当前位置:网站首页>spark-DataFrame数据插入mysql性能优化
spark-DataFrame数据插入mysql性能优化
2022-08-05 05:14:00 【IT_xhf】
简介
最近在公司项目有使用spark做数据处理,数据的结果要求写入到mysql或者tidb。spark在做完一系列的rdd操作后得到的结果通过jdbc方式插入到数据,但是插入的数据非常慢。开始研究这一块的代码和寻找性能优化。
结果插入mysql
spark给我们做了封装,插入mysql的代码使用非常简单,直接调用spark的API即可
df.write.mode(SaveMode.Append).format("jdbc")
.option("url",getValueOfPrefix(prefix,"url")) // 数据库连接地址
.option("isolationLevel","NONE") // 不开启事务
.option(JDBCOptions.JDBC_BATCH_INSERT_SIZE,150) // 设置批次大小
.option("dbtable", tableName) // 插入的表
.option("user",getValueOfPrefix(prefix,"username")) // 数据库用户名
.option("password",getValueOfPrefix(prefix,"password")) // 数据库密码
.save()
以上代码,运行的速度有点慢,插入几千的记录大概要话费2分钟左右,后来网上找了一些资料。原因很简单,这并没有开启批次插入,虽然代码设置了,但是数据层面没有开启批次查询,需要在数据库连接后再增加一个参数rewriteBatchedStatements=true//启动批处理操作
db.url= "jdbc:mysql://localhost:3306/User? rewriteBatchedStatements=true";
设置完这个参数后,插入几千条记录基本就是秒杀。
源代码解析总结
首先DataFrame会调用write方法,该方法返回一个org.apache.spark.sql.DataFrameWriter对象,这个对象的所有属性设置方法都采用链操作技术方式(设置完成属性后,返回this)
def write: DataFrameWriter[T] = {
if (isStreaming) {
logicalPlan.failAnalysis(
"'write' can not be called on streaming Dataset/DataFrame")
}
new DataFrameWriter[T](this)
}
设置完插入属性后,调用save()方法,去执行结果保存。在save方法中,创建了org.apache.spark.sql.execution.datasources.DataSource对象,通过调用DataSource对象的write(mode, df)方法完成保存数据的操作。
def save(): Unit = {
assertNotBucketed("save")
val dataSource = DataSource(
df.sparkSession,
className = source,
partitionColumns = partitioningColumns.getOrElse(Nil),
bucketSpec = getBucketSpec,
options = extraOptions.toMap)
dataSource.write(mode, df)
}
write方法做了2件事情,判断结果保存到数据库,还是保存到文件系统,本次跟踪的是保存结果到数据。
def write(mode: SaveMode, data: DataFrame): Unit = {
if (data.schema.map(_.dataType).exists(_.isInstanceOf[CalendarIntervalType])) {
throw new AnalysisException("Cannot save interval data type into external storage.")
}
providingClass.newInstance() match {
case dataSource: CreatableRelationProvider =>
dataSource.createRelation(sparkSession.sqlContext, mode, caseInsensitiveOptions, data) // 保存到数据库
case format: FileFormat =>
writeInFileFormat(format, mode, data)
case _ =>
sys.error(s"${providingClass.getCanonicalName} does not allow create table as select.")
}
}
}
org.apache.spark.sql.sources.CreatableRelationProvider#createRelation是一个接口,他的实现在org.apache.spark.sql.execution.datasources.jdbc.JdbcRelationProvider#createRelation
override def createRelation(
sqlContext: SQLContext,
mode: SaveMode,
parameters: Map[String, String],
df: DataFrame): BaseRelation = {
val jdbcOptions = new JDBCOptions(parameters)
val url = jdbcOptions.url
val table = jdbcOptions.table
val createTableOptions = jdbcOptions.createTableOptions
val isTruncate = jdbcOptions.isTruncate
val conn = JdbcUtils.createConnectionFactory(jdbcOptions)()
try {
val tableExists = JdbcUtils.tableExists(conn, url, table)
if (tableExists) {
mode match {
case SaveMode.Overwrite =>
if (isTruncate && isCascadingTruncateTable(url) == Some(false)) {
// In this case, we should truncate table and then load.
truncateTable(conn, table)
saveTable(df, url, table, jdbcOptions)
} else {
// Otherwise, do not truncate the table, instead drop and recreate it
dropTable(conn, table)
createTable(df.schema, url, table, createTableOptions, conn)
saveTable(df, url, table, jdbcOptions)
}
case SaveMode.Append =>
saveTable(df, url, table, jdbcOptions)
case SaveMode.ErrorIfExists =>
throw new AnalysisException(
s"Table or view '$table' already exists. SaveMode: ErrorIfExists.")
case SaveMode.Ignore =>
// With `SaveMode.Ignore` mode, if table already exists, the save operation is expected
// to not save the contents of the DataFrame and to not change the existing data.
// Therefore, it is okay to do nothing here and then just return the relation below.
