当前位置:网站首页>Gradient understanding decline
Gradient understanding decline
2020-11-06 01:14:00 【Artificial intelligence meets pioneer】

author |PHANI8 compile |VK source |Analytics Vidhya
Introduce
In this article , We'll see what a real gradient descent is , Why it became popular , Why? AI and ML Most of the algorithms in follow this technique .
Before we start , What the gradient actually means ? That sounds strange, right !
Cauchy is 1847 The first person to propose gradient descent in
Um. , The word gradient means the increase and decrease of a property ! And falling means moving down . therefore , in general , The act of descending to a certain point and observing and continuing to descend is called gradient descent

therefore , Under normal circumstances , As shown in the figure , The slope of the top of the mountain is very high , Through constant movement , When you get to the foot of the mountain, the slope is the smallest , Or close to or equal to zero . The same applies mathematically .
Let's see how to do it
Gradient descent math
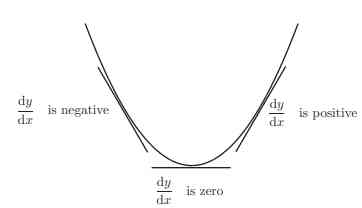
therefore , If you see the shape here is the same as the mountains here . Let's assume that this is a form of y=f(x) The curve of .
Here we know , The slope at any point is y Yes x The derivative of , If you use a curve to check , You'll find that , When you move down , The slope decreases at the tip or minimum and equals zero , When we move up again , The slope will increase
Remember that , We're going to look at the smallest point x and y What happens to the value of ,
Look at the picture below , We have five points in different positions !
.png)
When we move down , We will find that y The value will decrease , So in all the points here , We get a relatively minimum value at the bottom of the graph . therefore , Our conclusion is that we always find the minimum at the bottom of the graph (x,y). Now let's take a look at how ML and DL Pass this , And how to reach the minimum point without traversing the whole graph ?
In any algorithm , Our main purpose is to minimize the loss , This shows that our model works well . To analyze this , We're going to use linear regression
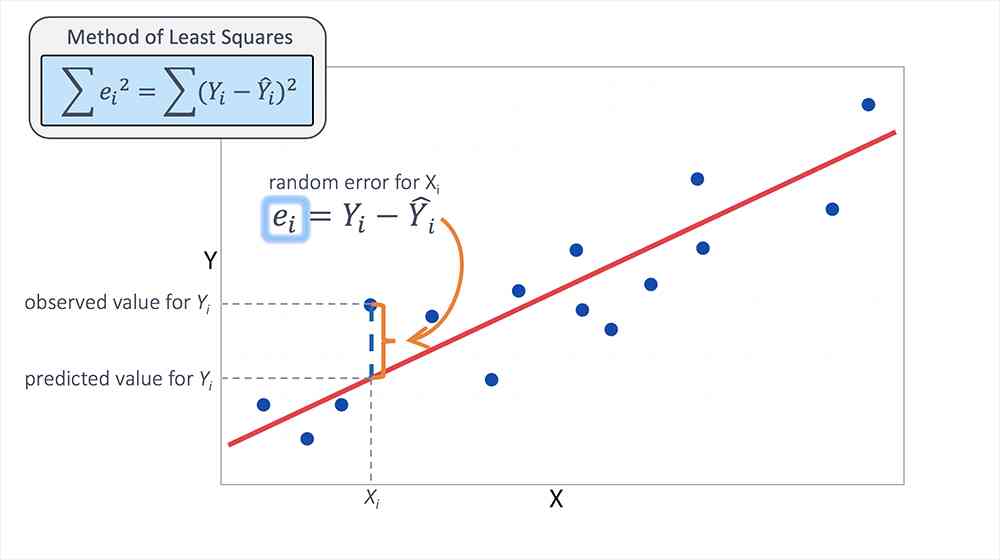
Because linear regression uses straight lines to predict continuous output -
Let's set a straight line y=w*x+c
Here we need to find w and c, In this way, we have the best fitting line to minimize the error . So our goal is to find the best w and c value
Let's start with some random values w and c, We update these values based on the loss , in other words , We update these weights , Until the slope is equal to or close to zero .
We will take y The loss function on the axis ,x There's... On the shaft w and c. Look at the picture below -
.png)
In order to achieve the minimum in the first graph w value , Please follow these steps -
-
use w and c Start calculating a given set of x _values The loss of .
-
Draw points , Now update the weight to -
w_new =w_old – learning_rate * slope at (w_old,loss)
Repeat these steps , Until the minimum value is reached !
-
We subtract the gradient here , Because we want to move to the foot of the mountain , Or moving in the steepest direction of descent
-
When we subtract , We're going to get a smaller slope than the previous one , This is where we want to move to a point where the slope is equal to or close to zero
-
We'll talk about the learning rate later
The same applies to pictures 2, Loss and c Function of
