当前位置:网站首页>基础知识点整理
基础知识点整理
2020-11-06 01:18:00 【ClawHub的博客】
一、java基础之集合类
1、ArrayList的扩容机制
- 每次扩容是原来容量的1.5倍,通过移位的方法实现。
- 使用copyOf的方式进行扩容。
扩容算法是首先获取到扩容前容器的大小。然后通过oldCapacity + (oldCapacity >> 1) 来计算扩容后的容器大小newCapacity。这里用到了>> 右移运算,即容量增大原来的1.5倍。还要注意的是,这里扩充容量时,用的时Arrays.copyOf方法,其内部也是使用的System.arraycopy方法。
区别:
- arraycopy()需要目标数组,将原数组拷贝到你自己定义的数组里,而且可以选择拷贝的起点和长度以及放入新数组中的位置。
- copyOf()是系统自动在内部新建一个数组,并返回该数组。
2、数组和ArrayList的区别
- 数组可以包含基本类型,ArrayList成员只能是对象。
- 数组大小是固定的,ArrayList可以动态扩容。
3、ArrayList和LinkedList的区别
- 线程安全
ArrayList 和 LinkedList 都是不同步的,也就是不保证线程安全; - 数据结构
LinkedList 是基于双向链表实现的,ArrayList 是基于数组实现的。 - 快速随机访问
ArrayList 支持随机访问,所以查询速度更快,LinkedList 添加、插入、删除元素速度更快。 - 内存空间占用
ArrayList的空间浪费主要体现在在list列表的结尾会预留一定的容量空间,LinkedList使用Node来存储数据每个Node中不仅存储元素的值,还存储了前一个 Node 的引用和后一个 Node 的引用,占用内存更多。 - 遍历方式选择
实现了RandomAccess接口的list,优先选择普通for循环 ,其次foreach,
未实现RandomAccess接口的list, 优先选择iterator遍历(foreach遍历底层也是通过iterator实现的),大size的数据,千万不要使用普通for循环。
4、如何创建同步的List
可以通过Collections.sychronizeList将list转换成同步list,或者直接使用CopyOnWriteArrayList。
5、CopyOnWriteArrayList
- 读时不加锁,写入时加锁,写入时创建一个新数组将老数组拷贝进入新数组,并将数据加入新数组。
- 只能保证最终一致性。
6、Vector
ArrayList线程安全的一个版本,底层通过synchronized加锁实现线程安全。
7、HashMap扩容机制
HashMap使用resize()方法来进行扩容,计算table数组的新容量和Node在新数组中的新位置,将旧数组中的值复制到新数组中,从而实现自动扩容。
- 当空的HashMap实例添加元素时,会以默认容量16为table数组的长度扩容,此时 threshold = 16 * 0.75 = 12。
- 当不为空的HashMap实例添加新元素数组容量不够时,会以旧容量的2倍进行扩容,当然扩容也是大小限制的,扩容后的新容量要小于等于规定的最大容量,使用新容量创建新table数组,然后就是数组元素Node的复制了,计算Node位置的方法是 index = (n-1) & hash,这样计算的好处是,Node在新数组中的位置要么保持不变,要么是原来位置加上旧数组的容量值,在新数组中的位置都是可以预期的(有规律的),并且链表上Node的顺序也不会发生改变。
8、HashMap为什么不是线程安全的
- 没有锁操作,两个线程操作同一个hashMap会出现线程安全的问题,可能会导致数据丢失。
- resize的时候会出现死锁,以为hash冲突之后采用链地址法解决hash冲突,但是两个线程都进行扩容的时候,链表使用头插法,导致出现循环引用,出现死锁。1.8之后 链表都是采用尾插法。避免了死循环的问题。
9、为什么HashMap的hashCode要高16位异或hashCode
因为元素所处位置只与低n位相关,高16位与hashcode进行异或是为了减少碰撞。
异或是两者相同返回0 不相同返回1。
10、为什么HashMap的容量要是2的N次幂
- 取模时分配更均匀。
- 扩容成本更低。
2^n下有特性:
x%2^n=x&(2^n-1)
只有2的幂次方才有此特性。
11、ConcurrentHashMap的实现
- jdk1.7之前,使用分段锁来实现,默认支持的并发度为16,segment继承自ReentrantLock,segment充当锁角色。每个segment中包含一个小的hash表。size方法将segment的count相加,计算两次,如果两次结果相同,说明计算准确,否则每个segment重新加锁计算。
- jdk1.8之后取消分段锁的设计,采用CAS+Synchronized保证线程安全。主要是锁住链表的头结点。size方法使用一个volatile变量baseCount记录元素个数,当插入新数据或者删除数据的时候会更新baseCount的值。
12、ConcurrentHashMap1.7与1.8异同
- 1.8取消了分段锁,锁的粒度更小,减少并发冲突的概率。
- 1.8采用了链表+红黑树的实现方式,对查询的提升很大。
13、为什么ConcurrentHashMap读操作不加锁
- ConcurrentHashMap只保证最终一致性,并不能保证强一致性。
- 对于value使用volatile关键字,保证内存可见,能够被多线程同时读,并且不会读到过期的值。根据java内存模型的happens-before原则,对volatile的写入操作先于读操作,即使两个线程同时读取和写入同一个变量,也能是get操作拿到最新值
- Node使用volatile关键字标识是为了数组扩容时的可见性。
14、LinkedHashMap的实现
基于hashMap和双向链表实现的,线程不安全。
15、HashSet的实现
- 底层是通过hashMap实现的。
- 判断两个对象是否相等,先判断hashCode是否相等,如果相等再判断equals,这就是为什么重写equals方法要重写hashCode方法。
16、TreeMap的实现
底层使用红黑树实现。根据键值进行排序,key必须实现Comparable接口或者构造TreeMap时传入Comparator。
17、TreeSet的实现
底层使用TreeMap实现,即使用红黑树进行实现。
Set判断两个元素是否相等,先判断hashCode再使用equals
18、解决Hash冲突的方法
- 开放定址法
- 链地址法
- 再hash法
19、List、Map、Set存储的null值
- list null值,加几个存几个。
- set null值 只存一个。
- map只存在一个null值对。
20、平衡二叉树AVL与红黑树的区别
- 平衡二叉树是高度平衡的,每次的插入和删除,都要进行rebalance操作。
- 红黑树不是高度平衡的。
红黑树定义:
- 节点是红色或黑色。
- 根节点是黑色。
- 每条路径上的黑色节点数目相同。
- 子节点和父节点的颜色不相同。
二、java基础之多线程
本次整理的内容如下:

1、进程与线程的区别
进程是一个可执行的程序,是系统资源分配的基本单位;线程是进程内相对独立的可执行单元,是操作系统进行任务调度的基本单位。
2、进程间的通信方式
2.1、操作系统内核缓冲区
由于每个进程都有独立的内存空间,进程之间的数据交换需要通过操作系统内核。需要在操作系统内核中开辟一块缓冲区,进程A将需要将数据拷贝到缓冲区中,进程B从缓冲区中读取数据。因为共享内存没有互斥访问的功能,需配合信号量进行互斥访问。
2.2、管道
管道的实现方式:
- 父进程创建管道,得到两个描述文件指向管道的两端。
- 父进程fork出子进程,子进程也拥有两个描述文件,指向同一个管道的两端。
- 父进程关闭读端(fd(0)),子进程关闭写端(fd(1))。父进程往管道里面写,子进程从管道里面读。
管道的特点:
只允许具有血缘关系的进程间通讯,只允许单向通讯,进程在管道在,进程消失管道消失。管道内部通过环形队列实现。
有名管道(命名管道):
通过文件的方式实现进程间的通信。允许无血缘关系的进程间的通信
2.3、消息队列
由消息组成的链表,存在系统内核中。克服了信号量传递的信息少,管道只能承载无格式的字符流及缓冲区的大小受限等特点。通过消息类型区分消息。
2.4、信号量
本质是一个计数器,不以传送数据为目的,主要用来保护共享资源,使得资源在一个时刻只有一个进程独享。
2.5、套接字
可用于不同机器间进程的通信。
套接字包括3个属性:域、类型、 协议。
- 域包括 ip 端口
- 类型指的是两种通信机制:流(stream)和数据报(datagram)
- 协议指 TCP/UDP 底层传输协议
创建socket 通过bind命名绑定端口,listen创建队列保存未处理的客户端请求,accept等待客户端的连接,connect服务端连接客户端socket,close关闭服务端客户端的连接。
stream和datagram的区别:
stream能提供有序的、可靠的、双向的、基于连接的字节流(TCP),会有拆包粘包问题。
datagram是无连接、不可靠、使用固定大小的缓冲区的数据报服务(UDP),因为基于数据报,且有固定的大小,所以不会有拆包粘包问题。
详细请参考:进程间的五种通信方式介绍
3、线程间的通信方式
共享内存:
Java采用的就是共享内存,内存共享方式必须通过锁或者CAS技术来获取或者修改共享的变量,看起来比较简单,但是锁的使用难度比较大,业务复杂的话还有可能发生死锁。
消息传递:
Actor模型即是一个异步的、非阻塞的消息传递机制。Akka是对于Java的Actor模型库,用于构建高并发、分布式、可容错、事件驱动的基于JVM的应用。消息传递方式就是显示的通过发送消息来进行线程间通信,对于大型复杂的系统,可能优势更足。
详细请参考:Java内存模型分析
4、多线程的优缺点
优点:
充分利用cpu的资源,提高cpu的使用率,使程序的运行效率提高。
缺点:
有大量的线程会影响性能,操作系统会在线程之间切换,会增加内存的开销。可能会产生死锁、存在线程之间的并发问题。
5、创建线程的方法
- 集成Thread类,重写run方法,利用start启动线程。
- 实现Runable接口创建线程,重写run方法,通过new Thread方式创建线程。
- 通过callable和futuretask创建线程,实现callable接口,重写call方法,使用future对象包装callable实例,通过 new Thread方式创建线程。
- 通过线程池创建线程。
6、runable和callable区别
- runable是重写run方法,callable重写call方法。
- runable没有返回值,callable有返回值。
- callable中的call方法可以抛出异常,runable中的run方法不能向外界抛出异常。
- 加入线程池运行 runable使用execute运行,callable使用submit方法。
7、sleep和wait区别
- wait只能在synchronized块中调用,属于对象级别的方法,sleep不需要,属于Thread的方法。
- 调用wait方法时候会释放锁,sleep不会释放锁。
- wait超时之后线程进入就绪状态,等待获取cpu继续执行。
8、yield和join区别
- yield释放cpu资源,让线程进入就绪状态,属于Thread的静态方法,不会释放锁,只能使同优先级或更高优先级的线程有执行的机会。
- join等待调用join方法的线程执行完成之后再继续执行。join会释放锁和cpu的资源,底层是通过wait方法实现的。
9、死锁的产生条件
- 互斥条件。
- 请求与保持条件。
- 不可剥夺条件。
- 循环等待条件。
详细请参考:并发编程挑战:死锁与上下文切换
10、如何解决死锁
- 破坏请求与保持条件
静态分配,每个线程开始前就获取需要的所有资源。
动态分配,每个线程请求获取资源时本身不占有资源。 - 破坏不可剥夺条件
