当前位置:网站首页>Anomaly detection method based on SVM
Anomaly detection method based on SVM
2020-11-06 01:14:00 【Artificial intelligence meets pioneer】
author |Mahbubul Alam compile |VK source |Towards Data Science

Introduction to single class support vector machines
As an expert or novice in machine learning , You may have heard of support vector machines (SVM)—— A supervised machine learning algorithm often cited and used in classification problems .
Support vector machines use hyperplanes in multidimensional space to separate one class of observations from another . Of course , Support vector machine is used to solve multi class classification problems .
However , Support vector machine is more and more applied to a class of problems , That is, all data belongs to one class . under these circumstances , Algorithms are trained to learn what is “ natural ”, So when a new data is displayed , The algorithm can identify whether it should be normal . without , New data will be marked as exception or exception . To learn more about single class support vector machines , Please check out Roemer Vlasveld This long article of :http://rvlasveld.github.io/blog/2013/07/12/introduction-to-one-class-support-vector-machines/
The last thing to mention is , If you are familiar with sklearn library , You'll notice that there's an algorithm for what's called “ Novelty testing ” And Design . It works in a similar way to what I described in the anomaly detection using single class support vector machines . in my opinion , It's just the context that determines whether it's called novelty detection or outlier detection or whatever .
Here is Python Simple demonstration of single class support vector machine in programming language . Please note that , I alternate between outliers and outliers .
step 1: Import library
For this demonstration , We need three core libraries - For data disputes python and numpy, For model building sklearn And Visualization matlotlib.
# Import library
import pandas as pd
from sklearn.svm import OneClassSVM
import matplotlib.pyplot as plt
from numpy import where
step 2: Prepare the data
I use the famous... From online resources Iris Data sets , So you can practice using , You don't have to worry about how to get the data from where .
# Import data
data = pd.read_csv("https://raw.githubusercontent.com/uiuc-cse/data-fa14/gh-pages/data/iris.csv")
# input data
df = data[["sepal_length", "sepal_width"]]
step 3: Model
It is different from the adjustment of super parameters in other classification algorithms , Single class support vector machines use nu As a super parameter , Used to define which parts of the data should be classified as outliers .nu=0.03 Indicates that the algorithm will 3% Is specified as an outlier .
# Model parameters
model = OneClassSVM(kernel = 'rbf', gamma = 0.001, nu = 0.03).fit(df)
step 4: forecast
The predicted dataset will have 1 or -1 value , among -1 Value is the outlier detected by the algorithm .
# forecast
y_pred = model.predict(df)
y_pred

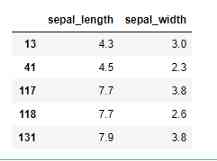
step 5: Filter exception
# Filter outlier index
outlier_index = where(y_pred == -1)
# Filter outliers
outlier_values = df.iloc[outlier_index]
outlier_values
step 6: Visual exception
# Visual output
plt.scatter(data["sepal_length"], df["sepal_width"])
plt.scatter(outlier_values["sepal_length"], outlier_values["sepal_width"], c = "r")

Red data points are outliers
summary
In this paper , I'd like to talk about a class of support vector machines (One-classsvm) Make a brief introduction , It's a form of fraud / abnormal / Machine learning algorithm for anomaly detection .
I showed you some simple steps to build intuition , But of course , A real implementation requires more experimentation to find out what works in a particular environment and Industry , What doesn't work .
Link to the original text :https://towardsdatascience.com/support-vector-machine-svm-for-anomaly-detection-73a8d676c331
Welcome to join us AI Blog station : http://panchuang.net/
sklearn Machine learning Chinese official documents : http://sklearn123.com/
Welcome to pay attention to pan Chuang blog resource summary station : http://docs.panchuang.net/
版权声明
本文为[Artificial intelligence meets pioneer]所创,转载请带上原文链接,感谢
边栏推荐
猜你喜欢

Existence judgment in structured data
DRF JWT authentication module and self customization

Kitty中的动态线程池支持Nacos,Apollo多配置中心了

熬夜总结了报表自动化、数据可视化和挖掘的要点,和你想的不一样

GBDT与xgb区别,以及梯度下降法和牛顿法的数学推导
TensorFlow2.0 问世,Pytorch还能否撼动老大哥地位?
Grouping operation aligned with specified datum
How do the general bottom buried points do?
连肝三个通宵,JVM77道高频面试题详细分析,就这?

Computer TCP / IP interview 10 even asked, how many can you withstand?
随机推荐
面经手册 · 第12篇《面试官,ThreadLocal 你要这么问,我就挂了!》
技術總監,送給剛畢業的程式設計師們一句話——做好小事,才能成就大事
小白量化投资交易入门课(python入门金融分析)
Programmer introspection checklist
制造和新的自动化技术是什么?
xmppmini 專案詳解:一步一步從原理跟我學實用 xmpp 技術開發 4.字串解碼祕笈與訊息包
In depth understanding of the construction of Intelligent Recommendation System
Flink on paasta: yelp's new stream processing platform running on kubernetes
X Window System介紹
Working principle of gradient descent algorithm in machine learning
Pycharm快捷键 自定义功能形式
Existence judgment in structured data
深度揭祕垃圾回收底層,這次讓你徹底弄懂她
WeihanLi.Npoi 1.11.0/1.12.0 Release Notes
ipfs正舵者Filecoin落地正当时 FIL币价格破千来了
WeihanLi.Npoi 1.11.0/1.12.0 Release Notes
Azure Data Factory(三)整合 Azure Devops 實現CI/CD
Kitty中的动态线程池支持Nacos,Apollo多配置中心了
DRF JWT authentication module and self customization
业内首发车道级导航背后——详解高精定位技术演进与场景应用