当前位置:网站首页>词嵌入教程
词嵌入教程
2020-11-06 01:28:00 【人工智能遇见磐创】

作者|Shraddha Anala 编译|VK 来源|Towards Data Science
无论我们是谁,阅读、理解、交流并最终产生新的内容是我们在职业生活中都要做的事情。
当涉及到从给定的文本体中提取有用的特征时,所涉及的过程与连续整数向量(词袋)相比是根本不同的。这是因为句子或文本中的信息是以结构化的顺序编码的,单词的语义位置传达了文本的意思。
因此,在保持文本的上下文意义的同时,对数据进行适当表示的双重要求促使我学习并实现了两种不同的NLP模型来实现文本分类的任务。
词嵌入是文本中单个单词的密集表示,考虑到上下文和其他与之相关的单词。
与简单的词袋模型相比,该实值向量可以更有效地选择维数,更有效地捕捉词与词之间的语义关系。
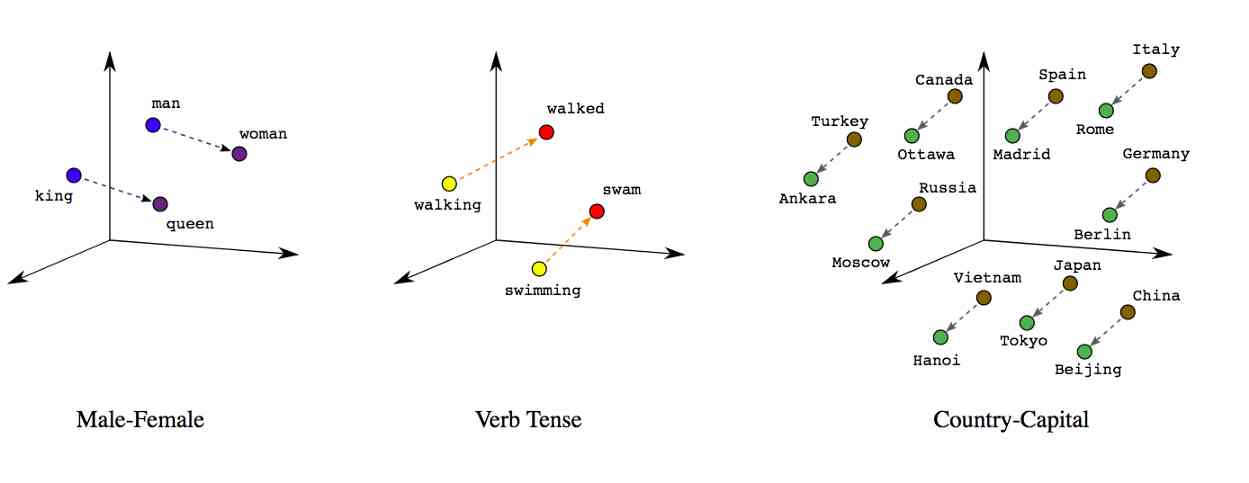
简单地说,具有相似含义或经常出现在相似上下文中的词,将具有相似的向量表示,这取决于这些词在其含义中的“接近”或“相距”有多远。
在本文中,我将探讨两个词的嵌入-
- 训练我们自己的嵌入
- 预训练的GloVe 词嵌入
数据集
对于这个案例研究,我们将使用Kaggle的Stack Overflow 数据集(https://www.kaggle.com/imoore/60k-stack-overflow-questions-with-quality-rate)。这个数据集包含了6万个用户在网站上提出的问题,主要任务是将问题分为3类。
现在让我们看看这个多分类NLP项目的实际模型本身。
但是,在开始之前,请确保你已经安装了这些包/库。
pip install gensim # 用于NLP预处理任务
pip install keras # 嵌入层
1. 训练词嵌入
如果你希望跳过解释,请访问第一个模型的完整代码:https://github.com/shraddha-an/nlp/blob/main/word_embedding_classification.ipynb
1) 数据预处理
在第一个模型中,我们将训练一个神经网络来从我们的文本语料库中学习嵌入。具体地说,我们将使用Keras库为神经网络的嵌入层提供词标识及其索引。
在训练我们的网络之前,必须确定一些关键参数。这些包括词汇的大小或语料库中唯一单词的数量以及嵌入向量的维数。
以下链接是用于训练和测试的数据集。现在我们将导入它们,只保留问题和质量列以供分析:https://www.kaggle.com/imoore/60k-stack-overflow-questions-with-quality-rate
我还更改了列名并定义了一个函数text_clean来清理问题。
# 导入库
# 数据操作/处理
import pandas as pd, numpy as np
# 可视化
import seaborn as sb, matplotlib.pyplot as plt
# NLP
import re
from nltk.corpus import stopwords
from gensim.utils import simple_preprocess
stop_words = set(stopwords.words('english'))
# 导入数据集
dataset = pd.read_csv('train.csv')[['Body', 'Y']].rename(columns = {'Body': 'question', 'Y': 'category'})
ds = pd.read_csv('valid.csv')[['Body', 'Y']].rename(columns = {'Body': 'question', 'Y': 'category'})
# 清理符号和HTML标签
symbols = re.compile(pattern = '[/<>(){}\[\]\|@,;]')
tags = ['href', 'http', 'https', 'www']
def text_clean(s: str) -> str:
s = symbols.sub(' ', s)
for i in tags:
s = s.replace(i, ' ')
return ' '.join(word for word in simple_preprocess(s) if not word in stop_words)
