当前位置:网站首页>使用 Iceberg on Kubernetes 打造新一代云原生数据湖
使用 Iceberg on Kubernetes 打造新一代云原生数据湖
2020-11-06 20:17:00 【腾讯云原生】
背景
大数据发展至今,按照 Google 2003年发布的《The Google File System》第一篇论文算起,已走过17个年头。可惜的是 Google 当时并没有开源其技术,“仅仅”是发表了三篇技术论文。所以回头看,只能算是揭开了大数据时代的帷幕。随着 Hadoop 的诞生,大数据进入了高速发展的时代,大数据的红利及商业价值也不断被释放。现今大数据存储和处理需求越来越多样化,在后 Hadoop 时代,如何构建一个统一的数据湖存储,并在其上进行多种形式的数据分析,成了企业构建大数据生态的一个重要方向。怎样快速、一致、原子性地在数据湖存储上构建起 Data Pipeline,成了亟待解决的问题。并且伴随云原生时代到来,云原生天生具有的自动化部署和交付能力也正催化这一过程。本文就主要介绍如何利用 Iceberg 与 Kubernetes 打造新一代云原生数据湖。
何为 Iceberg
Apache Iceberg is an open table format for huge analytic datasets. Iceberg adds tables to Presto and Spark that use a high-performance format that works just like a SQL table.
Apache Iceberg 是由 Netflix 开发开源的,其于2018年11月16日进入 Apache 孵化器,是 Netflix 公司数据仓库基础。Iceberg 本质上是一种专为海量分析设计的表格式标准,可为主流计算引擎如 Presto、Spark 等提供高性能的读写和元数据管理能力。Iceberg 不关注底层存储(如 HDFS)与表结构(业务定义),它为两者之间提供了一个抽象层,将数据与元数据组织了起来。
Iceberg 主要特性包括:
- ACID:具备 ACID 能力,支持 row level update/delete;支持 serializable isolation 与 multiple concurrent writers
- Table Evolution:支持 inplace table evolution(schema & partition),可像 SQL 一样操作 table schema;支持 hidden partitioning,用户无需显示指定
- 接口通用化:为上层数据处理引擎提供丰富的表操作接口;屏蔽底层数据存储格式差异,提供对 Parquet、ORC 和 Avro 格式支持
依赖以上特性,Iceberg 可帮助用户低成本的实现 T+0 级数据湖。
Iceberg on Kubernetes
传统方式下,用户在部署和运维大数据平台时通常采用手动或半自动化方式,这往往消耗大量人力,稳定性也无法保证。Kubernetes 的出现,革新了这一过程。Kubernetes 提供了应用部署和运维标准化能力,用户业务在实施 Kubernetes 化改造后,可运行在其他所有标准 Kubernetes 集群中。在大数据领域,这种能力可帮助用户快速部署和交付大数据平台(大数据组件部署尤为复杂)。尤其在大数据计算存储分离的架构中,Kubernetes 集群提供的 Serverless 能力,可帮助用户即拿即用的运行计算任务。并且再配合离在线混部方案,除了可做到资源统一管控降低复杂度和风险外,集群利用率也会进一步提升,大幅降低成本。
