当前位置:网站首页>Introduction to redis cluster
Introduction to redis cluster
2022-06-12 05:24:00 【Cloud sunwenbo】
- 0、 Comparison of several common modes
- One 、redis cluster What is it?
- Two 、 Cluster architecture
- 3、 ... and 、 Cluster schematic diagram
- Four 、 Cluster communication
- 5、 ... and 、 Cluster concept
- 6、 ... and 、 Cluster health check mechanism
- 7、 ... and 、 Recommended clients for each language
0、 Comparison of several common modes
Pattern | edition | advantage | shortcoming |
|---|---|---|---|
| A master-slave mode | redis2.8 Before | 1、 Solve the problem of data backup 2、 Separation of reading and writing , Improve server performance | 1、master fault , Unable to auto failover , Manual intervention is required 2、master Unable to achieve dynamic expansion |
| Sentinel mode | redis2.8 Mode after level | 1、Master Condition monitoring 2、master Node failure , Automatically switch between master and slave , Fault self healing 3、 all slave From the node , Change the new master node | 1、slave Node offline ,sentinel There will be no failover of one , The client connecting to the slave node cannot get a new available slave node 2、master Unable to implement dynamic capacity expansion |
| redis cluster Pattern | redis3.0 After the version | 1、 It works redis The need for distribution 2、 Encountered stand-alone memory , Concurrency and traffic bottlenecks , May adopt Cluster The scheme achieves the goal of load balancing 3、 It can realize dynamic capacity expansion 4、P2P Pattern , No center 5、 adopt Gossip Protocol synchronization node information 6、 Automatic failover 、Slot Data available during migration 7、 Automatically segment data to different nodes 8、 If some nodes of the whole cluster fail or are unreachable, they can continue to process commands | 1、 The architecture is relatively new , There are few best practices 2、 In order to improve performance , The client needs to cache the routing table information 3、 Node found 、reshard The operation is not automated enough 4、 Processing multiple... Is not supported keys The order of , Because it requires moving data between different nodes 5、Redis A cluster is not like a single machine Redis That supports multiple database functions , Clusters use only the default |
One 、redis cluster What is it?
Redis A cluster is a cluster made up of Multiple master-slave node groups A distributed service cluster , It has Copy 、 High availability and fragmentation characteristic .Redis Clusters do not need sentinel Sentinels can also perform node removal and failover functions . You need to set each node to cluster mode , There is no central node in this cluster mode , Scalable horizontally , According to official documents, it can be linearly extended to tens of thousands of nodes ( The official recommendation is no more than 1000 Nodes ).redis Cluster performance and high availability are better than the previous version of sentinel mode , And the cluster configuration is very simple .redis Cluster is mainly used for massive data + High concurrency + Highly available scenarios .
Two 、 Cluster architecture
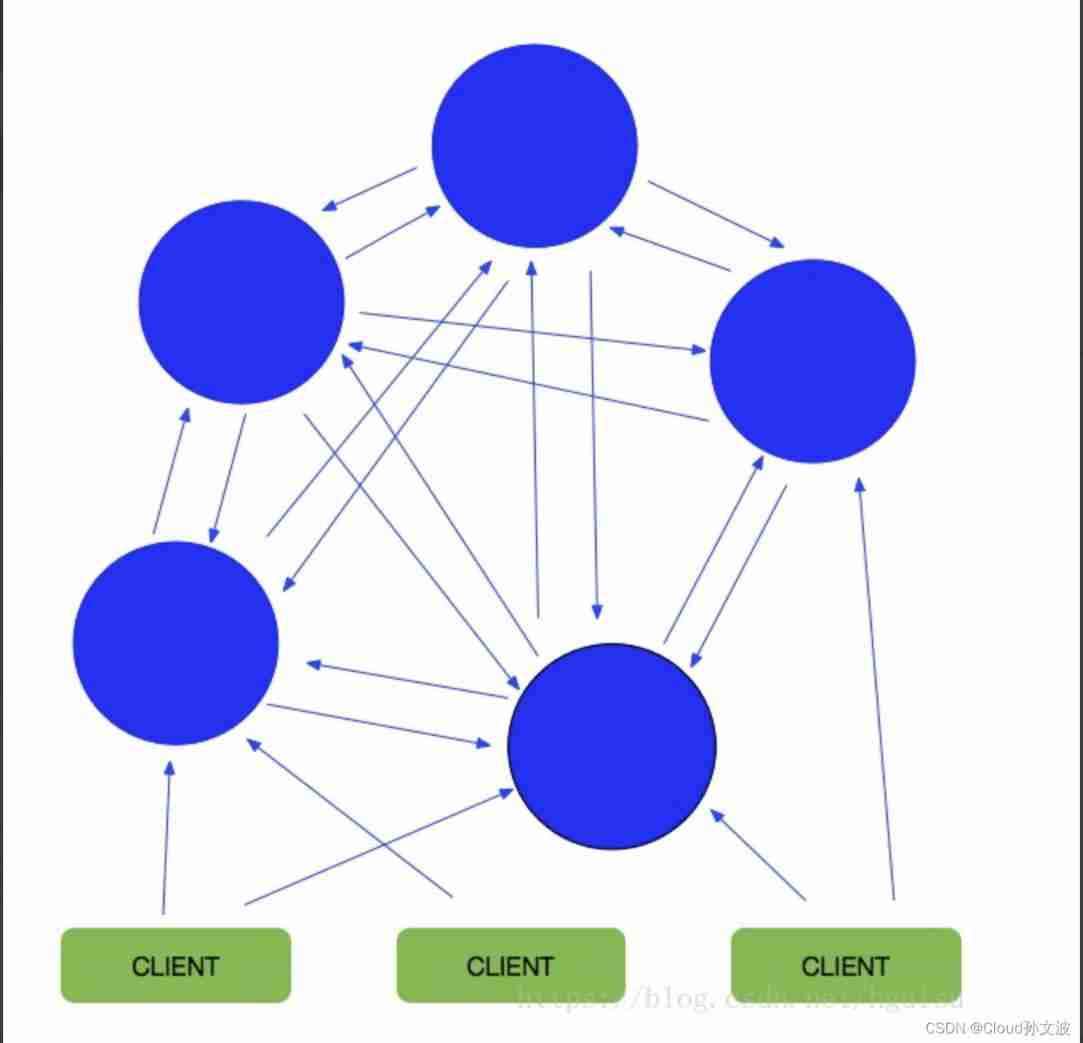
In this picture , Every blue circle represents a redis Server node of . Any two of them are connected to each other . The client can connect to any node , Then you can access any node in the cluster . Access to it and other operations
3、 ... and 、 Cluster schematic diagram