dataset.iloc[:, 0] = dataset.iloc[:, 0].apply(text_clean)
ds.iloc[:, 0] = ds.iloc[:, 0].apply(text_clean)
# 训练和测试集
X_train, y_train = dataset.iloc[:, 0].values, dataset.iloc[:, 1].values.reshape(-1, 1)
X_test, y_test = ds.iloc[:, 0].values, ds.iloc[:, 1].values.reshape(-1, 1)
# one-hot编码
from sklearn.preprocessing import OneHotEncoder as ohe
from sklearn.compose import ColumnTransformer
ct = ColumnTransformer(transformers = [('one_hot_encoder', ohe(categories = 'auto'), [0])],
remainder = 'passthrough')
y_train = ct.fit_transform(y_train)
y_test = ct.transform(y_test)
# 设置参数
vocab_size = 2000
sequence_length = 100
如果你浏览原始数据集,你会发现HTML标记中包含的问题,例如,<p>…question</p>。此外,还有一些词,如href,https等,在整个文本中都有,所以我要确保从文本中删除这两组不需要的字符。
Gensim的simple_preprocess方法返回一个小写的标记列表,去掉重音符号。
在这里使用apply方法将通过预处理函数迭代运行每一行,并在继续下一行之前返回输出。对训练和测试数据集应用文本预处理功能。
因为在因变量向量中有3个类别,我们将应用one-hot编码并初始化一些参数以备以后使用。
2) 标识化
接下来,我们将使用Keras Tokenizer类将单词组成的问题转换成一个数组,用它们的索引表示单词。
因此,我们首先必须使用fit_on_texts方法,从数据集中出现的单词构建索引词汇表。
在建立词汇表之后,我们使用text_to_sequences方法将句子转换成表示单词的数字列表。
pad_sequences函数确保所有观察值的长度相同,可以设置为任意数字或数据集中最长问题的长度。
我们先前初始化的vocab_size参数只是我们词汇表的大小(用于学习和索引)。
# Keras的标识器
from keras.preprocessing.text import Tokenizer
tk = Tokenizer(num_words = vocab_size)
tk.fit_on_texts(X_train)
X_train = tk.texts_to_sequences(X_train)
X_test = tk.texts_to_sequences(X_test)
# 用0填充所有
from keras.preprocessing.sequence import pad_sequences
X_train_seq = pad_sequences(X_train, maxlen = sequence_length, padding = 'post')
X_test_seq = pad_sequences(X_test, maxlen = sequence_length, padding = 'post')
3) 训练嵌入层
最后,在这一部分中,我们将构建和训练我们的模型,它由两个主要层组成,一个嵌入层将学习上面准备的训练文档,以及一个密集的输出层来实现分类任务。
嵌入层将学习单词的表示,同时训练神经网络,需要大量的文本数据来提供准确的预测。在我们的例子中,45000个训练观察值足以有效地学习语料库并对问题的质量进行分类。我们将从指标中看到。
# 训练嵌入层和神经网络
from keras.models import Sequential
from keras.layers import Embedding, Dense, Flatten
model = Sequential()
model.add(Embedding(input_dim = vocab_size, output_dim = 5, input_length = sequence_length))
