当前位置:网站首页>The ultra-large-scale industrial practical semantic segmentation dataset PSSL and pre-training model are open source!
The ultra-large-scale industrial practical semantic segmentation dataset PSSL and pre-training model are open source!
2022-08-02 01:46:00 【PaddlePaddle】
Semantic segmentation as the most“精细”的计算机视觉任务,与目标检测、Image classification techniques, etc,Each pixel needs to be classified.as in the field of autonomous driving,Need to accurately segment pedestrians、Vehicles and other road environment related objects,And then according to this information accurate obstacle avoidance;在医疗领域,It is necessary to accurately grasp the shape and size of the lesions,qualitative analysis of the disease;Special effects production scene in the field of film and television,For detailed requirements like cutout even reached the level of the hair,Therefore, semantic segmentation technology for refined classification tasks plays a key role in the above scenarios.
Semantic segmentation technology datasets on the market usually only cover common scenarios and the amount of data is around 1,000.,And in real business scenarios and changeful,without adding a lot of extra data,The segmentation effect of models trained based on common datasets in industrial practice is often substandard.
In order to solve the above-mentioned industry pain points,Paddle Semantic Segmentation Development KitPaddleSeg发布了120+万张ImageNetPseudo-label segmentation datasetPSSL[5](Pseudo Semantic Segmentation Labels)And achieve in five downstream tasks(CamVid,VOC-A,VOC-C,ADE20K, Cityscapes)上mIoU提高了1-5%不等.同时,PaddleSegOpen up complete pre-training models and strategies,Alleviate the problem of substandard model accuracy caused by small samples,The relevant results are currently inMachine Learning期刊发表,欢迎大家查阅~

- Dataset and model download link:
https://github.com/PaddlePaddle/PaddleSeg
* 记得Star收藏 *
防止走丢又实时关注更新
(https://mmbiz.qpic.cn/mmbiz_png/sKia1FKFiafggkHYlAgYRWvfESbqLjLVAq3Oaibfa0r9K9L6RN8nD6QUuNrSbtlU9t7OdsXxP3Yxdibs0iaPWfgCrtQ/640?wx_fmt=png)]
下面具体看看PSSLHow does the dataset and pretrained model strategy work?!
****PSSL
Semantic Segmentation Pseudo-Label Segmentation Dataset****
PSSL是具有120+万张和1000类别Semantic segmentation pseudo-label dataset of,Pseudo label refers to the difference from manual labeling,Automatically generated by the model of the label,而PSSLIt is automatically generated by Baidu's self-developed interpretability algorithm.At present, the common semantic segmentation datasets are:Pascal VOC, ADE20K, Cityscapes等,Their sample size is about5千到2万,Category is about19到80.而PSSL具有120+10,000 samples and1000的类别,Nearly one hundred times that of the common data set,因此PSSLThe dataset has more、Category with more advantages,Can overcome the challenges brought by the diversification of scenarios in industrial practice.
同时,Build semantic segmentation data sets will often meet with difficulty、High production cost and difficult,而PSSL以其自动生成的特性,Can solve the above difficulties well,Maintain a balance between dataset production cost and quality.
那么PSSLHow is the dataset created??
有研究[1,2]显示,Classification model is actually the recognition to the semantic information of an object,However, some interpretability algorithms are needed to extract this semantic information.So can we take advantage of classification models and interpretability algorithms,来Build a set of data segmentation automatically呢?毕竟,paddle has more than100个分类模型[3]and a complete set of interpretable algorithm open source tool library[4]呢.A single model explain the results sometimes is not perfect,So we use baidu itselfConsensus可解释性算法[2],Picked from Paddles20A classification model with high accuracy,fuse their interpretations,Get semantic information with less noise.We use this toImageNetSemantic extraction of all images in the training set,得到了120+Semantic segmentation pseudo-labels for thousands of imagesPSSL.
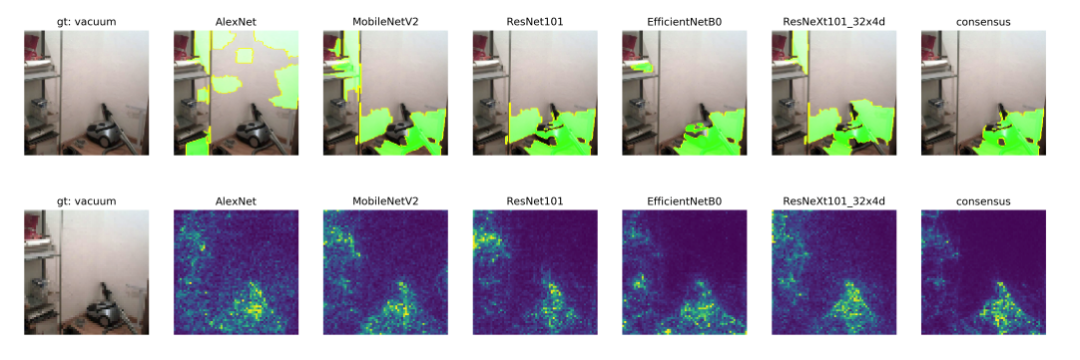 single model withConsensus解释结果(最右)示意图
single model withConsensus解释结果(最右)示意图
借助PSSL来进行预训练,Can improve the model and segmentation effect,Meet the requirements for segmentation accuracy in industrial practice.Currently we have only verifiedPSSLFor the segmentation task inmIoUimprovement in indicators[5],但是基于PSSLThe pre-training effect is very robust,We believe that for more models and a wider range of tasks,使用PSSL都会有提升.