}
} else {
createTable(df.schema, url, table, createTableOptions, conn)
saveTable(df, url, table, jdbcOptions)
}
} finally {
conn.close()
}
createRelation(sqlContext, parameters)
}
最后通过org.apache.spark.sql.execution.datasources.jdbc.JdbcUtils#saveTable函数完成数据的插入。
def saveTable(
df: DataFrame,
url: String,
table: String,
options: JDBCOptions) {
val dialect = JdbcDialects.get(url)
val nullTypes: Array[Int] = df.schema.fields.map {
field =>
getJdbcType(field.dataType, dialect).jdbcNullType
}
val rddSchema = df.schema
val getConnection: () => Connection = createConnectionFactory(options)
val batchSize = options.batchSize
val isolationLevel = options.isolationLevel
df.foreachPartition(iterator => savePartition(
getConnection, table, iterator, rddSchema, nullTypes, batchSize, dialect, isolationLevel)
)
}
可以看到,DataFrame调用foreachPartition函数,进行分区插入操作,真正完成插入的是在savePartition,函数中 。
def savePartition(
getConnection: () => Connection,
table: String,
iterator: Iterator[Row],
rddSchema: StructType,
nullTypes: Array[Int],
batchSize: Int,
dialect: JdbcDialect,
isolationLevel: Int): Iterator[Byte] = {
val conn = getConnection()
var committed = false
var finalIsolationLevel = Connection.TRANSACTION_NONE
if (isolationLevel != Connection.TRANSACTION_NONE) {
try {
val metadata = conn.getMetaData
if (metadata.supportsTransactions()) {
// Update to at least use the default isolation, if any transaction level
// has been chosen and transactions are supported
val defaultIsolation = metadata.getDefaultTransactionIsolation
finalIsolationLevel = defaultIsolation
if (metadata.supportsTransactionIsolationLevel(isolationLevel)) {
// Finally update to actually requested level if possible
finalIsolationLevel = isolationLevel
} else {
logWarning(s"Requested isolation level $isolationLevel is not supported; " +
s"falling back to default isolation level $defaultIsolation")
}
} else {
logWarning(s"Requested isolation level $isolationLevel, but transactions are unsupported")
}
} catch {
case NonFatal(e) => logWarning("Exception while detecting transaction support", e)
}
}
val supportsTransactions = finalIsolationLevel != Connection.TRANSACTION_NONE
try {
if (supportsTransactions) {
conn.setAutoCommit(false) // Everything in the same db transaction.
conn.setTransactionIsolation(finalIsolationLevel)
}
val stmt = insertStatement(conn, table, rddSchema, dialect)
val setters: Array[JDBCValueSetter] = rddSchema.fields.map(_.dataType)
.map(makeSetter(conn, dialect, _)).toArray
val numFields = rddSchema.fields.length
try {
var rowCount = 0
while (iterator.hasNext) {
val row = iterator.next()
var i = 0
while (i < numFields) {
if (row.isNullAt(i)) {
stmt.setNull(i + 1, nullTypes(i))
} else {
setters(i).apply(stmt, row, i)
}
i = i + 1
}
stmt.addBatch()
rowCount += 1
if (rowCount % batchSize == 0) {
stmt.executeBatch()
rowCount = 0
}
}
if (rowCount > 0) {
stmt.executeBatch()
}
} finally {
stmt.close()
}
if (supportsTransactions) {
conn.commit()
}
committed = true
Iterator.empty
} catch {
case e: SQLException =>
val cause = e.getNextException
if (cause != null && e.getCause != cause) {
if (e.getCause == null) {
e.initCause(cause)
} else {
e.addSuppressed(cause)
}
}
throw e
} finally {
if (!committed) {
// The stage must fail. We got here through an exception path, so
// let the exception through unless rollback() or close() want to
// tell the user about another problem.
if (supportsTransactions) {
conn.rollback()
}
conn.close()
} else {
// The stage must succeed. We cannot propagate any exception close() might throw.
try {
conn.close()
} catch {
case e: Exception => logWarning("Transaction succeeded, but closing failed", e)
}
}
}
}
总结
很多时候,本以为事情已经做的差不多了,其实等你做的更好的时候,发现原来做的还差很多。所以,任何时候都不要放弃。jdbc插入几千条记录要2分钟,这个结果我接受了1个多月,现在终于解决了,还是很有收获的。特此记录寻找优化的路径。
边栏推荐
猜你喜欢



随机推荐
LeetCode: 1403. Minimum subsequence in non-increasing order [greedy]
学习总结week3_2函数进阶
JSX基础
flink项目开发-配置jar依赖,连接器,类库
学习总结week2_3
Flink EventTime和Watermarks案例分析
What are the characteristics of the interface of the physical layer?What does each contain?
第5讲 使用pytorch实现线性回归
redis 缓存清除策略
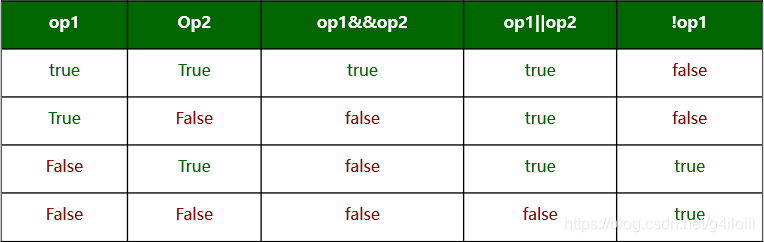
位运算符与逻辑运算符的区别
解决端口占用问题
Lecture 5 Using pytorch to implement linear regression
ES6 生成器
Lecture 3 Gradient Tutorial Gradient Descent and Stochastic Gradient Descent
Lecture 2 Linear Model Linear Model
flink实例开发-详细使用指南
关于基于若依框架的路由跳转
"PHP8 Beginner's Guide" A brief introduction to PHP
Matplotlib(二)—— 子图
【过一下10】sklearn使用记录