当前位置:网站首页>嘘!异步事件这样用真的好么?
嘘!异步事件这样用真的好么?
2020-11-06 01:33:00 【尹吉欢】
故事背景
今年年初的时候写了一篇文章 《围观:基于事件机制的内部解耦之心路历程》。这篇文章主要讲的是用 ES 数据异构的场景。程序订阅 Mysql Binlog 的变更,然后程序内部使用 Spring Event 来分发具体的事件,因为一个表的数据变更可能会需要更新多个 ES 索引。
为了方便大家理解我把之前方案的图片复制过来了,如下:
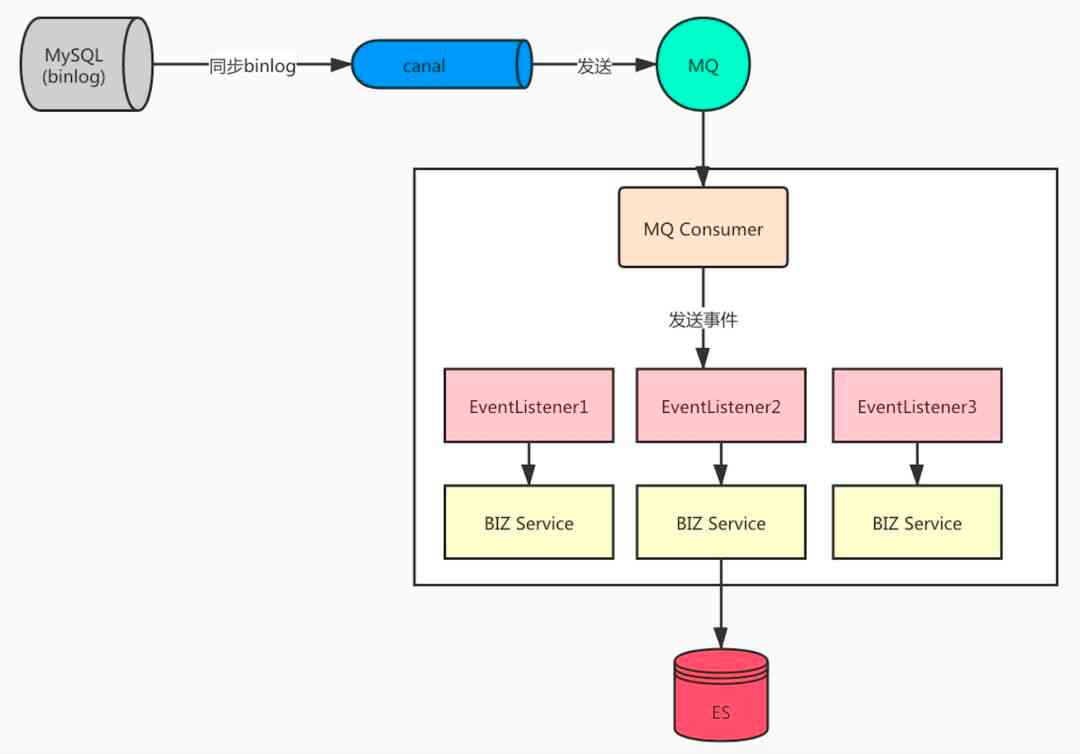
上图的方案存在一个问题,就是我们今天文章要聊的内容。
这个问题就是当 MQ Consumer 收到消息后,就直接发布 Event 了,如果是同步的,没有问题。如果某个 EventListener 中处理失败了,那么这条消息将不会 ACK。
如果是异步发布 Event 的场景,发布完消息马上就 ACK 了。就算某个 EventListener 中处理失败了,MQ 也感知不到,不会进行消息的重新投递,这就是存在的问题。
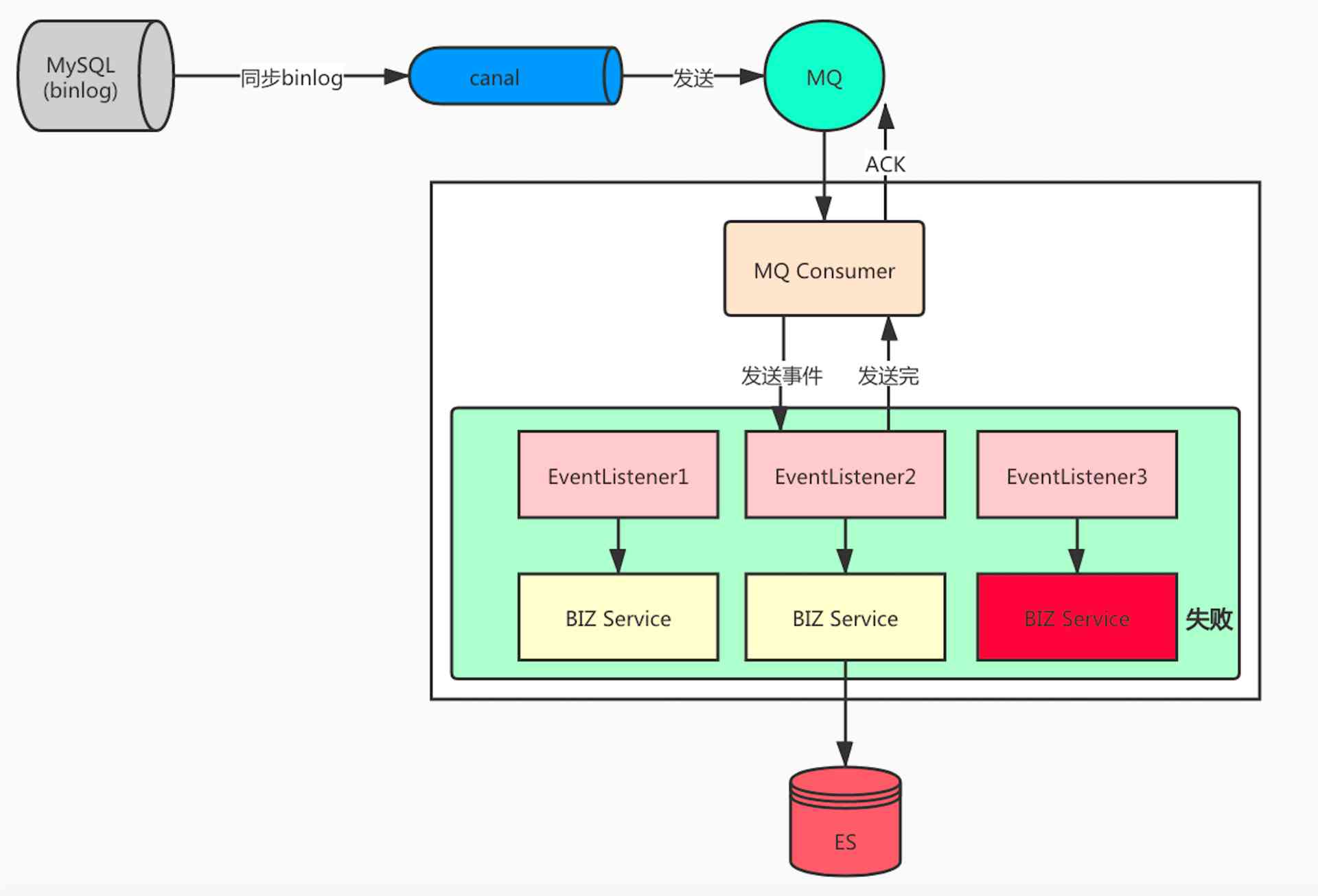
解决方案
方案一
既然消息已经 ACK 了,那就不利用 MQ 的重试功能了,使用方自己重试是不是也可以呢?
可肯定是可以的,内部处理是否成功肯定是可以知道的,如果处理失败了可以默认重试,或者有一定策略的重试。实在不行还可以落库,保存记录。
这样的问题在于太烦了呀,每个使用的地方都要去做这件事情,而且对于未来接手你代码的程序小哥哥来说,这很有可能让小哥哥头发慢慢脱落啊。。。。
脱落不要紧,关键他还不知道要做这个处理,说不定哪天就背锅了,惨兮兮。。。。
方案二
要保证消息和业务处理的一致性,就不能立马进行 ACK 操作。而是要等业务处理完成后再决定是否要 ACK。
如果有处理失败的就不应该 ACK,这样就能复用 MQ 的重试机制了。
分析下来,这就是一个典型的异步转同步的场景。像 Dubbo 中也有这个场景,所以我们可以借鉴 Dubbo 中的实现思路。
创建一个 DefaultFuture 用于同步等待获取任务执行结果。然后在 MQ 消费的地方使用 DefaultFuture。
@Service@RocketMQMessageListener(topic = "${rocketmq.topic.data_change}", consumerGroup = "${rocketmq.group.data_change_consumer}")public class DataChangeConsume implements RocketMQListener<DataChangeRequest> {@Autowiredprivate ApplicationContext applicationContext;@Autowiredprivate CustomApplicationContextAware customApplicationContextAware;@Overridepublic void onMessage(DataChangeRequest dataChangeRequest) {log.info("received message {} , Thread {}", dataChangeRequest, Thread.currentThread().getName());DataChangeEvent event = new DataChangeEvent(this);event.setChangeType(dataChangeRequest.getChangeType());event.setTable(dataChangeRequest.getTable());event.setMessageId(dataChangeRequest.getMessageId());DefaultFuture defaultFuture = DefaultFuture.newFuture(dataChangeRequest, customApplicationContextAware.getTaskCount(), 6000 * 10);applicationContext.publishEvent(event);Boolean result = defaultFuture.get();log.info("MessageId {} 处理结果 {}", dataChangeRequest.getMessageId(), result);if (!result) {throw new RuntimeException("处理失败,不进行消息ACK,等待下次重试");}}}
newFuture() 会传入事件参数,超时时间,任务数量几个参数。任务数量是用于判断所有 EventListener 是否全部执行完成。
defaultFuture.get(); 这不就会阻塞,等待所有任务执行完成才会返回结果,如果所有业务都处理成功了,那么会返回 true,流程结束,消息自动 ACK。
