当前位置:网站首页>中国提出的AI方法影响越来越大,天大等从大量文献中挖掘AI发展规律
中国提出的AI方法影响越来越大,天大等从大量文献中挖掘AI发展规律
2020-11-06 20:07:00 【顾延笙】

如何从学术文献中挖掘规律,甚至溯源文献的研究方法等?来自天津大学、之江实验室和中科院自动化所的研究者借鉴生化领域中分子标记示踪的思想,对文献正文中反映研究过程的信息进行示踪,挖掘出了方法的演化规律等更多有价值的信息。
将学术文献中蕴含的规律挖掘出来是非常有意义的。借鉴生化领域中分子标记示踪的思想,本文将 AI 文献中的方法、数据集和指标这三种同粒度的命名实体作为 AI 标记,对文献正文中反映研究过程的信息进行示踪,进而为文献挖掘分析开拓新视角,并挖掘更多有价值的学术信息。
首先,本文利用实体抽取模型抽取大规模 AI 文献中的 AI 标记。其次,溯源有效 AI 标记对应的原始文献,基于溯源结果进行统计分析和传播分析。最后,利用 AI 标记的共现关系实现聚类,得到方法簇和研究场景簇,并挖掘方法簇内的演化规律以及不同研究场景簇之间的影响关系。
上述基于 AI 标记的挖掘可以得到很多有意义的发现。例如,随着时间的发展,有效方法在不同数据集上的传播速度越来越快;中国近年来提出的有效方法对其他国家的影响力越来越大,而法国恰好相反;显著性检测这种经典计算机视觉研究场景最不容易受到其他研究场景的影响。
1 介绍 & 相关工作
对学术文献的探索能够帮助科研人员快速和准确地了解领域发展状况以及发展趋势。目前大多数的文献研究严重依赖论文的元数据,包括作者、关键词、引用等。Sahu 等人通过对文献作者数量的分析来探索其对文献质量的影响[19]。Wang 等人通过对引用数量的统计,发布 AI 领域学者高引排行榜 。Yan 等人使用引用数量来估计未来的文献引用[26]。Li 等人使用从文献元数据衍生的知识图谱来比较嵌入空间中的实体相似性(论文、作者和期刊)[12]。Tang 等人基于关键词和作者的国家研究 AI 领域的发展趋势[27]。此外,还有大量基于作者、关键词、引用等对文献进行分析的研究[4, 13, 14, 20, 24]。
由于元数据涉及到的语义内容有限,一些学者对文献的摘要进行分析。摘要是对文献内容的高度概括,主题模型是主要的分析工具[5, 6, 18, 21, 22, 31]。Iqbal 等人利用 Latent Dirichlet Allocation (LDA) 来探索 COMST 和 TON 中的重要主题[8]。Tang 等人利用 Author-Conference-Topic 模型构建学术社交网络[23]。此外,Tang 等人分析发现当前热点研究话题 TOP10 为 Neural Network、Convolutional Neural Network、Machine Learning 等 。但是,基于主题模型对摘要进行主题分析存在主题粒度不一致的问题。例如 Tang 等人发现的当前热点研究话题 top10 里面,Neural Network、Convolutional Neural Network、Machine Learning 三个话题的粒度完全不一致。
摘要中蕴含的主要是结论性信息,缺少反映研究过程的信息。文献正文中包含了研究的具体过程,但目前还基本未见有对文献正文的研究。其中一个主要原因是,论文正文通常包含几千个单词。在远超摘要长度的正文上,利用现有主题模型技术进行分析,可能会导致正文中与主题相关性低的非主题单词也会被作为主题单词。
我们注意到,生物领域中常用分子标记法来追踪反应过程中物质和细胞的变化,从而获取反应特征和规律[29, 30]。受此启发,我们发现在文献的特征与规律挖掘中,方法、数据集、指标能够起到和分子标记物相同的作用。我们将 AI 文献中这三种同粒度的命名实体作为 AI 标记,利用 AI 标记来对正文中反映研究过程的信息进行示踪。图 1 描述了 AI 标记和分子标记的相似性。基于 AI 标记的挖掘补充了常规的基于元数据和基于摘要的挖掘。
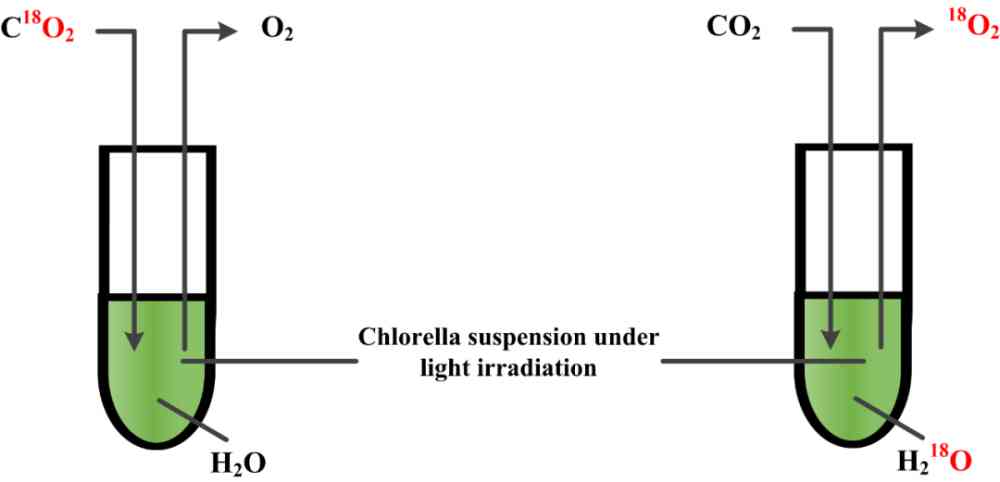
(a) Samuel Ruben 和 Martin Kamen 使用氧同位素 18O 分别标记 H2O 和 CO2,跟踪光合作用中的 O2 的来源。
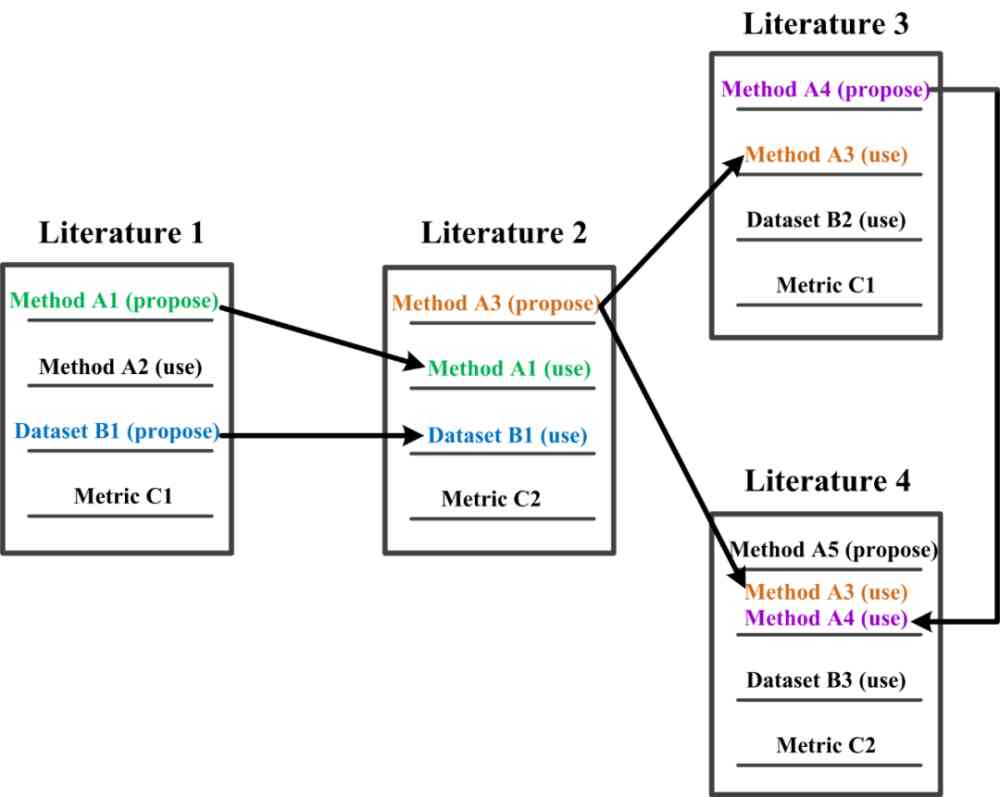
(b) 当 AI 标记被其他文献提出或引用时,就形成了特定研究过程中的踪迹。因此,AI 标记在挖掘文献的特征和规律性方面可以起到与分子标记相同的作用。
Figure 1:AI 标记和分子标记类比图
在我们的研究中,首先利用实体抽取模型对大规模 AI 文献中的 AI 标记进行抽取,并对有效 AI 标记(方法和数据集)进行统计分析。其次,我们对抽取的有效方法和数据集进行原始文献的溯源,对原始文献进行统计分析,并且研究了有效方法在数据集上和在国家之间的传播规律。最后,根据方法和研究场景共现关系来实现对方法和研究场景的聚类,得到方法簇和研究场景簇。基于方法簇及关联数据集绘制路径图,研究同类方法的演化关系,基于研究场景簇来分析方法对研究场景以及研究场景之间的影响关系。
通过基于 AI 标记的 AI 文献挖掘,我们可以得到如下主要发现与结论:
我们从有效方法和数据集的新角度,通过对 AI 标记进行统计分析,获得了反映 AI 领域年度发展情况的重要信息。例如,2017 年无人驾驶领域的经典数据集 KITTI 跻身于 top10 数据集,说明无人驾驶是 2017 年的热门研究主题;