Introduce :
Object to save to redis Go through before CRC16 Hash to a specified Node On ( This process is redis cluster The fragmentation of ), Inside the cluster, all the key Mapping to 16384 individual Slot in , Each of the clusters Redis Instance Responsible for a part of it Slot Read and write . Cluster clients connect to any of the clusters Redis Instance You can send commands , When Redis Instance Receive what you are not responsible for Slot The request of , Will be responsible for the request Key Where Slot Of Redis Instance Address returned to client , The client automatically resends the original request to this address after receiving it , Transparent to the outside . One Key Which is it Slot from (HASH_SLOT = CRC16(key) mod 16384) decision . Only master Nodes are assigned slots ,slave Nodes do not allocate slots .
Four 、 Cluster communication
1) Cluster discovery :MEET

The very beginning , Every redis The instance itself is a cluster , We go through cluster meet Let the nodes interact with each other “ handshake ”, You need to continue to build a truly working cluster , We have to connect the nodes , Forming a cluster with multiple nodes . Connect the working use of each node CLUSTER MEET Order to complete .
CLUSTER MEET Command implementation :
1) node A Will be for the node B Create a clusterNode structure , And add the structure to your own clusterState.nodes In the dictionary .
2) node A according to CLUSTER MEET The command is given IP Address and port number , To the node B Send a MEET news .
3) node B Received node A Sent MEET news , node B Will be for the node A Create a clusterNode structure , And add the structure to your own clusterState.nodes In the dictionary .
4) node B To the node A Return a PONG news .
5) node A Will be affected by the node B Back to PONG news , Through this article PONG Message node A You can know the node B You have successfully received your own MEET news .
6) after , node A To the node B Return a PING news .
7) node B The received nodes A Back to PING news , Through this article PING Message node B You can know the node A Has successfully received their own return PONG news , The handshake is complete .
8) after , node A The node will be B Information through Gossip The protocol is propagated to other nodes in the cluster , Let other nodes also be associated with nodes B A handshake , Final , After a period of time , node B Will be recognized by all nodes in the cluster .
2)gossip agreement
gossip Protocol contains multiple messages , contain ping、pong、meet、fail etc.
1)meet: A node internally sent a gossip meet Message to newly added node , Notify that node to join our cluster . Then the new node will join the communication of the cluster
2)ping: Each node will send to other nodes frequently ping, It contains its own state and cluster metadata maintained by itself , Through each other ping Exchange metadata
3)pong:ping and meet The return response of the message , Contains your own status and other information , Also used for information broadcast and update
4)fail: One node judges another fail after , Is sent fail To other nodes , Notify other nodes that this node is down
5、 ... and 、 Cluster concept
1) many slave The election
The process of selecting a new owner is based on Raft It's achieved by agreement election
1) When the slave node finds that its master node is offline , The slave node will broadcast a CLUSTERMSG_TYPE_FAILOVER_AUTH_REQUEST news , Ask all to receive this message , And the master node with voting right votes to the slave node
2) If a primary node has voting rights , And this master node has not yet voted for other slave nodes , Then the main node will return a... To the slave node requesting the vote ,CLUSTERMSG_TYPE_FAILOVER_AUTH_ACK news , Indicates that the master node supports the slave node to become a new master node
3) Every slave node participating in the election will receive CLUSTERMSG_TYPE_FAILOVER_AUTH_ACK news , And according to how many messages you receive, count how many primary nodes you get
4) If there is N Primary nodes with voting rights , So when a cluster that collects data from a node is greater than or equal to N/2+1 When there are support tickets , The slave node becomes the new master node
5) If enough support votes are not collected in an election cycle , Then the cluster enters a new election cycle , And choose the master again , Until a new master node is selected
2)slot( Slot )
Redis Cluster There is one of them. 16384 The concept of slot length , Their number is 0、1、2、3……16382、16383. This slot is a virtual slot , It's not really there . When it's working properly ,Redis Cluster Each of the Master Nodes are responsible for a part of the slot , When there is one key To be mapped to Master Responsible tank , So this Master Responsible for this key Provide services , As for which Master Which slot is the node responsible for , This can be specified by the user , It can also be generated automatically during initialization (redis-trib.rb Script ). It's worth mentioning here , stay Redis Cluster in , Only Master To own the slot , If it's some Master Of slave, This slave Only responsible for the use of the slot , But there's no ownership .
3) Data fragmentation
stay Redis Cluster in , Have 16384 individual slot, This number is fixed , Stored in Redis Cluster All the keys in are mapped to these slot in . Every key in the database belongs here 16384 One of the hash slots , The cluster uses the formula CRC16(key) % 16384 To calculate the key key Which slot does it belong to , among CRC16(key) Statements are used to evaluate keys key Of CRC16 The checksum . Each node in the cluster is responsible for processing a portion of the hash slots .
4) request redirections
Because each node is only responsible for part of slot, as well as slot It's possible to migrate from one node to another , As a result, the client may send a request to the wrong node . So there needs to be a mechanism to discover and fix it , This is request redirection . There are two different redirection scenarios :
a)MOVED error
