当前位置:网站首页>Using tensorflow to forecast the rental price of airbnb in New York City
Using tensorflow to forecast the rental price of airbnb in New York City
2020-11-06 01:14:00 【Artificial intelligence meets pioneer】
author |TIMOTHY102 compile |VK source |Analytics Vidhya
Introduce
Airbnb It's an online market , Allow people to rent their property or spare rooms to guests . Per booking 3 Guests , collect 12% and 6% Commission .
The company started from 2009 Since its establishment in , Has been helped from every year 2.1 Ten thousand guests found accommodation , To help every year 600 Ten thousand people on holiday , Currently in 90 From different countries 34000 Cities list amazing 80 Ten thousand houses .
In this paper , I will use Kaggle-newyorkcityairbnb Open data set , Try to use TensorFlow Build a neural network model to predict .
The goal is to build a suitable machine learning model , Be able to predict the price of future accommodation data .
In this paper , I'm going to show you what I've created Jupyter Notebook. You can GitHub Find it on the :https://github.com/Timothy102/Tensorflow-for-Airbnb-Prices
Load data
First , Let's see how to load data . We use it wget Directly from Kaggle Get data on the website . Be careful -o The flag indicates the file name .
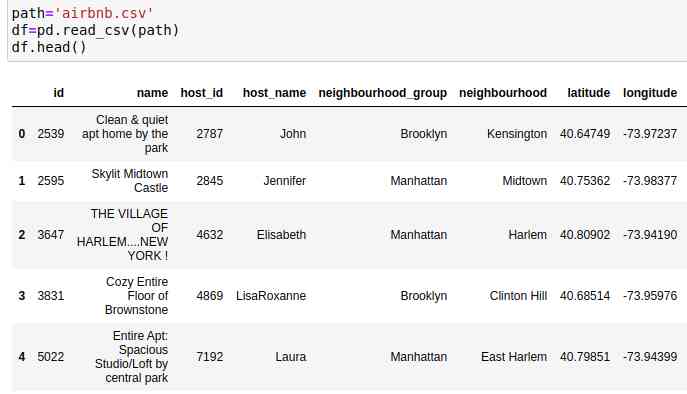
The dataset should look like this . share 48895 That's ok 16 Column .
Data analysis and preprocessing
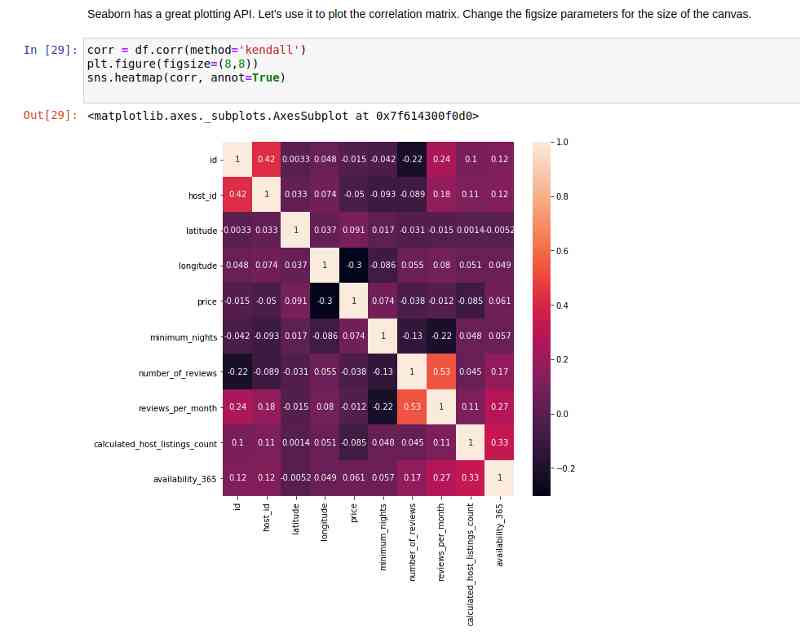
Seaborn There's a very simple API, You can draw all kinds of graphs for all kinds of data . If you are not familiar with grammar , Check out this article :https://www.analyticsvidhya.com/blog/2019/09/comprehensive-data-visualization-guide-seaborn-python/
