当前位置:网站首页>哇,ElasticSearch多字段权重排序居然可以这么玩
哇,ElasticSearch多字段权重排序居然可以这么玩
2020-11-06 01:28:00 【尹吉欢】
背景
读者提问:ES 的权重排序有没有示列,参考参考?
刚好之前也稍微接触过,于是写了这篇文章,可以简单参考下。
在很多复杂的业务场景下,排序的规则会比较复杂,单一的降序,升序无法满足日常需求。不过 ES 中提供了给文档加权重的方式来排序,还是挺好用的。
首先初始化三条测试数据,方便查看效果:
{id: 1,title: "Java怎么学",type: 3,userId: 1,tags: ["java"],textContent: "我要学Java",status: 1,heat: 80}{id: 2,title: "Java怎么学",type: 2,userId: 1,tags: ["java"],textContent: "我要学Java",status: 1,heat: 99}{id: 3,title: "Java怎么学",type: 1,userId: 1,tags: ["java"],textContent: "我要学Java",status: 1,heat: 100}
type:1 为翻译,2 为转载,3 为原创
需求是查询 userId=1 的所有文章,按照热度降序排序,但是原创类型的文章要显示在前面,优先级高于热度。
如果我们简单的按照热度排序的话,那么顺序肯定是 id 为 3(热度:100),2(热度:99),1(热度:80)这样排列的。
但是原创类型的要在前面,那么结果应该是 1(热度:80,类型:原创),3(热度:100,类型:翻译),2(热度:99,类型:转载)。
排序条件肯定是以热度来进行的,这个是肯定的。唯一需要处理的就是怎么将原创类型的排在前面,如果只考虑实现,方式还是有很多种的。
比如:原创类型的热度值可以调的比较高,但是呢,热度值要重新弄一个字段,只用于排序,给用户展示的还是之前的热度值,这样排序就简单了,还是根据热度排就可以实现效果。
weightFactorFunction
在 ES 搜索结果中_score 这个字段相信大家并不陌生,这是 ES 给出的评分,我们可以根据评分来排序,然后将原创类型的评分提高就可以实现想要的效果。
直接看 Java 代码吧,通过 FunctionScoreQueryBuilder 来构建查询。
@Testpublic void testSort() {FunctionScoreQueryBuilder.FilterFunctionBuilder[] filterFunctionBuilders = new FunctionScoreQueryBuilder.FilterFunctionBuilder[]{new FunctionScoreQueryBuilder.FilterFunctionBuilder(QueryBuilders.termQuery("type", 3), ScoreFunctionBuilders.weightFactorFunction(100)),new FunctionScoreQueryBuilder.FilterFunctionBuilder(QueryBuilders.termQuery("type", 2), ScoreFunctionBuilders.weightFactorFunction(1)),new FunctionScoreQueryBuilder.FilterFunctionBuilder(QueryBuilders.matchQuery("type", 1), ScoreFunctionBuilders.weightFactorFunction(1))};SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();boolQuery.must(QueryBuilders.termQuery("userId", 1));FunctionScoreQueryBuilder functionScoreQueryBuilder = QueryBuilders.functionScoreQuery(boolQuery, filterFunctionBuilders);searchSourceBuilder.query(functionScoreQueryBuilder).sort("_score", SortOrder.DESC).sort("heat", SortOrder.DESC);SearchRequest searchRequest = new SearchRequest(elasticSearchIndexConfig.getArticleSearchIndexName());searchRequest.types(EsConstant.DEFAULT_TYPE);searchRequest.source(searchSourceBuilder);List<ArticleDocument> searchResults = kittyRestHighLevelClient.search(searchRequest, ArticleDocument.class);searchResults.forEach(doc -> {System.out.println(doc.getId() + "\t" + doc.getType() + "\t" + doc.getHeat());});}
通过 ScoreFunctionBuilders.weightFactorFunction 为文章类型设置对应的权重,原创文章权重为 100,其他的都为 1,这样原创文章的得分就高于其他类型的文章。
在排序的时候优先得分排序,然后热度排序。就可以得到我们想要的结果了。
scriptFunction
除了使用 weightFactorFunction 来设置权重,另外介绍一种灵活度更高,适用于更复杂的排序场景的方式 scriptFunction。
scriptFunction 允许我们通过脚本的方式来实现权重,直接看代码:
@Testpublic void testSort() {String scoreScript = "if (doc['type'].value == 3) {" +" return 100;" +"} else {" +" return 1;" +"}";FunctionScoreQueryBuilder.FilterFunctionBuilder[] filterFunctionBuilders = new FunctionScoreQueryBuilder.FilterFunctionBuilder[]{new FunctionScoreQueryBuilder.FilterFunctionBuilder(QueryBuilders.matchAllQuery(), ScoreFunctionBuilders.scriptFunction(new Script(scoreScript)))};SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();boolQuery.must(QueryBuilders.termQuery("userId", 1));FunctionScoreQueryBuilder functionScoreQueryBuilder = QueryBuilders.functionScoreQuery(boolQuery, filterFunctionBuilders);searchSourceBuilder.query(functionScoreQueryBuilder).sort("_score", SortOrder.DESC).sort("heat", SortOrder.DESC);SearchRequest searchRequest = new SearchRequest(elasticSearchIndexConfig.getArticleSearchIndexName());searchRequest.types(EsConstant.DEFAULT_TYPE);searchRequest.source(searchSourceBuilder);List<ArticleDocument> searchResults = kittyRestHighLevelClient.search(searchRequest, ArticleDocument.class);searchResults.forEach(doc -> {System.out.println(doc.getId() + "\t" + doc.getType() + "\t" + doc.getHeat());});}