我们可基于 Kubernetes 构建 Hadoop 大数据平台: 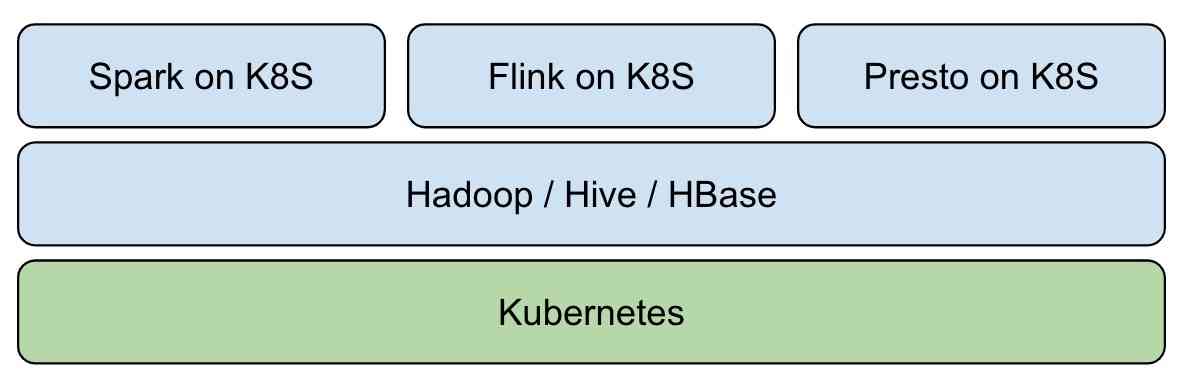 在近几年大热的数据湖领域,通过传统 Hadoop 生态构建实时数据湖,受制于组件定位与设计,较为复杂与困难。Iceberg 的出现使得依赖开源技术快速构建实时数据湖成为可能,这也是大数据未来发展方向 - 实时分析、仓湖一体与云原生。引入 Iceberg 后,整体架构变为:
在近几年大热的数据湖领域,通过传统 Hadoop 生态构建实时数据湖,受制于组件定位与设计,较为复杂与困难。Iceberg 的出现使得依赖开源技术快速构建实时数据湖成为可能,这也是大数据未来发展方向 - 实时分析、仓湖一体与云原生。引入 Iceberg 后,整体架构变为: 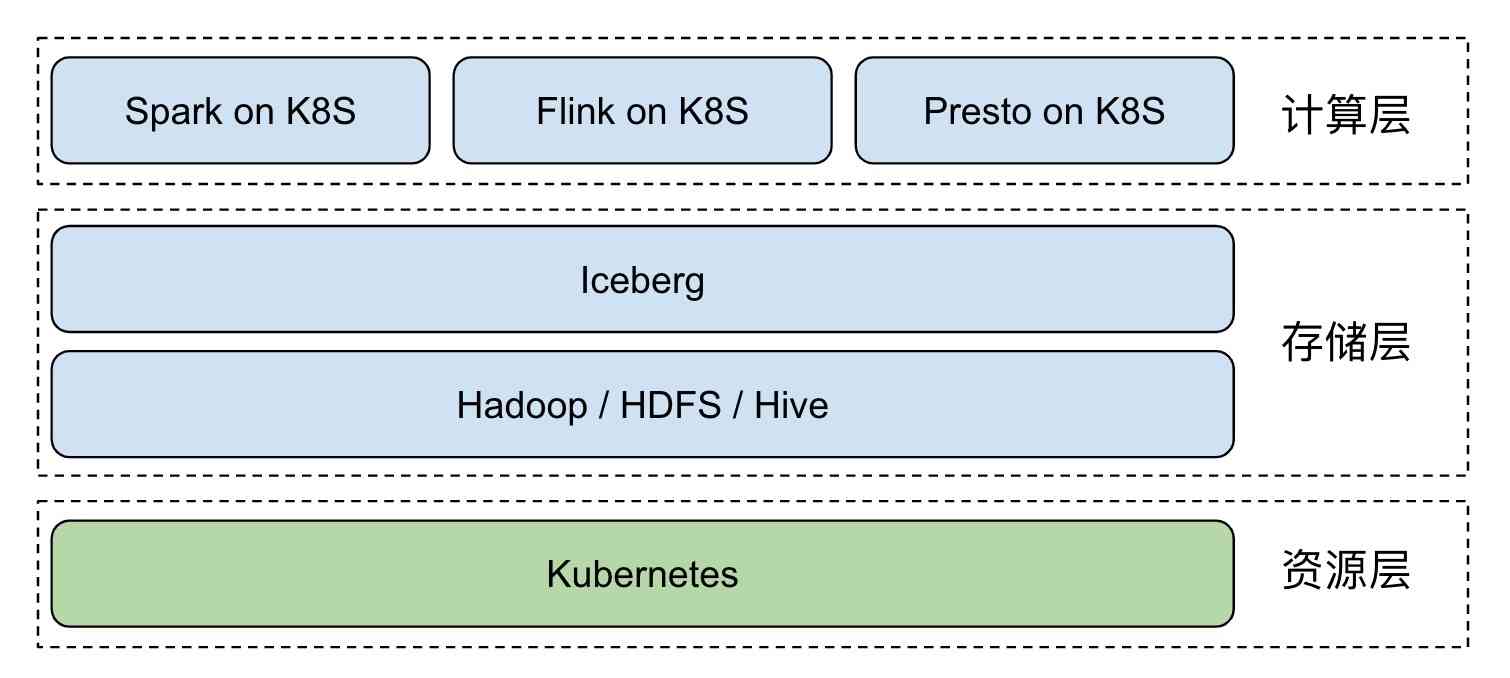 Kubernetes 负责应用自动化部署与资源管理调度,为上层屏蔽了底层环境复杂性。Iceberg + Hive MetaStore + HDFS 实现了基于 Hadoop 生态的实时数据湖,为大数据应用提供数据访问及存储。Spark、Flink 等计算引擎以 native 的方式运行在 Kubernetes 集群中,资源即拿即用。与在线业务混部后,更能大幅提升集群资源利用率。
Kubernetes 负责应用自动化部署与资源管理调度,为上层屏蔽了底层环境复杂性。Iceberg + Hive MetaStore + HDFS 实现了基于 Hadoop 生态的实时数据湖,为大数据应用提供数据访问及存储。Spark、Flink 等计算引擎以 native 的方式运行在 Kubernetes 集群中,资源即拿即用。与在线业务混部后,更能大幅提升集群资源利用率。
如何构建云原生实时数据湖
架构图
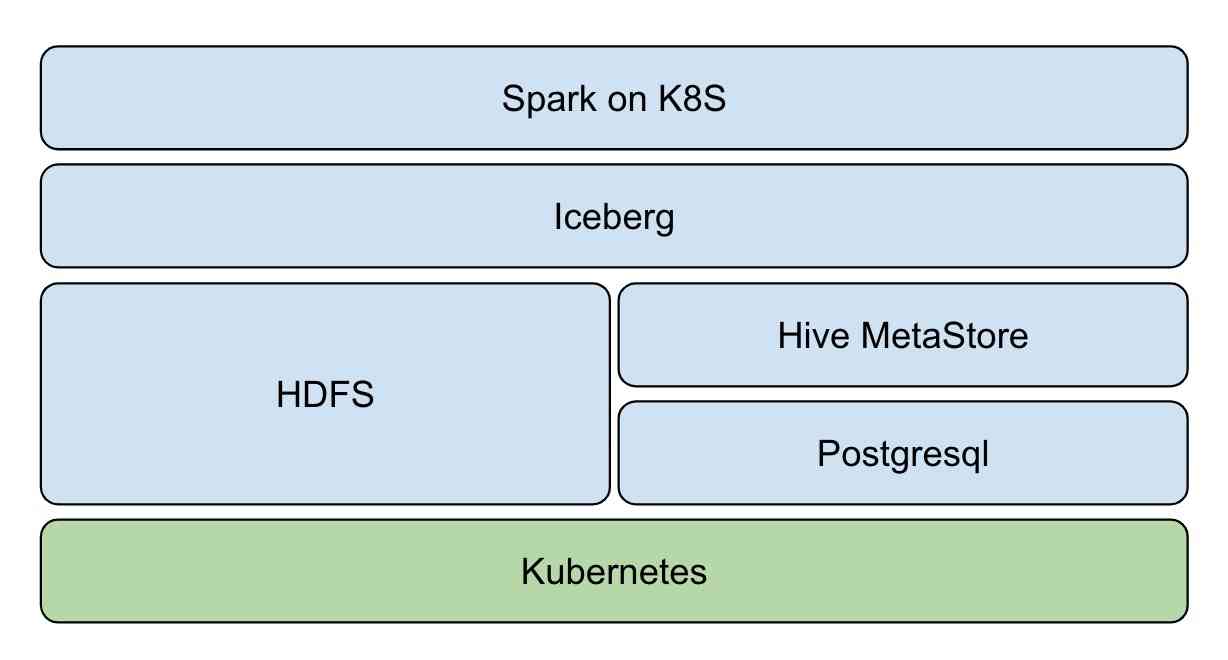
- 资源层:Kubernetes 提供资源管控能力
- 数据层:Iceberg 提供 ACID、table 等数据集访问操作能力
- 存储层:HDFS 提供数据存储能力,Hive MetaStore 管理 Iceberg 表元数据,Postgresql 作为 Hive MetaStore 存储后端
- 计算层:Spark native on Kubernetes,提供流批计算能力
创建 Kubernetes 集群
首先通过官方二进制或自动化部署工具部署 Kubernetes 集群,如 kubeadm,推荐使用腾讯云创建 TKE 集群。  推荐配置为:3 台 S2.2XLARGE16(8核16G)实例
推荐配置为:3 台 S2.2XLARGE16(8核16G)实例
部署 Hadoop 集群
可通过开源 Helm 插件或自定义镜像在 Kubernetes 上部署 Hadoop 集群,主要部署 HDFS、Hive MetaStore 组件。在腾讯云 TKE 中推荐使用 k8s-big-data-suite 大数据应用自动化部署 Hadoop 集群。 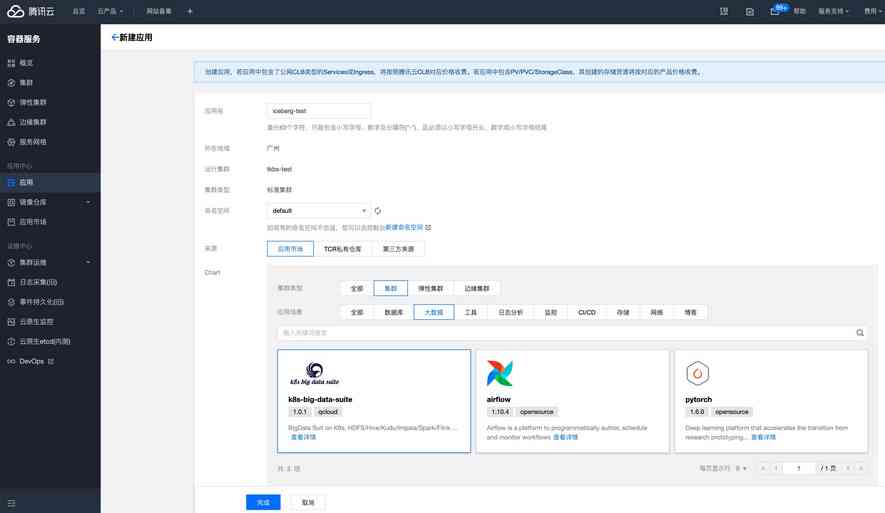 k8s-big-data-suite 是我们基于生产经验开发的大数据套件,可支持主流的大数据组件在 Kubernetes 上一键部署。部署之前请先按照要求做集群初始化:
k8s-big-data-suite 是我们基于生产经验开发的大数据套件,可支持主流的大数据组件在 Kubernetes 上一键部署。部署之前请先按照要求做集群初始化:
# 标识存储节点,至少三个
$ kubectl label node xxx storage=true