在对 AI 标记进行溯源得到的原始文献的统计分析层面,我们发现新加坡、以色列、瑞士提出的有效方法数量相对较多;从有效方法在数据集上的应用情况来看,随着时间的发展,有效方法应用在不同数据集上的速度越来越快;从有效方法在国家间的传播程度来看,中国提出的有效方法对其他国家的影响力越来越大,而法国恰好相反;
基于方法簇和数据集信息,我们构建了方法路径图,能够展示同一方法簇内各个方法的时间发展史及数据集应用情况;对于场景簇,我们发现与显著性检测相关的经典计算机视觉研究场景最不容易受到其他研究场景的影响。
2 数据
在我们文献挖掘的研究过程中,需要用到大量的文献数据,因此,本节首先介绍了我们收集的文献数据。此外,在研究过程中,我们需要用到两个机器学习模型。因此,本节对这两个模型的训练数据也分别进行了介绍。
2.1 收集的文献数据
我们使用中国计算机学会(CCF) 等级(Tier-A、Tier-B 和 Tier-C)中的 AI 期刊和会议列表,收集了 2005 年至 2019 年出版的 122,446 篇论文。用 GROBID 将 PDF 格式的论文转换为 XML 格式,从 XML 格式论文中提取标题、国家、机构和参考文献等信息。为了便于阅读,我们将收集到的这些数据称为 CCF corpus。
2.2 章节分类的训练数据
通常,一篇 AI 文献的正文包括引言、方法介绍、实验章节、结论四个部分。本文利用章节分类策略将 AI 文献的正文按上述四部分进行分类。
我们随机选取 2000 篇 CCF corpus 中的文献,并招募 10 名 AI 领域研究生标注这 2000 篇论文中的 63110 个段落。我们称该数据为 TCCdata。TCCdata 用来构建章节分类中的 BiLSTM 分类器[3]。TCCdata 中每类章节的数量以及每类章节包含的段落数量如表 1 所示。
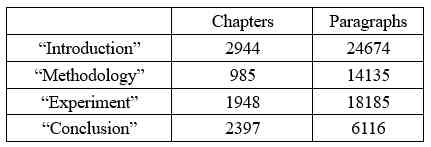
Table 1:TCCdata 中章节和段落的数量
2.3 AI 标记抽取的训练数据
为了训练 AI 标记抽取模型,我们随机选取 1000 篇 CCF corpus 中的文献。将文献正文中方法章节和实验章节的内容按标点符号切分成句子,并招募 10 名 AI 领域研究生对这些句子进行标注。我们采用 BIO 标注策略标注方法、数据集、指标这三种实体,利用机器之心编译好的方法、数据集、指标作为标注参考。最后我们得到 10410 个句子,称之为 TMEdata。
在构建 AI 标记抽取模型时,我们将 TMEdata 按照 7.5:1.5:1 的比例划分成训练集、验证集和测试集。训练集、验证集和测试集中包含的三种 AI 标记的数量如表 2 所示。
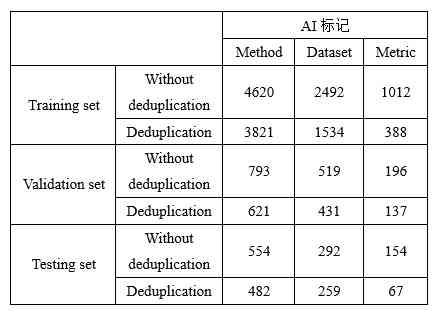
Table 2:TMEdata 中 AI 标记的数量
3 方法
本节介绍本项研究所涉及的具体方法,包括章节分类、AI 标记的抽取与归一、AI 标记原始文献的溯源、方法和研究场景的聚类、方法簇内路径图的生成以及研究场景簇的影响程度。
3.1 章节分类
在一篇 AI 文献正文中,位于方法章节和实验章节的 AI 标记对该篇文献起着实质性作用,因此我们只对 AI 文献正文中方法章节和实验章节的 AI 标记进行抽取。但是,由于 AI 文献正文结构的多样性,难以用简单的规则策略对 AI 文献正文章节进行较为准确的分类。因此,本文提出了BiLSTM 分类器和规则相融合的章节分类策略。
3.1.1 提出的分类策略
章节分类的整体流程如图 2 所示。对于一篇 AI 文献的正文内容,我们首先利用规则匹配(关键词和顺序)对正文章节进行标注。对于匹配到的章节,则输出章节标签。对于未匹配到的章节,则将章节下的段落输入到基于 TCCdata 训练的 paragraph-level BiLSTM 分类器进行预测。接下来对相同章节标题下的段落预测结果进行投票,将出现次数最多的标签作为该章节类别。最后,将基于规则匹配得到的章节标签与基于投票得到的章节标签结合,得到整个正文的章节标签。
我们采取了常规的 one layer BiLSTM 架构。其中最大句子长度选取为 200,词向量的维度选取为 200,hidden 维度选取为 256,batchsize 选取为 64。采用交叉熵作为损失函数,TCCdata 作为训练数据。
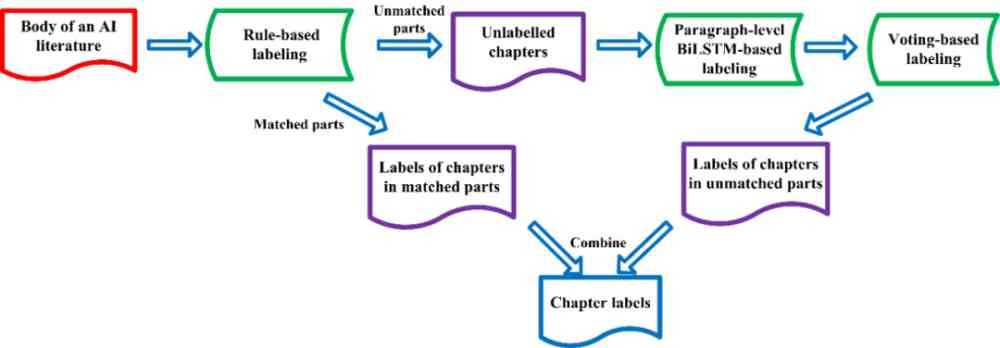
Figure 2:章节分类整体流程
3.1.2 评估结果
我们将 TCCdata 以 8:1:1 的比例划分成训练集、验证集、测试集。在测试集上,我们对规则匹配、paragraph-level BiLSTM、规则匹配与 paragraph-level BiLSTM 结合这三种章节分类方式分别进行了评估。结果表明,仅利用规则匹配,准确率为 0.793。仅利用基于 TCCdata 训练的 paragraph-level BiLSTM,准确率为 0.792。将规则匹配与基于 TCCdata 训练的 paragraph-level BiLSTM 结合后,准确率达到了 0.928。
3.2 AI 标记的抽取与归一
AI 标记的抽取与归一具有很大的挑战。由于每年都会涌现出大量 AI 文献,新的 AI 标记数量不断增加,形式也多种多样,一些常见词可能也会被当作数据集。例如 DROP 在 2019 年发表的 [2] 中被当成数据集。AI 标记的命名没有特定的规范。此外,一些 AI 标记存在歧义的问题。例如 CNN,既可以表示 Cable News Network 数据集,又可以表示 Convolutional Neural Networks 方法。比如 LDA,既可以表示 Latent Dirichlet Allocation 方法,又可以表示 Linear Discriminant Analysis 方法。
