当前位置:网站首页>自然语言处理-搜索中常用的bm25
自然语言处理-搜索中常用的bm25
2020-11-06 01:22:00 【IT界的小小小学生】
BM25算法是一种常见用来做相关度打分的公式,思路比较简单,主要就是计算一个query里面所有词和文档的相关度,然后在把分数做累加操作,而每个词的相关度分数主要还是受到tf/idf的影响。
关于Bim
BIM(二元假设模型)对于单词特征,只考虑单词是否在doc中出现过,并没有考虑单词本身的相关特征,BM25在BIM的基础上引入单词在查询中的权值,单词在doc中的权值,以及一些经验参数,所以BM25在实际应用中效果要远远好于BIM模型。
具体的bm25
bm25算法是常见的用来计算query和文章相关度的相似度的。其实这个算法的原理很简单,就是将需要计算的query分词成w1,w2,…,wn,然后求出每一个词和文章的相关度,最后将这些相关度进行累加,最终就可以的得到文本相似度计算结果。
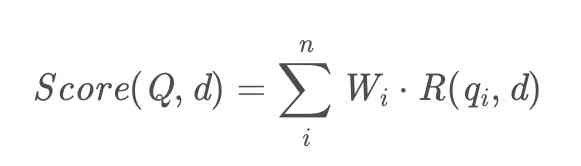
首先Wi表示第i个词的权重,这里我们一般会使用TF-IDF算法来计算词语的权重这个公式第二项R(qi,d)表示我们查询query中的每一个词和文章d的相关度,这一项就涉及到复杂的运算,我们慢慢来看。一般来说Wi的计算我们一般用逆项文本频率IDF的计算公式:
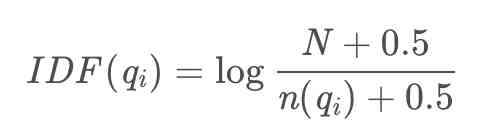
在这个公式中,N表示文档的总数,n(qi)表示包含这个词的文章数,为了避免对数里面分母项等于0,我们给分子分母同时加上0.5,这个0.5被称作调教系数,所以当n(qi)越小的时候IDF值就越大,表示词的权重就越大。
来举个栗子:“bm25”这个词只在很少一部分的文章中出现,n(qi)就会很小,那么“bm25”的IDF值就很大;“我们”,“是”,“的”这样的词,基本上在每一篇文章中都会出现,那么n(qi)就很接近N,所以IDF值就很接近于0,
接着我们来看公式中的第二项R(qi,d),接着来看看第二项的计算公式:
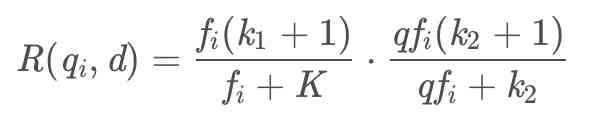
在这个公式中,一般来说,k1、k2和b都是调节因子,k1=1、k2=1、b = 0.75,qfi表示qi在查询query中出现的频率,fi表示qi在文档d中出现的频率,因为在一般的情况下,qi在查询query中只会出现一次,因此把qfi=1和k2=1代入上述公式中,后面一项就等于1,最终可以得到:
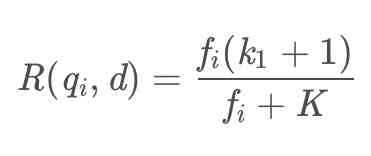
我们再来看看K,在这里其实K的值也是一个公式的缩写,我们把K展开来看: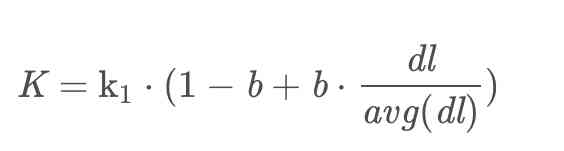
在K的展开式中dl表示文档的长度,avg(dl)表示文档的平均长度,b是前面提到的调节因子,从公式中可以看出在文章长度比平均文章长度固定的情况下,调节因子b越大,文章长度占有的影响权重就越大,反之则越小。在调节因子b固定的时候,当文章的长度比文章的平均长度越大,则K越大,R(qi,d)就越小。我们把K的展开式带入到bm25计算公式中去:
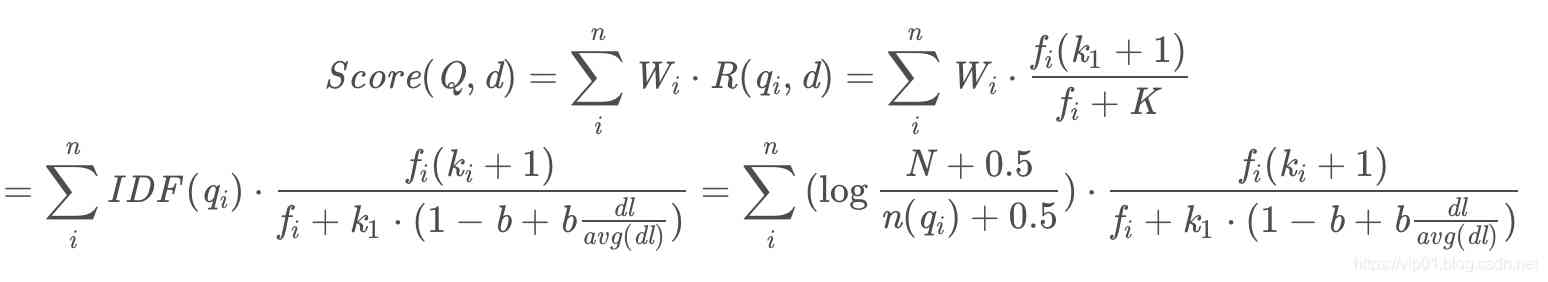
以上就是bm25算法的流程了。
以下是实现过程:
版权声明
本文为[IT界的小小小学生]所创,转载请带上原文链接,感谢
https://vip01.blog.csdn.net/article/details/103206166
边栏推荐
- Flink的DataSource三部曲之二:内置connector
- (1)ASP.NET Core3.1 Ocelot介紹
- Polkadot series (2) -- detailed explanation of mixed consensus
- Serilog原始碼解析——使用方法
- 10 easy to use automated testing tools
- PLC模拟量输入和数字量输入是什么
- 用Keras LSTM构建编码器-解码器模型
- 数据产品不就是报表吗?大错特错!这分类里有大学问
- Elasticsearch database | elasticsearch-7.5.0 application construction
- drf JWT認證模組與自定製
猜你喜欢





随机推荐
业内首发车道级导航背后——详解高精定位技术演进与场景应用
Can't be asked again! Reentrantlock source code, drawing a look together!
ipfs正舵者Filecoin落地正当时 FIL币价格破千来了
GBDT与xgb区别,以及梯度下降法和牛顿法的数学推导
哇,ElasticSearch多字段权重排序居然可以这么玩
阿里云Q2营收破纪录背后,云的打开方式正在重塑
技術總監7年經驗,告訴大家,【拒絕】才是專業
Azure Data Factory(三)整合 Azure Devops 實現CI/CD
分布式ID生成服务,真的有必要搞一个
熬夜总结了报表自动化、数据可视化和挖掘的要点,和你想的不一样
2018个人年度工作总结与2019工作计划(互联网)
Python自动化测试学习哪些知识?
01 . Go语言的SSH远程终端及WebSocket
C language 100 question set 004 - statistics of the number of people of all ages
TensorFlow2.0 问世,Pytorch还能否撼动老大哥地位?
面经手册 · 第12篇《面试官,ThreadLocal 你要这么问,我就挂了!》
【效能優化】納尼?記憶體又溢位了?!是時候總結一波了!!
Technical director, to just graduated programmers a word - do a good job in small things, can achieve great things
給萌新HTML5 入門指南(二)
Leetcode's ransom letter