部署成功后,连入 TKE 集群查看组件状态:
$ kubectl get po
NAME READY STATUS RESTARTS AGE
alertmanager-tkbs-prometheus-operator-alertmanager-0 2/2 Running 0 6d23h
cert-job-kv5tm 0/1 Completed 0 6d23h
elasticsearch-master-0 1/1 Running 0 6d23h
elasticsearch-master-1 1/1 Running 0 6d23h
flink-operator-controller-manager-9485b8f4c-75zvb 2/2 Running 0 6d23h
kudu-master-0 2/2 Running 2034 6d23h
kudu-master-1 2/2 Running 0 6d23h
kudu-master-2 2/2 Running 0 6d23h
kudu-tserver-0 1/1 Running 0 6d23h
kudu-tserver-1 1/1 Running 0 6d23h
kudu-tserver-2 1/1 Running 0 6d23h
prometheus-tkbs-prometheus-operator-prometheus-0 3/3 Running 0 6d23h
superset-init-db-g6nz2 0/1 Completed 0 6d23h
thrift-jdbcodbc-server-1603699044755-exec-1 1/1 Running 0 6d23h
tkbs-admission-5559c4cddf-w7wtf 1/1 Running 0 6d23h
tkbs-admission-init-x8sqd 0/1 Completed 0 6d23h
tkbs-airflow-scheduler-5d44f5bf66-5hd8k 1/1 Running 2 6d23h
tkbs-airflow-web-84579bc4cd-6dftv 1/1 Running 2 6d23h
tkbs-client-844559f5d7-r86rb 1/1 Running 6 6d23h
tkbs-controllers-6b9b95d768-vr7t5 1/1 Running 0 6d23h
tkbs-cp-kafka-0 3/3 Running 2 6d23h
tkbs-cp-kafka-1 3/3 Running 2 6d23h
tkbs-cp-kafka-2 3/3 Running 2 6d23h
tkbs-cp-kafka-connect-657bdff584-g9f2r 2/2 Running 2 6d23h
tkbs-cp-schema-registry-84cd7cbdbc-d28jk 2/2 Running 4 6d23h
tkbs-grafana-68586d8f97-zbc2m 2/2 Running 0 6d23h
tkbs-hadoop-hdfs-dn-6jng4 2/2 Running 0 6d23h
tkbs-hadoop-hdfs-dn-rn8z9 2/2 Running 0 6d23h
tkbs-hadoop-hdfs-dn-t68zq 2/2 Running 0 6d23h
tkbs-hadoop-hdfs-jn-0 2/2 Running 0 6d23h
tkbs-hadoop-hdfs-jn-1 2/2 Running 0 6d23h