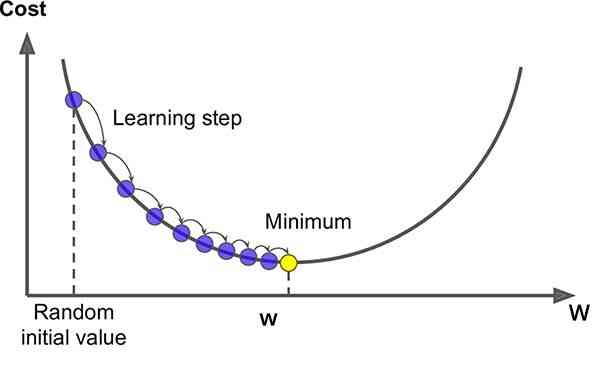
Now the question is why we put learning rate in the equation ? Because we can't traverse all the points between the starting point and the minimum
We need to skip a few points
-
We can take big steps at the beginning .
-
however , When we're close to the minimum , We need to take small steps , Because we're going to cross the minimum , Move to a slope to add . In order to control the step size and movement of the graph , The introduction of learning rate . Even if there is no learning rate , We'll also get the minimum , But what we care about is that our algorithms are faster !!
.png)
Here is an example algorithm for linear regression using gradient descent . Here we use the mean square error as the loss function -
1. Initialize model parameters with zero
m=0,c=0
2. Use (0,1) Any value in the range initializes the learning rate
lr=0.01
The error equation -
.png)
Now use (w*x+c) Instead of Ypred And calculate the partial derivative
.png)
3.c It can also be calculated that
.png)
4. Apply this to all epoch Data set of
for i in range(epochs):
y_pred = w * x +c
D_M = (-2/n) * sum(x * (y_original - y_pred))
D_C = (-2/n) * sum(y_original - y_pred)
Here the summation function adds the gradients of all points at once !
Update parameters for all iterations
W = W – lr * D_M
C = C – lr * D_C
Gradient descent method is used for deep learning of neural networks …
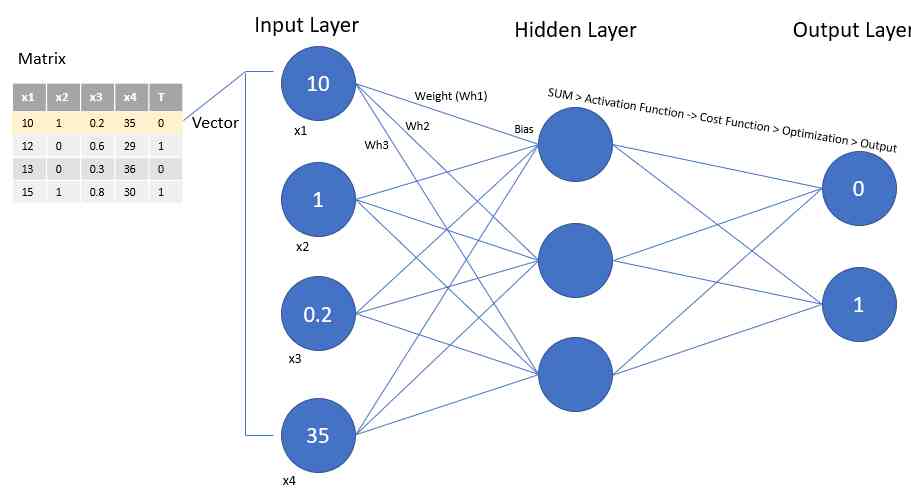
ad locum , We update the weights of each neuron , In order to get the best classification with minimum error . We use gradient descent to update the ownership value of each layer …
Wi = Wi – learning_rate * derivative (Loss function w.r.t Wi)
Why it's popular ?
Gradient descent is the most commonly used optimization strategy in machine learning and deep learning .
It's used to train data models , It can be combined with various algorithms , Easy to understand and implement
Many statistical techniques and methods use GD To minimize and optimize their process .
Reference
- https://en.wikipedia.org/wiki/Gradient_descent
- https://en.wikipedia.org/wiki/Stochastic_gradient_descent
Link to the original text :https://www.analyticsvidhya.com/blog/2020/10/what-does-gradient-descent-actually-mean/
Welcome to join us AI Blog station : http://panchuang.net/
sklearn Machine learning Chinese official documents : http://sklearn123.com/
Welcome to pay attention to pan Chuang blog resource summary station : http://docs.panchuang.net/
版权声明
本文为[Artificial intelligence meets pioneer]所创,转载请带上原文链接,感谢
边栏推荐
- mac 安装hanlp,以及win下安装与使用
- 免费的专利下载教程(知网、espacenet强强联合)
- 01 . Go语言的SSH远程终端及WebSocket
- Asp.Net Core learning notes: Introduction
- 前端模組化簡單總結
- Listening to silent words: hand in hand teaching you sign language recognition with modelarts
- xmppmini 專案詳解:一步一步從原理跟我學實用 xmpp 技術開發 4.字串解碼祕笈與訊息包
- mac 下常用快捷键,mac启动ftp
- htmlcss
- DTU连接经常遇到的问题有哪些
猜你喜欢


随机推荐
Network programming NiO: Bio and NiO
连肝三个通宵,JVM77道高频面试题详细分析,就这?
Jmeter——ForEach Controller&Loop Controller
Flink on paasta: yelp's new stream processing platform running on kubernetes
用Python构建和可视化决策树
DevOps是什么
Sort the array in ascending order according to the frequency
C++和C++程序员快要被市场淘汰了
drf JWT認證模組與自定製
給萌新HTML5 入門指南(二)
6.9.2 session flashmapmanager redirection management
Using Es5 to realize the class of ES6
幽默:黑客式编程其实类似机器学习!
10 easy to use automated testing tools
熬夜总结了报表自动化、数据可视化和挖掘的要点,和你想的不一样
GUI 引擎评价指标
Programmer introspection checklist
大数据应用的重要性体现在方方面面
小白量化投资交易入门课(python入门金融分析)
接口压力测试:Siege压测安装、使用和说明