stay pandas Use on data frame corr after , We pass it on to a heatmap function . give the result as follows :
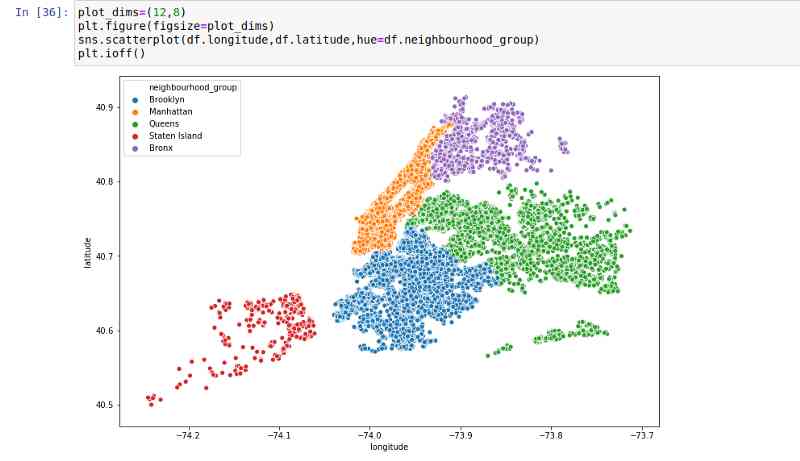
Since we have longitude and longitude and neighborhood data , Let's create a scatter plot :
Besides , I've deleted duplicate items and some unnecessary Columns , And filled in “reviews_per_month”, Because it has too many missing values . The data looks like this . It has 10 Column , There is no zero value :
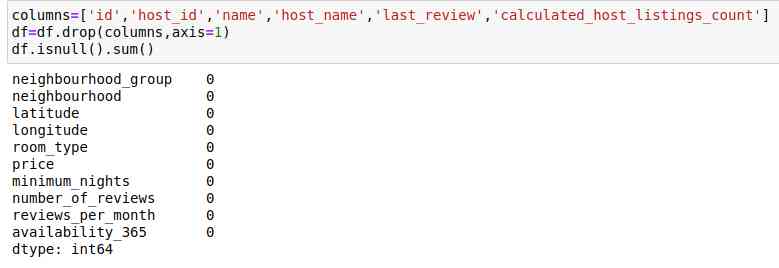
very good , Right ?
First , Computers do numbers . That's why we need to convert a sort column into a one-hot Encoded vector . This is the use of pandas Of factorize Method . You can use a lot of other tools :
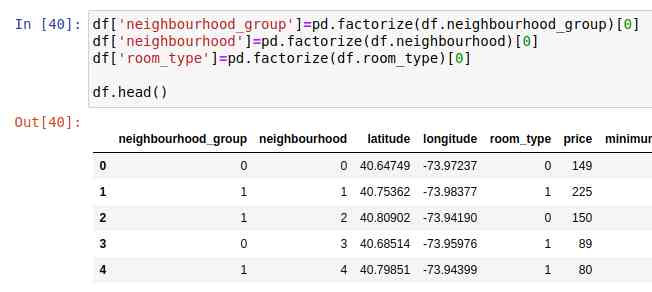
In order to keep the loss function in a stable range , Let's normalize some data , Let the average be 0, The standard deviation is 1.
Feature crossover
We have to make a change , This is an essential change . To correlate longitude and latitude with model output , We have to create a feature crossover . The following links should provide you with sufficient background knowledge , So that you can feel the cross of features correctly :
- https://developers.google.com/machine-learning/crash-course/feature-crosses/video-lecture
- https://www.kaggle.com/vikramtiwari/feature-crosses-tensorflow-mlcc
Our goal is to introduce latitude longitude crossing , This is one of the oldest techniques in the book . If we just put these two columns in the model as values , It will assume that these values are gradually related to the output .
contrary , We're going to use feature crossover , That means we're going to put longitude * The longitude map is divided into a grid . Fortunately, ,TensorFlow Make it easy .
