当前位置:网站首页>Didi elasticsearch cluster cross version upgrade and platform reconfiguration
Didi elasticsearch cluster cross version upgrade and platform reconfiguration
2020-11-06 01:15:00 【InfoQ】
Reading guide : Not long ago , sound of dripping water ES The team will maintain 30 Multiple ES colony ,3500 Multiple ES node ,8PB The data of , from 2.3.3 Seamless upgrade to 6.6.1. Under the premise of basically zero impact and change on user query writing , It's solved ES Cross major protocol incompatibility 、 Incompatible file format 、mapping Incompatibility, etc , The whole process is completely transparent to most users . At the same time, it's done Arius Architecture upgrade , The single machine query performance has been improved 40%, The whole cluster cpu falling 10%, write in tps promote 30%, The utilization rate of cluster resources has been improved 20%、0 fault 、 The cost of operation and maintenance has decreased 60% The achievement of .
This paper will systematically introduce didi from 2.3.3 Upgrade to across large versions 6.6.1 Problems encountered in the process and solutions , And in the search platform construction process of systematic thinking .
01 Background introduction
1. The cluster size

At present, Didi uses ES The version is 2.3.3, The number of clusters is 40 Multiple , Node scale has 3500+, The total capacity of the cluster is 8PB.
2. Business scale

1200 Multiple platform applications are using ES,30 Multiple core applications are using ES, Written in TPS Yes 1500W, Of the query QPS Yes 25W.
02 Problem analysis
For the above scale ES colony , from 2.3.3 Upgrade to 6.X edition , The small version will be determined based on the results of the final analysis , Potential problems need to be analyzed and distinguished .
1. Problem analysis
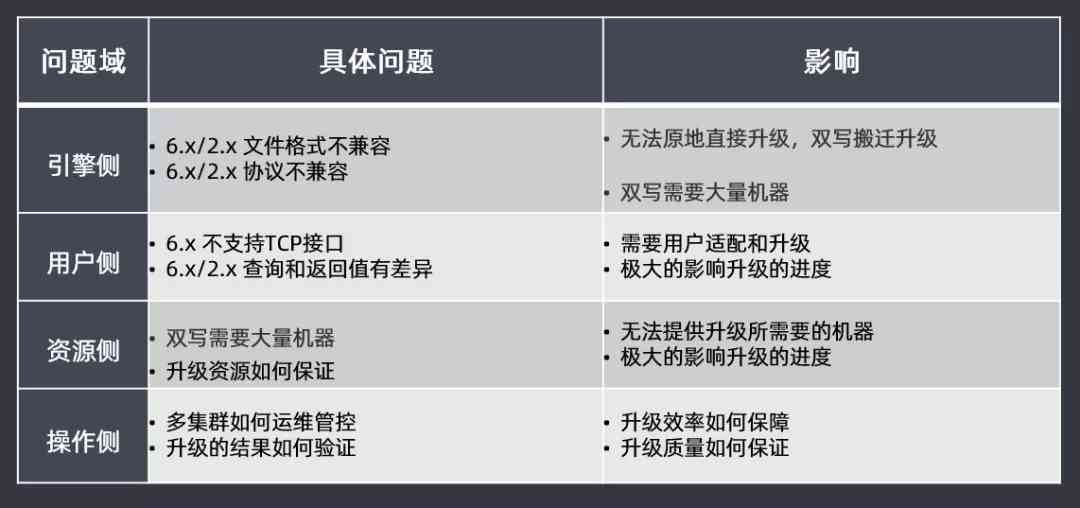
First of all, it analyzes the four problem areas :
- Engine side : As a result of 2.3.3 Upgrade to 6.X edition , The version gap is too big , Not compatible in file format or protocol , So you can't roll in place and upgrade directly , Need to double write relocation and upgrade , It costs a lot of machines to get involved
- The user side :6.X The version gradually does not support TCP Interface , Therefore, users need to adapt and upgrade ; There are also some differences between query and return value , If the user side adapts , Will greatly affect the progress of the upgrade
- Resource side : Because you can't scroll directly in place, upgrade directly , Need to double write using a lot of machines , But we can't provide the machines needed to upgrade , If resources cannot be guaranteed during the upgrade process , That will also greatly affect the progress of the upgrade
- Operation side : How to control the operation and maintenance of the new version of multi cluster ? How to verify the results of the upgrade ? How to guarantee the efficiency and quality of query ? All these problems need to be considered
Link to the original text :【https://www.infoq.cn/article/J6BFzWfJA0cbmgzN7R1w】. Without the permission of the author , Prohibited reproduced .
版权声明
本文为[InfoQ]所创,转载请带上原文链接,感谢
边栏推荐
- GBDT与xgb区别,以及梯度下降法和牛顿法的数学推导
- How to get started with new HTML5 (2)
- 【快速因數分解】Pollard's Rho 演算法
- Electron应用使用electron-builder配合electron-updater实现自动更新
- 有关PDF417条码码制的结构介绍
- 01 . Go语言的SSH远程终端及WebSocket
- 不吹不黑,跨平臺框架AspNetCore開發實踐雜談
- Python machine learning algorithm: linear regression
- 二叉树的常见算法总结
- Listening to silent words: hand in hand teaching you sign language recognition with modelarts
猜你喜欢



随机推荐
分布式ID生成服务,真的有必要搞一个
nlp模型-bert从入门到精通(一)
《Google軟體測試之道》 第一章google軟體測試介紹
Using tensorflow to forecast the rental price of airbnb in New York City
【jmeter】實現介面關聯的兩種方式:正則表示式提取器和json提取器
7.3.2 File Download & big file download
文本去重的技术方案讨论(一)
【新閣教育】窮學上位機系列——搭建STEP7模擬環境
简直骚操作,ThreadLocal还能当缓存用
企业数据库的选择通常由系统架构师主导决策 - thenewstack
6.8 multipartresolver file upload parser (in-depth analysis of SSM and project practice)
Basic principle and application of iptables
恕我直言,我也是才知道ElasticSearch条件更新是这么玩的
5.5 ControllerAdvice注解 -《SSM深入解析与项目实战》
DTU连接经常遇到的问题有哪些
Azure Data Factory(三)整合 Azure Devops 實現CI/CD
Dapr實現分散式有狀態服務的細節
Details of dapr implementing distributed stateful service
【效能優化】納尼?記憶體又溢位了?!是時候總結一波了!!
Clean架构能够解决哪些问题? - jbogard