tkbs-hadoop-hdfs-jn-2 2/2 Running 0 6d23h
tkbs-hadoop-hdfs-nn-0 2/2 Running 5 6d23h
tkbs-hadoop-hdfs-nn-1 2/2 Running 0 6d23h
tkbs-hbase-master-0 1/1 Running 3 6d23h
tkbs-hbase-master-1 1/1 Running 0 6d23h
tkbs-hbase-rs-0 1/1 Running 3 6d23h
tkbs-hbase-rs-1 1/1 Running 0 6d23h
tkbs-hbase-rs-2 1/1 Running 0 6d23h
tkbs-hive-metastore-0 2/2 Running 0 6d23h
tkbs-hive-metastore-1 2/2 Running 0 6d23h
tkbs-hive-server-8649cb7446-jq426 2/2 Running 1 6d23h
tkbs-impala-catalogd-6f46fd97c6-b6j7b 1/1 Running 0 6d23h
tkbs-impala-coord-exec-0 1/1 Running 7 6d23h
tkbs-impala-coord-exec-1 1/1 Running 7 6d23h
tkbs-impala-coord-exec-2 1/1 Running 7 6d23h
tkbs-impala-shell-844796695-fgsjt 1/1 Running 0 6d23h
tkbs-impala-statestored-798d44765f-ffp82 1/1 Running 0 6d23h
tkbs-kibana-7994978d8f-5fbcx 1/1 Running 0 6d23h
tkbs-kube-state-metrics-57ff4b79cb-lmsxp 1/1 Running 0 6d23h
tkbs-loki-0 1/1 Running 0 6d23h
tkbs-mist-d88b8bc67-s8pxx 1/1 Running 0 6d23h
tkbs-nginx-ingress-controller-87b7fb9bb-mpgtj 1/1 Running 0 6d23h
tkbs-nginx-ingress-default-backend-6857b58896-rgc5c 1/1 Running 0 6d23h
tkbs-nginx-proxy-64964c4c79-7xqx6 1/1 Running 6 6d23h
tkbs-postgresql-5b9ddc464c-xc5nn 1/1 Running 1 6d23h
tkbs-postgresql-ha-pgpool-5cbf85d847-v5dsr 1/1 Running 1 6d23h
tkbs-postgresql-ha-postgresql-0 2/2 Running 0 6d23h
tkbs-postgresql-ha-postgresql-1 2/2 Running 0 6d23h
tkbs-prometheus-node-exporter-bdp9v 1/1 Running 0 6d23h
tkbs-prometheus-node-exporter-cdrqr 1/1 Running 0 6d23h
tkbs-prometheus-node-exporter-cv767 1/1 Running 0 6d23h
tkbs-prometheus-node-exporter-l82wp 1/1 Running 0 6d23h
