当前位置:网站首页>用Keras LSTM构建编码器-解码器模型
用Keras LSTM构建编码器-解码器模型
2020-11-06 01:28:00 【人工智能遇见磐创】
作者|Nechu BM 编译|VK 来源|Towards Data Science

基础知识:了解本文之前最好拥有关于循环神经网络(RNN)和编解码器的知识。
本文是关于如何使用Python和Keras开发一个编解码器模型的实用教程,更精确地说是一个序列到序列(Seq2Seq)。在上一个教程中,我们开发了一个多对多翻译模型,如下图所示:
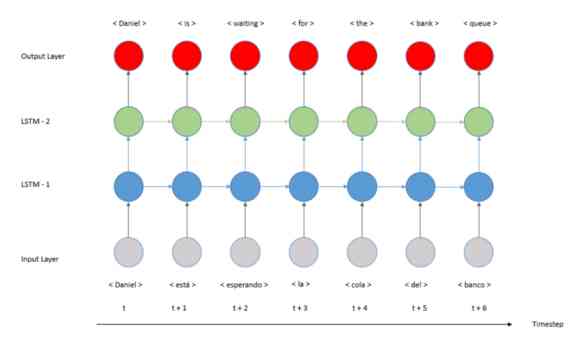
这种结构有一个重要的限制,即序列长度。正如我们在图像中看到的,输入序列和输出序列的长度必须相同。如果我们需要不同的长度呢?
例如,我们想实现一个接受不同序列长度的模型,它接收一个单词序列并输出一个数字,或者是图像字幕模型,其中输入是一个图像,输出是一个单词序列。
如果我们要开发的模型是输入和输出长度不同,我们需要开发一个编解码器模型。通过本教程,我们将了解如何开发模型,并将其应用于翻译练习。模型的表示如下所示。
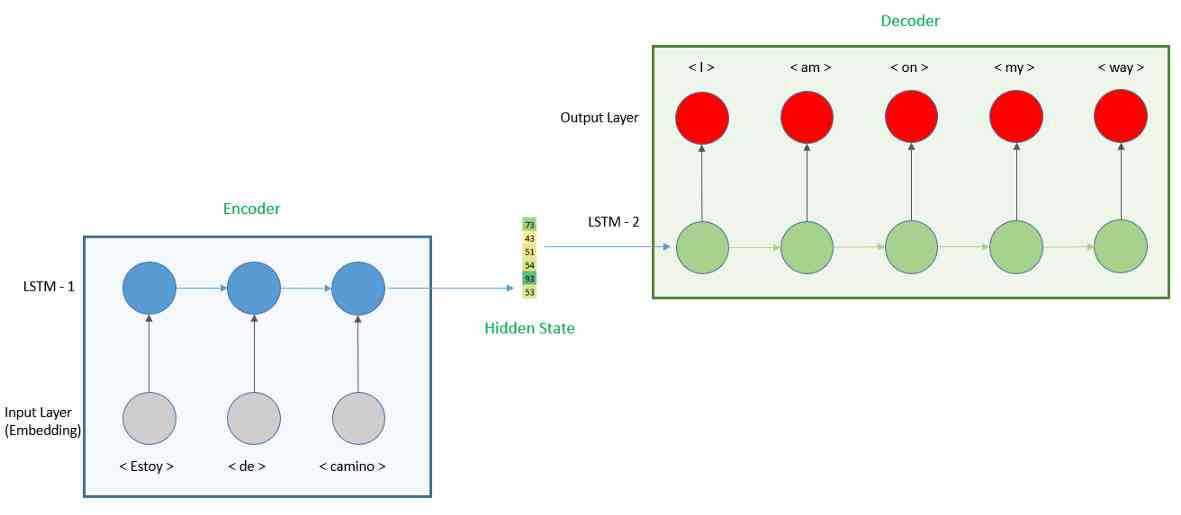
我们将模型分成两部分,首先,我们有一个编码器,输入西班牙语句子并产生一个隐向量。编码器是用一个嵌入层将单词转换成一个向量然后用一个循环神经网络(RNN)来计算隐藏状态,这里我们将使用长短期记忆(LSTM)层。
然后编码器的输出将被用作解码器的输入。对于解码器,我们将再次使用LSTM层,以及预测英语单词的全连接层。
实现
示例数据来自manythings.org。它是由语言的句子对组成的。在我们的案例中,我们将使用西班牙语-英语对。
建立模型首先需要对数据进行预处理,得到西班牙语和英语句子的最大长度。
1-预处理
先决条件:了解Keras中的类“tokenizer”和“pad_sequences”。如果你想详细回顾一下,我们在上一个教程中讨论过这个主题。
首先,我们将导入库,然后读取下载的数据。
import string
import numpy as np
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
from keras.models import Model
from keras.layers import LSTM, Input, TimeDistributed, Dense, Activation, RepeatVector, Embedding
from keras.optimizers import Adam
from keras.losses import sparse_categorical_crossentropy
# 翻译文件的路径
path_to_data = 'data/spa.txt'
# 读文件
translation_file = open(path_to_data,"r", encoding='utf-8')
raw_data = translation_file.read()
translation_file.close()
# 解析数据
raw_data = raw_data.split('\n')
pairs = [sentence.split('\t') for sentence in raw_data]
pairs = pairs[1000:20000]
一旦我们阅读了数据,我们将保留第一个例子,以便更快地进行训练。如果我们想开发更高性能的模型,我们需要使用完整的数据集。然后我们必须通过删除大写字母和标点符号来清理数据。
def clean_sentence(sentence):
# 把这个句子小写
lower_case_sent = sentence.lower()
# 删除标点
string_punctuation = string.punctuation + "¡" + '¿'
clean_sentence = lower_case_sent.translate(str.maketrans('', '', string_punctuation))