3.2.1 AI 标记抽取模型
AI 标记抽取是一个典型的命名实体识别问题。本文采用的 AI 标记抽取模型基于目前经典的 CNN+BiLSTM+CRF 框架[15],并作了小的改进,如图 3 所示。
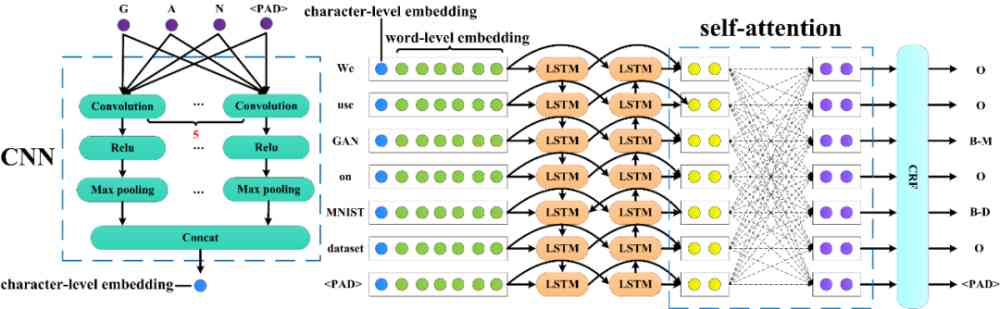
Figure 3:AI 标记抽取模型结构
对于一个输入句子 ,其中 w_i 表示第 i 个单词。首先将每个单词切分成字符级,通过 CNN 网络获取到每个单词的 character-level embedding。然后经过 Glove embedding[17] 模块获取到每个单词的 word-level embedding。将句子中每个单词的 character-level embedding 与每个单词的 word-level embedding 拼接,然后送入到 Bi-LSTM。使用 self-attention[25] 计算每个单词与其他所有单词之间的关联。最后,将通过 self-attention 获取到的隐向量送入 CRF[10],得到每个单词的标签序列 y。y∈,分别对应方法、数据集、指标和其他。
3.2.2 实验设置
模型参数设置如下。最大句子长度选取为 100,最大单词长度选取为 50,batchsize 选取为 16。字符级 CNN 网络使用 5 个并列的 3D 卷积 - 激活 - 最大池化,5 次卷积中每次分别用 10 个 1*1*50,1*2*50,1*3*50,1*4*50,1*5*50 的 3 维卷积核,激活函数均使用 ReLU。最后将 5 次得到的结果进行拼接,得到每个单词 50 维字符级词向量。Bi-LSTM 选用一层,hidden 维度选为 200,self-attention 的 hidden 维度选为 400。
3.2.3 评估结果
利用原始样本与其对应的小写化后的样本对模型进行训练。在测试时,我们分别对测试样本(1040 个句子)及其对应的 1040 个小写化后的样本进行测试。AI 标记抽取模型的评估结果如表 3 所示。
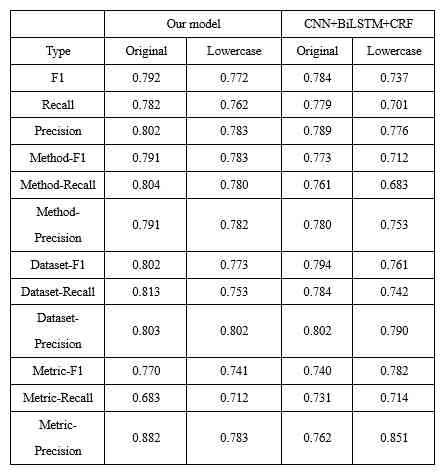
Table 3:AI 标记抽取模型评估结果
由表 3 可看出,相比于传统的 CNN+BiLSTM+CRF 模型,我们的模型无论是对于 AI 标记的整体识别,还是各个 AI 标记的单独识别,在 F1、Recall、precision 三个指标上效果均有所提高。此外,结合黑白名单等规则进行优化后,我们模型的 F1 为 0.864,Recall 为 0.876,Precision 为 0.853。
3.2.4 AI 标记归一
对于一些有多种表示形式的 AI 标记,我们制定了一系列的规则策略进行归一化。例如,对于方法「Long Short-Term Memory」,我们将「LSTM」、「LSTM-based」、「Long Short-Term Memory」等归一化成「LSTM (Long Short-Term Memory)」。对于指标「accuracy」,我们将「mean accuracy」、「predictive accuracy」等包含「accuracy」的指标都归一化成「accuracy」。详细归一化策略参见附录 A。对于出现的一些一词多义的情况,考虑到很多 AI 标记能够根据实体类别进行区分,且同一类型的一词多义出现概率很小,我们不对这种情况专门进行处理。
3.3 AI 标记原始论文溯源
要想得到一个方法或数据集从提出开始逐渐被其他文献引用的研究踪迹,首先需要追溯到方法和数据集的原始文献。我们将追溯到的方法和数据集原始文献称为「原始论文」。我们只对明确出现在后续文献的方法或者实验章节的方法或数据集进行追溯。
3.3.1 溯源方法
考虑到在一篇文献中,方法或数据集在被引用时,后面经常会附有其对应的原始论文。因此,在我们提出的溯源方法中,对于每个 AI 标记,我们首先找出引用该 AI 标记的文献集合。对于文献集合中的每篇文献,查找该 AI 标记出现的句子集合。对于每个句子,查看该 AI 标记后面的一个位置或者两个位置是否有参考文献,将有参考文献的信息记录下来。最后,将每个 AI 标记对应的引用数量最多的文献作为其原始文献。
3.3.2 评估结果
利用本文的溯源方法,我们追溯到了 CCF corpus 中提出的被明确引用次数大于 1 的方法的原始文献 4105 篇,方法 5118 个。追溯到 CCF corpus 中提出的被明确引用次数大于 1 的数据集的原始文献 949 篇,数据集 1265 个。
我们随机抽取得到的结果中被明确引用次数为 5、4、3、2 的方法各 200 个,被明确引用次数为 5、4、3、2 的数据集各 100 个。对这 800 个方法和 400 个数据集对应的原始文献结果进行人工评估,评估结果见表 4。结果准确率都超过了 90%。
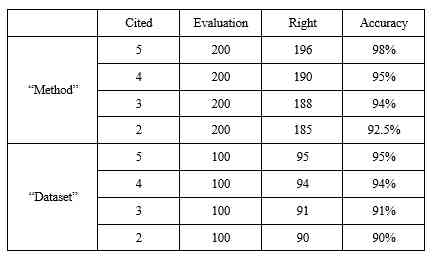
Table 4:溯源方法的评估结果
3.4 方法和研究场景的聚类