1. Requested key The corresponding slot is not on the node , The node will view the hash slot saved in itself to the node ID Mapping records for , The node replies with a MOVED error .
2. The client needs to try again .
b)ASK error ( It usually occurs in the process of data migration )
1. Requested key The current status of the corresponding slot belongs to MIGRATING state , And the current node can't find this key 了 , Node back to complex ASK error .ASK It's going to take the corresponding slot IMPORTING The node returns to you , I'll tell you to IMPORTING Try to find .
2. The client tries again and sends ASKING command , The node will set a one-time flag for the client (flag), bring The client can perform a test for IMPORTING Status slot command request , Then send the real command request .
3. There is no need to update the slot to node mapping recorded by the client .
5) Data migration
When slot x from Node A towards Node B When moving ,Node A and Node B There will be this slot x,Node A The upper trough x Is set to MIGRATING,Node B The upper trough x Is set to IMPORTING.
MIGRATING state
1) If key If it exists, it will be processed successfully
2) If key non-existent , Then return to the client ASK, Client according to ASK First send ASKING Command to the target node , Then send the requested command to the target node
3) When key Contains multiple commands ,
a) If both exist, it will be processed successfully
b) If none of them exist , Then return to the client ASK
c) If part of it exists , Then return to the client TRYAGAIN, Notify client to try again later , So when all the key When the migration is completed, the client will retrieve the request when retrying ASK, And then after a redirection You can get these keys
4) Do not refresh the client at this time node The mapping relation of
IMPORTING state
1) If key Not on this node , Will be MOVED Redirect , Refresh the client node The mapping relation of
2) If it is ASKING The command will be executed ,key The node that is not being migrated has been migrated to the target node
3)Key If it doesn't exist, create a new one
6) Fail over
When the slave node finds that its master node is offline (FAIL) In the state of , I try to enter Failover, In order to become a new master .
Here are the steps to perform failover :
1) Select a slave node from all the slave nodes of the offline master node
2) The selected slave node performs SLAVEOF NO NOE command , Becomes the new master node
3) The new master node will cancel all slot assignments to the offline master node , And assign all these slots to yourself
4) The new master node broadcasts to the cluster PONG news , Tell the other nodes that they have become the new master
5) The new master node begins to receive and process slot related requests
7) colony slots Is it necessary to be complete to provide external services
When redis.conf Configuration of cluster-require-full-coverage by no when , Indicates that when the primary library responsible for a slot is offline and there is no corresponding slave library for failure recovery , Clusters are still available , If yes The cluster is not available .
6、 ... and 、 Cluster health check mechanism
1、 Each node of the cluster sends an active message to each other ping package , When ping The return time of package confirmation exceeds node_timeout Time for , We believe that nodes fail
2、 Of course , When the node is waiting for more than half of the time node_timeout Has not received the target node for ping When the package replies , Will immediately try to reconnect the node , This mechanism ensures that all links are valid , Therefore, failure links between nodes will not lead to false failure reports
3、 The node goes from normal state to fail state , Each node pair needs to be collected for abnormal nodes (B) The confirmation of :1) When node (A) Sent ping The package did not return , At this time will be B The status information of the node is marked as (PFAIL) state , Then send the information to other nodes of the cluster , In the same way A Collect local information about B Information about status , When most primary nodes think B Node is PFAIL In the state of , node A Will mark B The status of is FAIL state , Then send this message to all reachable nodes
4、 When most primary nodes will B Nodes are marked as FAIL In the state of ,B Nodes are finally marked by the cluster as FAIL state , here B1(B The slave node ) Promotion provides services for the main node
5、 In essence ,FAIL The identity is only used to trigger the promotion of slave nodes (slave promotion) The security part of the algorithm . Theoretically, a slave node will act independently and start the slave node promotion program when its master node is not reachable , Then wait for the master node to reject the promotion ( If the master node restores the connection to most nodes ).PFAIL -> FAIL The state of change 、 Weak protocol 、 Force the propagation of state changes in the reachable part of the cluster in the shortest time FAIL news , The added complexity of these things has practical benefits . Because of this mechanism , If the cluster is in an error state , All nodes will stop receiving write operations at the same time , This starts with the use of Redis Cluster application is a good feature . There are also unnecessary elections , It is initiated when the slave node cannot access the master node , If this master node can be accessed by most other master nodes , This election will be rejected
边栏推荐
- Variables and data types
- JS controls the display and hiding of tags through class
- It costs less than 30 yuan, but we still don't build it quickly - check the small knowledge of software application
- Overview of common classes
- [backtracking] backtracking to solve subset problems
- Computer network connected but unable to access the Internet
- Enhanced vegetation index evi, NDVI data, NPP data, GPP data, land use data, vegetation type data, rainfall data
- How to deploy dolphin scheduler 1.3.1 on cdh5
- Radiometric calibration and atmospheric correction of sentry 2 L1C multispectral data using sen2cor
- 43. Number of occurrences of 1 in 1 ~ n integers
猜你喜欢