return clean_sentence
接下来,我们将句子标识化并分析数据。
def tokenize(sentences):
# 创建 tokenizer
text_tokenizer = Tokenizer()
# 应用到文本上
text_tokenizer.fit_on_texts(sentences)
return text_tokenizer.texts_to_sequences(sentences), text_tokenizer
创建完函数后,我们可以进行预处理:
# 清理句子
english_sentences = [clean_sentence(pair[0]) for pair in pairs]
spanish_sentences = [clean_sentence(pair[1]) for pair in pairs]
# 标识化单词
spa_text_tokenized, spa_text_tokenizer = tokenize(spanish_sentences)
eng_text_tokenized, eng_text_tokenizer = tokenize(english_sentences)
print('Maximum length spanish sentence: {}'.format(len(max(spa_text_tokenized,key=len))))
print('Maximum length english sentence: {}'.format(len(max(eng_text_tokenized,key=len))))
# 检查长度
spanish_vocab = len(spa_text_tokenizer.word_index) + 1
english_vocab = len(eng_text_tokenizer.word_index) + 1
print("Spanish vocabulary is of {} unique words".format(spanish_vocab))
print("English vocabulary is of {} unique words".format(english_vocab))
上面的代码打印以下结果

根据之前的代码,西班牙语句子的最大长度为12个单词,英语句子的最大长度为6个单词。在这里我们可以看到使用编解码器模型的优势。以前我们处理等长句子有局限性,所以我们需要对英语句子应用填充到12,现在只需要一半。因此,更重要的是,它还减少了LSTM时间步数,减少了计算需求和复杂性。
我们使用填充来使每种语言中句子的最大长度相等。
max_spanish_len = int(len(max(spa_text_tokenized,key=len)))
max_english_len = int(len(max(eng_text_tokenized,key=len)))
spa_pad_sentence = pad_sequences(spa_text_tokenized, max_spanish_len, padding = "post")
eng_pad_sentence = pad_sequences(eng_text_tokenized, max_english_len, padding = "post")
# 重塑
spa_pad_sentence = spa_pad_sentence.reshape(*spa_pad_sentence.shape, 1)
eng_pad_sentence = eng_pad_sentence.reshape(*eng_pad_sentence.shape, 1)
现在我们已经准备好了数据,让我们构建模型。
2.模型开发
在下一节中,我们将创建模型,并在python代码中解释添加的每一层。
2.1-编码器
我们定义的第一层是图像的嵌入层。为此,我们首先必须添加一个输入层,这里唯一要考虑的参数是“shape”,这是西班牙语句子的最大长度,在我们的例子中是12。