单独的数据集或者单独的指标可能会对应多个不同研究场景。例如 CMU PIE 数据集与 accuracy 指标的组合表示为人脸识别研究场景,IMDB 数据集与 accuracy 指标的组合表示为影评情感分类研究场景。因此,我们将一篇文献中的数据集和指标进行组合来代表研究场景,进而得到大量冗余的研究场景。
很多指标是同时应用的,比如 precision、recall 等,因此,首先需要将指标进行合并,以减少研究场景的冗余。
我们根据方法与研究场景在文献中的共现次数构建了方法 - 研究场景矩阵。由于数据集和指标的组合较多,使得研究场景的数量非常大,造成了方法 - 场景矩阵的高维稀疏。为解决该问题,我们借鉴 Nonnegative Matrix Factorization (NMF) [1, 11]和谱聚类[16],构建了降维及聚类算法。
首先,我们将数据集和指标组合成研究场景,根据方法和研究场景共现关系,得到方法 - 研究场景共现矩阵。其次,基于 NMF 和谱聚类对方法进行聚类,得到 500 类方法簇。然后,根据指标 - 方法簇共现矩阵对指标进行谱聚类,得到 50 类指标簇。将指标簇与数据集组合成研究场景,根据方法 - 研究场景共现矩阵对研究场景进行谱聚类,得到 500 类研究场景簇。我们期望每个簇中的研究场景数量大体比较均衡,因此将包含研究场景数量 500 以上的簇再次根据方法 - 研究场景共现矩阵进行谱聚类。一共有 2 个簇中包含的研究场景数量在 500 以上,通过再次聚类后得到 200 类研究场景簇。将这 200 类研究场景簇与其余 498 类研究场景簇合并后得到 698 类研究场景簇 。
3.5 方法簇内路径图的生成
方法路径图描述了不同但高度相关的方法的演变[28]。在通过上述聚类算法得到的方法簇中,每一类方法簇都是由相同类型方法组成的。在这个簇里面,如果能够构建一个按照时间的方法演化图,并且加入数据集信息,将会为相关的研究提供非常有启发的信息。
本文提出的方法簇内路径图的生成过程如下所示:
对于一个方法簇,获取其包含的所有方法的原始文献信息:提出时间、方法在提出该方法的论文中所在的章节、该方法对应原始论文使用的数据集 ;
对于该方法簇中的每种方法 M_i,找出该方法原始论文的实验章节所提到的其它方法 。构建 M_i 到 每个方法的路径 M_iM_j, M_j,∈。M_i 与 M_j 之间的边为 M_i 和 M_j 进行对比时使用的数据集;
合并连续路径,得到同类方法下方法的路径图。(例如, 如果有 (M_1M_2), (M_2M_3), (M_1M_3),只保留(M_1M_2), (M_2M_3))。
我们的路径图构建同 [28] 中的方法存在两点区别:1)我们增加了数据集的关系,方法和方法之间通过数据集建立联系,从而提供了额外的信息;2)我们通过大规模文献来获取方法,可以同时得到大量的路径图。
3.6 研究场景簇的影响程度
本文分析了研究场景簇之间的影响程度,以及追溯到的有效方法对其他研究场景簇的影响程度。
根据研究场景与研究场景簇的对应关系,我们找出每篇文献涉及的研究场景所对应的研究场景簇。考虑到一篇论文中一般只涉及 1 类主要的研究场景,因此,我们取每篇文献出现次数最多的研究场景簇作为该文献对应的研究场景簇。最终我们得到了 CCF corpus 中 45,215 篇文献对应的研究场景簇 。结合这 45,215 篇文献及其提出的有效方法,我们分析了这 45,215 篇文献中研究场景簇之间的相互影响关系,以及这些文献提出的有效方法对其他研究场景簇的影响。
我们将研究场景簇为 s 的文献集合定义为 Ls,。文献提出的有效方法三年内被 引用,场景簇非 s 的文献集合为 。研究场景簇 s 对其他研究场景簇 \s 的影响程度比率计算如公式 1 所示:
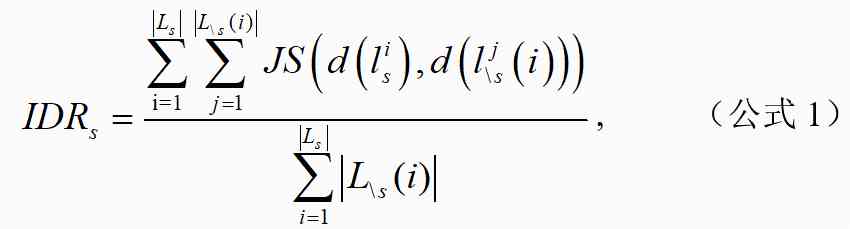
其中,为文献对应的研究场景簇在 45,215 篇论文中的分布,表示文献对应的研究场景簇在 45,215 篇论文中的分布。为计算与的 JS 散度。
此外,本文分析了这 45,215 篇文献提出的有效方法对其他研究场景簇的影响。
我们将有效方法 m 对应的原始文献表示为 l_m,文献 l_m 对应的研究场景簇为 s,三年内引用了有效方法 m 且场景簇非 s 的文献集合为 。有效方法 m 对研究场景簇的影响程度 ID_m 和影响程度比率 IDR_m 计算公式如下:
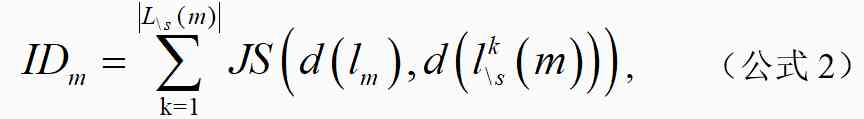
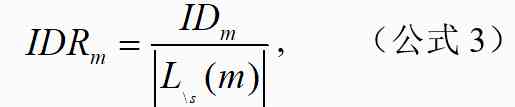
其中,为 l_m 文献对应的研究场景簇在 45,215 篇论文中的分布,表示为文献对应的研究场景簇在 45,215 篇论文中的分布。为计算与的 JS 散度。
4 结果
本节基于前述的方法,包括章节分类、AI 标记的抽取与归一、AI 标记原始文献的溯源、方法和研究场景的聚类、方法簇内路径图的生成以及研究场景簇的影响程度,对所收集的 CCF corpus(2005-2019 年的 AI 论文)进行基于 AI 标记的统计分析、传播分析与挖掘,并对结果进行展示。
4.1 有效 AI 标记的统计
我们通过提取 CCF corpus 中的 AI 标记,得到 171,677 个机器学习方法实体、16,645 个数据集实体、1551 个指标实体。考虑到很多只出现一次的 AI 标记基本上没有丰富的信息,我们只对出现 1 次以上的 AI 标记进行分析。我们将出现次数大于 1 的 AI 标记称为有效 AI 标记。
本节介绍了有效 AI 标记关于国家和出版地点的分析,以及对每年使用数量排名前十的有效 AI 标记的分析。
4.1.1 有效 AI 标记关于国家的分析