In the process of the training methods to improve
Semantic segmentation networks often include classification、split two modules,The traditional semantic segmentation pre-training process is only initialized for the classification network,Pretrained weights for segmentation module not loaded,However, the split module design is usually more complicated,Contains more parameters,Once the prior knowledge of the segmentation module is missing,will make fine-tuning training for downstream tasks very difficult,In turn, it affects the improvement of the segmentation model effect..
如下图所示,Compared with the traditional method, only the classification module is initialized,PSSLThe new pre-training strategy isIn the preliminary stage of training segmentation module and training together,In order to reduce the training difficulty of downstream tasks.
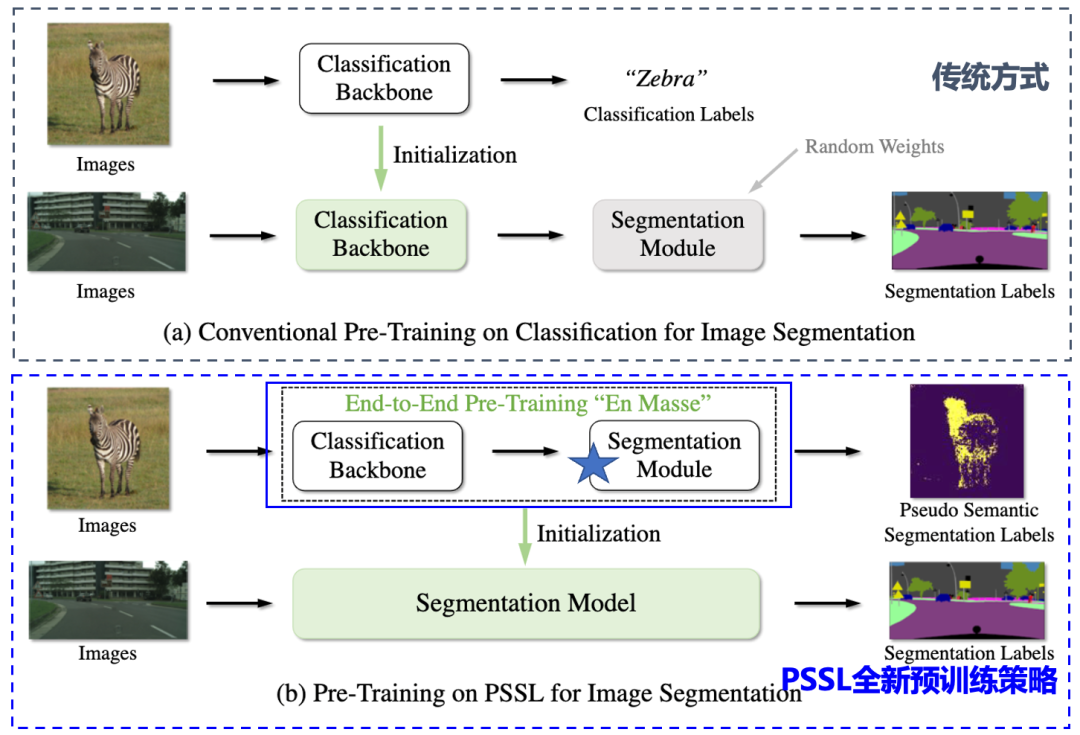
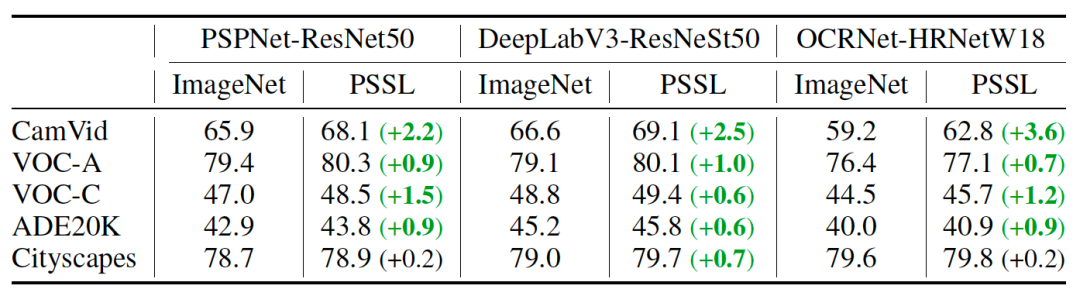
不仅如此,预训练完成后,无需修改代码,Developers can directly load pre-trained weights to predict downstream tasks.The table below shows three models applying the new pre-training strategy inPSSL数据集上的训练结果,可以看出,Three models on five categories of downstream tasksmIoUhave been significantly improved.