I go through iteration (max-min)/100, So as to generate a frame grid with uniform distribution .
I use it 100×100 grid :

Essentially , What we're doing here , Is to define a bucked Columns and the boundaries defined earlier , And create a DenseFeatures layer , Then pass it to Sequential API.
If you're not familiar with it Tensorflow grammar , Please check the documentation :https://www.tensorflow.org/api_docs/python/tf/feature_column/
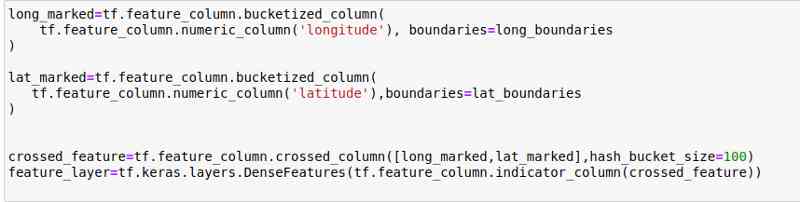
Now? , finally , We are ready for model training . Apart from splitting the data part , in other words .

obviously , We have to create two datasets , One contains all the data , The other contains the predicted score . Due to data size mismatch , This may cause problems for our model , So I decided to truncate data that was too long .
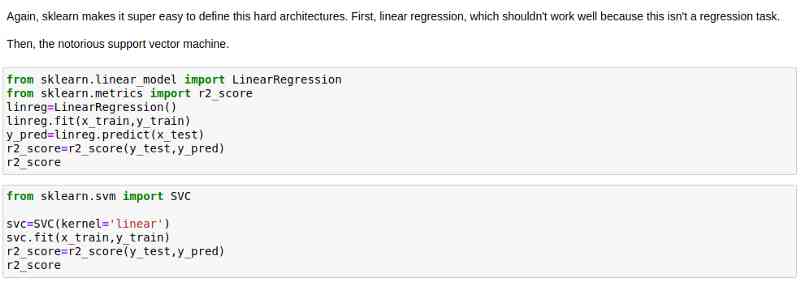
Creating models
Last , Established Keras Sequence model .
We use Adam Optimizer 、 Mean square error loss and two metrics to compile the model .
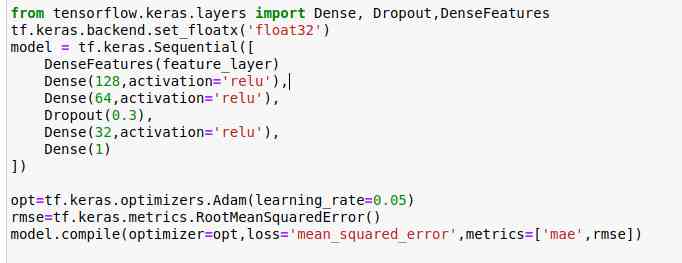
Besides , We use two callbacks :
-
Stop early , This is self-evident
-
Reduce the learning rate at high altitude .

after 50 individual epoch Training for ,batch The size is 64, Our model is quite successful .