一个国家提出有效 AI 标记的数量能够体现出该国 的 AI 研究实力。因此,我们首先对 CCF corpus 中各个国家在 2005-2019 年提出的有效方法和数据集的数量分别进行了统计,如图 4 和图 5 所示。
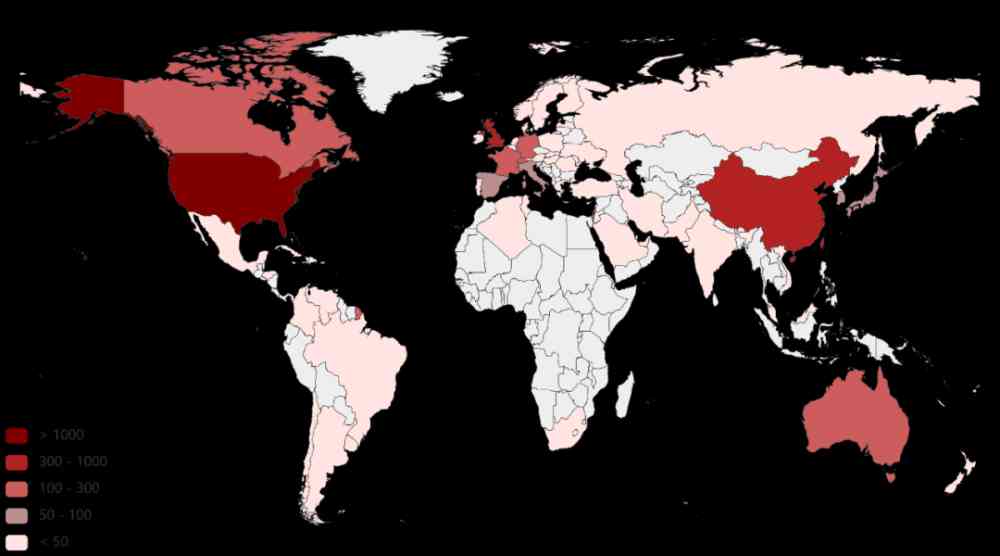
Figure 4:追溯到的由 CCF corpus 提出的有效方法在不同国家中的数量分布
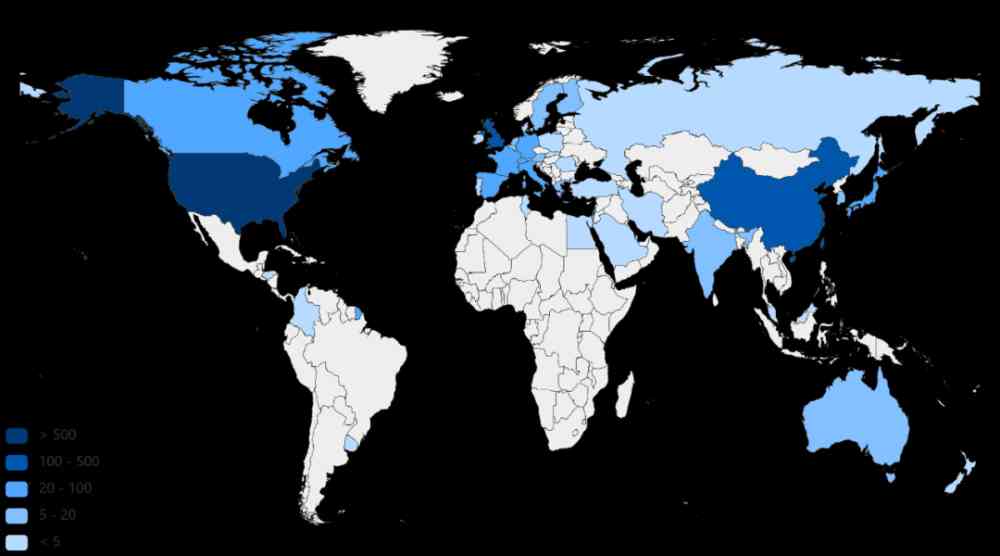
Figure 5:追溯到的由 CCF corpus 提出的有效数据集在不同国家中的数量分布
由图 4 我们可以看出,提出有效方法的数量排名前三的是美国、中国、英国。德国、法国、加拿大、新加坡、澳大利亚等国家提出的有效方法数量次之。由图 5 我们可以看出,提出有效数据集的数量排名前三的也是美国、中国、英国。德国、瑞士、加拿大、法国、新加坡、以色列等国家提出的有效数据集的数量次之。由此可以看出,美国、中国、英国是机器学习领域中相对更为活跃的国家。德国、法国、加拿大、新加坡等国家虽与美国、中国、英国有一定差距,但是相对而言也比较活跃。
为了降低各个国家论文发表数量对分析结果产生的影响,我们对 CCF corpus 中提出有效方法数量排名前十的国家的有效方法提出率和 CCF corpus 中提出有效数据集数量排名前十的国家的有效数据集提出率进行了分析。
国家 c 有效方法的提出率 MRc、有效数据集的提出率 DRc 计算如公式 4 和 5 所示。
其中, 表示 CCF corpus 中国家 c 提出的所有有效方法的集合, 表示 CCF corpus 中国家 c 提出的所有有效数据集的集合, 表示在 CCF corpus 中国家 c 的所有文献的集合。
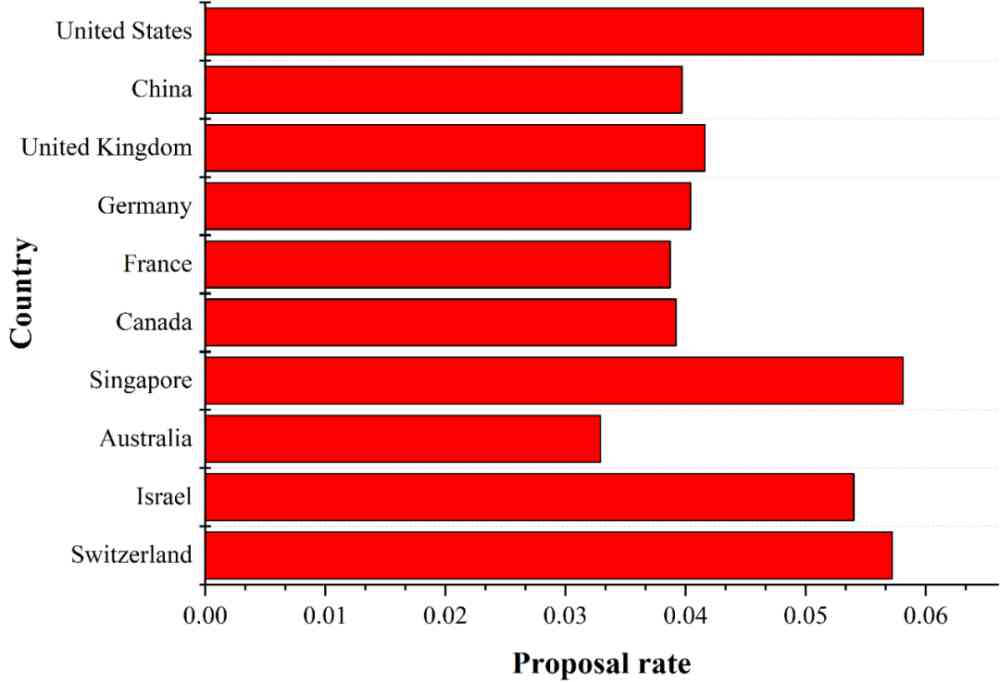
(a) 图 4 中排名前 10 国家的有效方法提出率。
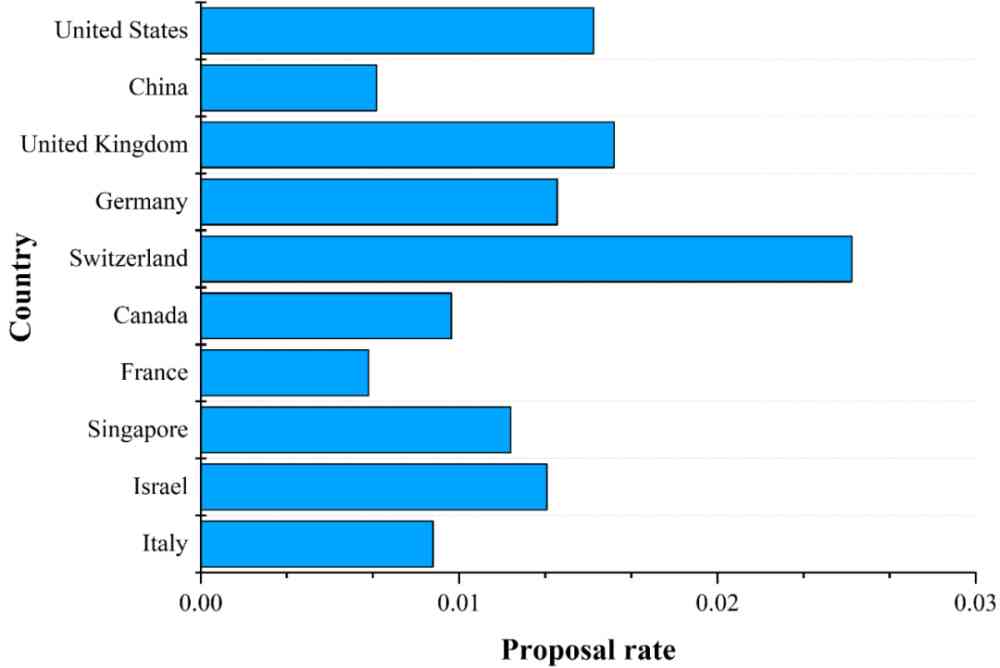
(b) 图 5 中排名前 10 国家的有效数据集提出率。
Figure 6:图 4 和图 5 中排名前 10 国家中有效 AI 标记的提出率。国家提出的 AI 标记的数量从上到下递减。
基于公式(4)和(5),我们计算了提出有效方法数量排名前 10 的国家中有效方法的提出率和提出有效数据集数量排名前 10 的国家中有效数据集的提出率,结果如图 6 所示。
由图 6a 我们可以看出,美国提出有效方法的数量和比例都稳居第一位。中国和英国虽然提出有效方法的数量比较高,但是提出有效方法率要低于新加坡、以色列、瑞士。由图 6b 可知,瑞士虽然提出有效数据集的数量要低于美国、中国、英国、德国,但是在数据集的提出率上是最高的,反映出瑞士特别重视 AI 数据集。
4.1.2 有效 AI 标记关于出版地点的分析
一个出版地点提出有效 AI 标记的数量能够体现出该出版地点的质量。出版地点 v 有效方法的提出率 MRv、有效数据集的提出率 DRv 计算如公式 6 和 7 所示。
其中,M_v表示 CCF corpus 中出版地点 v 提出的所有有效方法的集合,D_v表示 CCF corpus 中出版地点提出的所有有效数据集的集合,L_v表示在 CCF corpus 中发表在出版地点 v 的所有文献的集合。
利用公式 6 和 7,我们计算了提出有效方法数量排名前 10 的出版地点中有效方法的提出率和提出有效数据集数量排名前 10 的出版地点中有效数据集的提出率,结果如图 7 所示。
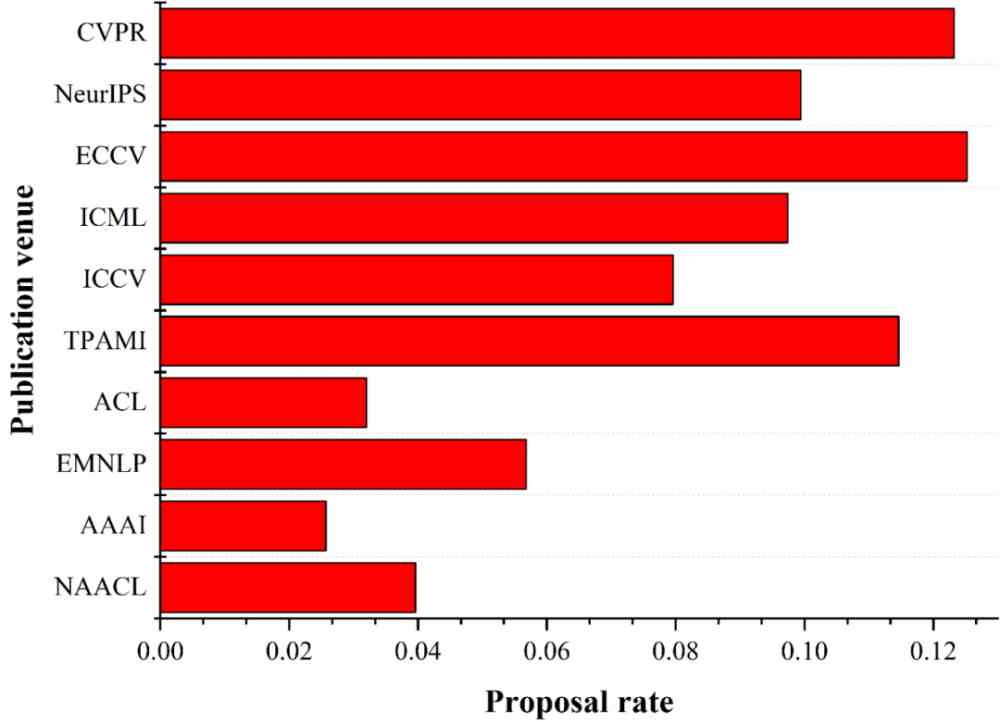
(a) 提出有效方法排名前 10 的出版地点的有效方法提出率。
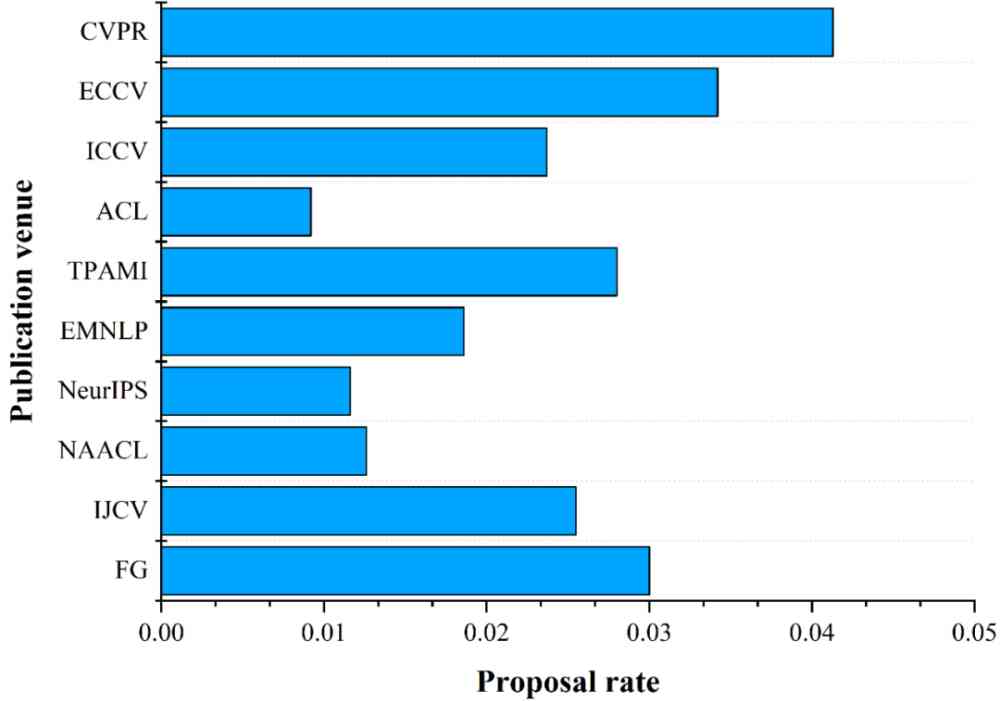
(b) 提出有效数据集排名前 10 的出版地点的有效数据集提出率。
Figure 7:提出有效 AI 标记排名前 10 的出版地点的有效 AI 标记提出率。出版地点提出的 AI 标记的数量从上到下递减。
由图 7a 我们可以看出, ECCV 虽然是 CCF 的 B 类会议,但是其有效方法提出率要高于 CVPR。在提出有效方法的数量排名前十的出版地点中,有 7 个都是 A 类的出版地点,这说明 A 类出版地点中的论文质量确实要比 B 和 C 类的高。
图 7b 展示了有效数据集的分布情况。我们可以看出,CVPR 提出更有效数据集的数量和提出率都排名第一。ECCV 虽然是 B 类会议,但是提出有效数据集的数量和提出率仅次于 CVPR。在提出有效数据集的数量排名前十的出版地点中,有 6 个是 A 类的出版地点,也反映出 A 类出版地点确实更关注有效数据集的提出。
4.1.3 每年使用排名数量前十的有效 AI 标记
本节分别对 2005-2019 年间每年使用的有效方法和有效数据集的数量进行了统计分析。
(1) 每年使用数量排名前 10 的有效方法
我们对 2005-2019 年间每年使用的有效方法数量进行了统计,每年排名前十的有效方法如图 8 所示。
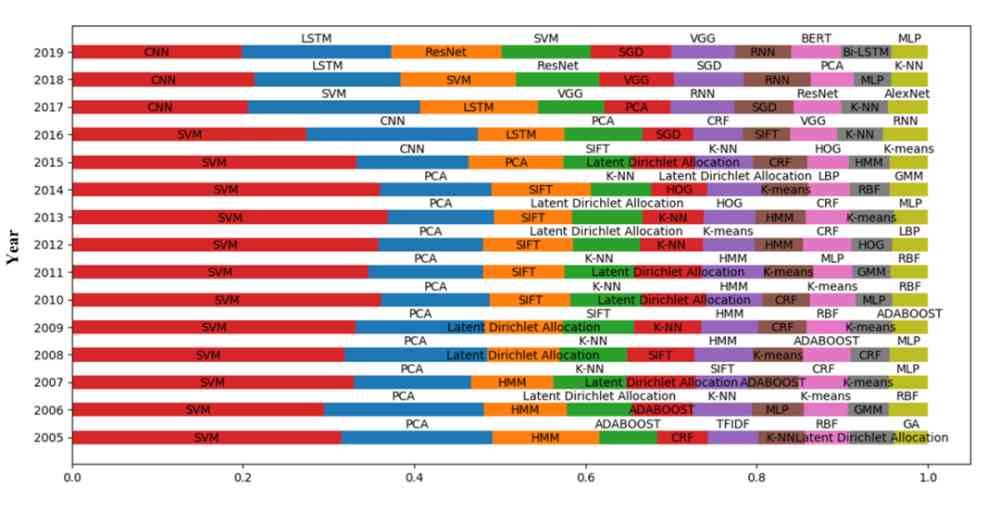
Figure 8:每年使用数量排名前十的有效方法
由图 8 可以看出,SVM 作为一种传统的机器学习方法,每年都被广泛使用。LDA 作为用于文本挖掘的经典的主题模型,在 2005-2015 年间一直被广泛应用。但是随着深度学习的快速发展,在 2015 年以后,其使用占比明显下降。2015 年以后,深度学习越来越流行,深度学习方法成为 AI 领域的主流。