如果返回了 false 证明有处理失败的或者超时的,就不需要 ACK 了,抛出异常等待重试。
public Boolean get() {if (isDone()) {return true;}long start = System.currentTimeMillis();lock.lock();try {while (!isDone()) {done.await(timeout, TimeUnit.MILLISECONDS);// 有失败的任务反馈if (!isSuccessDone()) {return false;}// 全部执行成功if (isDone()) {return true;}// 超时if (System.currentTimeMillis() - start > timeout) {return false;}}} catch (InterruptedException e) {throw new RuntimeException(e);} finally {lock.unlock();}return true;}
isDone() 会判断反馈结果了的任务数量跟总数量是否一致,如果一致就说明全部执行完成了。
public boolean isDone() {return feedbackResultCount.get() == taskCount;}
那么任务执行完了怎么反馈呢? 不可能让每个使用的方法去关心,所以我们定义了一个切面来做这件事情。
@Aspect@Componentpublic class EventListenerAspect {@Around(value = "@annotation(eventListener)")public Object aroundAdvice(ProceedingJoinPoint joinpoint, EventListener eventListener) throws Throwable {DataChangeEvent event = null;boolean executeResult = true;try {event = (DataChangeEvent)joinpoint.getArgs()[0];Object result = joinpoint.proceed();return result;} catch (Exception e) {executeResult = false;throw e;} finally {DefaultFuture.received(event.getMessageId(), executeResult);}}}
通过 DefaultFuture.received() 反馈执行结果。
public static void received(String id, boolean result) {DefaultFuture future = FUTURES.get(id);if (future != null) {// 累加失败任务数量if (!result) {future.feedbackFailResultCount.incrementAndGet();}// 累加执行完成任务数量future.feedbackResultCount.incrementAndGet();if (future.isDone()) {FUTURES.remove(id);future.doReceived();}}}private void doReceived() {lock.lock();try {if (done != null) {// 唤醒阻塞的线程done.signal();}} finally {lock.unlock();}}
下面我们来总结整个流程:
- 收到 MQ 消息,组装成 DefaultFuture,通过 get 方法获取执行结果,未执行完的时候此方法阻塞。
- 通过切面切入加了 EventListener 的方法,判断是否有异常来判断任务的执行结果。
- 通过 DefaultFuture.received() 反馈结果。
- 反馈时计算是否全部完成,全部完成则唤醒阻塞的线程。DefaultFuture.get()就能获取到结果。
- 是否要进行 ACK 操作。
需要注意的是每个 EventListener 内部消费的逻辑都要做幂等控制。
源码地址:https://github.com/yinjihuan/kitty-cloud/tree/master/kitty-cloud-mqconsume
关于作者:尹吉欢,简单的技术爱好者,《Spring Cloud 微服务-全栈技术与案例解析》, 《Spring Cloud 微服务 入门 实战与进阶》作者, 公众号 猿天地 发起人。个人微信 jihuan900,欢迎勾搭。
我整理了一份很全的学习资料,感兴趣的可以微信搜索 「猿天地」,回复关键字 「学习资料」获取我整理好了的Spring Cloud,Spring Cloud Alibaba,Sharding-JDBC分库分表,任务调度框架XXL-JOB,MongoDB,爬虫等相关资料。