Introduction to audio alsa architecture

Why is Julia so popular?
Some problems of silly girl solved

Acquisition of Lai data, NPP data, GPP data and vegetation coverage data

How to generate provincial data from county-level data in ArcGIS?

Transpiration and evapotranspiration (ET) data, potential evapotranspiration, actual evapotranspiration data, temperature data, rainfall data

The most commonly used objective weighting method -- entropy weight method

Thingsboard create RCP widget
How to quickly reference uview UL in uniapp, and introduce and use uviewui in uni app

How Bi makes SaaS products have a "sense of security" and "sensitivity" (Part I)
随机推荐
[backtracking] backtracking to solve subset problems
It costs less than 30 yuan, but we still don't build it quickly - check the small knowledge of software application
IC验证中的force/release 学习整理(6)研究对 wire 类型信号的影响
38. arrangement of strings
Stm32f4 ll library multi-channel ADC
Sentinel-2 data introduction and download
Thingsboard create RCP widget
Enhanced vegetation index evi, NDVI data, NPP data, GPP data, land use data, vegetation type data, rainfall data
Reason: Canonical names should be kebab-case (‘-‘ separated), lowercase alpha-numeric characters and
When the build When gradle does not load the dependencies, and you need to add a download path in libraries, the path in gradle is not a direct downloadable path
Pupanvr- an open source embedded NVR system (1)
Pupanvr hardware and software board side development environment configuration (4)
week7
Chapter 1
Qinglong wool - Kaka
IC验证中的force/release 学习整理(5)研究对 reg类型信号的影响
Detailed analysis of the 2021 central China Cup Title A (color selection of mosaic tiles)
Detailed tutorial on the use of yolov5 and training your own dataset with yolov5
国企为什么要上市
JS controls the display and hiding of tags through class