当前位置:网站首页>JVM内存区域与垃圾回收
JVM内存区域与垃圾回收
2020-11-06 01:18:00 【ClawHub的博客】
1、JAVA内存区域与内存溢出
1.1、概述
Java中JVM提供了内存管理机制,Java虚拟机在执行Java程序的过程中会把内存分为不同的数据区,如图: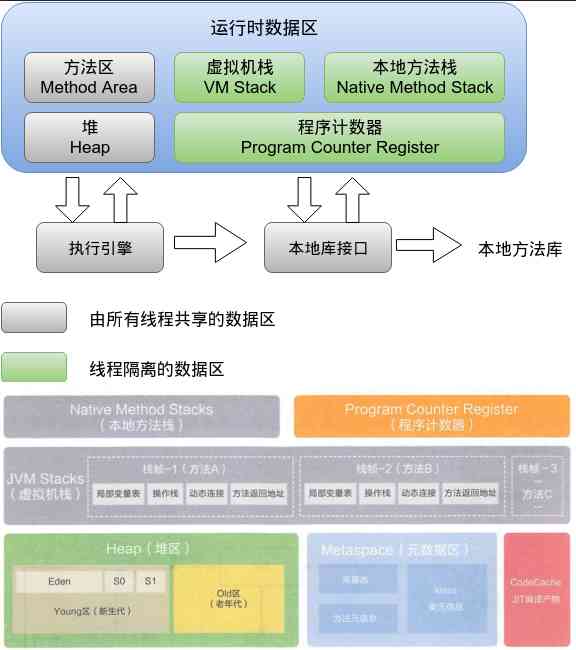
1.2、程序计数器
程序计数器是当前线程所执行的字节码的行号指示器,作用就是根据计数器的值获取下一条要执行的字节码指令。当执行的是java方法,则记录的是正在执行的虚拟机字节码指令的地址,如果是Native方法,则这个计数器的值为空。不存在任何OutOfMemoryError。
1.3、虚拟机栈
每个普通Java方法(除去Native方法)在执行的时候都会同时创建栈帧,用于存储局部变量表、操作栈、动态链接、方法出口等信息,每个方法被调用直到完成的过程对应着栈帧在JVM栈中的入栈与出栈。其中局部变量表所需要的内存空间在编译器间完成分配。
跟虚拟机栈相关联的异常有两种:
- StackOverflowError
线程请求的栈深度大于虚拟机允许的最大深度。
- OutOfMemoryError
虚拟机栈扩展时无法申请到足够的内存。
1.4、本地方法栈
用于虚拟机执行Native方法,其他和本地方法栈相同。也会有StackOverflowError和OutOfMemoryError。
1.5、堆
虚拟机启动后创建堆,用于存放对象实例。堆是垃圾回收器的主要工作区域,主要分为新生代和老年代,新生代又可以细分为Eden空间、From Survivor空间、To Survivor空间。java程序启动时,可用-Xmx与-Xms控制堆的大小。如果堆中没有内存完成实例分配并且堆也无法扩展时会抛出OutOfMemoryError。
1.6、方法区
方法区主要存储类的元数据,如虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码,JDK1.8之前以永久代实现,JDK1.8之后使用元空间,而且元空间使用的是系统内存。如果无法申请内存时,会抛出OutOfMemoryError。
2、垃圾回收
2.1、如何判断对象已经死亡?
2.1.1、引用计数法
在对象中添加一个引用计数器,当有个地方引用时,计数器值+1,当引用失效时,计数器值-1。计数器为0的对象就是死亡的,但是这里有个问题:对象循环引用,两个对象互相引用着对方,导致它们的引用计数器不为0,于是无法通知GC回收。
2.1.2、GC Roots搜索
Java中采用的是GC ROOT搜索,思路就是通过一系列名为“GC Roots”的对象作为起点,从这些节点开始向下搜索,搜索中所走过的路径称为引用链,当GC Roots对某一对象不可达时,则证明此对象不可用。
GC Roots包括以下几种:
- 栈帧中的本地变量表中引用的对象
- 方法区中类静态属性引用的对象
- 方法区中常量引用的对象
- 本地方法栈Native方法引用的对象
2.2、垃圾收集算法
2.2.1、标记-清除算法
标记-清除算法分为两个阶段:
- 标记:首先标记出所有需要回收的对象。
- 清除:统一回收被标记的对象。

这个算法有两个缺点:
- 效率不高
- 会产生不连续的内存碎片
2.2.2、复制算法
复制算法的效率很高,其将可用内存按照容量划分为大小相等的两块,每次只使用其中的一块,当一块用完时,就将还存活的对象复制到另一块上面,然后清除掉使用过的内存空间。

这种算法很适合回收新生代,在新生代中分为Eden空间、From Survivor空间、To Survivor空间,一般分配的内存比例为8:1:1,当回收时,将Eden与From Survivor中还存活的对象一次性拷贝到To Survivor中,之后清理掉Eden与From Servivor空间,当To Survivor空间不够时,需要依赖老年代。
2.2.3、标记-整理算法
在老年代,对象的存活率比较高,所以标记-整理算法被提出来了,首先标记出要回收的对象,然后将所有存活的对象都向一端移动,然后直接清理掉死亡的对象:

2.2.4、分代收集算法
分代回收的思想就是根据对象的存活周期,将不同的内存划分为几块,根据每块内存的特点采用适当的收集算法,比如新生代采用复制算法,老年代采用标记-整理算法。
2.3、垃圾收集器
下图展示了7种不同分代的收集器,如果两个收集器之间存在连线,则表示可以搭配使用。

