当前位置:网站首页>Want to do read-write separation, give you some small experience
Want to do read-write separation, give you some small experience
2020-11-06 01:15:00 【Yin Jihuan】
Read write separation is the most common technology to improve the performance of data access in applications , When there are more and more users , More and more visits , Single node database will inevitably encounter performance bottleneck . Many scenes are basically read more and write less , Therefore, it is natural to add multiple slave nodes to share the pressure of the master node .
After the application access read-write separation , There will inevitably be some unexpected problems , This article mainly introduces some common problems , If you have any other questions, please leave a message .
The articles before the sub database and sub table can be viewed :http://mp.weixin.qq.com/mp/homepage?__biz=MzIwMDY0Nzk2Mw==&hid=4&sn=1b96093ec951a5f997bdd3225e5f2fdf&scene=18#wechat_redirect
Realization way
For the use of read-write separation , There are mainly two ways , Client mode and proxy mode .
The client mode can be used by itself Spring Self contained AbstractRoutingDataSource To achieve , It can also be implemented in an open source framework , such as Sharding-JDBC.
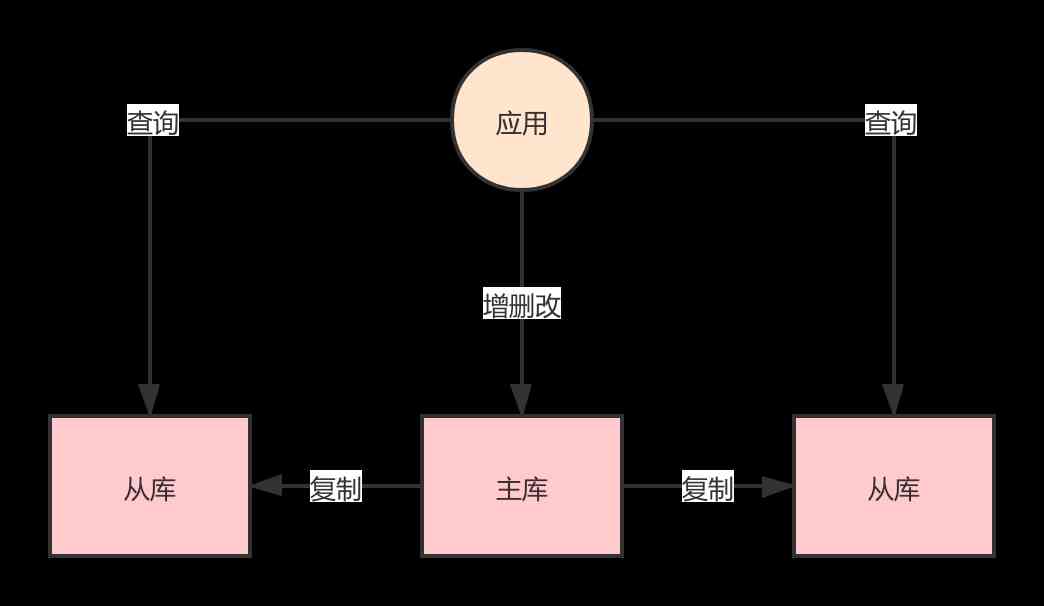
Proxy mode needs to write proxy service to manage all nodes , The application does not need to pay attention to the information of multiple database nodes . You can do it yourself , You can also use open source frameworks , You can also use commercial cloud services .
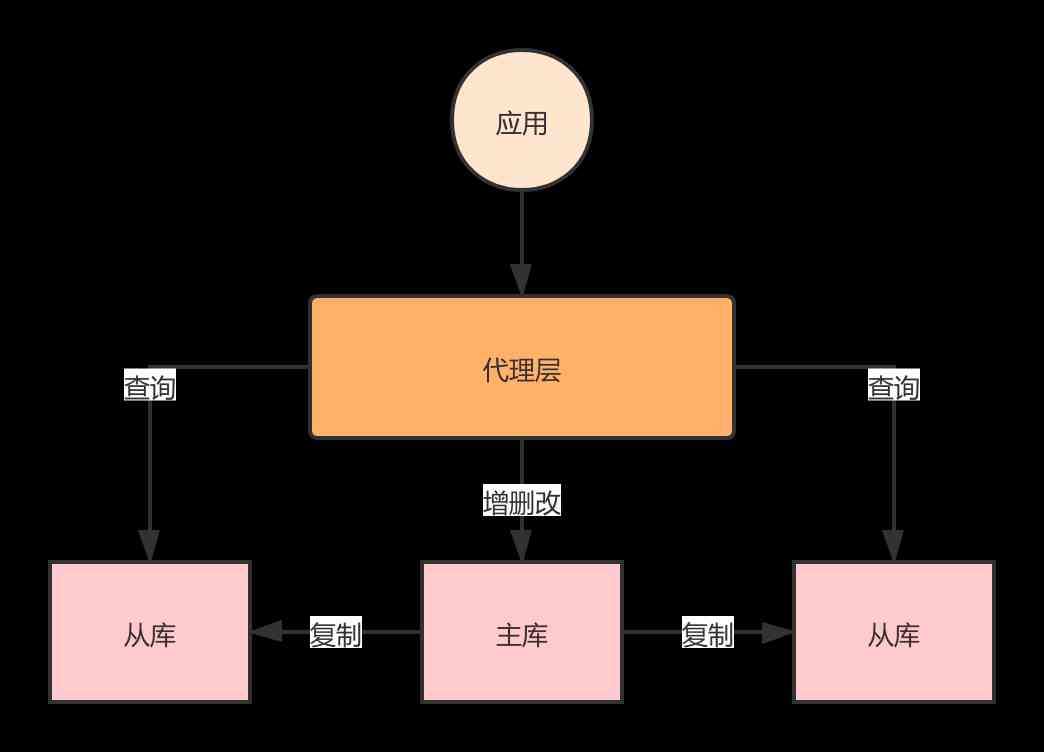
Data delay
When it comes to data latency , You have to understand the principle of master-slave architecture . The addition, deletion and modification of data are performed on the main database , The query is executed on the slave library , When the data is just inserted into the main database , And when I go to check immediately , Most likely, the data has not yet been synchronized to the slave library , There will be no query .
