当前位置:网站首页>文本去重的技术方案讨论(一)
文本去重的技术方案讨论(一)
2020-11-06 01:28:00 【IT界的小小小学生】
转发请注明出处:https://blog.csdn.net/HHTNAN
对于文本去重来说,我个人处理上会从数据量、文本特征、文本长度(短文本、长文本)几个方向考虑。
常见的去重任务,如网页去重,帖子去重,评论去重等等。
好的去重任务是不仅比对文本的相似性,还要比对语义上的相似性。
下面我们来介绍下文本去重的方案。
1.传统签名算法与文本完整性判断
一、传统签名算法与文本完整性判断
问题抛出:
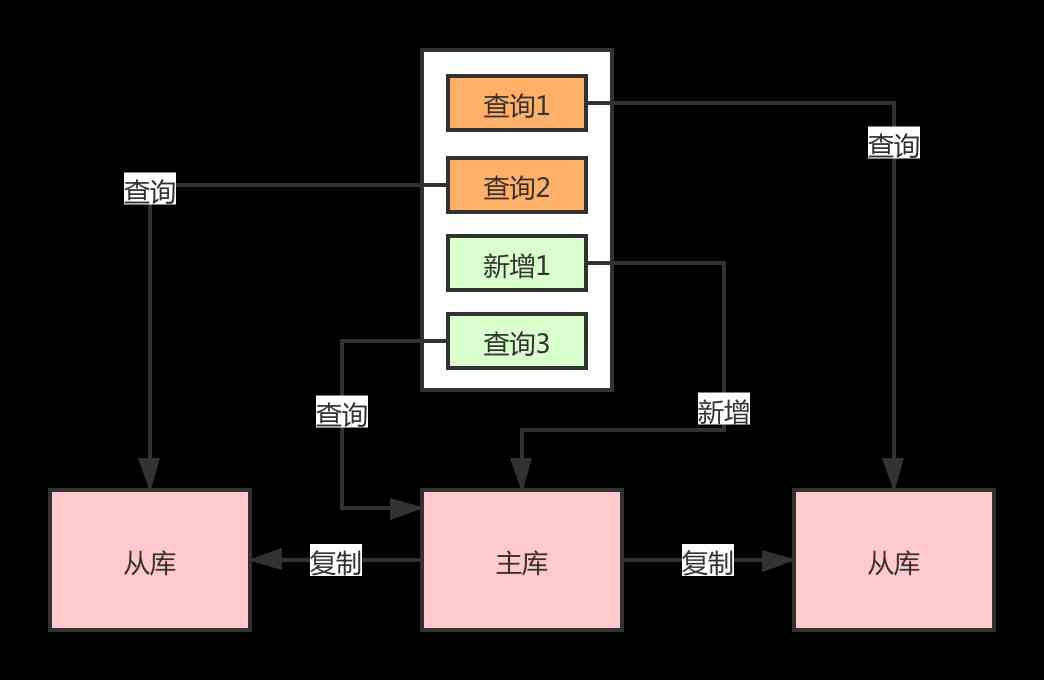
(1)运维上线一个bin文件,将文件分发到4台线上机器上,如何判断bin文件全部是一致的?
(2)用户A将消息msg发送给用户B,用户B如何判断收到的msg_t就是用户A发送的msg?
思路:
一个字节一个字节的比对两个大文件或者大网页效率低,我们可以用一个签名值(例如md5值)代表一个大文件,签名值相同则认为大文件相同(先不考虑冲突率)
回答:
(1)将bin文件取md5,将4台线上机器上的bin文件也取md5,如果5个md5值相同,说明一致
(2)用户A将msg以及消息的md5同时发送给用户B,用户B收到msg_t后也取md5,得到的值与用户A发送过来的md5值如果相同,则说明msg_t与msg相同
结论: md5是一种签名算法,常用来判断数据的完整性与一致性
md5设计原则: 两个文本哪怕只有1个bit不同,其md5签名值差别也会非常大,故它只适用于“完整性”check,不适用于“相似性”check。
新问题抛出:
有没有一种签名算法,如果文本非常相似,签名值也非常相似呢?