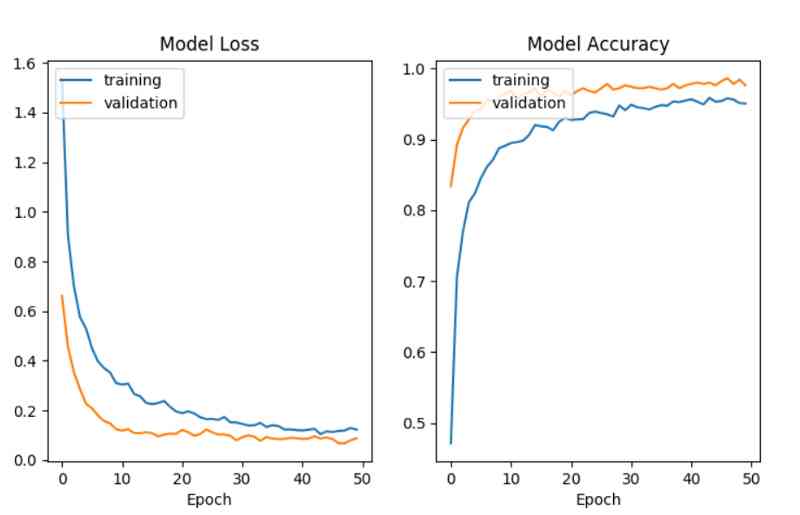
ending
We use New York City AirBnB The data builds a fully connected neural network to predict future prices .Pandas and seaborn It makes it very easy to visualize and examine data . We introduce the idea of latitude longitude crossing as a feature in the model . And thanks to that Kaggle Open data set of , We have a fully operational machine learning model .
Link to the original text :https://www.analyticsvidhya.com/blog/2020/10/predicting-nyc-airbnb-rental-prices-tensorflow/
Welcome to join us AI Blog station : http://panchuang.net/
sklearn Machine learning Chinese official documents : http://sklearn123.com/
Welcome to pay attention to pan Chuang blog resource summary station : http://docs.panchuang.net/
版权声明
本文为[Artificial intelligence meets pioneer]所创,转载请带上原文链接,感谢
边栏推荐
- keras model.compile损失函数与优化器
- 基于深度学习的推荐系统
- 人工智能学什么课程?它将替代人类工作?
- drf JWT認證模組與自定製
- GDB除錯基礎使用方法
- “颜值经济”的野望:华熙生物净利率六连降,收购案遭上交所问询
- Using Es5 to realize the class of ES6
- Didi elasticsearch cluster cross version upgrade and platform reconfiguration
- Don't go! Here is a note: picture and text to explain AQS, let's have a look at the source code of AQS (long text)
- 【新閣教育】窮學上位機系列——搭建STEP7模擬環境
猜你喜欢

“颜值经济”的野望:华熙生物净利率六连降,收购案遭上交所问询
使用NLP和ML来提取和构造Web数据
神经网络简史

Technical director, to just graduated programmers a word - do a good job in small things, can achieve great things
直播预告 | 微服务架构学习系列直播第三期
快快使用ModelArts,零基础小白也能玩转AI!

简直骚操作,ThreadLocal还能当缓存用
Aprelu: cross border application, adaptive relu | IEEE tie 2020 for machine fault detection
分布式ID生成服务,真的有必要搞一个
业内首发车道级导航背后——详解高精定位技术演进与场景应用
随机推荐
Pattern matching: The gestalt approach一种序列的文本相似度方法
Can't be asked again! Reentrantlock source code, drawing a look together!
谁说Cat不能做链路跟踪的,给我站出来
如何对Pandas DataFrame进行自定义排序
Jmeter——ForEach Controller&Loop Controller
被老程式設計師壓榨怎麼辦?我不想辭職
如何在Windows Server 2012及更高版本中將域控制器降級
7.2.2 compressing static resources through gzipresourceresolver
熬夜总结了报表自动化、数据可视化和挖掘的要点,和你想的不一样
【QT】 QThread部分原始碼淺析
Every day we say we need to do performance optimization. What are we optimizing?
[译] 5个Vuex插件,给你的下个VueJS项目
使用Asponse.Words處理Word模板
Asp.Net Core學習筆記:入門篇
容联完成1.25亿美元F轮融资
Electron应用使用electron-builder配合electron-updater实现自动更新
大数据应用的重要性体现在方方面面
Azure Data Factory(三)整合 Azure Devops 實現CI/CD
Using Es5 to realize the class of ES6
用Keras LSTM构建编码器-解码器模型