tkbs-prometheus-node-exporter-nb4pk 1/1 Running 0 6d23h
tkbs-prometheus-operator-operator-f74dd4f6f-lnscv 2/2 Running 0 6d23h
tkbs-promtail-d6r9r 1/1 Running 0 6d23h
tkbs-promtail-gd5nz 1/1 Running 0 6d23h
tkbs-promtail-l9kjw 1/1 Running 0 6d23h
tkbs-promtail-llwvh 1/1 Running 0 6d23h
tkbs-promtail-prgt9 1/1 Running 0 6d23h
tkbs-scheduler-74f5777c5d-hr88l 1/1 Running 0 6d23h
tkbs-spark-history-7d78cf8b56-82xg7 1/1 Running 4 6d23h
tkbs-spark-thirftserver-5757f9588d-gdnzz 1/1 Running 4 6d23h
tkbs-sparkoperator-f9fc5b8bf-8s4m2 1/1 Running 0 6d23h
tkbs-sparkoperator-f9fc5b8bf-m9pjk 1/1 Running 0 6d23h
tkbs-sparkoperator-webhook-init-m6fn5 0/1 Completed 0 6d23h
tkbs-superset-54d587c867-b99kw 1/1 Running 0 6d23h
tkbs-zeppelin-controller-65c454cfb9-m4snp 1/1 Running 0 6d23h
tkbs-zookeeper-0 3/3 Running 0 6d23h
tkbs-zookeeper-1 3/3 Running 0 6d23h
tkbs-zookeeper-2 3/3 Running 0 6d23h
注意
当前 TKE k8s-big-data-suite 1.0.3 在初始化 Postgresql 时,缺少对 Hive transaction 的支持,从而导致 Iceberg 表创建失败。请先执行以下命令手动修复:
$ kubectl get pod | grep postgresql
tkbs-postgresql-5b9ddc464c-xc5nn 1/1 Running 1 7d18h
$ kubectl exec tkbs-postgresql-5b9ddc464c-xc5nn -- psql -c "UPDATE pg_database SET datallowconn = 'false' WHERE datname = 'metastore';SELECT pg_terminate_backend(pid) FROM pg_stat_activity WHERE datname = 'metastore'"; kubectl exec tkbs-postgresql-5b9ddc464c-xc5nn -- psql -c "drop database metastore"; kubectl exec tkbs-postgresql-5b9ddc464c-xc5nn -- psql -c "create database metastore"
$ kubectl get pod | grep client
tkbs-client-844559f5d7-r86rb 1/1 Running 7 7d18h