scoreScript 就是控制权重的脚本,也就是一段代码(脚本默认是 groovy),是不是方便的多。
关于作者:尹吉欢,简单的技术爱好者,《Spring Cloud 微服务-全栈技术与案例解析》, 《Spring Cloud 微服务 入门 实战与进阶》作者, 公众号猿天地发起人。
我整理了一份很全的学习资料,感兴趣的可以微信搜索「猿天地」,回复关键字 「学习资料」获取我整理好了的 Spring Cloud,Spring Cloud Alibaba,Sharding-JDBC 分库分表,任务调度框架 XXL-JOB,MongoDB,爬虫等相关资料。

版权声明
本文为[尹吉欢]所创,转载请带上原文链接,感谢
http://cxytiandi.com/blog/detail/36500
边栏推荐
- Flink on PaaSTA:Yelp运行在Kubernetes上的新流处理平台
- 面经手册 · 第15篇《码农会锁,synchronized 解毒,剖析源码深度分析!》
- leetcode之赎金信
- 前端模組化簡單總結
- tensorflow之tf.tile\tf.slice等函数的基本用法解读
- 2个月再招10000人,字节跳动冲刺10万员工“小目标”
- 使用ES5实现ES6的Class
- 微信小程序:防止多次点击跳转(函数节流)
- 6.9.1 flashmapmanager initialization (flashmapmanager redirection Management) - SSM in depth analysis and project practice
- PMP考试心得
猜你喜欢
面经手册 · 第15篇《码农会锁,synchronized 解毒,剖析源码深度分析!》
面经手册 · 第12篇《面试官,ThreadLocal 你要这么问,我就挂了!》
nlp模型-bert从入门到精通(一)
梯度下降算法在机器学习中的工作原理
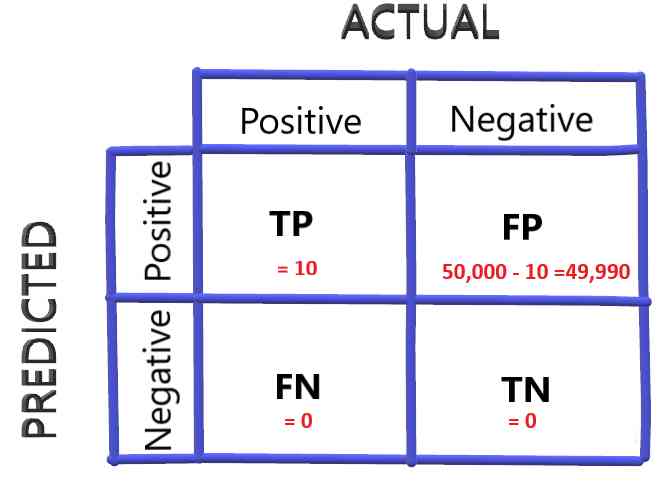
How to select the evaluation index of classification model

TF flags的简介
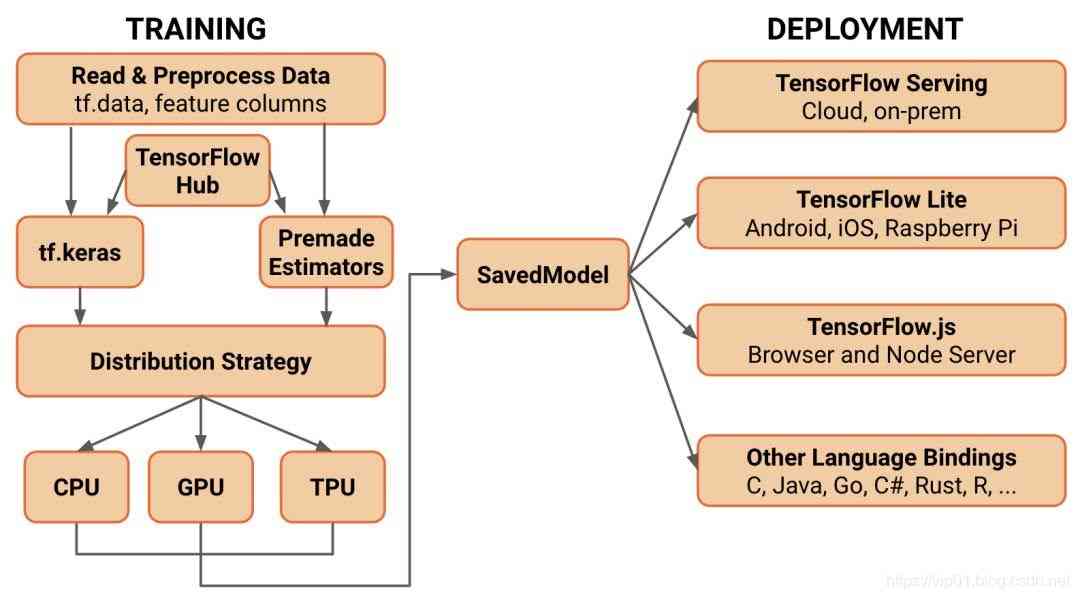
TensorFlow2.0 问世,Pytorch还能否撼动老大哥地位?

Outlier detection based on RNN self encoder
接口压力测试:Siege压测安装、使用和说明
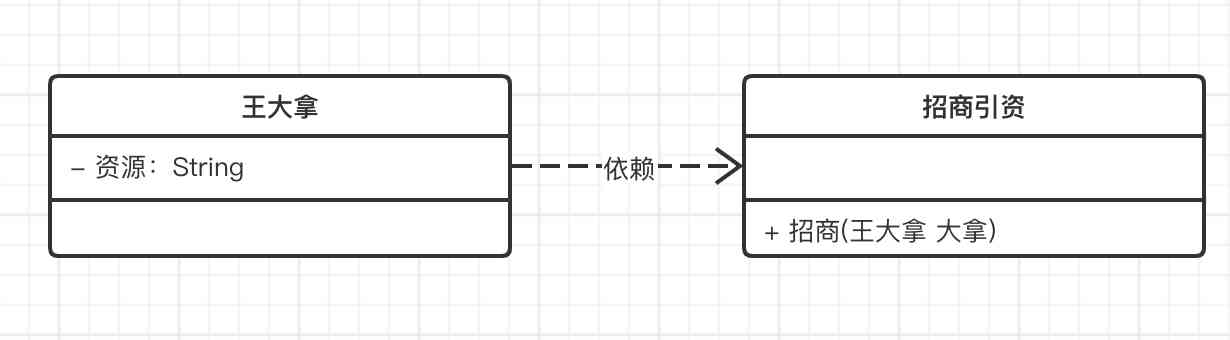
UML类图还不懂?来看看这版乡村爱情类图,一把学会!
随机推荐
十二因子原则和云原生微服务 - DZone
计算机TCP/IP面试10连问,你能顶住几道?
PMP考试心得
7.3.1 file upload and zero XML registration interceptor
OPTIMIZER_TRACE详解
APReLU:跨界应用,用于机器故障检测的自适应ReLU | IEEE TIE 2020
滴滴 Elasticsearch 集群跨版本升级与平台重构之路
Python3網路學習案例四:編寫Web Proxy
我们编写 React 组件的最佳实践
Azure Data Factory(三)整合 Azure Devops 實現CI/CD
互联网 舆情系统的架构实践
DeepWalk模型的简介与优缺点
为了省钱,我用1天时间把PHP学了!
Gradient understanding decline
免费的专利下载教程(知网、espacenet强强联合)
Outlier detection based on RNN self encoder
Vue 3 响应式基础
自然语言处理-搜索中常用的bm25
通过深层神经网络生成音乐
Big data real-time calculation of baichenghui Hangzhou station