计算机视觉和自然语言处理是 AI 研究中的两个重要研究学科。由图 8 可知,计算机视觉中的方法始终占据很大的比例,这表明计算机视觉一直是 AI 的热门研究分支。
(2) 每年使用数量排名前 10 的有效数据集
我们对每年使用的有效数据集的数量进行了统计,每年排名前十的有效数据集如图 9 所示。
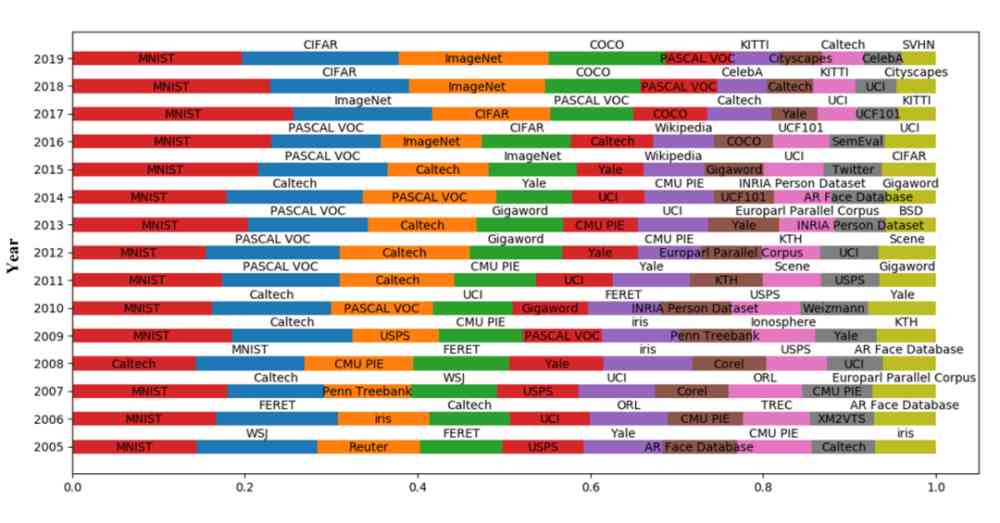
Figure 9:每年使用数量排名前十的有效数据集
由图 9 可知,MNIST 作为最经典的数据集之一,每年都被普遍使用。2016 年,SemEval 数据集进入了排名前十的行列,而 SemEval 数据集是情感分析常用数据集。由此可看出,2016 年,情感分析受到了广泛关注。2017 年,KITTI 数据集进入了排名前十的行列,而 KITTI 数据集是无人驾驶领域经典数据集,说明 2017 年无人驾驶领域受到了广泛关注,并且在 2017-2019 年期间,KITTI 数据集在每年前十数据集中的占比逐渐提高。此外,由该图我们还可以看出,一般数据集在发布后,至少需要两年时间才会得到认可和在相应领域的广泛使用。比如 PASCAL VOC 数据集 2007 年发布,2009 年被广泛使用;Weizmann 数据集 2006 年发布,2010 年被广泛使用;COCO 数据集 2014 年发布,2016 年得到广泛使用。
人脸识别是计算机视觉领域中比较热门的研究方向。我们对每年排名前 10 的有效数据集中人脸识别数据集的占比情况进行了统计,如表 5 所示。
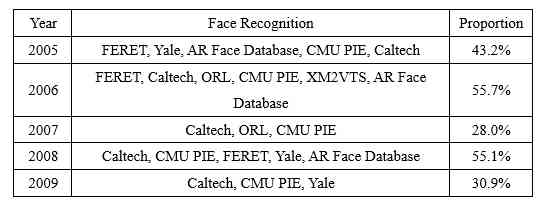
Table 5:每年排名前 10 的有效数据集中人脸识别数据集的占比
表 5 显示,2005-2019 年人脸识别的常用数据集有 Caltech、Yale、CMU PIE、CelebA。Caltech 在每年排名前十的有效数据集中均出现且占比都较高。Yale 出现的年份也很多,但是在 CelebA 数据集出现后,其地位就被 CelebA 替代。
4.2 有效方法的传播
本节对有效方法在数据集上的传播和在国家之间的传播分别进行了分析 。
4.2.1 在数据集上的传播
我们对 2005 年到 2019 年每年由 CCF corpus 中的文献提出的有效方法在数据集上的传播情况进行了分析。y 年提出的有效方法于 y 到 y+△y 时间区间内在数据集上的传播率计算公式如下:
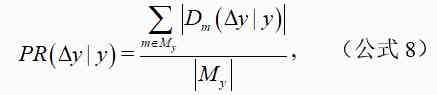
其中,M_y 表示所有在 y 年被提出的方法,表示在 y 到 y+△y 时间区间内被应用在方法 m 上的数据集集合,。
基于公式 8,我们得到每年由 CCF corpus 提出的有效方法一年内、两年内、三年内在数据集上的传播率,如图 10 所示。
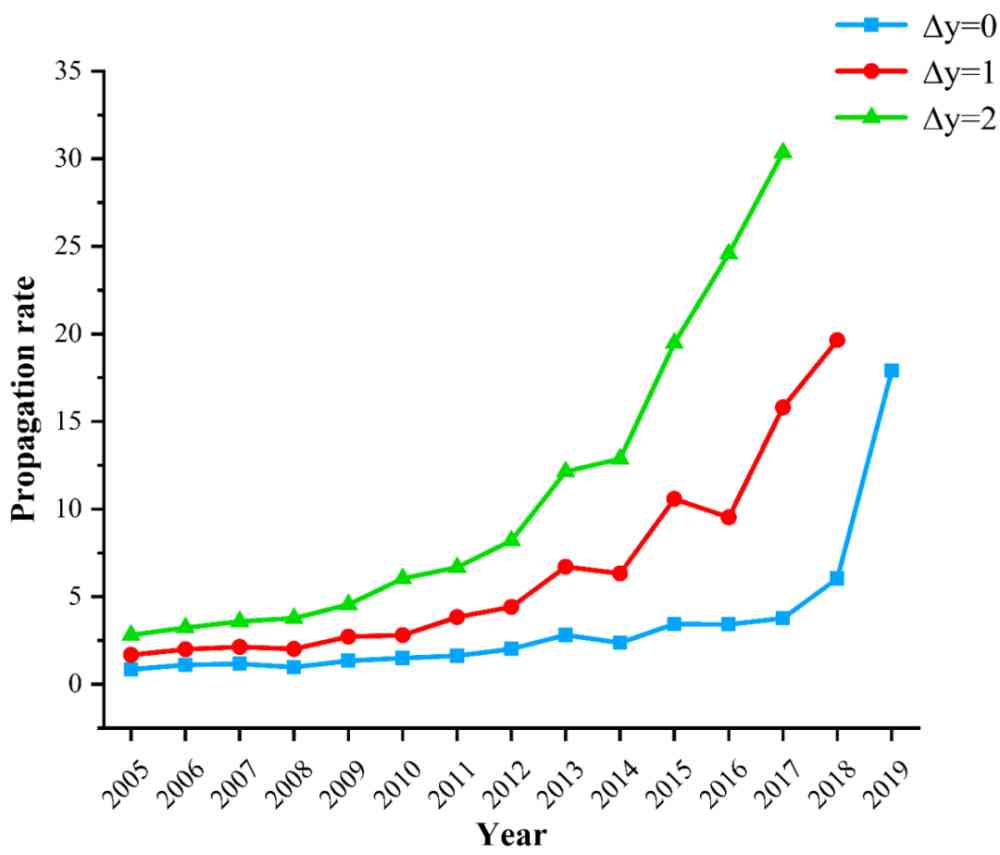
Figure 10:有效方法在数据集上的传播率
由图 10 可知,随着时间的发展,有效方法在数据集上的传播率呈逐渐上升的趋势,各种知名方法在文献未正式发表以前就通过类似 arxiv 的渠道为人们熟知。
此外,我们还对 2005 年由 CCF corpus 中原始文献提出的 Large margin nearest neighbor (LMNN) 方法和 2018 年由 CCF corpus 中原始文献提出的 Transformer 方法从传播到其他文献开始,两年内在数据集上的应用情况进行了对比,如图 11 所示。
由图 11 可知,Transformer 在 2018 年被提出后,2018 年和 2019 年被应用在了很多不同数据集上。然而 2005 年被提出的 LMNN,在 2006 年才开始被其他文献引用,应用在不同的数据集上。并且,我们还可以明显看出,Transformer 从传播到其他文献开始,两年内在数据集上的应用数量和种类要远多于 LMNN。这也反映出随着时间的发展,方法在数据集上的传播速度越来越快。
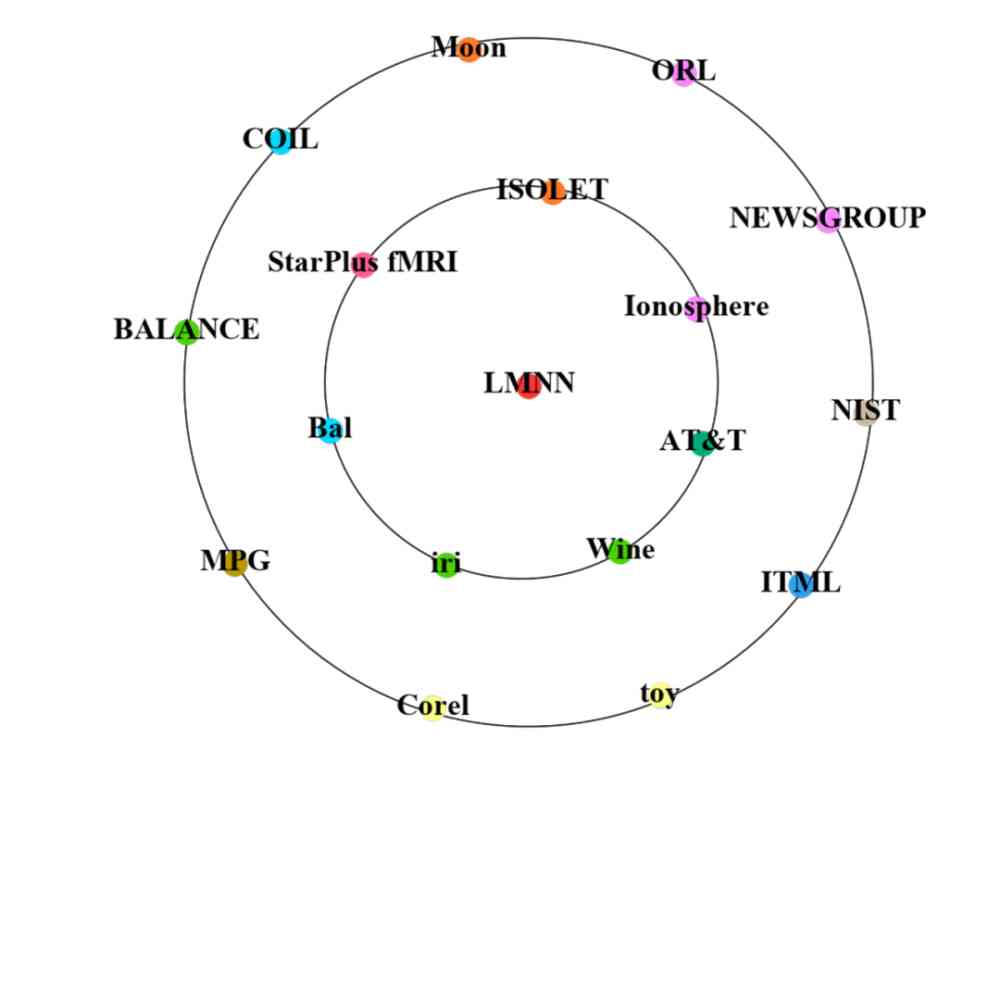
a) LMNN 2006 年(内圈)和 2007 年应用的数据集。
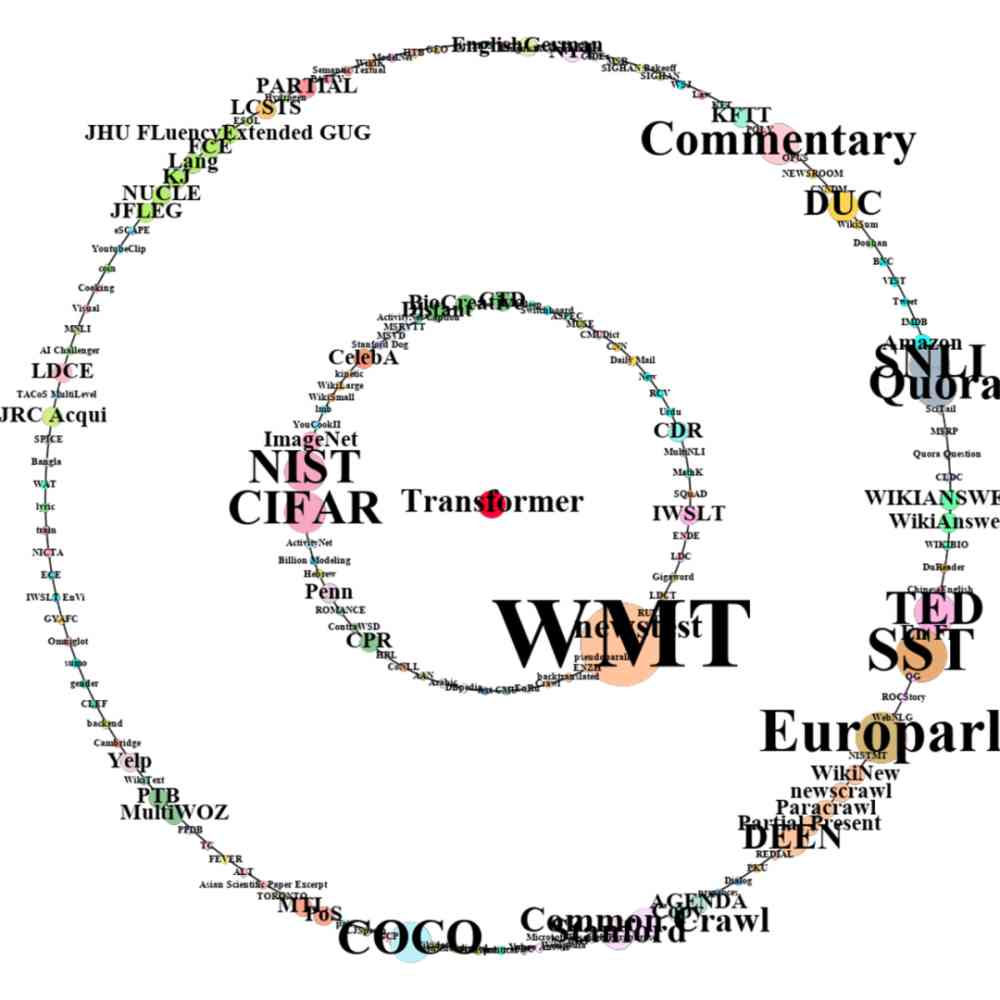
b) Transformer 2018 年(内圈)和 2019 年应用的数据集。
Figure 11:有效方法应用的数据集,中间的红点表示方法。内圈和外圈由许多数据集点组成,在数据集点中,点的大小表示该方法应用的数据集的数量,不同数据集点的颜色表示不同的研究场景。
4.2.2 在国家间的传播
本节对有效方法在国家间的传播进行了分析。我们将国家 c 提出的所有有效方法的集合定义为M_c,。在 y 到 y+△y 时间区间内,有效方法由国家 c 到国家 c’ 的传播程度的计算如公式 9 所示。
其中为在 y 到 y+△y 时间区间内,在实验章节引用了 m 的 c’ 国论文集合。为在 y 到 时间区间内,在方法介绍章节引用了 m 的 c’ 国论文集合, 。
基于公式 9,我们以 5 年为一个阶段,对 2005-2009 年、2010-2014 年、2015-2019 年有效方法在国家之间的传播程度进行了计算。每个阶段排名前十的国家之间有效方法传播程度如图 12 所示。
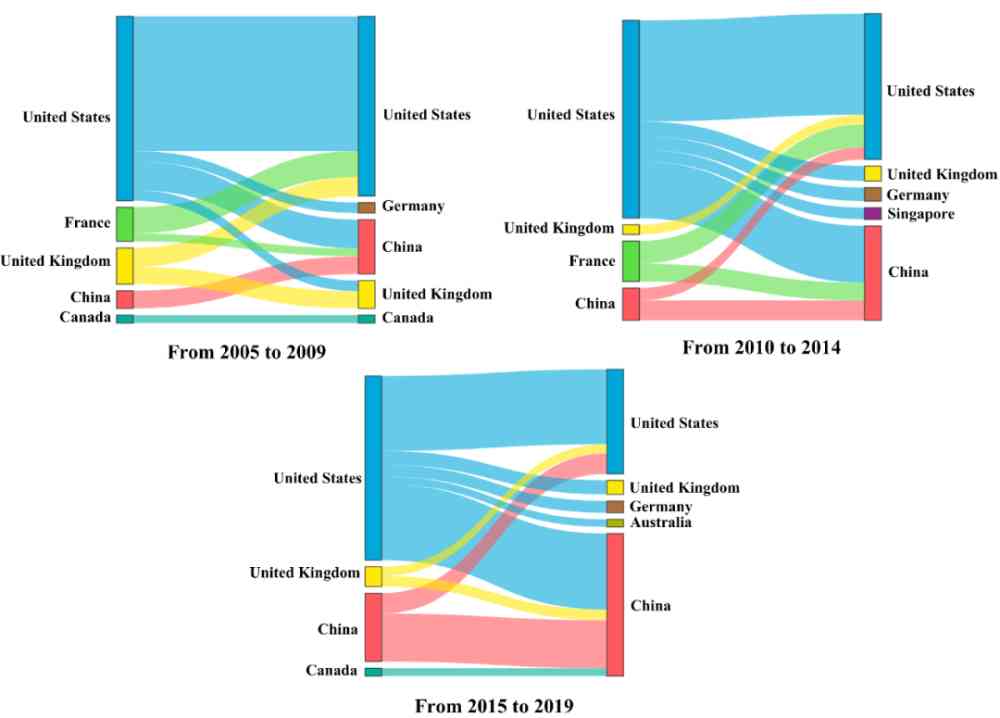
