当前位置:网站首页>【Pytorch学习笔记】11.取Dataset的子集、给Dataset打乱顺序的方法(使用Subset、random_split)
【Pytorch学习笔记】11.取Dataset的子集、给Dataset打乱顺序的方法(使用Subset、random_split)
2022-08-05 05:15:00 【takedachia】
(pytorch版本:1.2)
我们在使用Dataset定义好数据集后,在处理数据集时经常会碰到这些问题:如何把Dataset拆分成两个子集(如用于指定训练集和测试集、k折交叉验证等)?如何进行随机拆分?如何打乱一个Dataset内数据的顺序?
Dataset取子集、拆分
使用 torch.utils.data.Subset() 可对数据集取子集。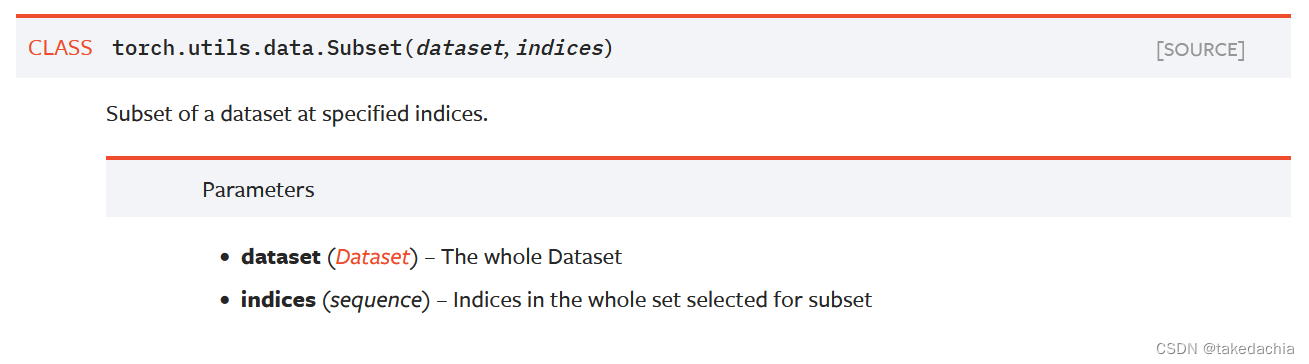
传入一个Dataset,一个序列切片indices,即可得到一个子集。
1.我们可以传入一个range():
indices = range(18353) # 取标号为第0个到第18352个数据
sub_imgs = torch.utils.data.Subset(imgs, indices)
len(imgs), len(sub_imgs)

2.可以取区间:
indices = range(18353, 27153) # 取标号为第18353个到第27152个数据
sub_imgs = torch.utils.data.Subset(imgs, indices)
len(imgs), len(sub_imgs)

3.可以传入一个List。有List就可以用列表生成式:
indices = [x for x in range(1234)]
sub_imgs = torch.utils.data.Subset(imgs, indices)
len(imgs), len(sub_imgs)

打乱Dataset内数据的顺序
我们可以直接传入一个乱序的index就可以达到数据集乱序的目的:
from torch import randperm
lenth = randperm(len(Leaf_dataset_train)).tolist() # 生成乱序的索引
rand_train = torch.utils.data.Subset(imgs, lenth)
# 显示一下第一张图片、原标号
X = rand_train[0]
plt.imshow(torch.transpose(X[0],0,2)), lenth[0]
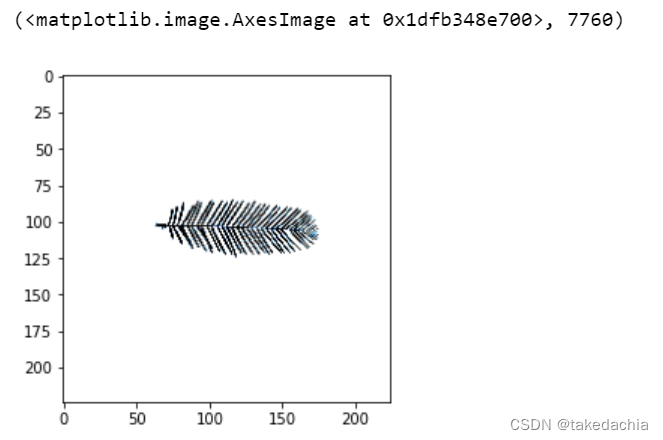
我们在打乱顺序后就可以取子集对数据集进行k折交叉验证等行为。
随机拆分Dataset
使用 torch.utils.data.random_split() 可直接对数据集进行拆分,随机分成多份。
可以传入一个List,注意传入的List序列中包含每个子集的大小(数量),且这几个数的和必须等于传入Dataset的长度。
示例:
# 这里Leaf_dataset_train的大小必须等于 17000+1353
train_set, test_set = torch.utils.data.random_split(Leaf_dataset_train, [17000, 1353])
print(len(train_set), len(test_set))

边栏推荐
猜你喜欢


随机推荐
Flink Oracle CDC写入到HDFS
flink on yarn 集群模式启动报错及解决方案汇总
Redux
【过一下12】整整一星期没记录
【过一下11】随机森林和特征工程
JSX基础
AWS 常用服务
day12函数进阶作业
LeetCode: 1403. Minimum subsequence in non-increasing order [greedy]
spark-DataFrame数据插入mysql性能优化
第三讲 Gradient Tutorial梯度下降与随机梯度下降
Pycharm中使用pip安装第三方库安装失败:“Non-zero exit code (2)“的解决方法
学习总结week2_2
实现跨域的几种方式
基于Flink CDC实现实时数据采集(四)-Sink接口实现
如何跟踪网络路由链路&检测网络健康状况
day8字典作业
Web Component-处理数据
The software design experiment four bridge model experiment
spingboot 容器项目完成CICD部署