当一个线程不能获取所有的资源时,进入等待状态,其已经获取的资源被隐式释放,重新加入到系统的资源列表中,可被其他线程使用。 - 死锁检测:银行家算法
11、threadLocal的实现
- ThreadLocal用于提供线程局部变量在多线程环境下可以保证各个线程里面的变量独立于其他线程里的变量。
- 底层使用ThreadLocalMap实现,每个线程都拥有自己的ThreadLocalMap,内部为继承了WeakReference的Entry数组,包含的Key为ThreadLocal,值为Object。
详细请参考:【SharingObjects】ThreadLocal
12、threadLocal什么时候会发生内存泄漏
java.lang.ThreadLocal.ThreadLocalMap.Entry:
1 |
static class Entry extends WeakReference<ThreadLocal<?>> { |
因为ThreadLocalMap中的key是弱引用,而key指向的对象是threadLocal,一旦把threadLocal实例置为null之后,没有任何强引用的对象指向threadLocal对象,因此threadLocal对象会被Gc回收,但与之关联的value却不能被回收,只有当前线程结束后,对应的map value才会被回收。如果当前线程没结束,可能会导致内存泄漏。
如线程池的场景,在线程中将threadlocal置为null,但线程没被销毁且一直不被使用,就可能会导致内存泄漏
在调用get、set、remove 方法时,会清除线程map中所有key为null 的value。所以在不使用threadLocal时调用remove移除对应的对象。
13、线程池
13.1、线程池类结构
ThreadPoolExecutor继承关系图: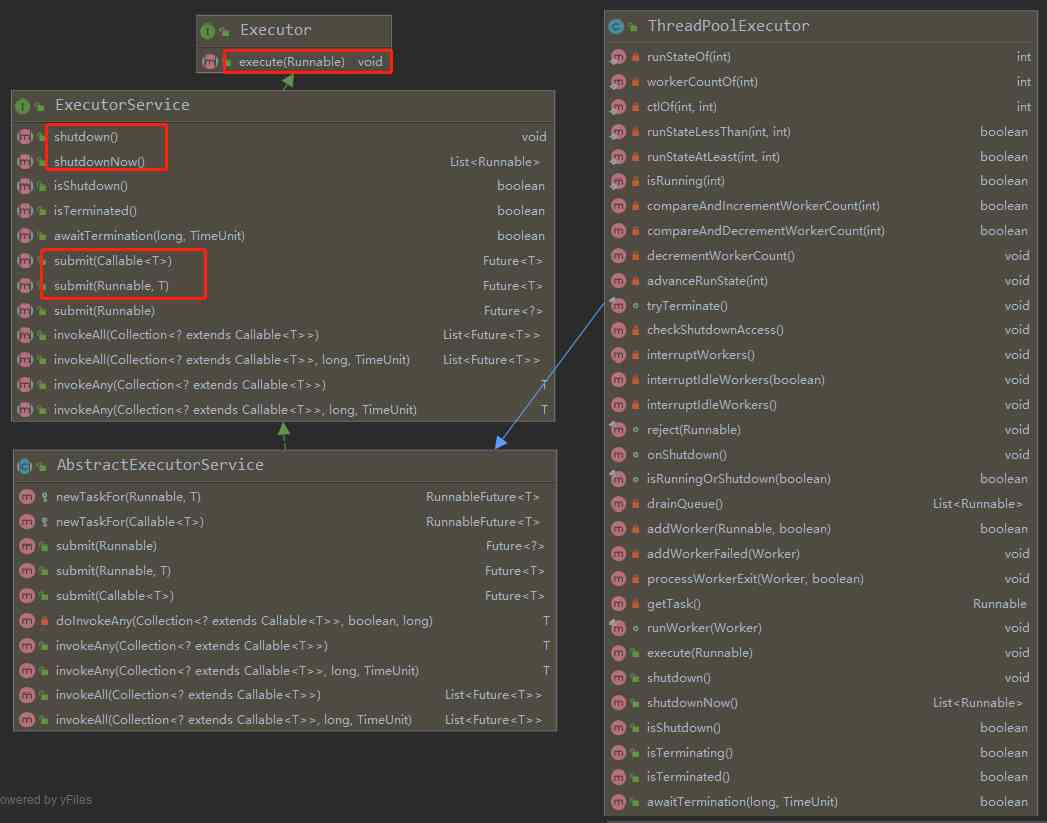
13.2、shutDown和shutDownNow的区别、
shutDown方法执行之后会变成SHUTDOWN状态,无法接受新任务,随后等待已提交的任务执行完成。
shutDownNow方法执行之后变成STOP状态,无法接受新任务。并对执行中的线程执行Thread.interrupt()方法。
- SHUTDOWN:不接受新任务提交,但是会继续处理等待队列中的任务。
- STOP:不接受新任务提交,不再处理等待队列中的任务,中断正在执行任务的线程。
13.3、线程池的参数
- CorePoolSize核心线程数
- MaximumPoolSize最大线程数,线程池允许创建的最大线程数
- keepAliveTime空闲线程的存活时间
- wokeQueue任务队列
- handler饱和策略
- threadFactory用于生成线程。
当任务来时,如果当前的线程数到达核心线程数,会将任务加入阻塞队列中,如果阻塞队列满了之后,会继续创建线程直到线程数量达到最大线程数,如果线程数量已经达到最大线程数量,且任务队列满了之后,会执行拒绝策略。
如果想让核心线程被回收,可以使用allowCoreThreadTimeOut参数,如果为false(默认值),核心线程即使在空闲时也保持活动状态。如果true,核心线程使用keepAliveTime来超时等待工作。
13.4、线程池的饱和策略
- CallerRunsPolicy:由提交任务的线程自己执行这个任。
- AbortPolicy (默认): 直接抛出RejectExecutionException异常。
- DisCardPolicy:不做处理,抛弃掉当前任务。
- DiscardOldestPolicy: 把队列队头的任务直接扔掉,提交当前任务进阻塞队列。
13.5、线程池分类
java.util.concurrent.Executors类:
newFixedThreadPool
1
2
3
4
5public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}生成一个固定大小的线程池,此时核心线程数和最大线程数相等,keepAliveTime = 0 ,任务队列采取 LinkedBlockingQueue 无界队列(也可设置为有界队列)。
适用于为了满足资源管理需求,而需要限制当前线程数量的应用场景,比如负载比较重的服务器。newSingleThreadExecutor
1
2
3
4
5public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));生成只有一个线程的线程池,核心线程数与最大线程数都是1,keepAliveTime = 0,任务队列采取LinkedBlockingQueue,适用于需要保证顺序地执行各个任务,并且在任意时间点不会有多个线程是活动的应用场景。
newCachedThreadPool
1
2
3
4
5public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}核心线程数是0,最大线程数是int最大值,keepaliveTime 为60秒,任务队列采取SynchronousQueue,适用于执行很多的短期异步任务的小程序,或者是负载较轻的服务器。
newScheduledThreadPool
1
2
3
4
5
6
7
8public static ScheduledExecutorService newSingleThreadScheduledExecutor() {
return new DelegatedScheduledExecutorService
(new ScheduledThreadPoolExecutor(1));
}
public ScheduledThreadPoolExecutor(int corePoolSize) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue());
}定长的线程池,支持周期性任务,最大线程数是int最大值,超时时间为0,任务队列使用DelayedWorkQueue,适用于需要多个后台执行周期任务,同时为了满足资源管理需求而需要限制后台线程的数量的应用场景。
13.6、任务执行过程中出现异常会怎么样?
任务执行失败后,只会影响到当前执行任务的线程,对于整个线程池是没有影响的。
详细请参考:ThreadPoolExecutor线程池任务执行失败的时候会怎样
13.7、线程池的底层实现
- 使用hashSet存储worker
- 每个woker控制自己的状态
- 执行完任务之后循环获取任务队列中的任务
13.8、重启服务、如何优雅停机关闭线程池
kill -9 pid 操作系统内核级别强行杀死某个进程。
kill -15 pid 发送一个通知,告知应用主动关闭。
ApplicationContext接受到通知之后,会执行DisposableBean中的destroy方法。
一般我们在destroy方法中做一些善后逻辑。
调用shutdown方法,进行关闭。
13.9、为什么使用线程池
- 降低资源消耗,减少创建销毁线程的成本。
- 提高响应速度。
- 提高线程的可管理性,线程的无限制的创建,消耗系统资源,降低系统的稳定性。
三、java基础之锁
1、锁状态
锁的状态只能升级不能降级。
- 无锁
没有锁对资源进行锁定,所有线程都能访问并修改同一个资源,但同时只有一个线程能修改成功。其他修改失败的线程会不断重试,直到修改成功,如CAS原理和应用是无锁的实现。 - 偏向锁
偏向锁是指一段同步代码一直被一个线程访问,那个该线程会自动获取锁,降低获取锁的代价。 - 轻量级锁
是指当锁是偏向锁的时候,被另外的线程所访问,偏向锁就会升级为轻量级锁,其他线程会通过自旋的形式尝试获取锁,不会阻塞,从而提高性能。通过cas操作和自旋来解决加锁问题,自旋超过一定的次数或者已经有一个线程在自旋,又来一个线程获取锁时,轻量级锁会升级为重量级锁。 - 重量级锁
升级为重量级锁,等待锁的线程都会进入阻塞状态。
2、乐观锁与悲观锁
- 乐观锁,每次拿数据的时候认为别人都不会修改,在更新的时候再判断在此期间有没有更新数据,可以使用版本号等机制,适合读取多场景,提高性能。
- 悲观锁,每次拿数据都认为别人会修改,都会上锁,可以使用synchronized、独占锁Lock、读写锁等机制,适合写多的场景,保证写入操作正确。
3、自旋锁与适应性自旋锁
- 自旋锁:指当一个线程在获取锁的时候,如果锁已经被其他线程获取,那么该线程将循环等待,然后不断判断锁是否能获取成功,直到获取到锁才退出循环。
优点:线程不进行上下文切换,减少了上下文切换的时间。
存在的问题:如果线程持有锁的时间较长,其他线程进入循环,消耗cpu。 - 自适应自旋锁:指的是自旋的时间不固定,由前一个在同一个锁上自旋的时间和锁拥有者的状态来决定。如果在同一个对象上,刚刚通过自旋成功获取过锁,且持有锁的线程正在运行中,那么虚拟机就会认为这次自旋很有可能再次成功。反之自旋操作很少成功获取锁,那么后面获取这个锁可能直接省略掉自旋的过程,直接阻塞线程。
4、公平锁与非公平锁
- 公平锁是指多个线程按照申请锁的顺序直接进入队列排队,队列中的第一个线程才能获取锁。
- 非公平锁是指线程先尝试获取锁,获取不到进入队列中排队,如果能获取到,则无需阻塞直接获取锁。
5、重入锁与非重入锁
重入锁:同一个线程在外层方法获取锁的时候,在进入内层方法会自动获取锁,前提是锁对象是相同的。
6、共享锁与排他锁
- 共享锁是指一个锁可以被多个线程锁持有。
- 排它锁或者叫独享锁或者互斥锁 指锁一次只能被一个线程所持有。
7、读写锁
- 读锁是共享的,写锁是独占的。
- 读读之间不会互斥,读写互斥,写写互斥,读写锁提高了读的性能。
8、CAS
CompareAndSwap比较与交换,是一种无锁算法,原子类使用了CAS实现了乐观锁。
带来的问题:
- ABA问题
解决思路在变量前面加版本号,每次变量更新的时候都将版本号+1,每次更新的时候要求版本>=当前版本(AtomicStampedReference) - 循环时间长开销大,CAS操作如果长时间执行不成功,会导致其一直自旋,cpu消耗大。
- 只能保证一个共享变量的原子操作。
可以把多个变量放在一个对象里面进行CAS操作。
9、锁优化
9.1、锁升级
- 偏向锁的升级
线程A获取锁对象时,会在java对象头和栈帧中记录偏向的线程A的id,线程A再次获取锁时,只需要比较java头中的线程id与当前Id是否相等,如果一致则无需通过cas加锁解锁。如果不一致,说明有线程B来获取锁,那么要判断java头中偏向锁的线程是否存活,如果没有存活,锁对象被置为无锁状态,线程B可将锁对象置为B的偏向锁。如果存活,则查看A是否还需要继续持有对当前锁,如果不需要持有,则将锁置为无锁状态,偏向新的线程,如果还继续持有锁对象,则暂停A线程,撤销偏向锁,将锁升级为轻量级锁。 - 轻量级锁的升级
线程A获取轻量级锁时会把锁的对象头复制到自己的线程栈帧中,然后通过cas把对象头中的内容替换为A所记录的地址。此时线程B也想获取锁,发现A已经获取锁,那么线程B就自旋等待。等到自旋次数到了或者线程A正在执行,线程B自旋等待,此时来了线程C来竞争锁对象,这个时候轻量级锁就会膨胀为重量级锁。重量级锁会把未获得到锁对象的线程全部变为阻塞状态防止cpu空转。
9.2、锁粗化
将多个连续的加锁,解锁操作连接在一起,扩展成为一个范围更大的锁,避免频繁的加解锁操作。
9.3、锁消除
通过逃逸分析,去除不可能存在共享资源竞争的锁,通过这种方式消除没有必要的锁。
10、synchronized底层实现
- synchronized通过Monitor实现同步,Monitor依赖于底层操作系统互斥锁来实现线程同步。
- java对象头是由markword(标记字段)和klass point(类型指针)组成。markword存储对象的hashcode,分代年龄和锁标志位信息。Klass point 指向对象元数据的指针,虚拟机通过这个指针来确定对象是哪个类的实例。
- synchronized修饰同步代码块,是使用monitorenter和monitorexit来控制的,通过java对象头中的锁计数器。
