当前位置:网站首页>nlp模型-bert从入门到精通(二)
nlp模型-bert从入门到精通(二)
2020-11-06 01:22:00 【IT界的小小小学生】
命名实体识别
首先下载相应bert 模块
pip install bert-base==0.0.9 -i https://pypi.python.org/simple
也可参考官网处理
安装
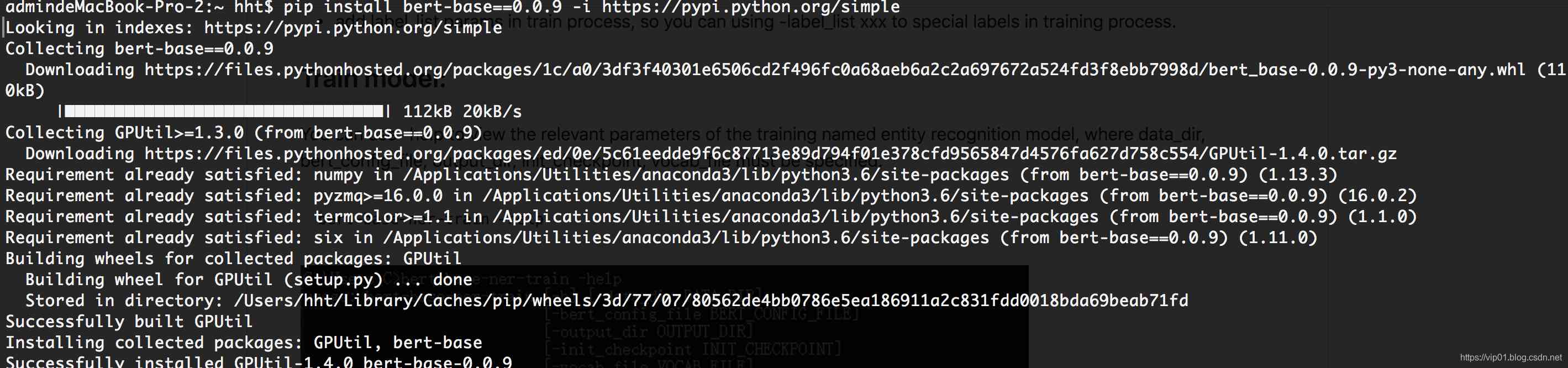
软件包现在支持的功能
1.命名实体识别的训练
2.命名实体识别的服务C/S
3.继承优秀开源软件:bert_as_service(hanxiao)的BERT所有服务
4.文本分类服务
后续功能会继续增加
基于命名行训练命名实体识别模型:
安装完bert-base后,会生成两个基于命名行的工具,其中bert-base-ner-train支持命名实体识别模型的训练,你只需要指定训练数据的目录,BERT相关参数的目录即可。可以使用下面的命令查看帮助
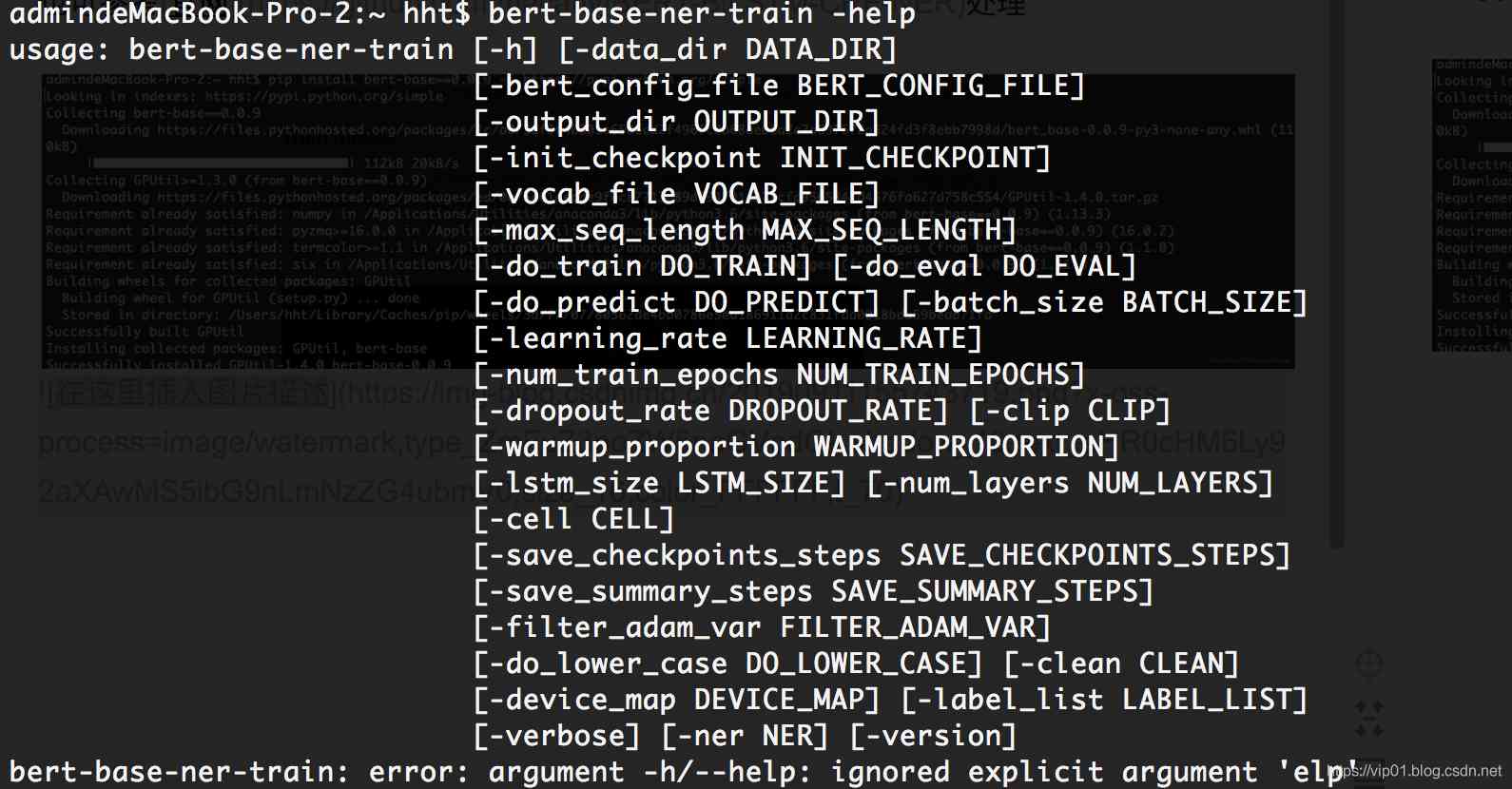
训练的事例命名如下:
bert-base-ner-train \
-data_dir {your dataset dir}\
-output_dir {training output dir}\
-init_checkpoint {Google BERT model dir}\
-bert_config_file {bert_config.json under the Google BERT model dir} \
-vocab_file {vocab.txt under the Google BERT model dir}
参数说明
其中data_dir是你的数据所在的目录,训练数据,验证数据和测试数据命名格式为:train.txt, dev.txt,test.txt,请按照这个格式命名文件,否则会报错。
训练数据的格式如下:
海 O
钓 O
比 O
赛 O
地 O
点 O
在 O
厦 B-LOC
门 I-LOC
与 O
金 B-LOC
门 I-LOC
之 O
间 O
的 O
海 O
域 O
。 O
每行得第一个是字,第二个是它的标签,使用空格’ '分隔,请一定要使用空格。句与句之间使用空行划分。程序会自动读取你的数据。
output_dir: 训练模型输出的文件路径,模型的checkpoint以及一些标签映射表都会存储在这里,这个路径在作为服务的时候,可以指定为-ner_model_dir
init_checkpoint: 下载的谷歌BERT模型
bert_config_file : 谷歌BERT模型下面的bert_config.json
vocab_file: 谷歌BERT模型下面的vocab.txt
训练完成后,你可以在你指定的output_dir中查看训练结果。
更多操作:
https://blog.csdn.net/macanv/article/details/85684284
还有一个bert模型的封装
https://www.jianshu.com/p/1d6689851622
https://cloud.tencent.com/developer/article/1470051
https://www.h3399.cn/201908/714454.html

