当前位置:网站首页>基于深度学习的推荐系统
基于深度学习的推荐系统
2020-11-06 01:28:00 【人工智能遇见磐创】
作者|James Loy 编译|VK 来源|Towards Data Science
传统的推荐系统基于聚类、最近邻和矩阵分解等方法。然而,近年来,深度学习在从图像识别到自然语言处理等多个领域取得了巨大的成功。推荐系统也得益于深度学习的成功。事实上,如今最先进的推荐系统,比如Youtube和Amazon的推荐系统,都是由复杂的深度学习系统驱动的,而不是传统方法。
本教程
在阅读了许多有用的教程,这些教程介绍了使用诸如矩阵分解等传统方法的推荐系统的基础知识,但我注意到,缺乏介绍基于深度学习的推荐系统的教程。在本教程中,我们将介绍以下内容:
-
如何使用PyTorch Lightning创建自己的基于深度学习的推荐系统
-
推荐系统中隐式反馈与显式反馈的区别
-
如何在不引入偏差和数据泄漏的情况下训练测试分割数据集以训练推荐系统
-
评估推荐系统的指标(提示:准确度或RMSE不合适!)
数据集
本教程使用MovieLens 20M数据集提供的电影评论,这是一个流行的电影评分数据集,包含1995年至2015年收集的2000万部电影评论。
如果你想查看本教程中的代码,可以查看我的Kaggle Notebook,在这里你可以运行代码,并在本教程中查看输出:https://www.kaggle.com/jamesloy/deep-learning-based-recommender-systems
利用隐式反馈构建推荐系统
在我们建立模型之前,重要的是要理解隐式反馈和显式反馈之间的区别,以及为什么现代推荐系统是建立在隐式反馈的基础上的。
显式反馈
在推荐系统中,显式反馈是从用户那里收集的直接的、定量的数据。例如,亚马逊允许用户对购买的商品进行1-10的评分。这些评分是直接由用户提供的,这个评分标准允许亚马逊量化用户的偏好。另一个明确反馈的例子包括YouTube上的赞/踩按钮,它捕捉用户对特定视频的明确偏好(即喜欢或不喜欢)。
然而,显式反馈的问题是它们很少。如果你仔细想想,你上一次点击YouTube视频上的“喜欢”按钮,或者对你的网上购物进行评级是什么时候?很可能你在YouTube上观看的视频数量远远大于你明确评级的视频数量。
隐性反馈
另一方面,隐式反馈是从用户交互中间接收集的,它们充当用户偏好的代理。例如。你在YouTube上观看的视频被用作隐式反馈,为你量身定做推荐,即使你没有明确地给视频打分。另一个隐含反馈的例子包括你在亚马逊上浏览过的商品,这些商品用来为你推荐其他类似的项目。
隐性反的优点在于它是丰富的。使用隐式反馈构建的推荐系统还允许我们通过每次点击和交互实时定制推荐。今天,在线推荐系统是使用隐式反馈构建的,它允许系统在每次用户交互时实时调整其推荐。
数据预处理
在开始构建和训练我们的模型之前,让我们做一些预处理,以获得所需格式的MovieLens数据。
为了保持30%的数据在用户可管理的范围内使用,我们将只使用30%的数据集。让我们随机选择30%的用户,并且只使用所选用户的数据。
import pandas as pd
import numpy as np
np.random.seed(123)
ratings = pd.read_csv('rating.csv', parse_dates=['timestamp'])
rand_userIds = np.random.choice(ratings['userId'].unique(),