Like I published articles on some websites before , After publishing, jump to the list page , No new articles were found , Refresh the next page again , From this point of view, this is the phenomenon caused by data delay after read-write separation .
Forced routing
Should data delay be solved , It generally depends on the business scenario . For business scenarios with less real-time requirements , Allow a certain delay , For real-time scenarios , The only way is to query directly from the main database , In this way, the latest data just inserted or modified can be read in time .
Forced routing is a solution , That is to force the read request to the main database for query . Most middleware supports Hint grammar /FORCE_MASTER/ and /FORCE_SLAVE/.
With Sharding-JDBC give an example , The framework provides HintManager To force routing , Use as follows :
HintManager hintManager = HintManager.getInstance();hintManager.setMasterRouteOnly();
For ease of use , Suggest encapsulating a comment , Annotate business methods that require real-time queries , Set mandatory routing through facets .
Annotations use :
@MasterRoute@Overridepublic UserBO getUser(Long id) {log.info(" Query the user [{}]", id);if (id == null) {throw new BizException(ResponseCode.PARAM_ERROR_CODE, "id Can't be empty ");}UserDO userDO = userDao.getById(id);if (userDO == null) {throw new BizException(ResponseCode.NOT_FOUND_CODE);}return userBoConvert.convert(userDO);}
Section settings :
@Aspectpublic class MasterRouteAspect {@Around("@annotation(masterRoute)")public Object aroundGetConnection(final ProceedingJoinPoint pjp, MasterRoute masterRoute) throws Throwable {HintManager hintManager = HintManager.getInstance();hintManager.setMasterRouteOnly();try {return pjp.proceed();} finally {hintManager.close();}}}
The transaction operations
Read requests in transactions , Go to the main library or the slave Library ? For this question , The simplest way is to go to the main database for all transactions , There are often inserts in transactions , And then re query the scene , The transaction is not committed at this time , Even if the synchronization is fast , There is no data from the database , So we can only go to the main library .
But there are also requests , Just query the slave library , If routing is enforced for all operations in a transaction , It's not very good either . stay Sharding-JDBC It's very good , about In the same thread and database connection , If there is a write operation , Later read operations are read from the main library , For data consistency . If we have a query request before the data is written , Or from the library , Reduce the pressure on the main reservoir .
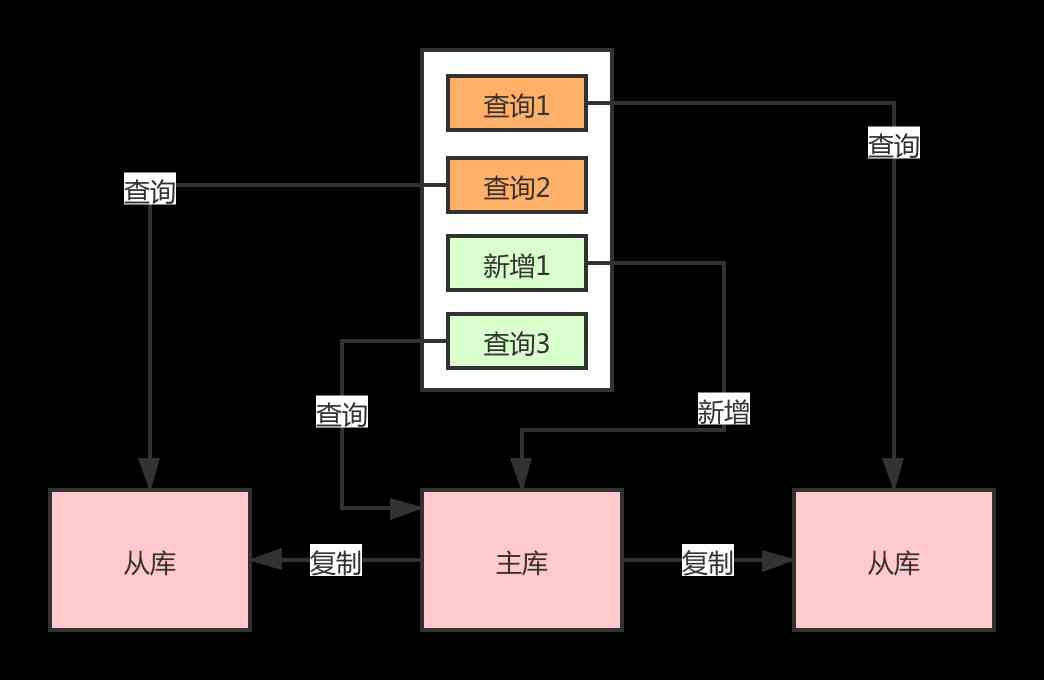
Dynamic forced routing
In the process of function development, it is decided which interfaces should be forced to go to the main library , At this time, we will control the routing in the code , This is the custom annotation mentioned above . If some are not added , However, when running online, it is found that you still need to go to the main database , At this time, we need to change the code and redistribute it .