版权声明
本文为[IT界的小小小学生]所创,转载请带上原文链接,感谢
https://vip01.blog.csdn.net/article/details/100739168
边栏推荐
- Vue 3 responsive Foundation
- Troubleshooting and summary of JVM Metaspace memory overflow
- Swagger 3.0 天天刷屏,真的香嗎?
- 解決pl/sql developer中資料庫插入資料亂碼問題
- 7.3.1 file upload and zero XML registration interceptor
- [performance optimization] Nani? Memory overflow again?! It's time to sum up the wave!!
- The practice of the architecture of Internet public opinion system
- 01 . Go语言的SSH远程终端及WebSocket
- After brushing leetcode's linked list topic, I found a secret!
- Every day we say we need to do performance optimization. What are we optimizing?
猜你喜欢

从海外进军中国,Rancher要执容器云市场牛耳 | 爱分析调研
Want to do read-write separation, give you some small experience
中国提出的AI方法影响越来越大,天大等从大量文献中挖掘AI发展规律
Cos start source code and creator

哇,ElasticSearch多字段权重排序居然可以这么玩
有关PDF417条码码制的结构介绍
怎么理解Python迭代器与生成器?
TensorFlow2.0 问世,Pytorch还能否撼动老大哥地位?

2018个人年度工作总结与2019工作计划(互联网)
业内首发车道级导航背后——详解高精定位技术演进与场景应用
随机推荐
50 + open source projects are officially assembled, and millions of developers are voting
[译] 5个Vuex插件,给你的下个VueJS项目
python过滤敏感词记录
Flink on paasta: yelp's new stream processing platform running on kubernetes
[performance optimization] Nani? Memory overflow again?! It's time to sum up the wave!!
Elasticsearch 第六篇:聚合統計查詢
神经网络简史
Listening to silent words: hand in hand teaching you sign language recognition with modelarts
做外包真的很难,身为外包的我也无奈叹息。
從小公司進入大廠,我都做對了哪些事?
多机器人行情共享解决方案
6.9.1 flashmapmanager initialization (flashmapmanager redirection Management) - SSM in depth analysis and project practice
Using Es5 to realize the class of ES6
使用 Iceberg on Kubernetes 打造新一代云原生数据湖
How to get started with new HTML5 (2)
有关PDF417条码码制的结构介绍
DTU连接经常遇到的问题有哪些
选择站群服务器的有哪些标准呢?
htmlcss
給萌新HTML5 入門指南(二)