size=int(len(ratings['userId'].unique())*0.3),
replace=False)
ratings = ratings.loc[ratings['userId'].isin(rand_userIds)]
过滤数据集之后,现在有来自41547个用户的6027314行数据(这仍然是大量数据!)。数据帧中的每一行都对应于单个用户的电影评论,如下所示。
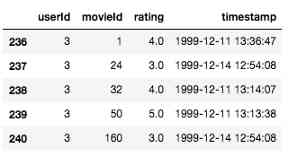
训练测试拆分
除了评级之外,还有一个时间戳列,显示提交评审的日期和时间。使用timestamp列,我们将使用留一法实现我们的训练测试分割策略。对于每个用户,最新的评分被用作测试集(即,测试集样本数为1),而其余的将用作训练数据。
为了说明这一点,用户39849审查的电影如下所示。用户评论的最后一部电影是2014年热映的《银河守护者》。我们将使用这部电影作为该用户的测试数据,并将其余已审查的影片用作训练数据。
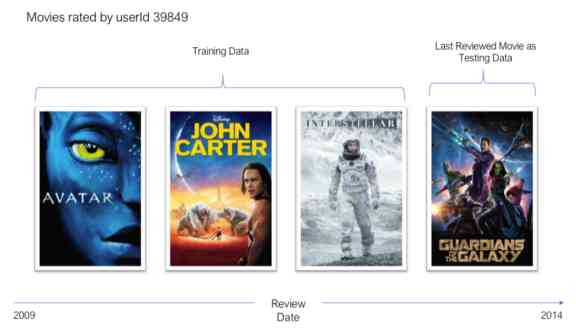
在训练和评估推荐系统时,经常使用这种训练-测试分割策略。做一个随机的分割是不公平的,因为我们可能会使用用户最近的评论进行训练,而使用早期的评论进行测试。这就引入了具有前瞻性偏差的数据泄漏,并且训练后的模型的性能不能概括为真实世界的性能。
下面的代码将使用留一法将我们的评分数据集分割为一个训练和测试集。
ratings['rank_latest'] = ratings.groupby(['userId'])['timestamp'].rank(method='first', ascending=False)
train_ratings = ratings[ratings['rank_latest'] != 1]
test_ratings = ratings[ratings['rank_latest'] == 1]
# 删除我们不再需要的列
train_ratings = train_ratings[['userId', 'movieId', 'rating']]
test_ratings = test_ratings[['userId', 'movieId', 'rating']]
将数据集转换为隐式反馈数据集
如前所述,我们将使用隐式反馈来训练推荐系统。然而,我们使用的MovieLens数据集是基于显式反馈的。要将此数据集转换为隐式反馈数据集,我们只需将评级进行二进制化并将其转换为“1”(即正类)。值“1”表示用户已与该项交互。
需要注意的是,使用隐式反馈可以重新定义我们的推荐者试图解决的问题。我们不是试图在使用显时反馈时预测电影收视率,而是试图预测用户是否会与每部电影互动(即点击/购买/观看),目的是向用户展示具有最高交互可能性的电影。
train_ratings.loc[:, 'rating'] = 1
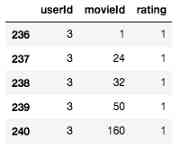
不过,我们现在确实有问题。在对数据集进行二进制化之后,我们看到数据集中的每个样本现在都属于正类。我们假设其余的电影是那些用户不感兴趣的电影-即使这是一个广泛的假设,可能不是真的,它通常是相当好的实践。
下面的代码为每行数据生成4个负样本。换句话说,阴性样本与阳性样本的比率是4:1。这个比例是任意选择的,但我发现它在实践中运行得相当好(你可以自己找到最好的比率!)。