Figure 12:2005 年到 2019 年,有效方法在国家之间的传播程度的 top10。
从图 12 可以看出,有效方法在 2005-2009 年更多地从美国、法国和英国传播到其他国家。相对而言,中国提出的有效方法传播程度较低。在 2010-2014 年,中国提出方法的传播程度逐渐增大,并且到了 2015-2019 年,中国提出方法对美国的传播程度跃到了第四位。反映出中国的 AI 发展越来越好。相反,法国提出的方法在 2005-2014 年传播程度比较大。而到了 2015-2019 年,法国提出的方法的传播程度排到了十名以后,反映出近几年法国的 AI 发展相对较慢。
4.3 路径图和研究场景的结果
本节介绍了方法的路径图和关于研究场景簇的分析。
4.3.1 方法路径图的案例研究
我们对知识图谱中的知识表示学习和生成对抗这两个常见的方法类进行了分析。利用我们提出的路径图生成算法对'Trans' 簇和'GAN' 簇内的方法路径图进行了绘制。
图 13 是'Trans' 簇中的方法路径图。经与 Ji 等人 [9] 发表的文献内容核对,'Trans' 簇中的方法路径图包含上述论文提到的 76% 的知识表示学习算法,同时也包含一些与知识表示学习相关的方法。例如:GMatching 和 KGE 是图嵌入方法,HITS 是链接分析方法。
此外,由图 13 可以直观看到每个方法的提出时间,例如:TransE 在 2013 年提出,TransH2014 年提出。同时,我们可以看到 TransE 方法节点的出度最大,一方面说明很多方法比如 CTransR、RTRANSE 等是从 TransE 方法受到启发,进而拓展出新方法。另一方面,也说明 TransE 是代表性知识表示学习方法,很多新提出的知识表示类方法常与其进行对比。此外,从图中,我们也可以看出'Trans' 簇中的方法使用的数据集情况。
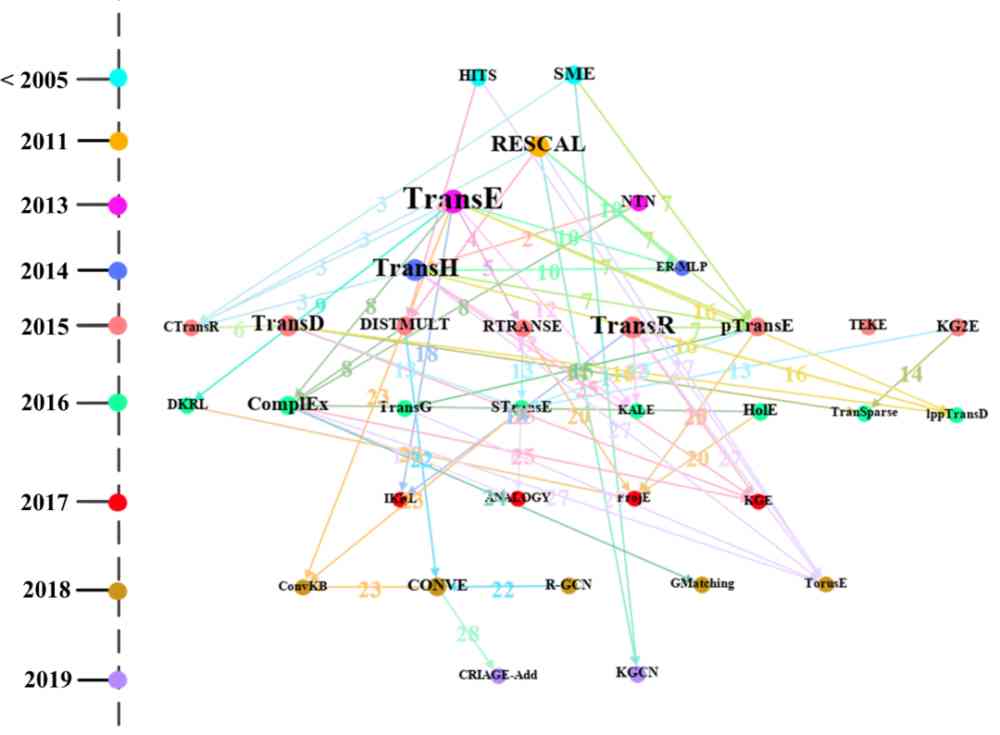
Figure 13:'Trans' 簇中方法的路径图,图中点的颜色表示年份,点的大小表示出度,线的颜色表示数字代表的数据集。
图中数字表示路径 MiMj 中 Mi 和 Mj 进行对比时使用的数据集,具体为:1: WIKILINKS 2: WIKILINKS;WN;FB 3: WordNet;FB;WN;Freebase 4: ClueWeb 5: Family 6: FB;WN 7: Freebase;NYT;YORK 8: WordNet;Freebase;WN 9:null 10: RESCAL;WordNet;WN 11: Freebase 12: WordNet;Freebase 13: ClueWeb;WN 14: FB;WN 15: WordNet;FB;WN;Freebase 16: FB;WN 17: null 18: KG;ImageNet;WN 19: null 20: DBpedia 21: FB;WN 22: WN;YAGO;WNRR 23: WNRR;HIT;MR
24: Wikione;NELLone;NELL 25: WNRR;WN 26: WordNet;WN 27: WordNet;Freebase;WN 28: YAGO
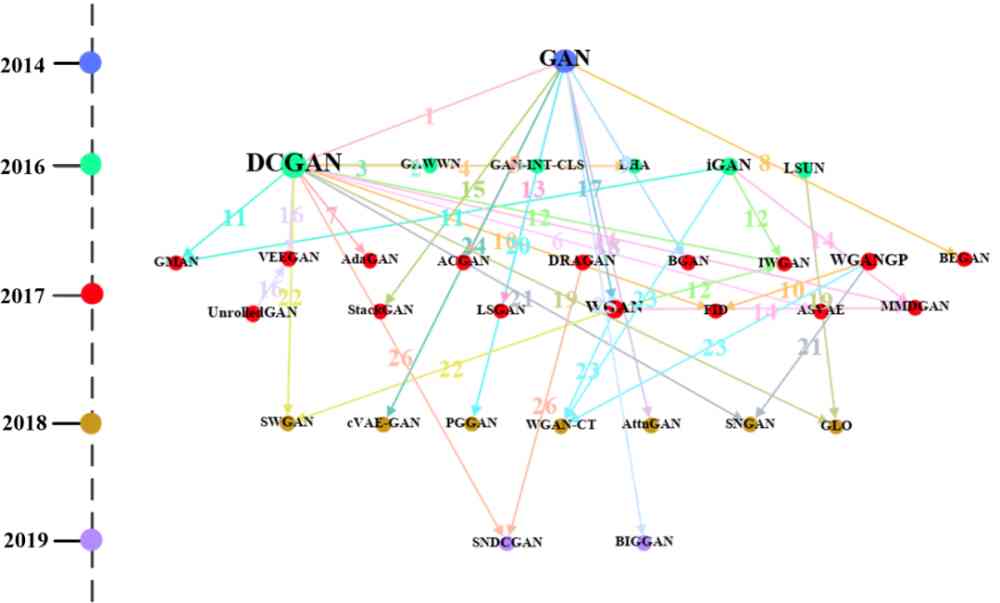
Figure 14:'GAN' 簇中方法的路径图,图中点的颜色表示年份,点的大小表示出度,线的颜色表示数字代表的数据集。
图中数字表示路径 MiMj 中 Mi 和 Mj 进行对比时使用的数据集,具体为:1: Face;NIST;SVHN;CelebA 2: CUB(CU Bird);Oxford Flower;Oxford 3: CUB(CU Bird);MPII Human;Caltech;MHP(Maximal Hyperclique Pattern) 4: ILSVRC;SVHN 5: ImageNet 6: NIST;CIFAR;ImageNet 7: NIST 8: CelebA 9: NIST;CIFAR;SVHN 10: BLUR;LSUN;SVHN;CIFAR;Noise;CelebA;LSUN Bedroom 11: NIST;SVHN;CIFAR 12: Google;LSUN;LSUN Bedroom 13: Google 14: NIST;LSUN;CIFAR;CelebA;LSUN Bedroom 15: CUB(CU Bird);Oxford 16: NIST;CIFAR 17: LSUN;CIFAR;LSUN Bedroom 18: ImageNet;COCO 19: NIST;SVHN;LSUN;CelebA;LSUN Bedroom 20: LSUN;CelebA;LSUN Bedroom 21: null 22: NIST;LSUN;CIFAR;CelebA;LSUN Bedroom 23: NIST;SVHN;CIFAR 24: poem;Chinese Poem 25: CONFER 26: null
图 14 是'GAN' 簇中的方法路径图。经与 Hong 等人 [7] 发表的文献内容核对,'GAN' 簇中方法的路径图包含上述论文提到的 75% 的生成对抗类算法。此外,由图 14 可以直观看到每个方法的提出时间,例如:GAN 是 2014 年提出的,DCGAN 是 2016 年提出的。同时,我们可以看到 DCGAN 方法节点的出度最大。一方面说明很多方法比如 AdaGAN、SNDCGAN 是从 DCGAN 受到启发,进而拓展出新方法。另一方面,也可以发现,DCGAN 作为生成对抗的代表性方法,很多新提出来的生成对抗类方法常与 DCGAN 进行对比。此外,从图中,我们也可以看出'GAN' 簇中的方法使用的数据集情况。