$ kubectl exec tkbs-client-844559f5d7-r86rb -- schematool -dbType postgres -initSchema
集成 Iceberg
当前 Iceberg 对 Spark 3.0 有较好支持,对比 Spark 2.4 有以下优势: 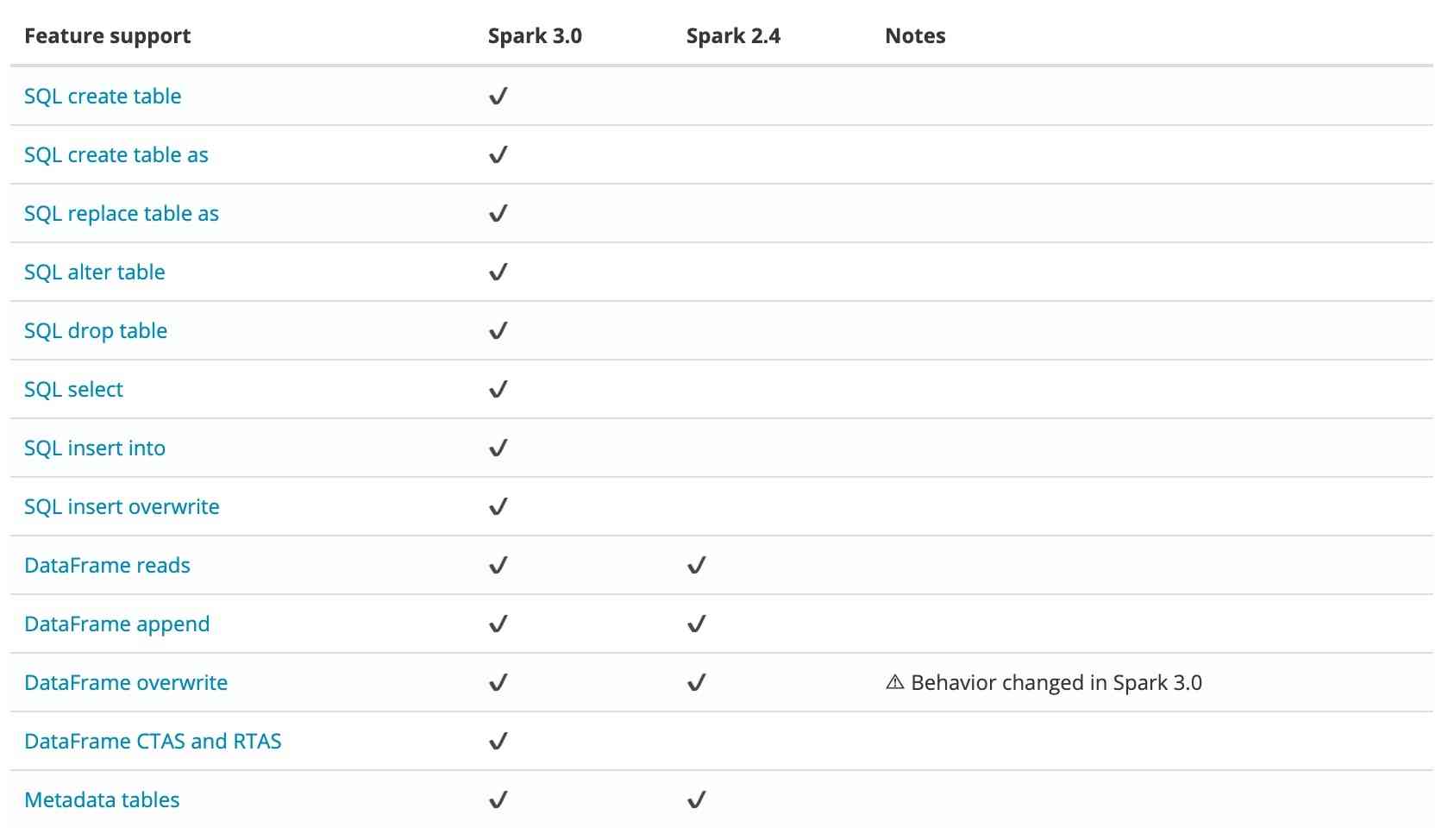 所以我们默认采用 Spark 3.0 作为计算引擎。Spark 集成 Iceberg,首先需引入 Iceberg jar 依赖。用户可在提交任务阶段手动指定,或将 jar 包直接引入 Spark 安装目录。为了便于使用,我们选择后者。笔者已打包 Spark 3.0.1 的镜像,供用户测试使用:ccr.ccs.tencentyun.com/timxbxu/spark:v3.0.1。
所以我们默认采用 Spark 3.0 作为计算引擎。Spark 集成 Iceberg,首先需引入 Iceberg jar 依赖。用户可在提交任务阶段手动指定,或将 jar 包直接引入 Spark 安装目录。为了便于使用,我们选择后者。笔者已打包 Spark 3.0.1 的镜像,供用户测试使用:ccr.ccs.tencentyun.com/timxbxu/spark:v3.0.1。
我们使用 Hive MetaStore 管理 Iceberg 表信息,通过 Spark Catalog 访问和使用 Iceberg 表。在 Spark 中做如下配置:
spark.sql.catalog.hive_prod = org.apache.iceberg.spark.SparkCatalog
spark.sql.catalog.hive_prod.type = hive
spark.sql.catalog.hive_prod.uri = thrift://metastore-host:port
若使用 TKE k8s-big-data-suite 套件部署 Hadoop 集群,可通过 Hive Service 访问 Hive MetaStore:
$ kubectl get svc | grep hive-metastore
tkbs-hive-metastore ClusterIP 172.22.255.104 <none> 9083/TCP,8008/TCP 6d23h
Spark 配置变更为:
spark.sql.catalog.hive_prod = org.apache.iceberg.spark.SparkCatalog
spark.sql.catalog.hive_prod.type = hive
spark.sql.catalog.hive_prod.uri = thrift://tkbs-hive-metastore
创建和使用 Iceberg 表
执行 spark-sql 进行验证:
$ spark-sql --master k8s://{k8s-apiserver} --conf spark.kubernetes.container.image=ccr.ccs.tencentyun.com/timxbxu/spark:v3.0.1 --conf spark.sql.catalog.hive_prod=org.apache.iceberg.spaparkCatalog --conf spark.sql.catalog.hive_prod.type=hive --conf spark.sql.catalog.hive_prod.uri=thrift://tkbs-hive-metastore --conf spark.sql.warehouse.dir=hdfs://tkbs-hadoop-hdfs-nn/iceberg
