当前位置:网站首页>Pytorch模型训练实用教程学习笔记:一、数据加载和transforms方法总结
Pytorch模型训练实用教程学习笔记:一、数据加载和transforms方法总结
2022-08-01 19:16:00 【zstar-_】
前言
最近在重温Pytorch基础,然而Pytorch官方文档的各种API是根据字母排列的,并不适合学习阅读。
于是在gayhub上找到了这样一份教程《Pytorch模型训练实用教程》,写得不错,特此根据它来再学习一下Pytorch。
仓库地址:https://github.com/TingsongYu/PyTorch_Tutorial
数据集转换
首先练习对数据集的处理方式。
这里采用的是cifar-10数据集,从官网下载下来的格式长这样:
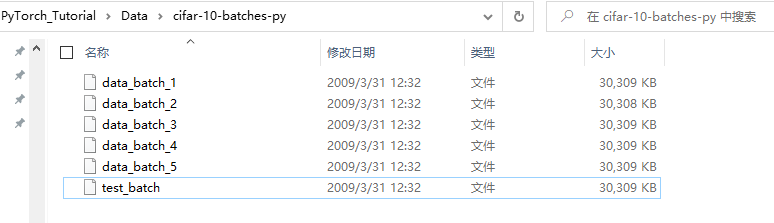
data_batch_1-5是训练集,test_batch是测试集。
这种形式不利于直观阅读,因此利用pickle来对其进行转换,转换成png格式。
另附cifar-10数据集备份:https://pan.baidu.com/s/1uxQ7RGjLChe99fpiotM7jw?pwd=8888
转换代码
# coding:utf-8
""" 将cifar10的data_batch_12345 转换成 png格式的图片 每个类别单独存放在一个文件夹,文件夹名称为0-9 """
from imageio import imwrite
import numpy as np
import os
import pickle
data_dir = os.path.join("..", "..", "Data", "cifar-10-batches-py")
train_o_dir = os.path.join("..", "..", "Data", "cifar-10-png", "raw_train")
test_o_dir = os.path.join("..", "..", "Data", "cifar-10-png", "raw_test")
# 解压缩,返回解压后的字典
def unpickle(file):
with open(file, 'rb') as fo:
dict_ = pickle.load(fo, encoding='bytes')
return dict_
def my_mkdir(my_dir):
if not os.path.isdir(my_dir):
os.makedirs(my_dir)
if __name__ == '__main__':
# 生成训练集图片
for j in range(1, 6):
data_path = os.path.join(data_dir, "data_batch_" + str(j)) # data_batch_12345
train_data = unpickle(data_path)
print(data_path + " is loading...")
for i in range(0, 10000):
img = np.reshape(train_data[b'data'][i], (3, 32, 32))
img = img.transpose(1, 2, 0) # (channels,imagesize,imagesize)转换成(imagesize,imagesize,channels)
label_num = str(train_data[b'labels'][i])
o_dir = os.path.join(train_o_dir, label_num)
my_mkdir(o_dir)
img_name = label_num + '_' + str(i + (j - 1) * 10000) + '.png'
img_path = os.path.join(o_dir, img_name)
imwrite(img_path, img)
print(data_path + " loaded.")
print("test_batch is loading...")
# 生成测试集图片
test_data_path = os.path.join(data_dir, "test_batch")
test_data = unpickle(test_data_path)
for i in range(0, 10000):
img = np.reshape(test_data[b'data'][i], (3, 32, 32))
img = img.transpose(1, 2, 0)
label_num = str(test_data[b'labels'][i])
o_dir = os.path.join(test_o_dir, label_num)
my_mkdir(o_dir)
img_name = label_num + '_' + str(i) + '.png'
img_path = os.path.join(o_dir, img_name)
imwrite(img_path, img)
print("test_batch loaded.")