# 获取所有电影id的列表
all_movieIds = ratings['movieId'].unique()
# 用于保存训练数据的占位符
users, items, labels = [], [], []
# 这是每个用户都与之交互的项目集
user_item_set = set(zip(train_ratings['userId'], train_ratings['movieId']))
# 4:1
num_negatives = 4
for (u, i) in user_item_set:
users.append(u)
items.append(i)
labels.append(1) # 用户与项目有交互
for _ in range(num_negatives):
# 随机选择一个项目
negative_item = np.random.choice(all_movieIds)
# 检查用户是否与该项目进行了交互
while (u, negative_item) in user_item_set:
negative_item = np.random.choice(all_movieIds)
users.append(u)
items.append(negative_item)
labels.append(0) # 代表没有交互
太好了!我们现在有了模型所需格式的数据。在继续之前,让我们定义一个PyTorch数据集,以便于训练。下面的类简单地将上面编写的代码封装到PyTorch数据集类中。
import torch
from torch.utils.data import Dataset
class MovieLensTrainDataset(Dataset):
"""MovieLens PyTorch数据集用于训练
Args:
ratings (pd.DataFrame): 包含电影评级的DataFrame
all_movieIds (list): 包含所有电影id的列表
"""
def __init__(self, ratings, all_movieIds):
self.users, self.items, self.labels = self.get_dataset(ratings, all_movieIds)
def __len__(self):
return len(self.users)
def __getitem__(self, idx):
return self.users[idx], self.items[idx], self.labels[idx]
def get_dataset(self, ratings, all_movieIds):
users, items, labels = [], [], []
user_item_set = set(zip(ratings['userId'], ratings['movieId']))
num_negatives = 4
for u, i in user_item_set:
users.append(u)
items.append(i)
labels.append(1)
for _ in range(num_negatives):
negative_item = np.random.choice(all_movieIds)
while (u, negative_item) in user_item_set:
negative_item = np.random.choice(all_movieIds)
users.append(u)
items.append(negative_item)
labels.append(0)
return torch.tensor(users), torch.tensor(items), torch.tensor(labels)
我们的模型-神经协同过滤(NCF)
虽然有许多基于深度学习的推荐系统架构,但是我发现由He等人(https://arxiv.org/abs/1708.05031)提出的框架。是最直接的,它非常简单,可以在这样的教程中实现。
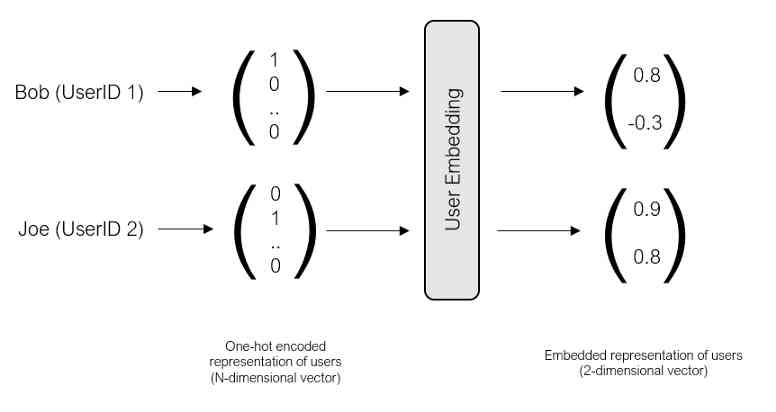
用户嵌入
在深入研究模型的体系结构之前,让我们先熟悉一下嵌入的概念。嵌入是一个低维空间,它从高维空间捕获向量之间的关系。为了更好地理解这个概念,让我们更仔细地研究一下用户嵌入。
假设我们想根据用户对两种类型电影的偏好来代表他们——动作片和浪漫片。让第一个维度是用户对动作电影的喜爱程度,第二个维度是用户对浪漫电影的喜爱程度。
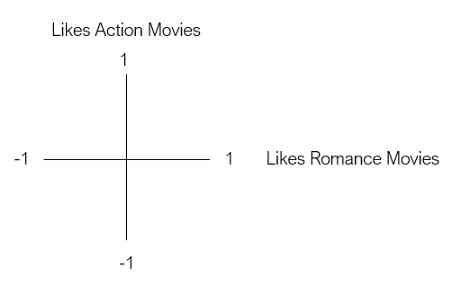
现在,假设Bob是我们的第一个用户。鲍勃喜欢动作片,但不喜欢爱情片。为了将Bob表示为二维向量,我们根据Bob的偏好将其放置在图中。
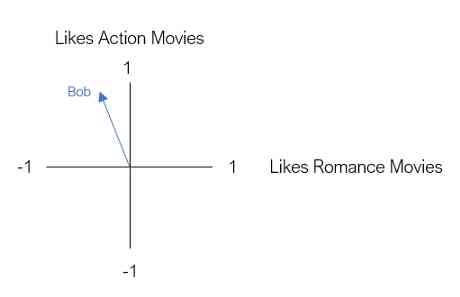
我们的下一个用户是乔。乔是动作片和爱情片的超级粉丝。我们用一个二维向量来表示Joe,就像Bob一样。
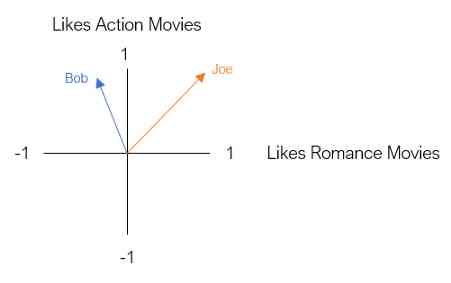
这个二维空间被称为嵌入。本质上,嵌入减少了我们的用户,使他们可以在一个低维空间中以有意义的方式表示。在这种嵌入中,具有相似电影偏好的用户彼此靠近,反之亦然。
当然,我们并不局限于仅使用二维来表示我们的用户。我们可以使用任意数量的维度来表示我们的用户。更大数量的维度将允许我们更准确地捕捉每个用户的特征,而代价是模型的复杂性。在我们的代码中,我们将使用8个维度(稍后将看到)。
学习嵌入
类似地,我们将使用一个单独的项目嵌入层来表示项目(即电影)在低维空间中的特征。
你可能会想知道,我们如何了解嵌入层的权重,以便它提供用户和项目的准确表示?在前面的示例中,我们使用了Bob和Joe对动作和浪漫电影的偏好来手动创建嵌入。有没有办法自动学习这种嵌入?
答案是协同过滤——通过使用分级数据集,我们可以识别相似的用户和电影,创建从现有评级中学习到的用户和项目嵌入。
模型体系结构
既然我们对嵌入有了更好的理解,我们就可以定义模型体系结构了。正如你将看到的,用户和项嵌入是模型的关键。
让我们使用以下训练示例来浏览模型体系结构:

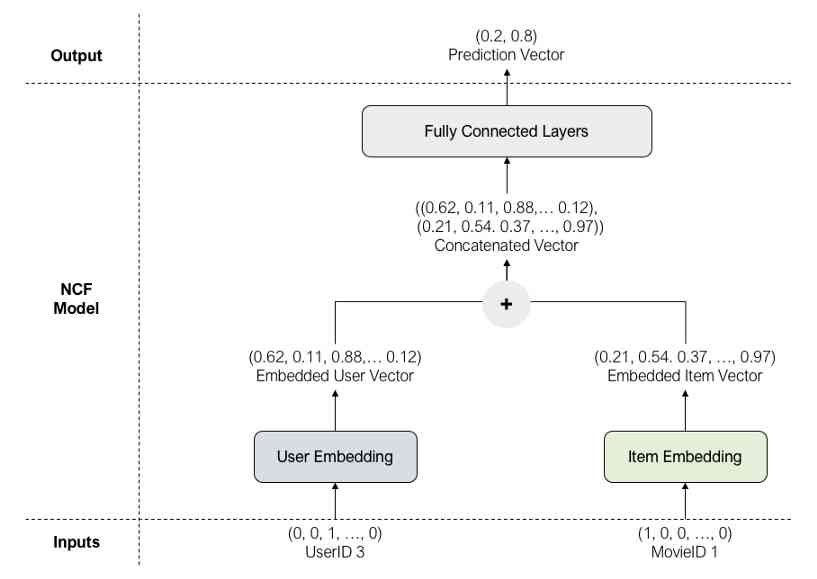
模型的输入是userId=3和movieId=1的one-hot编码用户和项向量。因为这是一个正样本(用户实际评级的电影),所以标签是1。
用户向量和项目向量分别被输入到用户嵌入和项目嵌入中,从而得到更小、更密集的用户和项目向量。
嵌入的用户和项目向量在通过一系列完全连接的层之前被连接起来,这些层将连接的嵌入映射到一个预测向量中作为输出。在输出层,我们应用一个Sigmoid函数来获得最可能类。在上面的例子中,由于0.8>0.2,最有可能的类是1(正类)。
现在,让我们用PyTorch Lightning来定义这个NCF模型!