此方法来源于网络,我认为很好,故直接引用了,作为开篇,如有侵权,可随时与我联系。
simhash

simhash是google用来处理海量文本去重的算法。 google出品,你懂的。 simhash最牛逼的一点就是将一个文档,最后转换成一个64位的字节,暂且称之为特征字,然后判断重复只需要判断他们的特征字的距离是不是<n(根据经验这个n一般取值为3),就可以判断两个文档是否相似。
原理
simhash值的生成图解如下
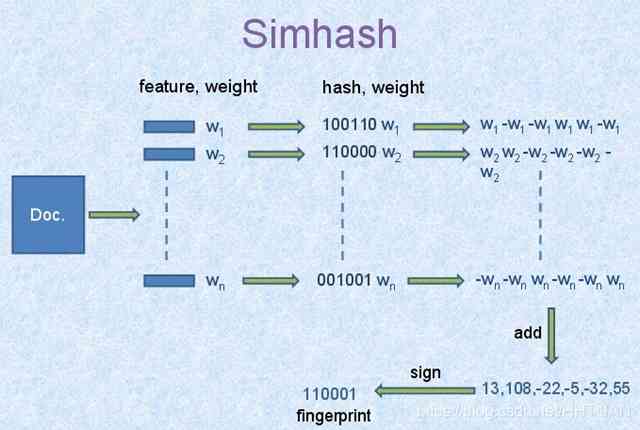
概花三分钟看懂这个图就差不多怎么实现这个simhash算法了。特别简单。谷歌出品嘛,简单实用。
-
1、分词,把需要判断文本分词形成这个文章的特征单词。最后形成去掉噪音词的单词序列并为每个词加上权重,我们假设权重分为5个级别(1~5)。比如:“
美国“51区”雇员称内部有9架飞碟,曾看见灰色外星人 ” ==> 分词后为 “ 美国(4) 51区(5) 雇员(3) 称(1) 内部(2)
有(1) 9架(3) 飞碟(5) 曾(1) 看见(3) 灰色(4) 外星人(5)”,括号里是代表单词在整个句子里重要程度,数字越大越重要。 -
2、hash,通过hash算法把每个词变成hash值,比如“美国”通过hash算法计算为 100101,“51区”通过hash算法计算为
101011。这样我们的字符串就变成了一串串数字,还记得文章开头说过的吗,要把文章变为数字计算才能提高相似度计算性能,现在是降维过程进行时。 -
3、加权,通过 2步骤的hash生成结果,需要按照单词的权重形成加权数字串,比如“美国”的hash值为“100101”,通过加权计算为“4
-4 -4 4 -4 4”;“51区”的hash值为“101011”,通过加权计算为 “ 5 -5 5 -5 5 5”。 -
4、合并,把上面各个单词算出来的序列值累加,变成只有一个序列串。比如 “美国”的 “4 -4 -4 4 -4 4”,“51区”的 “ 5
-5 5 -5 5 5”, 把每一位进行累加, “4+5 -4±5 -4+5 4±5 -4+5 4+5” ==》 “9 -9 1 -1 1 9”。这里作为示例只算了两个单词的,真实计算需要把所有单词的序列串累加。 -
5、降维,把4步算出来的 “9 -9 1 -1 1 9” 变成 0 1 串,形成我们最终的simhash签名。 如果每一位大于0 记为1,小于0 记为 0。最后算出结果为:“1 0 1 0 1 1”。
整个过程图为:
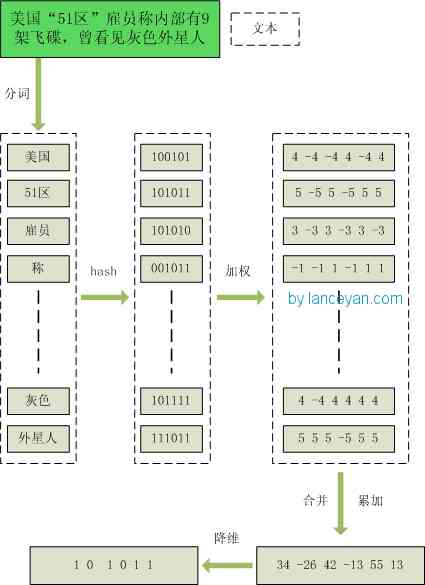
到此,如何从一个doc到一个simhash值的过程已经讲明白了。
大家可能会有疑问,经过这么多步骤搞这么麻烦,不就是为了得到个 0 1 字符串吗?我直接把这个文本作为字符串输入,用hash函数生成 0 1 值更简单。其实不是这样的,传统hash函数解决的是生成唯一值,比如 md5、hashmap等。md5是用于生成唯一签名串,只要稍微多加一个字符md5的两个数字看起来相差甚远;hashmap也是用于键值对查找,便于快速插入和查找的数据结构。不过我们主要解决的是文本相似度计算,要比较的是两个文章是否相识,当然我们降维生成了hashcode也是用于这个目的。看到这里估计大家就明白了,我们使用的simhash就算把文章中的字符串变成 01 串也还是可以用于计算相似度的,而传统的hashcode却不行。我们可以来做个测试,两个相差只有一个字符的文本串,“你妈妈喊你回家吃饭哦,回家罗回家罗” 和 “你妈妈叫你回家吃饭啦,回家罗回家罗”。
通过simhash计算结果为:
1000010010101101111111100000101011010001001111100001001011001011