- 修饰方法时会将方法标识为ACCSYNCHRONIZE,JVM通过这个标志来判断方法是不是同步方法。
11、synchronized与ReentrantLock的区别
- 两者都是悲观锁,可重入锁。
- ReentrantLock 可中断,可以实现公平锁,可以绑定多个条件。
- ReentrantLock需要显示的调用锁和释放锁,synchronized属于java关键字,不需要显式的释放。
12、volatile关键字
- 保证变量内存可见。
- 禁止指令重排序。
volatile和synchronized的区别:
- volatile不会阻塞,synchronized会阻塞。
- volatile保证数据的内存可见性但不能保证原子性,synchronized两者都能保证。
- volatile主要解决变量在线程之间的可见性,而synchronized主要解决多线程访问资源的同步性。
13、Atomic原子类实现
使用cas操作 + volatile + native方法保证同步。
14、AQS
AQS(AbstractQueuedSynchronizer)内部维护的是一个FIFO的双向同步队列,如果当前线程竞争锁失败,AQS会把当前线程以及等待状态信息构造成一个Node加入到同步队列中,同时阻塞该线程。当获取锁的线程释放锁以后,会从队列中唤醒一个阻塞的节点线程。使用内部的一个state来控制是否获取锁,当state=0时表示无锁状态,state>0时表示已经有线程获取了锁。
15、AQS的组件
- semaphore 可指定多个线程同时访问某个共享资源。
- countDownLatch 一个线程A等待其他线程执行完成之后才继续执行。
- cyclicBarrier 一组线程等待至某个状态之后同时执行。
countDownLatch和CyclicBarrier的区别
- countDownLatch是一个线程等一组线程执行完成之后才执行, cyclicBarrier是一组线程互相等待至某个状态之后,同时执行。
- countDownLatch不能复用,cyclicBarrier可以重用。
16、锁降级
锁降级是指将写锁降级为读锁,这个过程就是当前线程已经获取到写锁的时候,再获取到读锁,随后释放写锁的过程,这么做的目的为的就是保证数据的可见性。
17、逃逸分析
- 逃逸分析就是分析对象的动态作用域,当一个对象在方法中被定义后,他可能被外部方法所引用,作为参数传递到其他方法中,成为方法逃逸,赋值给类变量或者可以被其他线程访问的实例变量成为线程逃逸。
- 使用逃逸分析,编译器可以对代码做优化。比如:同步省略(锁消除),将堆分配转化为栈分配,标量替换。
- 使用逃逸分析的缺点,没法保证逃逸分析的性能一定高于其他性能。极端的话经过逃逸分析后,所有的对象都逃逸了,那么逃逸分析的过程就浪费了。
四、java基础之JVM
1、内存模型
1.1、堆
- 堆是所有线程共享的,主要存放对象实例和数组。
- 新生代和老年代的比例是1:2。
- 新生代中三个区域的比例是 8 : 1 : 1。
1.1.1、新生代
对象分配在eden区中,当eden区满时会触发minor gc,将eden区中存活的对象,复制到survivor0区中,清空eden区,当survivor0中满了时,会将存活的对象复制到survivor1区中,然后将survivor0和survivor1交换,保持survivor1是空的。每经过一次yong gc 年龄就+1。
- Eden
对象创建,对象分配在eden区,当eden区满了,再创建对象的时候,会触发minor gc,进行Eden和from survivor区域的垃圾回收。 - FromSurvivor
- ToSurvivor
minor gc后还存活的对象会被放入此区域,当对象年龄到达阈值后会进入老年代。或者to survivor区域满了,会将对象放入老年代。
1.1.2、老年代
- 大对象,需要大量连续内存空间的对象
- 长期存活的对象,对象年龄超过15(默认值)
- yong gc后survivor区容不下的对象。
1.2、JVM栈
线程私有的,每个线程都有一个栈,主要存放当前线程的局部变量,程序运行状态,方法返回值,方法出口等。
1.3、本地方法栈
为虚拟机使用到的native方法服务。
1.4、方法区
用于存放已经被夹在的类信息,常量,静态变量,1.8后取消了永久代,增加了元空间,元空间并不在虚拟机中,而是用的是本地内存。元空间中存放类的元信息,静态变量和常量池移入堆中。
1.5、程序计数器
- 程序私有,生命周期与程序相同
- 当前线程所执行的字节码的行号指示器。
- 用来实现分支,循环,跳转,异常等功能。
2、常量池中包括什么
常量池在编译时期确定,存放在编译生成的class文件中,包含了基本数据类型和对象类型(String和数组)
3、如何判断对象是否存活
使用什么方法标记一个对象可回收?
- 引用计数法,每个对象都有一个引用计数器,被引用+1 当引用数为0即为可被GC的对象
- 可达性分析:从根节点出发,向下搜索,未访问到的对象标记为不可达,可被回收
4、哪些对象可以用为GC ROOT对象
- 虚拟机栈中引用的对象。
- 方法区中静态对象引用的对象。
- 方法区中常量引用的对象。
- 本地方法栈中引用的对象。
5、GC策略
- 标记清除法,从根节点进行扫描,对存活的对象进行标记,标记完成后,再扫描整个空间中未被标记的对象,进行清理。容易造成内存碎片。
- 复制,将内存划分为两份,当其中一份内存满了时,从根节点扫描,将存活的对象复制到另一份内存中。不会出现内存碎片问题,但需要两倍的空间。
- 标记整理,如标记清除法一样,标记对象,清除后将所有存活对象向左移。避免了内存碎片和两倍空间的问题,但增加了移动对象的成本。
6、具体GC收集器
- 串行垃圾收集器,serial
- 并行垃圾收集器 parNew,parallel 注重吞吐量
- cms 注重最短回收停顿时间
- G1
cms和G1的区别 :
- cms是老年代的垃圾收集器,采用标记清除。
- G1是新生代和老年代的垃圾收集器,采用标记整理。
- cms会产生内存碎片,G1并不会。
- Cms追求最小停顿时间,G1是达到可控的停顿时间,尽可能提高吞吐量。
7、什么样的对象进入老年代
- 大对象,需要大量连续内存空间的对象。
- 长期存活的对象,对象年龄超过15(默认值)。
- yong Gc后survivor区容不下的对象。
8、为什么要区分新生代和老年代
- 对象的生存情况不同使用不同的GC算法。
- 新生代对象可能被频繁的创建和回收,老年代回收较少。
9、survivor区存在的意义
- 为了提高对象进入老年代的门槛,减少fullGC的次数,因为fullGC很耗时。
- 两个survivor的作用是为了减少survivor区的内存碎片。
10、什么是yangGC
对年轻代进行gc。触发条件:
- eden区不足
- 清空eden from to中没被引用的对象。
- 将eden from中存活的对象 复制到 to中。
- 将to中的对象晋升到old中,包括两类对象,一个是年龄到达阈值,一个是to中放不下。
- full gc也会触发yong gc
11、什么时候触发fullGC
- 手动触发的GC。
- 老年代的空间不足。
- 永久代的空间满了(方法区)。
- 统计到yong gc晋升到老年代的平均大小大于老年代剩余的大小(老年代的空间不足)。
- jvm自身固定频率的fullGC(默认一小时执行一次)。
12、内存的配置参数
- xms xmx 配置堆内存的最小和最大值
- xmn 年轻代内存的初始大小
- xss jvm栈大小
13、对象分配内存的两种方式
- 指针碰撞,如果内存对象是规整的,采用指针碰撞来为对象分配内存,所有使用过的内存在指针的一侧,未使用过的内存在指针的另一侧,分配内存只需要移动指针即可。
- 空闲列表,内存不规整,使用过的内存和未使用过的内存交织在一起,维护一个内存使用列表,记录那些内存是可用的,在分配的时候找到一块足够大的空间划分给对象,并更新列表上的内容。
14、如何减少GC的开销
- 避免显示的调用System.gc。
- 尽量减少临时对象的使用。
- 对象不使用时,最好显式的置为null。
- 尽量使用StringBuffer而不用String累加字符串。
- 能用基本类型就是用基本类型。
- 尽量少用静态对象变量。
15、什么是JAVA内存模型(JMM)
用于屏蔽掉各种硬件和操作系统的内存访问差异,以实现让java程序在各个平台下都能达到一致的并发效果。
16、什么是happens-before
- 保证了内存的可见性
- 制定了四个规则:
- 程序顺序规则:一个线程中的每个操作 happens-before 与后续的所有操作。
- 监视器锁规则:一个监视器解锁 happens-before 于 加锁。
- volatile变量规则: 写操作 happens-before 读操作。
- 传递性 A happens-before B ,B happens-before C ,那么A happens-before C。
17、性能调优工具
17.1、jps
jps主要用来输出jvm中运行的进程状态信息。
-l 输出main类或者jar的权限名。
17.2、jstack
jstack pid > log
可以将线程堆栈转存到文件中。
日志分析可以使用fastthread.io。
17.3、jstat
可以显示出虚拟机进程中的classloader、内存、gc等运行数据。
参数
-class pid 类加载统计。
-gc 垃圾回收统计 ,后面跟两个参数一个是间隔输出时间,一个是总共输出次数。
gc日志可以使用 gceasy.io
17.4、jmap
jmap查看堆内存的使用情况:
jmap pid
17.5、jinfo
查看java程序的运行环境参数:
jinfo pid
18、内存栅栏
通过确保从另一个CPU来看,屏障的两边的所有指令都是正确的程序顺序,而保持程序顺序的外部可见性;其次可以实现内存数据可见性,确保内存数据会同步到CPU缓存子系统。
19、JVM产生的内存溢出及解决办法
- java heap space
代码中存在大对象的分配,多次GC后仍找不到分配空间。
解决办法:查看是否有大对象分配尤其是大数组。通过jmap把堆内存的日志dump下来,分析日志,如果解决不了增加堆内存的空间。 - permspace metaspace
永久代或元空间溢出。生成大量的代理类或者使用自定义的类加载器。
解决办法:查看有没有配置永久代或者元空间的大小。是否长时间没有重启jvm,是否有大量的反射操作。
五、java基础之类加载机制
1、类加载过程
1.1、加载
查找和导入class文件。
1.2、链接
验证
检验载入的class文件的正确性,完整性。准备
给类的静态变量分配存储空间,会赋对象类型的默认值。解析
将class常量池中的符号引用转换成直接引用。符号引用和直接引用的区别:
- 符号引用:java编译阶段不知道所引用的对象的实际地址,使用符号引用来代替
- 直接引用:能够直接定位到对象的指针,或相对偏移量。能定位到一个对象的内存实际地址。
1.3、初始化
对类的静态变量,代码块执行初始化操作,静态变量赋值顺序根据代码定义的顺序执行。
2、类的加载顺序
- 父类静态成员变量
- 父类静态代码块
- 子类静态成员变量
- 子类静态代码块
- 父类非静态成员变量
- 父类非静态代码块
- 父类构造方法
- 子类非静态成员变量
- 子类非静态代码块
- 子类构造方法
3、类加载时机
- 创建类实例-使用new关键字,反射,克隆,反序列化。
- 调用类的静态变量或者静态方法,或对静态变量进行赋值操作。
- 初始化子类时会先初始化父类。
- 虚拟机启时,包含main方法的启动类。
注意:
- 通过数组定义的引用类,不会造成类的初始化。
- 访问类的静态常量是不会造成类加载的。因为在编译时期,静态常量已经放入类的常量池中了。访问类静态常量其实是直接访问常量池中的常量,不需要加载类。
4、静态常量是什么时候赋值的
静态常量在编译阶段把初始值存入class文件的常量池中,在类的准备阶段,将值赋给静态变量。
5、什么是双亲委派
1.类加载器包括:BootstrapClassLoader、ExtensionClassLoader、 ApplicationClassLoader、自定义的类加载器。