然后我们将其连接到嵌入层,这里要考虑的参数是“input_dim”(西班牙语词汇表的长度)和“output_dim”(嵌入向量的形状)。此层将把西班牙语单词转换为输出维度形状的向量。
这背后的概念是以空间表示的形式提取单词的含义,其中每个维度都是定义单词的特征。例如,“sol”将转换为形状为128的向量。输出维越高,从每个单词中提取的语义意义就越多,但所需的计算和处理时间也就越高。我们也需要在速度和性能之间找到平衡。
input_sequence = Input(shape=(max_spanish_len,))
embedding = Embedding(input_dim=spanish_vocab, output_dim=128,)(input_sequence)
接下来,我们将添加大小为64的LSTM层。即使LSTM的每一个时间步都输出一个隐藏向量,我们会把注意力集中在最后一个,因此参数return_sequences 是'False'。我们将看到LSTM层如何在解码器的return_sequences=True的情况下工作。
input_sequence = Input(shape=(max_spanish_len,))
embedding = Embedding(input_dim=spanish_vocab, output_dim=128,)(input_sequence)
encoder = LSTM(64, return_sequences=False)(embedding)
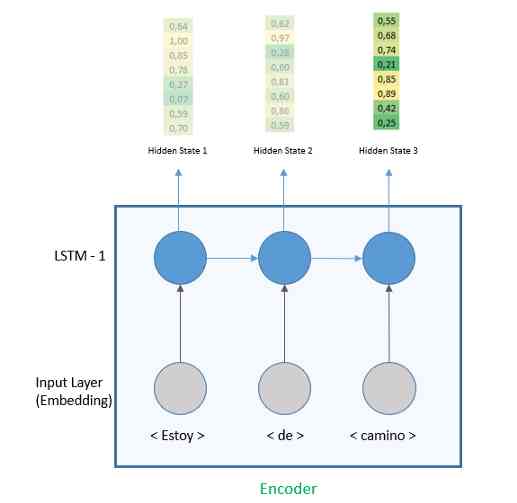
当返回序列为'False'时,输出是最后一个隐藏状态。
2.2-解码器
编码器层的输出将是最后一个时间步的隐藏状态。然后我们需要把这个向量输入解码器。让我们更精确地看一下解码器部分,并了解它是如何工作的。
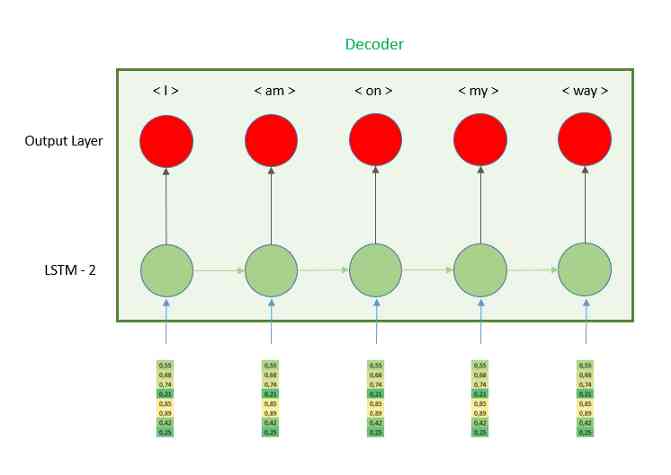
正如我们在图像中看到的,隐藏向量被重复n次,因此LSTM的每个时间步都接收相同的向量。为了使每个时间步都有相同的向量,我们需要使用层RepeatVector,因为它的名字意味着它的作用是重复它接收的向量,我们需要定义的唯一参数是n,重复次数。这个数字等于译码器部分的时间步数,换句话说就是英语句子的最大长度6。
input_sequence = Input(shape=(max_spanish_len,))
embedding = Embedding(input_dim=spanish_vocab, output_dim=128,)(input_sequence)
encoder = LSTM(64, return_sequences=False)(embedding)
r_vec = RepeatVector(max_english_len)(encoder)
一旦我们准备好输入,我们将继续解码器。这也是用LSTM层构建的,区别在于参数return_sequences,在本例中为'True'。这个参数是用来做什么的?在编码器部分,我们只期望在最后一个时间步中有一个向量,而忽略了其他所有的向量,这里我们期望每个时间步都有一个输出向量,这样全连接层就可以进行预测。
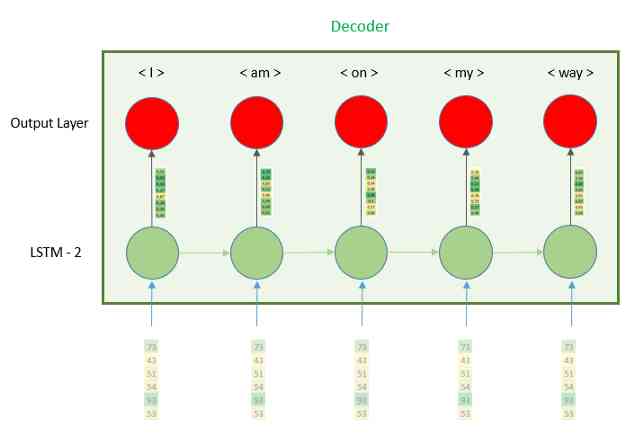
input_sequence = Input(shape=(max_spanish_len,))
embedding = Embedding(input_dim=spanish_vocab, output_dim=128,)(input_sequence)
encoder = LSTM(64, return_sequences=False)(embedding)
r_vec = RepeatVector(max_english_len)(encoder)
decoder = LSTM(64, return_sequences=True, dropout=0.2)(r_vec)