import torch.nn as nn
import pytorch_lightning as pl
from torch.utils.data import DataLoader
class NCF(pl.LightningModule):
""" 神经协同过滤(NCF)
Args:
num_users (int): 唯一用户的数量
num_items (int): 唯一项的数量
ratings (pd.DataFrame): 包含用于训练的电影评级
all_movieIds (list): 包含所有movieIds的列表(训练+测试)
"""
def __init__(self, num_users, num_items, ratings, all_movieIds):
super().__init__()
self.user_embedding = nn.Embedding(num_embeddings=num_users, embedding_dim=8)
self.item_embedding = nn.Embedding(num_embeddings=num_items, embedding_dim=8)
self.fc1 = nn.Linear(in_features=16, out_features=64)
self.fc2 = nn.Linear(in_features=64, out_features=32)
self.output = nn.Linear(in_features=32, out_features=1)
self.ratings = ratings
self.all_movieIds = all_movieIds
def forward(self, user_input, item_input):
# 通过嵌入层
user_embedded = self.user_embedding(user_input)
item_embedded = self.item_embedding(item_input)
# Concat两个嵌入层
vector = torch.cat([user_embedded, item_embedded], dim=-1)
# 通过全连接层
vector = nn.ReLU()(self.fc1(vector))
vector = nn.ReLU()(self.fc2(vector))
# 输出层
pred = nn.Sigmoid()(self.output(vector))
return pred
def training_step(self, batch, batch_idx):
user_input, item_input, labels = batch
predicted_labels = self(user_input, item_input)
loss = nn.BCELoss()(predicted_labels, labels.view(-1, 1).float())
return loss
def configure_optimizers(self):
return torch.optim.Adam(self.parameters())
def train_dataloader(self):
return DataLoader(MovieLensTrainDataset(self.ratings, self.all_movieIds),
batch_size=512, num_workers=4)
让我们用GPU训练我们的NCF模型,epoch=5
注意:PyTorch Lightning与vanilla PyTorch相比的一个优势是,你不需要编写自己的训练代码。注意Trainer类是如何让我们只需要几行代码就可以训练我们的模型。
num_users = ratings['userId'].max()+1
num_items = ratings['movieId'].max()+1
all_movieIds = ratings['movieId'].unique()
model = NCF(num_users, num_items, train_ratings, all_movieIds)
trainer = pl.Trainer(max_epochs=5, gpus=1, reload_dataloaders_every_epoch=True,
progress_bar_refresh_rate=50, logger=False, checkpoint_callback=False)
trainer.fit(model)
评估我们的推荐系统
现在我们已经训练出了模型,我们准备使用测试数据来评估它。在传统的机器学习项目中,我们使用诸如准确性(对于分类问题)和RMSE(对于回归问题)这样的度量来评估我们的模型。然而,这样的度量对于评估推荐系统来说过于简单。
为了设计一个好的评价推荐系统的指标,我们首先需要了解现代推荐系统是如何使用的。
看看Netflix,我们可以看到如下推荐列表:
同样,亚马逊给出:
这里的关键是我们不需要用户与推荐列表中的每一项进行交互。至少我们需要用户与列表中的一个项目进行交互,至少我们需要与该项目进行交互。
为了模拟这一点,让我们运行下面的评估协议,为每个用户生成一个前10个推荐项的列表。
-
对于每个用户,随机选择99个用户没有交互的项目。
-
将这99个项目与测试项目(用户最后一次交互的实际项目)结合起来。我们现在有100件。
-
对这100个项目运行模型,并根据它们的预测概率对它们进行排序。
-
从100个项目列表中选择前10个项目。如果测试项出现在前10项中,那么我们认为这是命中。