各参数含义如下:
- --master k8s://{k8s-apiserver}:Kubernetes 集群地址
- --conf spark.kubernetes.container.image=ccr.ccs.tencentyun.com/timxbxu/spark:v3.0.1:Spark Iceberg 镜像
- --conf spark.sql.catalog.hive_prod.type=hive:Spark Catalog 类型
- --conf spark.sql.catalog.hive_prod.uri=thrift://tkbs-hive-metastore:Hive MetaStore 地址
- --conf spark.sql.warehouse.dir=hdfs://tkbs-hadoop-hdfs-nn/iceberg:Spark 数据地址
创建 Iceberg 表:
spark-sql> CREATE TABLE hive_prod.db.table (id bigint, data string) USING iceberg;
查看是否创建成功:
spark-sql> desc hive_prod.db.table;
20/11/02 20:43:43 INFO BaseMetastoreTableOperations: Refreshing table metadata from new version: hdfs://10.0.1.129/iceberg/db.db/table/metadata/00000-1306e87a-16cb-4a6b-8ca0-0e1846cf1837.metadata.json
20/11/02 20:43:43 INFO CodeGenerator: Code generated in 21.35536 ms
20/11/02 20:43:43 INFO CodeGenerator: Code generated in 13.058698 ms
id bigint
data string
# Partitioning
Not partitioned
Time taken: 0.537 seconds, Fetched 5 row(s)
20/11/02 20:43:43 INFO SparkSQLCLIDriver: Time taken: 0.537 seconds, Fetched 5 row(s)
查看 HDFS 是否存在表信息:
$ hdfs dfs -ls /iceberg/db.db
Found 5 items
drwxr-xr-x - root supergroup 0 2020-11-02 16:37 /iceberg/db.db/table
查看 Postgresql 是否存在表元数据信息:
$ kubectl get pod | grep postgresql
tkbs-postgresql-5b9ddc464c-xc5nn 1/1 Running 1 7d19h$ kubectl exec tkbs-postgresql-5b9ddc464c-xc5nn -- psql -d metastore -c 'select * from "TBLS"'
向 Iceberg 表插入数据:
spark-sql> INSERT INTO hive_prod.db.table VALUES (1, 'a'), (2, 'b');
查看是否插入成功:
spark-sql> select * from hive_prod.db.table;
...