我们还有最后一步,预测翻译的单词。为此,我们需要使用全连接层。我们需要定义的参数是单元数,这个单元数是输出向量的形状,它需要与英语词汇的长度相同。为什么?这个向量的值都接近于零,除了其中一个单位接近于1。然后我们需要将输出1的单元的索引映射到字典中,在字典中我们将每个单元映射到一个单词。
例如,如果输入是单词‘sun’,而输出是一个向量,其中所有都是零,然后单元472是1,那么我们将该索引映射到包含英语单词的字典上,并得到值‘sun’。
我们刚刚看到了如何应用全连接层来预测一个单词,但是我们如何对整个句子进行预测呢?因为我们使用return_sequence=True,所以LSTM层在每个时间步输出一个向量,所以我们需要在每个时间步应用前面解释过的全连接层层,让其每次预测一个单词。
为此,Keras开发了一个称为TimeDistributed的特定层,它将相同的全连接层应用于每个时间步。
input_sequence = Input(shape=(max_spanish_len,))
embedding = Embedding(input_dim=spanish_vocab, output_dim=128,)(input_sequence)
encoder = LSTM(64, return_sequences=False)(embedding)
r_vec = RepeatVector(max_english_len)(encoder)
decoder = LSTM(64, return_sequences=True, dropout=0.2)(r_vec)
logits = TimeDistributed(Dense(english_vocab))(decoder)
最后,我们创建模型并添加一个损失函数。
enc_dec_model = Model(input_sequence, Activation('softmax')(logits))
enc_dec_model.compile(loss=sparse_categorical_crossentropy,
optimizer=Adam(1e-3),
metrics=['accuracy'])
enc_dec_model.summary()
一旦我们定义了模型,我们就可以训练它了。
model_results = enc_dec_model.fit(spa_pad_sentence, eng_pad_sentence, batch_size=30, epochs=100)
当模型训练好后,我们就可以进行第一次翻译了。你还可以找到函数“logits_to_sentence”,它将全连接层的输出与英语词汇进行映射。
def logits_to_sentence(logits, tokenizer):
index_to_words = {idx: word for word, idx in tokenizer.word_index.items()}
index_to_words[0] = '<empty>'
return ' '.join([index_to_words[prediction] for prediction in np.argmax(logits, 1)])
index = 14
print("The english sentence is: {}".format(english_sentences[index]))
print("The spanish sentence is: {}".format(spanish_sentences[index]))
print('The predicted sentence is :')
print(logits_to_sentence(enc_dec_model.predict(spa_pad_sentence[index:index+1])[0], eng_text_tokenizer))
结论
编解码器结构允许不同的输入和输出序列长度。首先,我们使用嵌入层来创建单词的空间表示,并将其输入LSTM层,因为我们只关注最后一个时间步的输出,我们使用return_sequences=False。