2.双亲委派模型:如果一个类加载器收到了加载类的请求,首先交给父类加载器进行加载,如果父类加载器加载失败,当前类才会自己加载类。
3.双亲委派的作用:避免重复加载,父类已经加载子类不用加载,防止用户自定义加载器加载java核心的api,带来安全隐患。
4.一个类是否被加载是通过全类名和命名空间确定的,命名空间是加载类的加载器名。
6、如何自定义类加载器
继承classloader类,重写findClass方法。
六、java基础之Web与网络
1、转发与重定向的区别
- 转发是服务器请求资源,服务器直接访问目标地址url,把响应内容返回给浏览器。 重定向根据服务器返回的状态码重新请求地址。
- 转发是服务器行为,重定向是客户端行为。
- 转发显示的url不变而重定向显示新的url。
- 转发页面和转发到的页面共享request的信息,重定向不共享数据。
- 转发一般用于用户登录,根据角色转发到相应的模块, 重定向一般用于用户注销,跳转到其他的地方。
2、TCP三次握手
建立连接时进行TCP三次握手:
- 客户端发送syn给服务端 连接请求。
- 服务端发送syn ack 给客户端 授予连接。
- 客户端发送ack给服务端 确认连接。
第一次客户端确认自己的发送正常,服务端确认自己的接收正常。
第二次服务端确认自己的发送,接收正常,客户端的发送正常。客户端确认自己的发送、接受正常,服务端的发送、接受正常。
第三次客户端服务端都确认双方的发送接收正常。
3、TCP四次挥手
- 客户端发送fin给服务端,关闭客户端到服务端的数据传送。
- 服务端发送ack 。
- 服务端发送fin,关闭服务端和客户端的连接。
- 客户端发送ack,连接关闭。
4、为什么是三次握手四次挥手
建立连接的时候,syn和ack可以同时发送,但是断开连接的时候fin和ack不能同时发送,因为server还未确认是否所有的报文都发送完了,所有的报文发送完了才能发送fin。所以建立连接需要三次握手,断开连接需要四次挥手。
5、TCP与UDP的区别
- TCP协议是有连接的,必须通过三次握手建立连接,UDP是无连接的。
- TCP保证数据按序到达,UDP不能保证。
- TCP是面向字节流的服务,UDP是面向报文的服务。
6、什么是Servlet
是http请求和程序之间的中间层。可以读取客户端请求数据,处理数据并生成结果。
7、拦截器与过滤器的区别
- 拦截器基于java反射实现,过滤器基于函数回调。
- 拦截器不依赖Servlet容器,过滤器依赖Servlet。
实现一个拦截器继承HandlerIntecepterAdapter。
实现过滤器继承Filter,在web.xml中进行配置。
8、HTTPS的过程
- 客户端发起https请求,建立连接,发送所支持的ssl/tls的版本,支持的加密套件等。
- 服务器收到请求后,会发送服务端的证书,选择的ssl/tls的版本,使用的加密套件。
- 客户端收到证书之后对证书进行验证,验证证书是否被篡改,验证证书的有效期。获取服务器的公钥。
- 使用服务器的公钥对一个随机数进行加密,传送给服务器。
- 然后使用这个随机数进行对称加密进行传输数据。
9、加密相关
- 对称加密
加解密使用同一套秘钥,常用的加密算法: AES、 DES。 - 非对称加密
指的是加解密使用不同的密匙,一个公钥一个私钥。公钥加密的信息只有私钥能解开,私钥加密的信息只有公钥能解开。 - 摘要
一段信息,经过摘要算法得到一串hash值。常用的摘要算法:MD5、SHA1、SHA256。 - 数字签名
先用摘要算法,获取内容的摘要,之后使用自己的私钥对摘要进行加密生成签名。 - 数字证书
证书有签发者、证书用途、公钥、加密算法、hash算法、到期时间等。数字证书会做一个数字签名防止证书被篡改。会用CA的私钥进行加密。CA的公钥是公开的,浏览器会缓存。
七、java基础之其他
1、自定义注解
@target
说明了Annotation所修饰的对象范围: constructor、method、field、package、type等等。
@retention
定义了该Annotation被保留的时间长短, source(源文件保留)、class( class保留)、runtime(运行时有效)。
@inherited
某个被标记的类型是被继承的。一个类标记了带有@inherited的注解,那么他的子类也拥有这个注解。
@document
被修饰的注解会生成到javadoc中。
2、内部类
- 内部类分为:成员内部类,匿名内部类,静态内部类,局部内部类。
- 除了静态内部类,其他的内部类不能拥有静态变量或静态方法,因为内部类属于外部类的一个成员变量,先加载外部类在加载内部类。
原因:- 静态变量在类加载的时候需要将符号引用替换为直接引用而此时还没有内部类的对象。
- 内部类无法在没有外部类的实例下直接使用。
2.1、为什么静态内部类可以拥有静态常量
因为静态常量是在编译时期就确定的值,会存入类的常量池,而访问常量池中的常量是不需要加载类的。
2.2、内部类的使用场景
- 达到一个多重继承的效果
- 访问控制,只能通过外部类调用
3、自动拆箱装箱
- 基本类型和引用类型之间的转换。
- 集合类只接受对象。
- 注意包装类的缓存值,Float和Double值没有缓存值,Integer和Long缓存值为-128~127超过之后会自动转换成对象。两个包装类型进行比较时需要用equals。
4、String为什么是final,StringBuilder与StringBuffer的区别
- String定义成final类型表示不能被继承,确保不会在子类中改变语义。
每次对string对象的改变相当于重新生成了一个新的string对象。经常改变的字符串不建议使用String。 - StringBuffer是线程安全的, StringBuilder是非线程安全的。
5、transient
- 被标记的成员变量不参与序列化过程。
- 只能修饰成员变量,不能修饰类和方法。
6、如何进行序列化
- 实现Serializable接口。
- 序列化使用输出流进行writeObject。
- 反序列化使用输入流进行readObject。
7、如何实现对象克隆
- 实现Cloneable接口,并重写clone方法。
- 也可通过序列化方式进行深拷贝
- 一般实际使用过程中我们只需要拷贝对象的属性,通常使用BeanUtils.copy()
这种拷贝都是浅拷贝 - 几种拷贝对象的性能
cglib>Spring>apache, 一般不建议使用apache的因为对象转换会出错,Spring的date类型转换也可能会出错。
8、异常
8.1、Error
系统级别的错误,程序不必处理。出了错误之后只能退出运行。
8.2、Exception
- 需要进行捕捉或者程序处理的异常。
- Exception分为运行时异常和受检异常
RuntimeException包括:空指针异常,数组下标越界,classNotFound,类型转换异常等等。
受检异常指:编译器要求方法必须声明抛出可能发生的受检异常。
9、Object中的finalize方法
如果类中重写了finalize方法,当该类对象被回收时,finalize方法有可能会被触发。
八、dubbo知识点整理
1、dubbo的组成
- provider 服务提供方。
- consumer 服务消费方。
- registry 注册中心 服务发现与注册。
- container 服务运行容器。
- monitor 监控中心,统计服务调用次数与调用时间。
2、dubbo的服务注册与发现的过程
服务提供者启动时注册服务地址到注册中心。消费者启动时订阅服务地址,注册中心根据消费者所请求服务信息,匹配对应的提供者列表发送给消费者进行缓存,消费者在发起远程调用时,基于缓存的提供者列表选择其中一个进行调用。
服务提供者状态变更会实时通知注册中心,注册中心也实时推送给消费者。
3、注册中心挂掉,客户端服务端是否能进行通信
能进行通信,因为客户端缓存了服务端的信息。
4、dubbo支持哪些协议
- dubbo协议
- rmi协议
- http协议
- webservice协议
默认使用dubbo协议。
5、dubbo的序列化协议
推荐使用hessian序列化,还有dubbo,fastjson java自带序列化。
6、dubbo的通信框架
netty。
7、dubbo的负载均衡
- random 随机,按照权重设置随机概率。
- roundrobin 轮询
- 最少活跃调用数
- 一致性hash,相同的参数请求总发送到同一个提供者。
8、dubbo超时处理
dubbo在调用服务不成功时,会默认重试两次。
9、dubbo的集群容错方案
默认是失败自动切换其他服务,读操作建议只用Failover失败自动切换,默认重试两次其他服务器。写操作建议使用Failfast快速失败,发一次调用失败就立即报错。
10、服务失效踢出基于什么原理
zookeeper的临时节点作用。
11、当一个接口有多种实现如何处理
可以使用group属性来分组,服务提供方和消费方都指定同一个group。
12、服务上线如何兼容旧版本
可以使用版本号进行注册,不同版本号服务之间不进行引用,类似于服务分组。
13、dubbo在安全机制方面如何解决
dubbo通过token令牌防止用户绕过注册中心直连,然后在注册中心上管理授权。dubbo还提供服务黑白名单,来控制服务所允许的调用方。
九、mq知识点整理
1、kafka
kafka由多个broker服务器组成,每个类型的消息被定义成topic,同一topic内部的消息根据key和算法分布到不同的partition上,存储在不同的broker上。
1.1、kafka如何实现高吞吐
- 顺序IO,kafka消息是不断追加到文件中,减少硬盘磁头的寻道时间,只需要很少的扇区旋转时间。使用os的pageCache功能。
- 零拷贝,跳过用户缓冲区的拷贝,建立磁盘空间和内存的直接映射,数据不再复制到用户缓冲区中。把数据从内核Buffer中Copy到网卡的Buffer上,这样完成一次发送。
- 文件分段,partition分为多段segment,每次操作只是对一小部分进行操作,增加了并行操作的能力。
- 数据压缩,通过gzip或snappy格式对消息进行压缩。减少传输的数据量,减轻网络传输的压力
- 批量发送,producer发送消息的时候,可以将消息缓存在本地,等到固定条件在发送给kafka,减少了服务端IO的次数。
1.2、kafka如何保证消息可靠
kafka消息的可靠性主要是通过副本机制实现,通过配置参数,使kafka能在可靠性与性能之间做权衡。
1.3、kafka如何实现高可用
kafka由多个broker组成,每个broker是一个节点。一个topic可以划分为多个partition,每个partition可以存在于不同的broker上,每个partition只放一部分数据。
kafka 0.8以后提供了HA机制,就是replica副本机制,每个partition数据会同步到其他的broker上面,形成自己的副本,所有的replica会选举出一个leader(通过zookeeper实现)来跟生产者和消费者打交道,其他的replica就是follower。如果某个broker挂了,上面有partition的leader,则会从follower中重新选举出一个leader。
写数据时,生产者就写leader,leader将数据落盘,follower主动pull数据,follower同步好了之后会发送ACK给leader,leader收到所有的follower的ack后会返回成功给生产者。
读数据 从leader读,只有当一个消息被所有的follower都同步成功了才会被消费者消费掉。
生产者通过zookeeper找到partition的leader。leader的选举本质上是一个分布式锁。
2、如何保证消息队列高可用
kafka参考1.3节;
RabbitMQ:使用镜像集群实现队列高可用,多个实例之间同步消息。
缺点:
- 性能开销大,所有消息都要同步到所有的节点上。
- 没有扩展性,基于主从结构没有线性扩展性可言。
3、如何保证消息可靠、数据不丢失
RabbitMQ