1 a
2 b
Time taken: 0.854 seconds, Fetched 2 row(s)
20/11/02 20:49:43 INFO SparkSQLCLIDriver: Time taken: 0.854 seconds, Fetched 2 row(s)
查看 Kubernetes 集群 Spark 任务运行状态:
$ kubectl get pod | grep spark
sparksql10-0-1-64-ed8e6f758900de0c-exec-1 1/1 Running 0 86s
sparksql10-0-1-64-ed8e6f758900de0c-exec-2 1/1 Running 0 85s
Iceberg Spark 支持的更多操作可见:https://iceberg.apache.org/spark/
通过以上步骤,我们即可在 Kubernetes 上快速部署生产可用的实时数据湖平台。
总结
在这个数据量爆炸的时代,传统数仓已较难很好满足数据多样性需求。数据湖凭借开放、低成本等优势,逐渐居于主导地位。并且用户和业务也不再满足于滞后的分析结果,对数据实时性提成了更多要求。以 Iceberg、Hudi、Delta Lake 为代表的开源数据湖技术,填补了这部分市场空白,为用户提供了快速搭建适用于实时 OLAP 的数据湖平台能力。另外云原生时代的到来,更是大大加速了这一过程。大数据毋庸置疑正朝着实时分析、计算存储分离、云原生,乃至于湖仓一体的方向发展。大数据基础设施也正因为 Kubernetes、容器等云原生技术的引入,正发生巨大变革。未来大数据会更好的“长于云上”,Bigdata as a Service 的时代,相信很快会到来。
参考材料
- https://iceberg.apache.org/
- https://github.com/apache/iceberg
- https://cloud.tencent.com/product/tke
- https://github.com/tkestack/charts/tree/main/incubator/k8s-big-data-suite
- 基于Apache Iceberg打造T+0实时数仓
【腾讯云原生】云说新品、云研新术、云游新活、云赏资讯,扫码关注同名公众号,及时获取更多干货!!

版权声明
本文为[腾讯云原生]所创,转载请带上原文链接,感谢
https://my.oschina.net/u/4534936/blog/4706809
边栏推荐
猜你喜欢

How to demote a domain controller in Windows Server 2012 and later

Anomaly detection method based on SVM
用Python构建和可视化决策树
Cos start source code and creator
业内首发车道级导航背后——详解高精定位技术演进与场景应用
Elasticsearch database | elasticsearch-7.5.0 application construction

分布式ID生成服务,真的有必要搞一个
DTU连接经常遇到的问题有哪些
Want to do read-write separation, give you some small experience
你的财务报告该换个高级的套路了——财务分析驾驶舱
随机推荐
分布式ID生成服务,真的有必要搞一个
Dapr實現分散式有狀態服務的細節
怎么理解Python迭代器与生成器?
Cocos Creator 原始碼解讀:引擎啟動與主迴圈
3分钟读懂Wi-Fi 6于Wi-Fi 5的优势
基于深度学习的推荐系统
容联完成1.25亿美元F轮融资
【效能優化】納尼?記憶體又溢位了?!是時候總結一波了!!
[C#] (原創)一步一步教你自定義控制元件——04,ProgressBar(進度條)
中国提出的AI方法影响越来越大,天大等从大量文献中挖掘AI发展规律
小白量化投资交易入门课(python入门金融分析)
C++和C++程序员快要被市场淘汰了
网络安全工程师演示:原来***是这样获取你的计算机管理员权限的!【维持】
C language 100 question set 004 - statistics of the number of people of all ages
7.3.1 file upload and zero XML registration interceptor
6.8 multipartresolver file upload parser (in-depth analysis of SSM and project practice)
Anomaly detection method based on SVM
DRF JWT authentication module and self customization
python 下载模块加速实现记录
vite + ts 快速搭建 vue3 專案 以及介紹相關特性