1000010010101101011111100000101011010001001111100001101010001011
通过 hashcode计算为:
1111111111111111111111111111111110001000001100110100111011011110
1010010001111111110010110011101
大家可以看得出来,相似的文本只有部分 01 串变化了,而普通的hashcode却不能做到,这个就是局部敏感哈希的魅力。目前Broder提出的shingling算法和Charikar的simhash算法应该算是业界公认比较好的算法。在simhash的发明人Charikar的论文中并没有给出具体的simhash算法和证明,量子图灵”得出的证明simhash是由随机超平面hash算法演变而来的。
下面是关于【海明距离】
二进制串A 和 二进制串B 的海明距离 就是 A xor B 后二进制中1的个数。
举例如下:
> A = 100111;
> B = 101010;
> hamming_distance(A, B) = count_1(A xor B) = count_1(001101) = 3;
当我们算出所有doc的simhash值之后,需要计算doc A和doc B之间是否相似的条件是:
A和B的海明距离是否小于等于n,这个n值根据经验一般取值为3,
simhash本质上是局部敏感性的hash,和md5之类的不一样。 正因为它的局部敏感性,所以我们可以使用海明距离来衡量simhash值的相似度。
simhash是由 Charikar 在2002年提出来的,参考 《Similarity estimation techniques from rounding algorithms》 。
通过这样的转换,我们把库里的文本都转换为simhash 代码,并转换为long类型存储,空间大大减少。现在我们虽然解决了空间,但是如何计算两个simhash的相似度呢?难道是比较两个simhash的01有多少个不同吗?对的,其实也就是这样,我们通过海明距离(Hamming distance)就可以计算出两个simhash到底相似不相似。两个simhash对应二进制(01串)取值不同的数量称为这两个simhash的海明距离。举例如下: 10101 和 00110 从第一位开始依次有第一位、第四、第五位不同,则海明距离为3。对于二进制字符串的a和b,海明距离为等于在a XOR b运算结果中1的个数(普遍算法)。
为了高效比较,我们预先加载了库里存在文本并转换为simhash code 存储在内存空间。来一条文本先转换为 simhash code,然后和内存里的simhash code 进行比较,测试100w次计算在100ms。速度大大提升。
小节:
- 1、目前速度提升了但是数据是不断增量的,如果未来数据发展到一个小时100w,按现在一次100ms,一个线程处理一秒钟 10次,一分钟 60 10 次,一个小时 6010 60 次 = 36000次,一天 601060*24 = 864000次。 我们目标是一天100w次,通过增加两个线程就可以完成。但是如果要一个小时100w次呢?则需要增加30个线程和相应的硬件资源保证速度能够达到,这样成本也上去了。能否有更好的办法,提高我们比较的效率?
- 2、通过大量测试,simhash用于比较大文本,比如500字以上效果都还蛮好,距离小于3的基本都是相似,误判率也比较低。但是如果我们处理的是微博信息,最多也就140个字,使用simhash的效果并不那么理想。看如下图,在距离为3时是一个比较折中的点,在距离为10时效果已经很差了,不过我们测试短文本很多看起来相似的距离确实为10。如果使用距离为3,短文本大量重复信息不会被过滤,如果使用距离为10,长文本的错误率也非常高,如何解决?