转换后的数据集长这样:
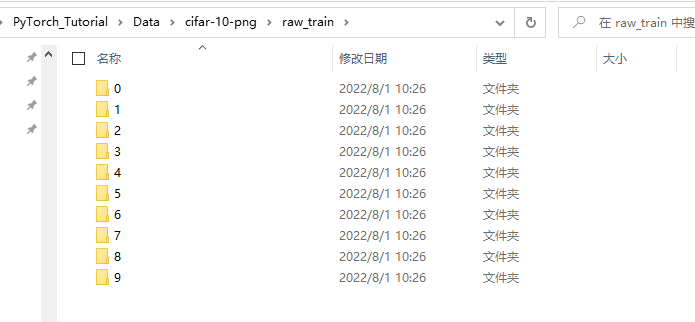

注:cifar-10共有10个类别,每张图片大小为32x32像素。
数据集划分
下面对数据集划分,这里只是为了演示学习,因此仅对原本的测试集数据进行划分,划分比例为8:1:1。
代码:
# coding: utf-8
""" 将原始数据集进行划分成训练集、验证集和测试集 """
import os
import glob
import random
import shutil
dataset_dir = os.path.join("..", "..", "Data", "cifar-10-png", "raw_test")
train_dir = os.path.join("..", "..", "Data", "train")
valid_dir = os.path.join("..", "..", "Data", "valid")
test_dir = os.path.join("..", "..", "Data", "test")
train_per = 0.8
valid_per = 0.1
test_per = 0.1
def makedir(new_dir):
if not os.path.exists(new_dir):
os.makedirs(new_dir)
if __name__ == '__main__':
for root, dirs, files in os.walk(dataset_dir):
for sDir in dirs:
imgs_list = glob.glob(os.path.join(root, sDir, '*.png')) # glob匹配路径,匹配所有png格式图片
random.seed(666)
random.shuffle(imgs_list)
imgs_num = len(imgs_list)
train_point = int(imgs_num * train_per)
valid_point = int(imgs_num * (train_per + valid_per))
for i in range(imgs_num):
if i < train_point:
out_dir = os.path.join(train_dir, sDir)
elif i < valid_point:
out_dir = os.path.join(valid_dir, sDir)
else:
out_dir = os.path.join(test_dir, sDir)
makedir(out_dir)
out_path = os.path.join(out_dir, os.path.split(imgs_list[i])[-1])
shutil.copy(imgs_list[i], out_path)
print('Class:{}, train:{}, valid:{}, test:{}'.format(sDir, train_point, valid_point-train_point, imgs_num-valid_point))
划分好的数据如图所示:
数据集加载文件
通常来说,数据加载都是通过txt文件进行路径读取,在我之前的博文【目标检测】YOLOv5跑通VOC2007数据集(修复版)也实现过这一效果,这里不作赘述。
代码:
# coding:utf-8
import os
''' 为数据集生成对应的txt文件 '''
train_txt_path = os.path.join("..", "..", "Data", "train.txt")
train_dir = os.path.join("..", "..", "Data", "train")
valid_txt_path = os.path.join("..", "..", "Data", "valid.txt")
valid_dir = os.path.join("..", "..", "Data", "valid")
def gen_txt(txt_path, img_dir):
f = open(txt_path, 'w')
for root, s_dirs, _ in os.walk(img_dir, topdown=True): # 获取 train文件下各文件夹名称
for sub_dir in s_dirs:
i_dir = os.path.join(root, sub_dir) # 获取各类的文件夹 绝对路径
img_list = os.listdir(i_dir) # 获取类别文件夹下所有png图片的路径
for i in range(len(img_list)):
if not img_list[i].endswith('png'): # 若不是png文件,跳过
continue
label = img_list[i].split('_')[0]
img_path = os.path.join(i_dir, img_list[i])
line = img_path + ' ' + label + '\n'
f.write(line)
f.close()
if __name__ == '__main__':
gen_txt(train_txt_path, train_dir)
gen_txt(valid_txt_path, valid_dir)
生成结果:

构建Dataset
数据加载通常使用Pytorch提供的DataLoader,在此之前,需要构建自己的数据集类,在数据集类中,可以包含transform一些数据处理方式。
from PIL import Image
from torch.utils.data import Dataset
class MyDataset(Dataset):
def __init__(self, txt_path, transform=None, target_transform=None):
fh = open(txt_path, 'r')
imgs = []
for line in fh:
line = line.rstrip()
words = line.split()
imgs.append((words[0], int(words[1])))
self.imgs = imgs # 最主要就是要生成这个list, 然后DataLoader中给index,通过getitem读取图片数据
self.transform = transform
self.target_transform = target_transform
def __getitem__(self, index):
fn, label = self.imgs[index]
img = Image.open(fn).convert('RGB') # 像素值 0~255,在transfrom.totensor会除以255,使像素值变成 0~1
if self.transform is not None:
img = self.transform(img) # 在这里做transform,转为tensor等等
return img, label
def __len__(self):
return len(self.imgs)
注:在DataLoader中,会调用__getitem__方法,需要返回的是data+label的形式。
数据标准化
数据标准化(Normalize)是非常常见的数据处理方式,在Pytorch中的调用示例:
normMean = [0.4948052, 0.48568845, 0.44682974]
normStd = [0.24580306, 0.24236229, 0.2603115]
normTransform = transforms.Normalize(normMean, normStd)
注:这里的均值和标准差是需要自定义的。
下面这段程序就是随机读取CNum张图片,来计算三通道的均值和标准差。
# coding: utf-8
import numpy as np
import cv2
import random
import os
""" 随机挑选CNum张图片,进行按通道计算均值mean和标准差std 先将像素从0~255归一化至 0-1 再计算 """
train_txt_path = os.path.join("..", "..", "Data/train.txt")
CNum = 2000 # 挑选多少图片进行计算
img_h, img_w = 32, 32
imgs = np.zeros([img_w, img_h, 3, 1])
means, stdevs = [], []
with open(train_txt_path, 'r') as f:
lines = f.readlines()
random.shuffle(lines) # shuffle , 随机挑选图片
for i in range(CNum):
img_path = lines[i].rstrip().split()[0]
img = cv2.imread(img_path)
img = cv2.resize(img, (img_h, img_w))
img = img[:, :, :, np.newaxis]
imgs = np.concatenate((imgs, img), axis=3)
print(i)
imgs = imgs.astype(np.float32)/255.