rabbitMq提供事务和confirm模式来保证生产者的数据不丢失。事务模式是指在提交数据前开启事务,如果发送过程中出现异常事务回滚。这种方式会导致吞吐量降低。开启confirm模式,生产者提交消息后,rabbitmq会返回ack给生产者说明消息入队成功,如果返回nack,生产者可以进行重试。Kafka
设置request.require.acks=all,
producer.type=sync
min.insnrc.replicas=2,要求至少有两个副本都写成功,才会返回响应给producer。4、如何保证消息的有序性
kafka
写入partition时指定一个key,那么消费者从partition中取数据是有序的,如果是多线程消费,那么需要一个内存队列,将相同的hash结果存放在一个内存队列中,然后一个线程对应一个内存队列。就能保证写入数据库的顺序是一致的。rabbitmq
如果存在多个消费者,那么让每个消费者对应一个queue,然后把要发送的数据全都放到一个queue中,这样就能保证所有的数据只能到达一个消费者,从而保证数据到达数据库的顺序是一定的。
5、几种消息队列的对比
- activeMq使用java语言开发,吞吐量达到万级,没经过大规模吞吐量验证,社区不活跃。
- rabbitMq使用erlang语言开发,性能好,吞吐量高达万级,社区活跃,但很难定制开发。
- rocketMq 使用java开发,接口简单易用,吞吐量达到十万级,经过阿里大规模吞吐量验证。
- kafka 使用scala开发,高吞吐,吞吐量高达十万级,主要用于日志采集和大数据实时计算。
6、为什么使用消息队列
- 系统解耦
- 异步处理
- 流量削峰
7、引入消息队列带来什么弊端
- 系统可用性降低。
- 系统的复杂性增加,要考虑一致性问题,消息重复消费,消息的可靠性等问题。
8、如果MQ中积压了几百万数据如何处理
- 先修复consumer的问题,使得consumer工作正常。
- 进行紧急扩容,增加consumer的数量和消息队列的数量,并将积压的消息分配到新增的消息队列中。
- 如果积压的消息过期了,只能从日志中进行补偿。
十、mybatis知识点整理
1、什么是Mybatis
MyBatis是一个半ORM框架,内部封装了JDBC,开发时只需关注SQL语句本身,不需要花费精力去处理加载驱动、创建连接、创建Statement等复杂过程,程序员直接写原生SQL,可以控制SQL执行性能,灵活度高。
Mybatis执行步骤:
- 创建SqlSessionFactory
- 通过SqlSessionFactory获取SqlSession
- 通过SqlSession执行数据库操作
- 提交事务
- 关闭会话
2、MyBatis的xml如何与接口对应
xml会配置nameSpace限制接口的全量名,接口中的方法名映射为标签中的ID值,接口中的方法参数是传递给SQL的参数列表。
接口运行的工作原理是使用JDK的动态代理,根据mapper配置的xml去生成DAO的实现。
3、接口绑定有几种方式
- 注解绑定 @Select @Update
- 通过xml中写SQL绑定
4、$与#的区别
#是预编译处理,$是原样替换,$多拼接了两个’在替换的数据前后。#可以防止SQL注入。
5、mapper如何传递多个参数
使用@Param注解来命名参数,封装成Map。
6、MyBatis如何分页,分页插件如何实现
MyBatis利用RowBounds对象进行分页,针对resultset进行内存分页,也可以直接书写带有物理分页的参数进行物理分页。
分页插件是利用MyBatis提供的插件接口,实现自定义插件,在插件内拦截待执行的SQL,然后重写SQL添加对应的物理分页语句和参数。
7、MyBatis如何将返回结果与Java对象映射
- 使用resultMap定义数据库列名与对象属性之间的映射。
- 使用resultType使用别名与对象属性名进行映射。
MyBatis通过反射创建对象,然后给属性逐一赋值。
8、半自动ORM与全自动ORM的区别
半自动ORM:查询关联对象或者关联集合对象时,需要手动编写SQL来完成。
9、MyBatis有几个执行器
- SimpleExecutor 每个SQL都生成新的Statement对象。
- ReuseExecutor 以SQL作为key缓存Statement,Statement对象复用。
- BatchExecutor 等待addBatch后执行executebatch
在配置文件中使用executorType来配置使用的executor。
十一、mysql知识点整理
1、事务
1.1、特性
ACID(原子性、一致性、隔离性、持久性)
1.2、隔离级别
- read uncommit:未提交读、产生脏读问题。
- read committed:已提交读、解决脏读问题,但是有不可重复读问题。
- repeateble read:可重复读,解决不可重复读问题,有幻读问题。
- serializable:解决所有问题,事务串行执行。
- 脏读:读到未提交的脏数据。
- 不可重复读: 在同一个事务中,对于单条数据,两次读的结果不一致,因为其他事务修改了数据。
- 幻读:对于读取多条数据,同一事务中两次读的结果不一致,因为新增了数据。
1.3、事务实现原理
使用锁机制和mvcc实现事务的隔离性:
- 两个写操作之间使用锁机制来保证隔离性。
- 一个写操作与一个读操作之间,使用mvcc来保证隔离性。
undolog和redolog:
- redolog 重做日志是用来恢复数据用的,保证已提交事务的持久性。
- undolog 回滚日志用来回滚数据用的,保证未提交事务的原子性。
1.4、为什么拥有了MVCC还需要锁
使用mvcc可以减少锁的使用,大多数读操作都不用加锁,性能比较好。读不加锁,读写不冲突。
2、锁
2.1、锁的分类
- 共享锁:读锁,其他事务可以读,但不能写。
- 排他锁:写锁 ,其他事务不能读,也不能写。
- 意向共享锁:InnoDB提供,不需要用户干预,加共享锁之前,事务必须获取意向共享锁。
- 意向排他锁:加排他锁之前事务必须获取意向排他锁。
- 间隙锁:锁定索引记录的间隙,确保索引记录的间隙不变。
- 行锁:通过索引实现的。
2.2、如何开启锁
insert、update、delete默认加排它锁。
select需要显示的声明才会加锁:
加共享锁:lock in share mode
加排它锁:for update
2.3、什么情况下锁表
使用索引作为检索条件修改数据时,会采用行锁,否则采用表锁。
2.4、意向锁主要解决什么问题
主要解决表锁与行锁共存的问题,意向锁解决表锁与之前可能存在的行锁冲突,避免为了判断表是否存在行锁而去扫描全表的系统消耗。行锁在加锁前要先加意向锁。意向锁是一种表锁。
3、MVCC
在MVCC并发控制中,读操作可以分成两类:快照读 (snapshot read)与当前读 (current read)。快照读,读取的是记录的可见版本 (有可能是历史版本),不用加锁。当前读,读取的是记录的最新版本,并且,当前读返回的记录,都会加上锁,保证其他事务不会再并发修改这条记录。
4、引擎
4.1、InnoDB与myisam的区别
- InnoDB支持行锁,事务,外键。
- InnoDB不保存具体的行数,执行select count(*) from table时要扫描全表。
- InnoDB支持mvcc myisan不支持。
4.2、InnoDB的行锁是通过什么实现的
InnoDB行锁是通过给索引上的索引项加锁来实现的,InnoDB这种行锁实现特点意味着:只有通过索引条件检索数据,InnoDB才使用行级锁,否则,InnoDB将使用表锁。
4.3、InnoDB是通过什么方式解决幻读
使用Next-key lock解决幻读。
next-key lock是行锁+gap lock 间隙锁实现的。行锁是单个索引记录上加排它锁,间隙锁是锁定一个范围,但不包括记录本身。阻止多个事务将记录插入到同一个范围中。
5、复制表
- create table a like b
只复制结构不拷贝数据。 - create table a as (select * from b)
复制结构也拷贝数据。
6、主从复制流程及原理
- 主服务器上的任何修改都会写入binlog中,从服务器上启动一个I/O thread 连接到主服务器上读取binlog,写到从服务器本地的 relaylog(中继日志)中,从服务器上开启一个sql thread 定期检查relaylog,如果发现有更改立即把更新的内容在本机上执行一遍。
- 三种主从复制的模式
- sql语句复制:对数据库所有的操作的sql都写入binlog中。
- 行复制:会将每一条数据的变化写到binlog中。
- 混合模式:sql语句+行复制,mysql自动选择。
- 全局事务ID实现复制原理
主节点更新数据时会产生GTID记录到binlog中,从节点I/O线程获取到变更的binlog记录到自己的relaylog中,从节点的sql线程从relaylog中获取GTID,然后从自己的binlog中查找,如果查找到说明该GTID已经被执行过,然后忽略,如果没有记录,会从relaylog中执行该GTID的事务并记录到binlog中。
7、双主架构
两台mysql服务互为主从,masterA负责数据写入,masterB备用,两台主从之间通过keepAlived做高可用,所有的从服务器与masterB进行主从同步。
8、半同步复制和并行复制
- 半同步复制解决数据丢失问题。
- 并行复制解决主从复制延时问题。
半同步复制确保事务在主库写完binlog后需要从库返回一个ack才返回给客户端。确保事务提交后binlog至少传输到一个从库,不保证从库用完这个事务的binlog,性能降低,响应时间变长。
并行复制是指从库开启多个sql线程并行应用binlog。
9、mysql中char与varchar的区别;varchar(20)和int(20)区别
- varchar是变长的;char的长度是固定的。
- varchar(50)代表最多可以存储50个字符;int(20)中是指显示的字符长度,不影响内部存储。
10、truncate\delete\drop区别
使用场景不同:
- truncate:清空表数据。
- delete:删除表数据,一行或者多行。
- drop:删除表。
11、为什么要使用索引
使用索引是为了提高查找效率,创建唯一索引保证数据的唯一性。
- hash索引:是一个hash表存储的数据结构,根据key能直接查找到value,只能满 =、in、 !=的查询,范围检索hash索引无用。hash索引无法利用索引完成排序。联合索引中hash索引不能利用部分索引建进行查询。因为是联合索引建合并一起计算hash值,而不是单独计算hash值。
- B+树索引:叶子节点保存了完整的数据记录,B+树磁盘读写代价更低,查询效率更稳定。读写代价低是因为非叶子节点不存储数据,查询效率稳定是因为每次查询都要走一条从根节点到叶子节点的路。
索引并不是越多越好,因为索引提高了select的效率但是降低了insert及update的效率,因为insert和update时要动态的维护索引,索引也占了一定的物理空间,太多的索引列也不是一个太好的选择。
12、什么是聚簇索引
一张表中聚簇索引只有一个,数据与索引存储在一个位置,找到索引就找到了数据。
13、什么是覆盖索引
select的数据列只用从索引中就能够取得,不必读取数据行,换句话说就是查询列能被所建的索引覆盖。
14、索引的数据结构
使用B+树,在InnoDB中每个索引都是一个B+树,主键索引称作聚簇索引,其他非主键索引称为二级索引。主键索引的叶子节点保存整个数据行的记录,而二级索引的叶子节点保存的是主键值。
根据二级索引查询到结果的主键值,再根据主键值在主键索引中查找出记录。
15、索引的最左前缀
- 如果不是按照索引的最左列开始查找,则无法使用索引。
- 联合索引是有顺序的,不能跳过联合索引的某些列。
- 如果查询列中有某个列的范围查询,则其右边所有列都无法使用索引优化查找,因为右边的所有列变得无序。
16、什么情况下不适用索引、SQL优化
- 条件中有or。
- 不符合最左前缀原则。
- like 条件以%开始。
- 出现类型强制转换。
- 条件中有不等于。