4.3.2 研究场景簇的结果
由 3.6 节中的公式 1,我们得到了研究场景簇之间的相互影响强度比率。考虑到只被 1 篇原始文献影响或者包含的研究场景数量过少的研究场景簇含有的信息量不多,包含的研究场景数量过多的研究场景簇内含有的研究场景信息比较杂乱。为保证结果的合理性,我们只对包含的场景数量介于 15-20 之间(包含 15 和 20)的研究场景簇进行分析。
得到最容易受其他研究场景簇影响的 top3 研究场景簇:颜色恒常性、图像记忆性预测、多核学习,以及最不容易受其他研究场景簇影响的 top3 研究场景簇:显著性检测、行人重识别、人脸识别。
由 3.6 节中的公式 2 和 3,我们对由 45,215 篇论文提出的有效方法对其他研究场景簇的影响强度和影响强度比率分别进行了计算。每年影响强度最大的方法信息如表 7 所示,每年影响强度比率最大的方法信息如表 8 所示。
Table 7:每年影响强度最大的方法信息
Table 8:每年影响强度比率最大的方法信息
由表 7 和表 8 我们可以发现,2005-2019 年每年对其他研究场景簇影响强度最大的方法中,有 12 个方法都与计算机视觉相关;影响强度比率最大的方法中,有 10 个方法都与计算机视觉相关。这说明计算机视觉类方法相对于其他类方法而言更容易影响其他研究场景簇。此外,从出版地点角度来看,表 7 中的 15 篇文献中 12 篇来自于 A 类出版地点,表 8 中的 15 篇文献中 14 篇来自于 A 类出版地点,这说明A 类出版地点提出的方法更容易对其他研究场景簇产生影响。
5 结论和未来工作
本文借鉴生物领域中通过标记物来追踪反应过程中物质和细胞的变化,从而获取反应特征和规律的思想,将 AI 文献中的方法、数据集、指标实体作为 AI 领域的标记物,利用这三种同粒度命名实体在具体研究过程中的踪迹来研究 AI 领域的发展变化情况。
我们首先利用 AI 标记抽取模型对 122,446 篇论文中方法章节和实验章节的 AI 标记进行提取,对提取的有效方法和数据集进行统计分析,获得反映 AI 领域年度发展情况的重要信息。其次,我们对有效方法和数据集进行了原始文献的溯源,对原始文献进行了计量分析。并挖掘了有效方法在数据集上和在国家之间的传播规律。发现新加坡、以色列、瑞士等国家提出的有效方法数量相对很多;随着时间的发展,有效方法在应用在不同数据集上的速度越来越快;中国提出的有效方法对其他国家的影响力越来越大,而法国恰好相反。最后,我们将数据集和指标进行组合作为 AI 研究场景,对方法和研究场景分别进行聚类。基于方法聚类及关联数据集绘制路径图,研究同类方法的演化关系。基于研究场景的聚类结果来分析方法对研究场景以及研究场景之间的影响程度,发现显著性检测这种经典的计算机视觉研究场景最不容易受其他研究场景的影响。
在以后的工作中,我们将对 AI 标记抽取模型进行改进,优化其抽取性能,并尝试从 AI 文献的表格、图像等部分提取 AI 标记,更全面、准确地实现对 AI 标记的提取,进而更准确地展示 AI 领域的发展情况。郑州人流医院哪家好
版权声明
本文为[顾延笙]所创,转载请带上原文链接,感谢
https://my.oschina.net/u/4560691/blog/4706557
边栏推荐
- 接口压力测试:Siege压测安装、使用和说明
- 如何在Windows Server 2012及更高版本中將域控制器降級
- 03_ Detailed explanation and test of installation and configuration of Ubuntu Samba
- 高级 Vue 组件模式 (3)
- Python + Appium 自動化操作微信入門看這一篇就夠了
- 连肝三个通宵,JVM77道高频面试题详细分析,就这?
- 被老程式設計師壓榨怎麼辦?我不想辭職
- 我们编写 React 组件的最佳实践
- Python3網路學習案例四:編寫Web Proxy
- 业务策略、业务规则、业务流程和业务主数据之间关系 - modernanalyst
猜你喜欢



随机推荐
不吹不黑,跨平臺框架AspNetCore開發實踐雜談
用Keras LSTM构建编码器-解码器模型
接口压力测试:Siege压测安装、使用和说明
安装Anaconda3 后,怎样使用 Python 2.7?
【jmeter】實現介面關聯的兩種方式:正則表示式提取器和json提取器
为了省钱,我用1天时间把PHP学了!
Query意图识别分析
2018个人年度工作总结与2019工作计划(互联网)
[译] 5个Vuex插件,给你的下个VueJS项目
谁说Cat不能做链路跟踪的,给我站出来
前端模組化簡單總結
8.1.1 handling global exceptions through handlerexceptionresolver
自然语言处理-搜索中常用的bm25
(1) ASP.NET Introduction to core3.1 Ocelot
mac 安装hanlp,以及win下安装与使用
vite + ts 快速搭建 vue3 專案 以及介紹相關特性
mac 下常用快捷键,mac启动ftp
DTU连接经常遇到的问题有哪些
【Flutter 實戰】pubspec.yaml 配置檔案詳解
嘘!异步事件这样用真的好么?