for i in range(3):
pixels = imgs[:,:,i,:].ravel() # 拉成一行
means.append(np.mean(pixels))
stdevs.append(np.std(pixels))
means.reverse() # BGR --> RGB
stdevs.reverse()
print("normMean = {}".format(means))
print("normStd = {}".format(stdevs))
print('transforms.Normalize(normMean = {}, normStd = {})'.format(means, stdevs))
transforms方法汇总
对于数据处理,pytorch专门提供的transforms函数,该函数有下列一些方法可以使用。
裁剪——Crop
中心裁剪:transforms.CenterCrop
功能:依据给定的 size 从中心裁剪
参数:
size- (sequence or int),若为 sequence,则为(h,w),若为 int,则(size,size)
随机裁剪:transforms.RandomCrop
功能:依据给定的 size 随机裁剪
参数:
size- (sequence or int),若为 sequence,则为(h,w),若为 int,则(size,size)
padding-(sequence or int, optional),此参数是设置填充多少个 pixel。
当为 int 时,图像上下左右均填充 int 个,例如 padding=4,则上下左右均填充 4 个 pixel,若为 32x32,则会变成 40x40。当为 sequence 时,若有 2 个数,则第一个数表示左右扩充多少,第二个数表示上下的。当有 4 个数时,则为左,上,右,下。
fill- (int or tuple) 填充的值是什么(仅当填充模式为 constant 时有用)。int 时,各通道均填充该值,当长度为 3 的 tuple 时,表示 RGB 通道需要填充的值。
padding_mode- 填充模式,这里提供了 4 种填充模式,1.constant,常量。2.edge 按照图片边缘的像素值来填充。3.reflect。 4. symmetric。
随机长宽比裁剪:transforms.RandomResizedCrop
功能:随机大小,随机长宽比裁剪原始图片,最后将图片 resize 到设定好的 size
参数:
size- 输出的分辨率
scale- 随机 crop 的大小区间,如 scale=(0.08, 1.0),表示随机 crop 出来的图片会在的 0.08倍至 1 倍之间。
ratio- 随机长宽比设置
interpolation- 插值的方法,默认为双线性插值(PIL.Image.BILINEAR)
上下左右中心裁剪:transforms.FiveCrop
功能:对图片进行上下左右以及中心裁剪,获得 5 张图片,返回一个 4D-tensor
参数:
size- (sequence or int),若为 sequence,则为(h,w),若为 int,则(size,size)
上下左右中心裁剪后翻转,transforms.TenCrop
功能:对图片进行上下左右以及中心裁剪,然后全部翻转(水平或者垂直),获得 10 张图
片,返回一个 4D-tensor。
参数:
size- (sequence or int),若为 sequence,则为(h,w),若为 int,则(size,size)
vertical_flip (bool) - 是否垂直翻转,默认为 flase,即默认为水平翻转
翻转和旋转——Flip and Rotations
依概率 p 水平翻转:transforms.RandomHorizontalFlip(p=0.5)
功能:依据概率 p 对 PIL 图片进行水平翻转
参数:
p- 概率,默认值为 0.5
依概率 p 垂直翻转:transforms.RandomVerticalFlip(p=0.5)
功能:依据概率 p 对 PIL 图片进行垂直翻转
参数:
p- 概率,默认值为 0.5
随机旋转:transforms.RandomRotation
功能:依 degrees 随机旋转一定角度
参数:
degress- (sequence or float or int) ,若为单个数,如 30,则表示在(-30,+30)之间随机旋转,若为 sequence,如(30,60),则表示在 30-60 度之间随机旋转
图像变换
图像缩放:transforms.Resize
功能:重置图像分辨率
参数:
size- If size is an int, if height > width, then image will be rescaled to (size * height / width, size),所以建议 size 设定为 h*w
interpolation- 插值方法选择,默认为 PIL.Image.BILINEAR
标准化:transforms.Normalize
class torchvision.transforms.Normalize(mean, std)
功能:对数据按通道进行标准化,即先减均值,再除以标准差,注意是 h * w * c
转为 tensor,并归一化至[0-1]:transforms.ToTensor
功能:将 PIL Image 或者 ndarray 转换为 tensor,并且归一化至[0-1]
注意事项:归一化至[0-1]是直接除以 255,若自己的 ndarray 数据尺度有变化,则需要自行