- 在条件中进行函数运算,表达式运算。
- 条件中对null值判断。
- in 和 not in。
- mysql估计使用全表扫描要比使用索引快,不会使用索引。
17、什么是数据库的三范式
- 第一范式:要求有主键,并且要求每一个字段原子性不可再分。
- 第二范式:要求所有非主键字段完全依赖主键,不能产生部分依赖。
- 第三范式:所有非主键字段和主键字段之间不能产生传递依赖
18、in和exist的区别
in是把外表和内表做hash连接,而exist是对外表做loop循环,每次loop循环再对内表做查询。
19、执行计划
- id:表示selec语句操作表顺序,id越大表示优先级越高,越先被执行。
- select type 表示每个select子句的类型
- simple 查询中不包含子查询或union
- primary 最外层查询
- subquery select或where 子查询
- derived 在from列表中的子查询
- union 第二个select出现在union之后被标记为union
- union result 从union表获取结果的select
- type 连接类型
- system 查询表只有一行
- const sql查询根据索引一次就找到了
- eq_ref 使用主键或唯一索引,且结果只有一条
- ref 使用非唯一索引查找,能扫描到多条记录
- range 索引范围查找,索引根据指定范围进行查找。常见于between > <等
- index 遍历索引,只扫描索引树,而非数据库表。
- ALL 扫描全表数据
sql语句至少要达到range级别
- table 查询的表
- possible key 查询列上包含的索引
- key 使用到的索引名,如果没有使用索引则是NULL
- ref
- rows 扫描行数 预估值
- extra 详细说明 using index表示使用了覆盖索引,using where表示使用where子句来过滤结果集 using tempory 使用了临时表 using filesort使用了文件排序(无法利用索引完成排序)
20、分库分表
- 垂直拆分
垂直分表:将不常用的字段,数据较大字段较长的拆分到扩展表中,避免查询时数据量太大造成问题。
垂直分库:对于一个系统中根据业务模块进行拆分。 - 水平拆分 一个表分成多个表,一个库分成多个库。
垂直切分解决了IO瓶颈,水平切分减轻了单个表的读写压力。
分库分表的方法:
- 查询切分,将ID和库的mapping单独记录在一个库中,优点是:Id和库的mapping算法可以随意修改。缺点是引入额外的单点,
- 范围切分,比如按照时间区域或者范围来切分,优点:单表大小可控,天然水平扩展,无法解决几种写入的瓶颈问题。
- 采用一致性hash进行切分。
20.1、事务一致性问题
分布式事务:2PC\TCC\事务补偿。
最终一致性:不要求实时一致性的系统,可以采用事务补偿的方式实现最终一致性。
比如一天对数据进行对账检查,基于日志进行对比,定期同标准数据来源进行同步。
20.2、跨节点的分页、排序、函数
先在不同节点的分片节点中对数据进行分页、排序、函数等操作,然后将不同分片返回的结果集进行汇总,和再次的处理,最终返回给用户。
20.3、跨库join的几种方案
- 使用字典表,将这类表在每个库中都保存一份,通常是一些不会修改的数据。
- 字段冗余,冗余一些需要关联的字段。
- 在业务代码中进行组装。
复制表,冗余字段需要解决一致性的问题,可以定期更新。
20.4、一致性hash
一致性hash只能较好的避免扩容过程中的数据迁移问题,但不能完全避免数据迁移问题。
假设由2^32个点组成点组成一个hash环,首先将服务器进行hash,分布在hash环上,将数据key使用相同的hash算法,计算出hash值并分布到hash环上,顺时针遇到的第一个机器就是该数据存储的服务器。可以引入虚拟节点解决一致性hash的数据倾斜问题。一致性hash使得数据迁移达到了最小,且数据分布比较均匀。
20.5、平滑扩展、免迁移扩容
采用双倍扩容策略,避免数据迁移,扩容前每个节点的数据,有一半要迁移至一个新增节点中。先设置成主从结构,然后数据复制完成后再删除主从结构,修改路由规则,然后在删除冗余数据。
20.6、常用的分库分表中间件
- cobar
- mycat
- sharding-jdbc
21、唯一ID
- uuid:本地生成,效率高,但是长度较长,而且无序。
- 雪花算法:时间戳+机器id+序列号 趋势递增不依赖第三方系统,稳定性和效率都比较高,就是强依赖时间。
- 数据库Auto increment 多台机器设置不同的步长,N台机器设置步长为N,初始值是从0-N-1,能保证多个机器的Id不同。
- redis生成Id:本身提供incr increby的自增原子命令,能保证id生成有序。
- 美团的leaf-snowflake需要使用zookeeper。
十二、netty知识点整理
1、netty是什么
netty是基于nio开发的异步的事件驱动的网络通信框架,对比BIO增加了很高的并发性。
2、netty的特点
- 高并发:基于nio。
- 传输快:netty的传输依赖于零拷贝技术,减少了不必要的内存拷贝,提高传输效率。
- 封装好:封装了很多nio的操作细节,提供了易于使用的接口。
3、什么是netty的零拷贝
在OS层面上的Zero-copy 通常指避免在 用户态(User-space) 与 内核态(Kernel-space)之间来回拷贝数据。Netty的Zero-copy完全是在用户态(Java 层面)的, 更多的偏向于优化数据操作。
- 缓冲区buffer在堆外直接内存中对socket进行读写,不需要进行字节缓冲区的二次拷贝。
- Netty的文件传输采用了transferTo方法,它可以直接将文件缓冲区的数据发送到目标Channel,避免了传统通过循环write方式导致的内存拷贝问题。
4、netty的应用场景
- rpc框架-dubbo。
- rocketmq。
5、非阻塞IO的应用场景
rpc框架 dubbo thirft
redis
6、netty高性能表现在哪些方面
- 使用nio
- 零拷贝
- 高性能序列化协议 protobuff
7、netty的组件
- channel
- channelfeature
- eventloop
- channelhandler
- channelpipline
8、netty的线程模型
Netty通过Reactor模型基于多路复用器接收并处理用户请求,内部实现了两个线程池,boss线程池和work线程池,其中boss线程池的线程负责处理请求的accept事件,当接收到accept事件的请求时,把对应的socket封装到一个NioSocketChannel中,并交给work线程池,其中work线程池负责请求的read和write事件,由对应的Handler处理。
9、BIO\NIO\AIO的区别
- bio 一个连接一个线程,客户端有连接请求时服务器端就需要启动一个线程进行处理。线程开销大。
- nio 一个请求一个线程,但客户端发送的连接请求都会注册到多路复用器上,多路复用器轮询到连接有I/O请求时才启动一个线程进行处理。
- aio 一个有效请求一个线程,客户端的I/O请求都是由OS先完成了再通知服务器应用去启动线程进行处理。
10、BIO与NIO的区别
- BIO是面向流的 NIO是面向缓冲区的
- BIO是阻塞的 NIO是非阻塞的
- BIO没有selector NIO有selector
- BIO流是单向的 NIO channel是双向的
11、什么是粘包拆包问题
应用程序写入的字节大小大于套接字发送缓冲区的大小,会发生拆包现象,而应用程序写入数据小于套接字缓冲区大小,网卡将应用多次写入的数据发送到网络上,这将会发生粘包现象;
12、netty如何解决粘包拆包
- 消息定长
- 包尾增加特殊字符分割
- 消息分消息头和消息体
十三、redis知识点整理
1、Redis主节点之间如何同步数据
双主结构,两个redis互为主从,然后通过主从同步来实现双主节点之间的数据同步。
2、Redis主从数据同步
- 建立连接
从节点使用slaveof建立与主节点的socket连接,从节点会发送ping命令进行首次请求,如果返回pong以外的结果,断开socket重连,如果主节点返回pong说明socket连接正常。 - 数据同步
从节点向主节点发送psync命令,开始同步。分为全量复制和部分复制。
全量复制是主节点fork子线程,在后台生成RDB文件,并使用一个复制缓冲区记录从现在开始所有的写命令。当bgsave执行完成之后,将RDB文件发送给从节点,从节点首先清除自己的旧数据,重新载入RDB文件。主节点将复制缓冲区中所有的命令发送给从节点,从节点执行这些命令,更新自己的状态。
部分复制是指主节点和从节点都会记录一个复制偏移量,主要用来判断主从数据库状态是否一致,从节点如果从未复制过数据则会请求全量复制,否则发送psync命令时会发送主节点的runid和offset请求部分复制,主节点根据runid和offset来判断是进行部分复制还是全量复制。如果主节点的runid和从节点发送的runid相同且从节点发送的offset还在复制缓冲区中,那么会把复制缓冲区中的这部分的数据发送给从节点。从节点执行完毕后会更新自己的状态和offset。 - 命令传播(主从节点之间有ping replconf ack命令进行互相的心跳检测)
数据同步完成后,主从节点进入命令传播阶段。这个阶段主要是主节点将自己执行的写命令发送给从节点,从节点接受命令并执行,从而保证主从节点的数据一致性。
3、Redis高可用方案
3.1、哨兵模式
哨兵机制是使用一个或多个哨兵实例组成系统来管理redis的主从服务器,实现故障发现、故障自动转移、配置中心 、客户端通知。
- 故障发现:监控redis master和slave进行工作是否正常。
- 故障自动转移:master宕机之后,slave升级成为master。
- 配置中心:如果故障转移发生了,通知client客户端新的master地址。
- 客户端通知:被监控的redis节点出现问题后,哨兵通过API向管理员或者应用程序发通知。
哨兵的作用:
master的异常检测,发现异常后的故障转移,将其中一个slave作为master,将之前的master作为slave。修改配置文件中的信息。哨兵的工作原理:
每10秒每个哨兵会获取主从节点的info,作用是发现从节点,确认主从关系。
每两秒通过master的pub sub机制交换信息,包括自身节点信息和各节点的信息。如果发现当前master版本低于其他master的版本,则更新当前master的版本。也用于哨兵的互相发现。
每1秒对其他的哨兵和redis节点做ping操作。主要为了进行心跳检测。
如果发现主节点宕机,认为主观宕机,则向其他的哨兵发送消息,如果大多数认为节点宕机,则认为客观宕机。
客观宕机后哨兵会进行选举,选择一个哨兵进行failover。failover会选举一个slave节点作为新的master节点,并更新配置文件,发送slaveof命令完成故障转移。
slave选举会判断:与master的断连次数,slave的优先级,数据复制的下标offset,进程id。
故障转移分为三部分:
- 从下线的主服务中的所有从服务中挑选一个从服务,将其作为主服务。
- 将已下线的主服务的所有从服务改为复制新的主服务。
- 将已下线的主服务设置为新的主服务的从服务。
3.2、Redis主从
主要使用主从同步原理做Redis的高可用。
3.3、Redis分区集群模式
引入了hash槽的概念,分为16384个hash槽。使用crc16 hash算法,将一个key映射成为16位数字。将物理节点映射到hash槽上面。
集群中每个节点都与其他节点相互通信。每个节点都会维护所有节点的信息。节点之间通过gossip协议来交换状态信息,用投票机制完成slave到master的切换。只有master客观下线之后才能进行切换。
从节点只为了作为备用节点,不提供请求,只做故障转移操作。
客户端可以使用jediscluser,本地缓存node节点的信息。
4、什么是主观宕机、客观宕机
- 主观宕机 SDOWN 指单个哨兵实例对服务器做出下线判断。