代码实现
#coding:utf8
import math
import jieba
import jieba.analyse
class SimHash(object):
def __init__(self):
pass
def getBinStr(self, source):
if source == "":
return 0
else:
x = ord(source[0]) << 7
m = 1000003
mask = 2 ** 128 - 1
for c in source:
x = ((x * m) ^ ord(c)) & mask
x ^= len(source)
if x == -1:
x = -2
x = bin(x).replace('0b', '').zfill(64)[-64:]
print(source, x)
return str(x)
def getWeight(self, source):
# fake weight with keyword
return ord(source)
def unwrap_weight(self, arr):
ret = ""
for item in arr:
tmp = 0
if int(item) > 0:
tmp = 1
ret += str(tmp)
return ret
def simHash(self, rawstr):
seg = jieba.cut(rawstr, cut_all=True)
keywords = jieba.analyse.extract_tags("|".join(seg), topK=100, withWeight=True)
print(keywords)
ret = []
for keyword, weight in keywords:
binstr = self.getBinStr(keyword)
keylist = []
for c in binstr:
weight = math.ceil(weight)
if c == "1":
keylist.append(int(weight))
else:
keylist.append(-int(weight))
ret.append(keylist)
# 对列表进行"降维"
rows = len(ret)
cols = len(ret[0])
result = []
for i in range(cols):
tmp = 0
for j in range(rows):
tmp += int(ret[j][i])
if tmp > 0:
tmp = "1"
elif tmp <= 0:
tmp = "0"
result.append(tmp)
return "".join(result)
def getDistince(self, hashstr1, hashstr2):
length = 0
for index, char in enumerate(hashstr1):
if char == hashstr2[index]:
continue
else:
length += 1
return length
if __name__ == "__main__":
simhash = SimHash()
s1="感冒了怎么办" #效果不好,语义
s2="感冒了怎么治"
# s1 = "100元=38万星币,加微信" #效果不好
# s2 = "38万星币100元,加VX"
# with open("a.txt", "r") as file:
# s1 = "".join(file.readlines())
# file.close()
# with open("b.txt", "r") as file:
# s2 = "".join(file.readlines())
# file.close()
# s1 = "this is just test for simhash, here is the difference"
# s2 = "this is a test for simhash, here is the difference"
# print(simhash.getBinStr(s1))
# print(simhash.getBinStr(s2))
hash1 = simhash.simHash(s1)
hash2 = simhash.simHash(s2)
distince = simhash.getDistince(hash1, hash2)
# value = math.sqrt(len(s1)**2 + len(s2)**2)
value = 5
print("海明距离:", distince, "判定距离:", value, "是否相似:", distince<=value)
参考资料:直通车

版权声明
本文为[IT界的小小小学生]所创,转载请带上原文链接,感谢
https://vip01.blog.csdn.net/article/details/86539804
边栏推荐
- 【事件中心 Azure Event Hub】Event Hub日誌種發現的錯誤資訊解讀
- APReLU:跨界应用,用于机器故障检测的自适应ReLU | IEEE TIE 2020
- 深入了解JS数组的常用方法
- 自然语言处理-错字识别(基于Python)kenlm、pycorrector
- 面经手册 · 第15篇《码农会锁,synchronized 解毒,剖析源码深度分析!》
- 技术总监,送给刚毕业的程序员们一句话——做好小事,才能成就大事
- c++学习之路:从入门到精通
- 普通算法面试已经Out啦!机器学习算法面试出炉 - kdnuggets
- 2个月再招10000人,字节跳动冲刺10万员工“小目标”
- 微信小程序:防止多次点击跳转(函数节流)
猜你喜欢


随机推荐
使用Consul实现服务发现:instance-id自定义
安装Consul集群
JVM内存区域与垃圾回收
tensorflow之tf.tile\tf.slice等函数的基本用法解读
9.2.3 loadcustomvfs method (XML configuration builder analysis) - SSM in depth analysis and project practice
深入了解JS数组的常用方法
Python 基于jwt实现认证机制流程解析
如何将分布式锁封装的更优雅
Skywalking系列博客2-Skywalking使用
Python爬蟲實戰詳解:爬取圖片之家
【QT】 QThread部分原始碼淺析
如何使用ES6中的参数
React 高阶组件浅析
一场关于FLV是否要支持HEVC的争论
字符串的常见算法总结
如何成为数据科学家? - kdnuggets
数据科学家与机器学习工程师的区别? - kdnuggets
Python + Appium 自動化操作微信入門看這一篇就夠了
drf JWT认证模块与自定制
OPTIMIZER_TRACE详解