** open source
SurprisePaddleSeg**
免费使用PSSL数据集
Use your institution/The company's official mail system,State your institution/公司的信息、Purpose of using the dataset,发送邮件至[email protected]
Trained pretrained model
在最新版的PaddleSeg中,We also provide the trained model and training process records,It is convenient for developers to save the process of pre-training.
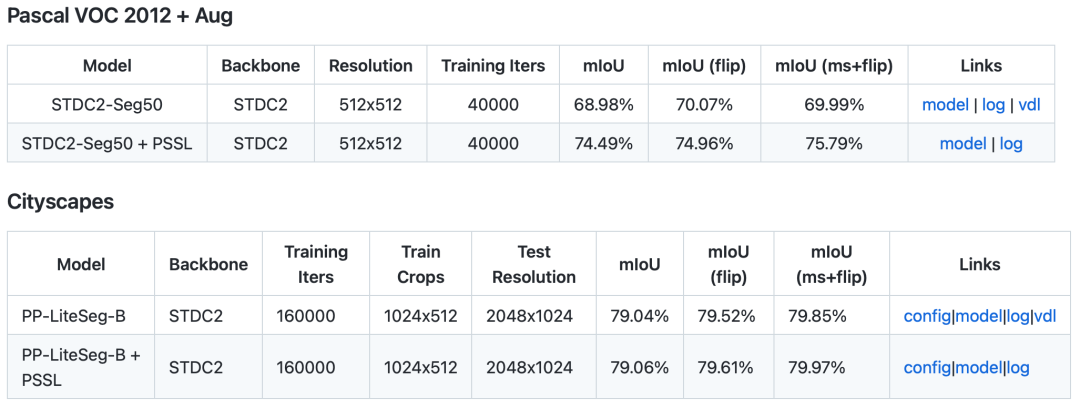
- 模型链接:
https://github.com/PaddlePaddle/PaddleSeg/tree/release/2.6/configs/pssl
利用PSSLThe dataset and this way of pre-training,不管什么模型、什么数据,The segmentation effect can be further improved1~5个点.This is totally free lunch!
Pre-training tutorials are fully open
当然,We don't stop those who want to pre-train themselves.预训练代码、PSSLThe datasets are all ready,The surprise isPaddleSeg,Welcome to the trial.
- 参考链接:
https://github.com/PaddlePaddle/PaddleSeg/tree/release/2.6/configs/pssl#optional-pretraining
总而言之,PaddleSeg新增的PSSLData sets and pre-trained models help comprehensively improve the performance of segmentation models on downstream tasks,Makes the industrial landing of split tasks easier!
引用:
[1] Zhou, B., Khosla, A., Lapedriza, A., Oliva, A., & Torralba, A. (2015). Learning Deep Features for Discriminative Localization. arXiv preprint arXiv:1512.04150.
[2] Li, X., Xiong, H., Huang, S., Ji, S., & Dou, D. (2021). Cross-model consensus of explanations and beyond for image classification models: An empirical study. arXiv preprint arXiv:2109.00707.
[3] https://github.com/PaddlePaddle/PaddleClas.
[4]https://github.com/PaddlePaddle/InterpretDL.
[5] Li, X., Xiong, H., Liu, Y., Zhou, D., Chen, Z., Wang, Y., & Dou, D. (2022). Distilling ensemble of explanations for weakly-supervised pre-training of image segmentation models. Machine Learning, 1-17.
关注【飞桨PaddlePaddle】公众号
获取更多技术内容~
边栏推荐
猜你喜欢






随机推荐
typescript29-枚举类型的特点和原理
NFT到底有哪些实际用途?
feign异常传递的两种方式 fallbackfactory和全局处理 获取服务端自定义异常
typescript36-class的构造函数实例方法
Anti-oversold and high concurrent deduction scheme for e-commerce inventory system
Rust P2P网络应用实战-1 P2P网络核心概念及Ping程序
typescript38-class的构造函数实例方法继承(implement)
有效进行自动化测试,这几个软件测试工具一定要收藏好!!!
电商库存系统的防超卖和高并发扣减方案
使用百度EasyDL实现厂区工人抽烟行为识别
5年自动化测试经验的一些感悟:做UI自动化一定要跨过这10个坑
Can‘t connect to MySQL server on ‘localhost3306‘ (10061) 简洁明了的解决方法
typescript34-class的基本使用
DCM 中间件家族迎来新成员
Kubernetes — 核心资源对象 — Controller
云和恩墨:让商业数据库时代的价值在openGauss生态上持续繁荣
秒懂大模型 | 3步搞定AI写摘要
《自然语言处理实战入门》 基于知识图谱的问答机器人
求大神解答,这种 sql 应该怎么写?
¶Backtop 回到顶部 不生效