- 客观宕机 ODOWN 指多个哨兵实例(超过一半)对服务器做出下线判断。
5、Redis持久化方案
- RDB持久化 将redis数据定期dump到磁盘上进行持久化。
- AOF持久化 将redis的操作日志以追加的方式写入文件中。
RDB持久化时会fork一个子线程,先将数据写入临时文件,全部写成功后替换最终文件。
AOF以日志的形式记录服务器的写、删操作,以文本的方式保存。数据安全性高。
redis提供三种同步方式:每秒同步 everysec、每次修改同步 always 和 不同步 no。
6、Redis数据淘汰方案
当redis内存到达最大值时会执行数据淘汰
- volatile-lru 从设置了过期时间的key中淘汰最近最少使用的key。
- volatile-ttl 从设置了过期时间的key中淘汰最先过期的key。
- volatile-random 从设置了过期时间的key中 随机淘汰。
- allkeys-lru 从所有key中挑选最近最少使用的key淘汰。
- allkeys-random 从所有key中随机淘汰。
- no-envication 禁止淘汰数据。
redis的最大使用内存和数据淘汰策略可以根据maxmemory和maxmemory-policy进行配置。
7、Redis数据的过期策略
- 定期删除 定期随机获取一些key判断是否过期
- 惰性删除 访问key时判断key是否过期
8、为什么Redis快
- 纯内存操作。
- 单线程减少线程上下文的切换。
- 使用非阻塞IO,多路IO复用。
9、Redis多路复用原理
利用select、poll、epoll可以监控多个IO事件的能力,在空闲时会把当前线程阻塞,当有一个或多个流有IO事件时,就从阻塞状态中唤醒,于是程序就会轮询一遍所有的流,epoll只轮询真正发出了事件的流,并且只依次顺序的处理就绪的流,这种做法就避免了大量的无用操作。
多路指的是多个网络连接,复用指的是复用同一个线程。
IO多路复用采用事件驱动。
10、Redis的数据结构
10.1、string
内部存储:
- 数字使用int。
- 其他使用SDS。
10.2、list
内部存储:
- ziplist 所有字符串长度小于64字节,数量小于512。
- linkedlist 双向链表。
10.3、hash
内部存储:
- ziplist 数量小于512,所有元素长度小于64字节。
- dict。
10.4、set
内部存储:
- intset 所有元素都是整数,元素数量小于512。
- dict。
10.5、sort set
内部存储:
- ziplist 元素数量小于128 且长度小于64。
- skiplist。
11、Redis hash底层原理
dict字典,hash算法采用murmurhash,冲突解决办法使用链地址法,rehash使用两个hash表,hd[0]和hd[1]。渐进式rehash,先为ht[1]分配空间让dict持有两个hash表的引用,维持一个索引计数器,rehashidx,将它的值设为0表示rehash开始,在rehash期间,每次对字典crud操作,都会将ht[0]中的数据rehash到ht[1]中,并且将rehashidx增加1,当所有的ht[0]中的数据全部转移到ht[1]中时,将rehashidx设置为-1,将ht[1]的指针赋给ht[0],ht[1]置为null。
ziplist是为了节约内存开发的,由一块连续内存块组成的顺序型的数据结构,每个压缩节点可以保存一个字节数组或一个整数值。
其中的每个entry节点头部保存前后节点长度信息,实现双向链表功能。
数据少时使用ziplist数据多时使用dict
所有元素数量小于512,且每个元素大小小于64字节使用ziplist否则使用dict。
12、skiplist
跳跃表是一种有序的数据结构,通过在每个节点上维持多个节点的指针,从而达到快速访问的目的。跳跃表多层构成,每层都是一个有序链表,最底层链表包含所有元素。随机产生层数。
13、ziplist
ziplist是为了节约内存开发的,由一块连续内存块组成的顺序型的数据结构,每个压缩节点可以保存一个字节数组或一个整数值。其中的每个entry节点头部保存前后节点长度信息,实现双向链表功能。
14、如何利用Redis实现分布式锁
使用SETNX获取锁,并使用expire命令为锁添加一个超时时间,超过超时时间会自动释放锁,避免产生死锁。锁的value是随机生成的uuid,用来在释放锁的时候进行判断。释放锁的时候通过uuid来判断是不是该锁,若是则使用delete操作进行释放。
但存在一个问题,如果线程执行时间过长超过了锁过期的时间就会造成多个线程拥有锁,导致分布式锁失效。
15、如何利用Redis集群实现分布式锁
redlock算法:
获取当前时间戳,并以此向N个节点获取锁,与单机获取锁相同。计算整个获取锁的时间,如果大于半数的节点都获取到锁,且没有超过锁的超时时间,则获取锁成功。如果获取失败则向所有节点发起释放锁。
如果中间出现了主节点宕机,异步复制还未同步,此时可能出现多个客户端同时加锁成功。
16、Redis事务如何实现
通过 multi、discard、exec、watch四个命令来实现redis的事务。使用multi开启事务,有exec触发提交事务,discard用于取消事务。
watch的作用是在事务开启之前监视任意数量的键,如果任意一个被监视的键被客户端修改,则整个事务不执行。当客户端结束事务,无论事务成功失败,watch的键和客户端相关资料都会被删除。
17、Redis的pub\sub机制如何实现
通过publish和subcribe命令实现订阅发布。
redis维护了一个pubsub_channels的字典,字典用于保存订阅频道的信息,字典的键是频道名,字典的值是一个链表,链表中保存了订阅这个频道的客户端。客户端调用suncribe命令时,redis就将客户端和要订阅的频道在pubsub_channels关联起来。
subcribe channel1 channel2
publish channel1 message
使用unsubcribe channel1 退订频道。从pubsub_channels删除频道中对应的客户端信息。
模式的订阅是指正则表达式。publish的message不仅会发送到某个频道,如果有某个模式和这个频道匹配的话,那么订阅这个模式的客户端也会收到消息。底层使用pubsub_patterns链表保存,每个节点都保存了patterns和订阅的客户端,只需要遍历整个列表就能找到要发送的客户端有哪些。
psubcribe patterns 用来订阅模式
punsubcribe patterns 用来退订模式
18、Redis和Memcache有什么区别
- redis支持多种数据类型,memcache只支持字符串。
- redis支持持久化,memcache不支持。
- redis支持分布式,memcache不支持。
19、缓存雪崩
同一时刻出现大面积缓存失效,导致DB压力过大。
解决办法:
- 考虑同步的方式对数据库进行读写。
- 做二级缓存,A为原始缓存,B为拷贝缓存,当A失效时可以访问B
- 通过hystrix对请求进行限流和降级处理。
- 在原来过期时间的基础上加随机值。
- 给缓存设置一个过期标志的key,这个key的过期时间是缓存过期时间的一半,先判断这个key是否过期,如果过期异步刷新缓存。
20、缓存穿透
如果海量请求查询不存在的key,这些请求会落到DB上,导致DB压力大
- 缓存null值,并不能根本解决问题,如果使用不同的key并发访问,这种办法失效
- 布隆过滤器。
布隆过滤器的实现原理:一个bit的数组加一组hash函数组成,对一个key进行K次hash,映射到bit数组的K个点上,将这K个点存储为1,下次进来时候,做同样的操作,查看这K位是否都为1,有一位是0则返回空值。
21、缓存击穿
热点数据集中失效
- 设置热点数据永不过期。
- 加互斥锁,保证缓存失效后的第一个请求命中到数据库,其他请求还是在第一个请求把数据写入缓存后访问缓存。
22、热点数据
一个计时周期内一个数据的访问频次。
23、如何解决分布式缓存一致性
Cache-Aside-pattern:
- 失效
应用程序先从cache中取数据,没有得到(数据带失效时间),则从数据库中取数据,成功后,放入缓存。 - 命中
应用程序从cache中取数据,取到数据后返回。 - 更新
先将数据更新到数据库中,成功后,再将缓存数据清除。
24、缓存算法
LRU 最近最少使用 利用链表+hashmap实现,每次查看hashmap中是否存在,存在则返回,并将节点添加至链表的头结点。不存在则加入链表尾结点,每次淘汰从链表的尾结点进行淘汰。
LFU 最不经常使用 使用两个map进行实现,一个map记录key value 另一个map记录key的访问频次和访问时间。淘汰最少使用的key。
FIFO 先进先出,使用链表实现,从头部淘汰,尾部添加。
十四、Spring面试知识点整理
1、事务传播行为
- require 如果存在事务则加入,否则新建事务。
- supports 如果存在事务则加入,否则不使用事务。
- mandatory 如果存在事务则加入,否则抛异常。
- require_new 创建事务,当前存在事务则将当前事务挂起。
- not_support 以非事务的方式运行,如果当前存在事务则挂起。
- never 以非事务方式运行,如果当前存在事务则抛出异常。
- nested 如果当前存在事务,则创建事务作为嵌套事务,如果当前不存在事务,则新建事务。
2、事务隔离性
- default 使用数据库设置的隔离级别
- ReadUncommitted 出现脏读、不可重复读、幻读。
- ReadCommitted 出现不可重复读、幻读。
- RepeatableRead 出现幻读。
- serializable 串行执行。
3、Spring事务怎么实现
通过AOP来实现声明式事务处理,Spring启动时会解析生成相关的bean,这时候会查看相关注解的类和方法,并且为这些类和方法生成代理,并根据@Transactional的相关参数进行配置注入。
注意:
- @Transactional只能修饰public方法。
- 自调用的方法事务不生效,如果想让事务生效,必须显示的通过代理对象调用。
- 数据库引擎必须支持事务。
- 异常被捕获时回滚。
4、动态代理
JDK的动态代理要求类必须实现了接口,cglib需要引入cglib的类库。
4.1、JDK动态代理
JDK动态代理的核心是invocationHandler接口和Proxy类。要求代理类必须实现接口。然后实现invocationHandler,通过反射获取代理对象,在调用代理对象方法时,在方法的前后做相关的操作。
4.2、cglib的动态代理
通过实现MethodInterceptor接口,重写interceptor方法,类似于回调方法,调用代理对象的方法时会调用到interceptor方法,在interceptor方法中做相关操作。
5、SpringAOP
AOP是基于动态代理实现的。如果代理对象实现了接口,那么使用JDK动态代理生成代理对象,否则使用cglib生成代理对象。
6、SpringIOC
SpringIOC控制反转,对象都由spring容器来管理,使得对象之间解耦,底层通过反射获取实现,SpringIOC负责创建对象,管理对象,整合对象和配置对象。
7、Bean的作用域
- singleton 默认的作用域,单例。
- prototype 每次注入或者通过Spring上下文获取实例都会重新创建一次。
- request 每次http请求都会创建一次。
- session 每个session都会创建一次。
8、Bean的生命周期
- 创建Bean实例。
- 设置属性值。
- 如果实现了BeanNameAware接口,调用setBeanName的方法。
- 如果实现了BeanFactoryAware接口,调用setBeanFactory方法。
- 如果实现了ApplicationContextAware接口,调用setApplicationContext方法。
- 如果实现了BeanPostProcessor接口,则调用postProcessBeforeInitialization方法。