修改。
填充:transforms.Pad
功能:对图像进行填充
参数:
padding-(sequence or int, optional),此参数是设置填充多少个 pixel。
当为 int 时,图像上下左右均填充 int 个,例如 padding=4,则上下左右均填充 4 个 pixel,若为 32x32,则会变成 40x40。
fill- (int or tuple) 填充的值是什么
padding_mode- 填充模式,这里提供了 4 种填充模式,1.constant,常量。2.edge 按照图片边缘的像素值来填充。3.reflect 4. symmetric
修改亮度、对比度和饱和度:transforms.ColorJitter
功能:修改修改亮度、对比度和饱和度
转灰度图:transforms.Grayscale
功能:将图片转换为灰度图
参数:
num_output_channels- (int) ,当为 1 时,正常的灰度图,当为 3 时, 3 channel with r == g == b
线性变换:transforms.LinearTransformation()
功能:对矩阵做线性变化
仿射变换:transforms.RandomAffine
功能:仿射变换
依概率 p 转为灰度图:transforms.RandomGrayscale
功能:依概率 p 将图片转换为灰度图,若通道数为 3,则 3 channel with r == g == b
将数据转换为 PILImage:transforms.ToPILImage
功能:将 tensor 或者 ndarray 的数据转换为 PIL Image 类型数据
参数:
mode- 为 None 时,为 1 通道, mode=3 通道默认转换为 RGB,4 通道默认转换为 RGBA
transforms操作
transforms.RandomChoice(transforms)
功能:从给定的一系列 transforms 中选一个进行操作
transforms.RandomApply(transforms, p=0.5)
功能:给一个 transform 加上概率,依概率进行操作
transforms.RandomOrder
功能:将 transforms 中的操作随机打乱
使用示例:
例如,想对数据进行缩放、随机裁剪、归一化和标准化,可以这样进行设置:
# 数据预处理设置
normMean = [0.4948052, 0.48568845, 0.44682974]
normStd = [0.24580306, 0.24236229, 0.2603115]
normTransform = transforms.Normalize(normMean, normStd)
trainTransform = transforms.Compose([
transforms.Resize(32),
transforms.RandomCrop(32, padding=4),
transforms.ToTensor(),
normTransform
])
train_data = MyDataset(txt_path=train_txt_path, transform=trainTransform)
边栏推荐
猜你喜欢






随机推荐
explain each field introduction
Prometheus's Recording rules practice
[National Programming] "Software Programming - Lecture Video" [Zero Basic Introduction to Practical Application]
文库网站建设源码分享
When compiling a program with boost library with VS2013, it prompts fatal error C1001: An internal error occurred in the compiler
How to install voice pack in Win11?Win11 Voice Pack Installation Tutorial
手撸代码,Redis发布订阅机制实现
不要再使用MySQL online DDL了
Win11如何开启剪贴板自动复制?Win11开启剪贴板自动复制的方法
easyUI中datagrid中的formatter里面向后台发送请求获取数据
Keras deep learning practice - traffic sign recognition
Map by value
经验共享|在线文档协作:企业文档处理的最佳选择
[Server data recovery] Data recovery case of offline multiple disks in mdisk group of server Raid5 array
安徽建筑大学&杭州电子科技大学|基于机器学习方法的建筑可再生能源优化控制
【LeetCode】Day109-the longest palindrome string
explain 各字段介绍
突破边界,华为存储的破壁之旅
屏:全贴合工艺之GFF、OGS、Oncell、Incell
Tencent Cloud Hosting Security x Lightweight Application Server | Powerful Joint Hosting Security Pratt & Whitney Version Released