Dynamic forced routing can be implemented in combination with configuration center , Determine which interfaces are forced to route by configuration , And then in Filter Pass through HintManager To set up , Avoid code changes, restart .
You can also use dynamic routing configuration that is accurate to the business method level .
Traffic distribution
Scene one :
Suppose you have a master node , Two slave nodes , More read requests , The pressure of the two slave nodes is a little bit high . At this time, we can only increase the pressure from the third node . The phenomenon is that the pressure on the main reservoir is not great , Write less , In terms of cost , Can we not add a third slave node ?
Scene two :
Suppose you have a 8 nucleus 64G Main library ,8 nucleus 64G Slave Library ,4 nucleus 32G Slave Library , In terms of configuration ,4 nucleus 32G The processing capacity of the slave database of the system is definitely lower than that of the other two , At this time, if we don't customize the proportion of traffic distribution , There will be a problem caused by the high pressure of low configuration database . Of course, this can also avoid using different rules of the slave Library .
The above scenario needs to be able to manage requests , stay Sharding-JDBC Provides a read-write separation routing algorithm in , We can customize the algorithm for traffic distribution management .
Implementation algorithm class :
public class KittyMasterSlaveLoadBalanceAlgorithm implements MasterSlaveLoadBalanceAlgorithm {private RoundRobinMasterSlaveLoadBalanceAlgorithm roundRobin = new RoundRobinMasterSlaveLoadBalanceAlgorithm();@Overridepublic String getDataSource(String name, String masterDataSourceName, List<String> slaveDataSourceNames) {String dataSource = roundRobin.getDataSource(name, masterDataSourceName, slaveDataSourceNames);// Control logic , For example, different slave nodes ( Different configurations ) There can be different proportionsreturn dataSource;}@Overridepublic String getType() {return "KITTY_ROUND_ROBIN";}@Overridepublic Properties getProperties() {return roundRobin.getProperties();}@Overridepublic void setProperties(Properties properties) {roundRobin.setProperties(properties);}}
be based on SPI Mechanism configuration :
org.apache.shardingsphere.core.strategy.masterslave.RoundRobinMasterSlaveLoadBalanceAlgorithmorg.apache.shardingsphere.core.strategy.masterslave.RandomMasterSlaveLoadBalanceAlgorithmcom.cxytiandi.kitty.db.shardingjdbc.algorithm.KittyMasterSlaveLoadBalanceAlgorithm
Read write separation configuration :
spring.shardingsphere.masterslave.load-balance-algorithm-class-name=com.cxytiandi.kitty.db.shardingjdbc.algorithm.KittyMasterSlaveLoadBalanceAlgorithmspring.shardingsphere.masterslave.load-balance-algorithm-type=KITTY_ROUND_ROBIN
About author : Yin Jihuan , Simple technology enthusiasts ,《Spring Cloud Microservices - Full stack technology and case analysis 》, 《Spring Cloud Microservices introduction Actual combat and advanced 》 author , official account Ape world Originator .
版权声明
本文为[Yin Jihuan]所创,转载请带上原文链接,感谢
边栏推荐
猜你喜欢



随机推荐
6.9.1 flashmapmanager initialization (flashmapmanager redirection Management) - SSM in depth analysis and project practice
tensorflow之tf.tile\tf.slice等函数的基本用法解读
使用NLP和ML来提取和构造Web数据
【C/C++ 2】Clion配置与运行C语言
drf JWT認證模組與自定製
Why do private enterprises do party building? ——Special subject study of geek state holding Party branch
7.3.1 file upload and zero XML registration interceptor
01 . Go语言的SSH远程终端及WebSocket
业内首发车道级导航背后——详解高精定位技术演进与场景应用
哇,ElasticSearch多字段权重排序居然可以这么玩
如何对Pandas DataFrame进行自定义排序
Gradient understanding decline
Details of dapr implementing distributed stateful service
Using tensorflow to forecast the rental price of airbnb in New York City
解決pl/sql developer中資料庫插入資料亂碼問題
DevOps是什么
python 下载模块加速实现记录
Basic principle and application of iptables
快快使用ModelArts,零基础小白也能玩转AI!
Ubuntu18.04上安裝NS-3