- 如果实现了InitailizeBean接口,则调用afterPropertiesSet方法。
- 在bean的配置文件中配置了init-method,则调用指定方法。
- 如果实现了BeanPostProcessor接口,则调用postProcessAfterInitialization方法。
销毁Bean的时候,如果实现了DisposableBean,则执行destroy方法。
9、SpringMVC工作原理
- 客户端请求到DispatcherServlet。
- DispatcherServlet根据请求信息调用handlerMapper,找到对应的handler。
- 将handler交由handlerAdapter处理。
- handlerAdapter根据handler找到具体的controller进行处理,并返回ModelAndView对象。
- DispatcherServlet将ModelAndView对象发送给ViewResolver进行解析。
- ViewResover会返回对应的view给DispatcherServlet,然后返回给用户。
10、SpringMVC启动流程
Web容器初始化:先初始化Listener,然后初始化Filter,最后初始化Servlet。
初始化Listener的时候,一般会使用ContextLoaderListener类,Spring会创建一个WebApplicationContext对象作为IOC容器,全局的读取wen.xml中配置的ContextConfigLocation参数中的xml来创建对应的Bean。
Listener初始化完成之后会去初始化Filter,最后初始化Servlet。Servlet会创建一个当前的Servlet的IOC的子容器,并将刚刚生成的WebApplicationContext作为父容器,读取Servlet initParam配置的xml,并初始化加载相关的Bean。
11、BeanFactory和AppliacationContext有什么区别
ApplicationContext是BeanFactory的子接口,对BeanFactory进行了扩展。在其基础上增加了AOP、事件传播、MessageResource(国际化)。
BeanFactory是IOC容器的核心接口,用来包装和管理各种Bean。
BeanFactory是延迟加载的,只有从容器中获取Bean的时候,才会去实例化。
12、SpringMVC与SpringBoot的区别
SpringMVC提供了一个轻度耦合的方式开发web应用。SpringBoot实现了自动配置,降低项目搭建的复杂度。
13、Hystrix
服务熔断降级,每一个请求都是Hystrix的一个Command,每个Command都会向熔断器报告状态,熔断器会维护统计这些数据,并根据这些数据来判断熔断器是否打开,如果熔断器打开,请求快速返回,隔一段时间熔断器尝试半开,放一部分请求过来,进行健康检查,如果检查成功,熔断器关闭,否则继续打开。
14、如何解决循环引用
- 构造器循环依赖
将当前正在创建的Bean记录在缓存中,如果创建Bean的过程中发现自己已经在缓存中,则报错BeanCurrentlyInCreationException,表示循环依赖。对于创建完成的bean会从缓存中删除。 - setter循环依赖(只有单例模式才生效,prototype是不会做缓存的)使用三级缓存:singletonFactories(进入实例化阶段的单例对象)、earlySingletonObjects(完成实例化但是没有初始化的对象)、singletonObjects(完成初始化的单例对象)。
Spring解决循环依赖的方法_lkforce-CSDN博客
15、@Autowired与@Resource的区别
- @Autowired默认是byType进行注入的,@Resource是byName进行注入。
- @Autowired可以设置成require属性,如果为true则必须注入,如果是false则可以不注入。
- 如果是@Autowired,可以用name与@Qualifier配合使用。
- @Resource可以指定注入方式。
16、@Component与@Bean的区别
@Component注解基于类,@Bean基于方法。
17、将一个类声明为Spring的bean的注解有哪些
@Componet:通用的注解,可以标注任意类为Spring bean。
@Repository:持久层,DAO层
@Service:服务层。
@Controller:控制器层
这四个注解均在org.springframework.stereotype包下。
18、Spring单例的实现原理
使用单例注册表的方式实现,注册表为ConcurrentHashMap。
19、SpringIOC的注入方式
- 构造器注入
- setter注入
- 注解注入
20、Spring容器与SpringMVC容器以及Web容器的关系
Spring容器是SpringMVC的父容器,子容器可以直接使用父容器的bean,如:Controller中注入Service。Web容器包括Servlet、Filter、Listener等,和Spring及SpringMVC容器无关,当Web容器中想使用Spring中的Bean时,需要通过ServletContextEvent获取WebApplicationContext 或者ApplicationContext,之后就可以获取Bean了。
详细参考:spring容器和springmvc容器,以及web容器的关系 - 海小鑫 - 博客园
21、SpringBoot @Condition条件装配
假设一个接口有多个实现,都要由Spring来管理,但是Spring没法明白到底要把哪个类加载到容器中,@Conditional 的功能,就是在不同条件下,指导加载器,要构建哪些bean加入到ioc容器。
详细参考:springboot 条件装配 - 简书
22、Spring对于相同name或者id的bean的处理
当一个功能的开发人数过多时,就会发生配置文件或者注解中配置了同样名称或者ID的Bean,当然它们的内部属性可能不同,当Spring加载时,后者会将前者覆盖掉,如果将DefaultListableBeanFactory类的属性allowBeanDefinitionOverriding设置为false,则启动时会报错,便于定位问题。
详细参考:解决spring中不同配置文件中存在name或者id相同的bean可能引起的问题_zgmzyr的专栏-CSDN博客
23、Controller中注入Request对象
Controller中可以注入HttpServletRequest对象吗?答案是:能的,这样有引入了一个问题,Controller是在SpringMVC初始化加载到容器中的,而HttpServletRequest每次请求都不一样,Spring是怎么处理的呢,而且怎么保证线程安全的呢?答案是:使用动态代理+ThreadLocal技术。当代理对象被调用的时候,会最终获取RequestContextHolder中的ThreadLocal成员变量中存放的Request对象。那么这个Request对象是Spring什么时候放入的呢?答案是:在SpringMVC的DispatcherServlet的父类FrameworkServlet的processRequest方法中处理的。
详细参考:在SpringMVC Controller中注入Request成员域 - abcwt112 - 博客园
spring bean中注入HttpServletRequest成员变量的思考 - 简书
24、Web中的filter获取Spring中的Bean
需要获取WebApplicationContext ,之后就可以获取到bean了。
详细参考:filter中获取spring bean - 晨羲 - 博客园
25、Dubbo中如何注入Spring中的Bean
Dubbo初始化时,是怎么获取到Spring容器中的Bean呢?
使用dubbo-spring时,ReferenceBean和ServiceBean均实现了ApplicationContextAware,回调方法中会将ApplicationContent传递给扩展工厂SpringExtensionFactory。这样bean就可以在Dubbo中注入了。注入的方式和原理参考下面的文章:如何在filter等dubbo自管理组件中注入spring的bean - 简书
十五、zookeeper知识点整理
1、zookeeper是什么
开源的分布式应用协调服务。
2、zookeeper提供了什么
- 文件系统
- 通知机制
3、zookeeper做了什么
- 命名服务 利用zk创建一个全局路径,这个全局路径唯一,作为一个名字指向服务提供地址等。
- 配置管理,将程序的配置信息放在znode下面,znode发生变换通过watcher机制通知客户端。
- 集群管理。
- 分布式锁。
4、zookeeper如何实现分布式锁
获取分布式锁是在locker目录下建立临时顺序节点,释放锁时删除该临时节点。
客户端连接zookeeper,并在目录下创建临时节点,判断自己创建的临时节点是否是节点中最小的,如果是则认为获取到锁,否则监听刚好在自己前一位的子节点的变更消息,获得变更消息后,重复执行上面的步骤,直到获取到锁。业务代码执行完成后,删除临时自节点。
第三方工具curator可直接使用分布式锁。
5、zookeeper的通知机制
client 端会对某个 znode 建立一个 watcher 事件,当该 znode 发生变化时,这些 client 会收到 zk 的通知,然后 client 可以根据 znode 变化来做出业务上的改变等。
注册watcher getData、exists、getChildren
触发watcher create、delete、setData
通知机制不是永久的,是一次性的,需要借助第三方工具实现重复注册。
6、zookeeper有几种节点类型
持久节点、持久顺序节点、临时节点、临时顺序节点。

版权声明
本文为[ClawHub的博客]所创,转载请带上原文链接,感谢
https://clawhub.club/posts/2020/01/08/%E9%9D%A2%E8%AF%95/%E7%9F%A5%E8%AF%86%E7%82%B9%E6%95%B4%E7%90%86/
边栏推荐
猜你喜欢


随机推荐
面经手册 · 第12篇《面试官,ThreadLocal 你要这么问,我就挂了!》
网络安全工程师演示:原来***是这样获取你的计算机管理员权限的!【维持】
Asp.Net Core學習筆記:入門篇
谁说Cat不能做链路跟踪的,给我站出来
如果前端不使用SPA又能怎样?- Hacker News
微信小程序:防止多次点击跳转(函数节流)
人工智能学什么课程?它将替代人类工作?
50 + open source projects are officially assembled, and millions of developers are voting
GDB除錯基礎使用方法
对pandas 数据进行数据打乱并选取训练机与测试机集
安装Anaconda3 后,怎样使用 Python 2.7?
Real time data synchronization scheme based on Flink SQL CDC
Network programming NiO: Bio and NiO
hadoop 命令总结
Azure Data Factory(三)整合 Azure Devops 實現CI/CD
不吹不黑,跨平臺框架AspNetCore開發實踐雜談
ThreadLocal原理大解析
如何将分布式锁封装的更优雅
7.2.2 compressing static resources through gzipresourceresolver
[performance optimization] Nani? Memory overflow again?! It's time to sum up the wave!!