-
对所有用户重复此过程。命中率就是平均命中率。
这种评估协议称为命中率@10( Hit Ratio @ 10),通常用于评估推荐系统。
命中率@10
现在,让我们使用所描述的协议来评估我们的模型。
# 用于测试的用户-项目对
test_user_item_set = set(zip(test_ratings['userId'], test_ratings['movieId']))
# 每个用户与之交互的所有条目
user_interacted_items = ratings.groupby('userId')['movieId'].apply(list).to_dict()
hits = []
for (u,i) in test_user_item_set:
interacted_items = user_interacted_items[u]
not_interacted_items = set(all_movieIds) - set(interacted_items)
selected_not_interacted = list(np.random.choice(list(not_interacted_items), 99))
test_items = selected_not_interacted + [i]
predicted_labels = np.squeeze(model(torch.tensor([u]*100),
torch.tensor(test_items)).detach().numpy())
top10_items = [test_items[i] for i in np.argsort(predicted_labels)[::-1][0:10].tolist()]
if i in top10_items:
hits.append(1)
else:
hits.append(0)
print("The Hit Ratio @ 10 is {:.2f}".format(np.average(hits)))

我们有相当不错的命中率@10!从上下文来看,这意味着86%的用户被推荐了他们最终交互的实际项目(在10个项目列表中)。不错!
下一步
我希望这是一个有用的介绍,以创建一个基于深度学习的推荐系统。要了解更多信息,我建议使用以下资源:
- Wide & Deep Learning — Model introduced by Google for Recommender Systems(https://ai.googleblog.com/2016/06/wide-deep-learning-better-together-with.html)
- Recommenders library by Microsoft — Best practices for Recommender Systems(https://github.com/microsoft/recommenders)
- Deep Learning based Recommender Systems — Useful survey paper(https://arxiv.org/pdf/1707.07435.pdf)
原文链接:https://towardsdatascience.com/deep-learning-based-recommender-systems-3d120201db7e
欢迎关注磐创AI博客站: http://panchuang.net/
sklearn机器学习中文官方文档: http://sklearn123.com/
欢迎关注磐创博客资源汇总站: http://docs.panchuang.net/
版权声明
本文为[人工智能遇见磐创]所创,转载请带上原文链接,感谢
https://my.oschina.net/u/4253699/blog/4698398
边栏推荐
猜你喜欢

通用的底层埋点都是怎么做的?
【數量技術宅|金融資料系列分享】套利策略的價差序列計算,恐怕沒有你想的那麼簡單

mongodb(从0到1),11天mongodb初级到中级进阶秘籍
让人怪不好意思的,粉丝破万,用了1年!
How to select the evaluation index of classification model

Working principle of gradient descent algorithm in machine learning
被老程式設計師壓榨怎麼辦?我不想辭職
网络安全工程师演示:原来***是这样获取你的计算机管理员权限的!【***】
Elasticsearch数据库 | Elasticsearch-7.5.0应用搭建实战
PPT画成这样,述职答辩还能过吗?
随机推荐
互联网 舆情系统的架构实践
C语言中字符字符串以及内存操作函数
【性能优化】纳尼?内存又溢出了?!是时候总结一波了!!
今天你写博客了吗?
Vue 3 响应式基础
结构化数据中的存在判断问题
【Flutter 實戰】pubspec.yaml 配置檔案詳解
使用Consul实现服务发现:instance-id自定义
ES6精华:Proxy & Reflect
微服务 - 如何解决链路追踪问题
二叉树的常见算法总结
程序员自省清单
不能再被问住了!ReentrantLock 源码、画图一起看一看!
深入了解JS数组的常用方法
Clean架构能够解决哪些问题? - jbogard
架构文章搜集
按指定基准对齐的分组运算
通用的底层埋点都是怎么做的?
Asp.Net Core学习笔记:入门篇
Cocos Creator 源码解读:引擎启动与主循环