版权声明
本文为[尹吉欢]所创,转载请带上原文链接,感谢
http://cxytiandi.com/blog/detail/36489
边栏推荐
猜你喜欢

架构文章搜集
非常规聚合问题举例

Working principle of gradient descent algorithm in machine learning

mac 下常用快捷键,mac启动ftp
面经手册 · 第15篇《码农会锁,synchronized 解毒,剖析源码深度分析!》
别走!这里有个笔记:图文讲解 AQS ,一起看看 AQS 的源码……(图文较长)

2018个人年度工作总结与2019工作计划(互联网)

Big data real-time calculation of baichenghui Hangzhou station
通过深层神经网络生成音乐
Using tensorflow to forecast the rental price of airbnb in New York City
随机推荐
如何使用ES6中的参数
网络安全工程师演示:原来***是这样获取你的计算机管理员权限的!【***】
互联网 舆情系统的架构实践
高级 Vue 组件模式 (3)
读取、创建和运行多个文件的3个Python技巧
8.2.2 inject bean (interceptor and filter) into filter through delegatingfilterproxy
Skywalking系列博客5-apm-customize-enhance-plugin插件使用教程
經典動態規劃:完全揹包問題
小白量化投资交易入门课(python入门金融分析)
python 保存list数据
面经手册 · 第12篇《面试官,ThreadLocal 你要这么问,我就挂了!》
Python machine learning algorithm: linear regression
keras model.compile损失函数与优化器
tensorflow之tf.tile\tf.slice等函数的基本用法解读
链表的常见算法总结
别走!这里有个笔记:图文讲解 AQS ,一起看看 AQS 的源码……(图文较长)
刚刚,给学妹普及了登录的两大绝学
Skywalking系列博客2-Skywalking使用
不能再被问住了!ReentrantLock 源码、画图一起看一看!
微服務 - 如何解決鏈路追蹤問題