon as we enter "remote", we will never regret, and several people will be happy and several people will be sad| Community essay solicitation
Global and Chinese pediatric palliative care drug market development research and investment planning recommendations report 2022-2028
Web-ui automated testing - the most complete element positioning method
(9) Opencv Canny edge detection