这个输出向量需要重复的次数与解码器部分的时间步数相同,为此我们使用RepeatVector层。解码器将使用LSTM,参数return_sequences=True,因此每个时间步的输出都会传递到全连接层。
尽管这个模型已经是上一个教程的一个很好的改进,我们仍然可以提高准确性。我们可以在一层的编码器和解码器中增加一层。我们也可以使用预训练的嵌入层,比如word2vec或Glove。最后,我们可以使用注意机制,这是自然语言处理领域的一个主要改进。我们将在下一个教程中介绍这个概念。
附录:不使用重复向量的编解码器
在本教程中,我们了解了如何使用RepeatVector层构建编码器-解码器。还有第二个选项,我们使用模型的输出作为下一个时间步骤的输入,而不是重复隐藏的向量,如图所示。
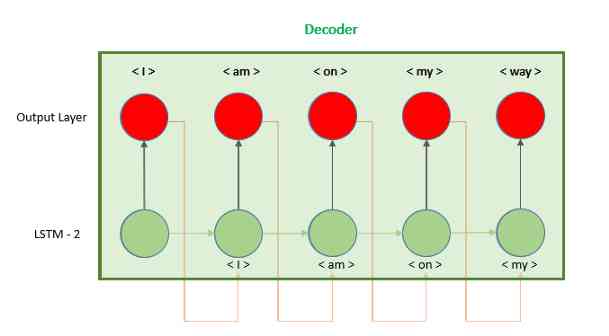
实现这个模型的代码可以在Keras文档中找到,它需要对Keras库有更深入的理解,并且开发要复杂得多:https://blog.keras.io/a-ten-minute-introduction-to-sequence-to-sequence-learning-in-keras.html
欢迎关注磐创AI博客站: http://panchuang.net/
sklearn机器学习中文官方文档: http://sklearn123.com/
欢迎关注磐创博客资源汇总站: http://docs.panchuang.net/
版权声明
本文为[人工智能遇见磐创]所创,转载请带上原文链接,感谢
https://my.oschina.net/u/4253699/blog/4697981
边栏推荐
猜你喜欢
APReLU:跨界应用,用于机器故障检测的自适应ReLU | IEEE TIE 2020
面经手册 · 第14篇《volatile 怎么实现的内存可见?没有 volatile 一定不可见吗?》
How to select the evaluation index of classification model

技術總監7年經驗,告訴大家,【拒絕】才是專業
nlp模型-bert从入门到精通(二)
阻塞队列之LinkedBlockingQueue分析

Probabilistic linear regression with uncertain weights

基础知识点整理

TF flags的简介
自然语言处理之分词、命名主体识别、词性、语法分析-stanfordcorenlp-NER(二)
随机推荐
聆听无声的话语:手把手教你用ModelArts实现手语识别
写一个通用的幂等组件,我觉得很有必要
6.7 theme resolver theme style parser (in-depth analysis of SSM and project practice)
什么是无副作用的函数方法?如何取名? - Mario
6.8 multipartresolver file upload parser (in-depth analysis of SSM and project practice)
不能再被问住了!ReentrantLock 源码、画图一起看一看!
【性能优化】纳尼?内存又溢出了?!是时候总结一波了!!
2020十大最佳大数据分析工具,果断收藏
7.3.2 File Download & big file download
结构化数据中的从属判断问题
计算机TCP/IP面试10连问,你能顶住几道?
【C/C++ 2】Clion配置与运行C语言
Skywalking系列博客5-apm-customize-enhance-plugin插件使用教程
从零学习人工智能,开启职业规划之路!
企业数据库的选择通常由系统架构师主导决策 - thenewstack
Big data real-time calculation of baichenghui Hangzhou station
结构化数据中的存在判断问题
使用Asponse.Words處理Word模板
Outlier detection based on RNN self encoder
为了省钱,我用1天时间把PHP学了!