通过以下命令可以查看垃圾回收器信息:
1 |
java -XX:+PrintCommandLineFlags -version |
我的测试服务器结果:
1 |
-XX:InitialHeapSize=524503488 -XX:MaxHeapSize=8392055808 -XX:+PrintCommandLineFlags -XX:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:+UseParallelGC |
可以看到使用的是:ParallelGC。
JVM参数对应关系:
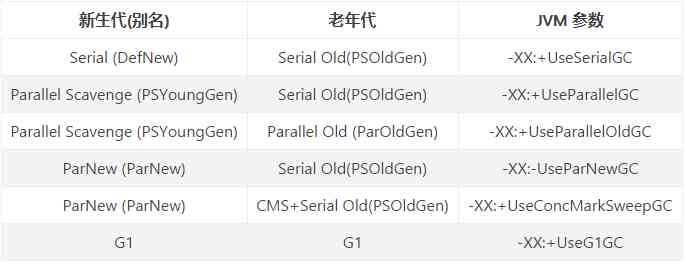
下面简单介绍7种垃圾回收器:
2.3.1、Serial收集器
新生代单线程收集器,简单高效。
2.3.2、ParNew收集器
Serial收集器的多线程版本,除了在垃圾回收时使用多线程,其余都和Serial收集器相同。
2.3.3、Parallel Scavenge收集器
Parallel Scavenge收集器是并行的采用复制算法的新生代收集器,着重于系统的吞吐量,适合后台运算而不需要太多用户交互的任务。
2.3.4、Serial Old收集器
Serial Old是单线程的老年代垃圾收集器,使用标记-整理算法。具有简单高效的特点。
2.3.5、Parallel Old收集器
Parallel Old收集器是Parallel Scanenge的老年代版本,多线程垃圾回收,也是用标记-整理算法。
2.3.6、CMS收集器
CMS注重服务的响应时间,是基于标记-清除算法实现。具有并发收集、低停顿的特点。
2.3.7、G1收集器
Garbage First,基于标记-整理算法,其将整个Java堆(包括新生代和老年代)划分为多个大小固定的独立区域,并且跟踪这些区域里的垃圾堆积程度,在后台维护一个优先列表,每次根据允许的收集时间,优先回收垃圾最多的区域。
3、CPU占用过高问题排查
3.1、 linux查看进程信息
1 |
top |
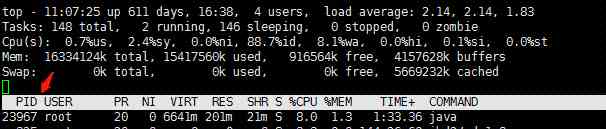
3.2、查看进程占用cpu最多的线程
1 |
ps -mp 23967 -o THREAD,tid,time |

3.3、线程ID转16进制
1 |
printf "%x\n" 23968 |

3.4、查看线程信息
1 |
jstack 23967 |grep -A 10 5da0 |

1 |
jstack 23967 |grep 5da0 -A 30 |

3.5、 查看进程的对象信息
1 |
jmap -histo:live 23967 | more |

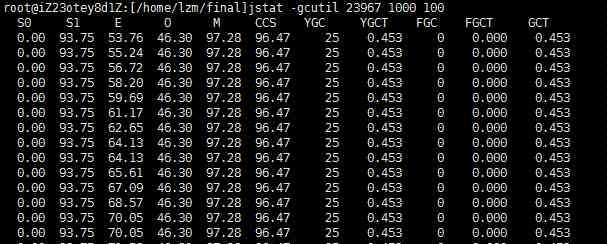
3.6、查看进程的GC情况
1 |
jstat -gcutil 23967 1000 100 |
参考

版权声明
本文为[ClawHub的博客]所创,转载请带上原文链接,感谢
https://clawhub.club/posts/2019/12/24/JVM/JVM%E5%86%85%E5%AD%98%E5%8C%BA%E5%9F%9F%E4%B8%8E%E5%9E%83%E5%9C%BE%E5%9B%9E%E6%94%B6/
边栏推荐
猜你喜欢
DRF JWT authentication module and self customization
【C/C++ 1】Clion配置与运行C语言
Want to do read-write separation, give you some small experience

Technical director, to just graduated programmers a word - do a good job in small things, can achieve great things
自然语言处理之命名实体识别-tanfordcorenlp-NER(一)

车的换道检测
安装Anaconda3 后,怎样使用 Python 2.7?

什么是无副作用的函数方法?如何取名? - Mario
快快使用ModelArts,零基础小白也能玩转AI!
接口压力测试:Siege压测安装、使用和说明
随机推荐
如何将分布式锁封装的更优雅
Cos start source code and creator
Ubuntu18.04上安裝NS-3
C language 100 question set 004 - statistics of the number of people of all ages
《Google軟體測試之道》 第一章google軟體測試介紹
6.8 multipartresolver file upload parser (in-depth analysis of SSM and project practice)
7.3.1 file upload and zero XML registration interceptor
前端模組化簡單總結
Cocos Creator 原始碼解讀:引擎啟動與主迴圈
Clean架构能够解决哪些问题? - jbogard
6.9.2 session flashmapmanager redirection management
2018个人年度工作总结与2019工作计划(互联网)
用Python构建和可视化决策树
Basic principle and application of iptables
Analysis of ThreadLocal principle
如何在Windows Server 2012及更高版本中將域控制器降級
WeihanLi.Npoi 1.11.0/1.12.0 Release Notes
從小公司進入大廠,我都做對了哪些事?
Kitty中的动态线程池支持Nacos,Apollo多配置中心了
Electron应用使用electron-builder配合electron-updater实现自动更新