model.add(Flatten())
model.add(Dense(units = 3, activation = 'softmax'))
model.compile(loss = 'categorical_crossentropy',
optimizer = 'rmsprop',
metrics = ['accuracy'])
model.summary()
history = model.fit(X_train_seq, y_train, epochs = 20, batch_size = 512, verbose = 1)
# 完成训练后保存模型
#model.save("model.h5")
4) 评估和度量图
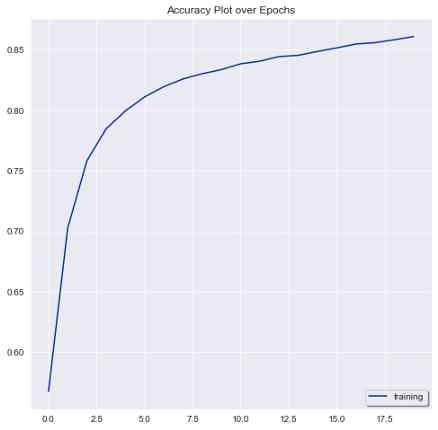
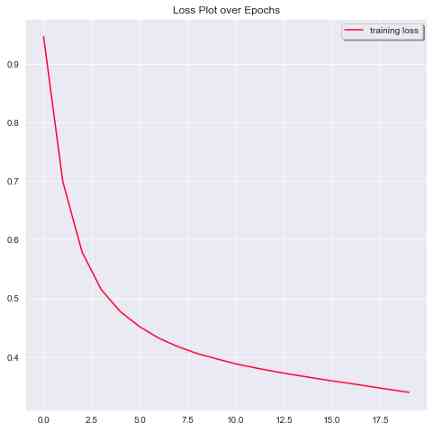
剩下的就是评估我们的模型的性能,并绘制图来查看模型的准确性和损失指标是如何随时间变化的。
我们模型的性能指标显示在下面的屏幕截图中。

代码与下面显示的代码相同。
# 在测试集上评估模型的性能
loss, accuracy = model.evaluate(X_test_seq, y_test, verbose = 1)
print("\nAccuracy: {}\nLoss: {}".format(accuracy, loss))
# 画出准确度和损失
sb.set_style('darkgrid')
# 1) 准确度
plt.plot(history.history['accuracy'], label = 'training', color = '#003399')
plt.legend(shadow = True, loc = 'lower right')
plt.title('Accuracy Plot over Epochs')
plt.show()
# 2) 损失
plt.plot(history.history['loss'], label = 'training loss', color = '#FF0033')
plt.legend(shadow = True, loc = 'upper right')
plt.title('Loss Plot over Epochs')
plt.show()
以下是训练中准确度的提高
20个epoch的损失图
2.预训练的GloVe词嵌入
如果你只想运行模型,这里有完整的代码:https://github.com/shraddha-an/nlp/blob/main/pretrained_glove_classification.ipynb
代替训练你自己的嵌入,另一个选择是使用预训练好的词嵌入,比如GloVe或Word2Vec。在这一部分中,我们将使用在Wikipedia+gigaword5上训练的GloVe词嵌入;从这里下载:https://nlp.stanford.edu/projects/glove/
i) 选择一个预训练的词嵌入,如果
你的数据集是由更“通用”的语言组成的,一般来说你没有那么大的数据集。
由于这些嵌入已经根据来自不同来源的大量单词进行了训练,如果你的数据也是通用的,那么预训练的模型可能会做得很好。
此外,通过预训练的嵌入,你可以节省时间和计算资源。
ii)选择训练你自己的嵌入,如果
你的数据(和项目)是基于一个利基行业,如医药、金融或任何其他非通用和高度特定的领域。
在这种情况下,一般的词嵌入表示法可能不适合你,并且一些单词可能不在词汇表中。
需要大量的领域数据来确保所学的词嵌入能够正确地表示不同的单词以及它们之间的语义关系
此外,它需要大量的计算资源来浏览你的语料库和建立词嵌入。
最终,是根据已有的数据训练你自己的嵌入,还是使用预训练好的嵌入,将取决于你的项目。
显然,你仍然可以试验这两种模型,并选择一种精度更高的模型,但上面的教程只是一个简化的教程,可以帮助你做出决策。
过程
前面的部分已经采取了所需的大部分步骤,只需进行一些调整。
我们只需要构建一个单词及其向量的嵌入矩阵,然后用它来设置嵌入层的权重。
所以,保持预处理、标识化和填充步骤不变。
一旦我们导入了原始数据集并运行了前面的文本清理步骤,我们将运行下面的代码来构建嵌入矩阵。
以下决定要嵌入多少个维度(50、100、200),并将其名称包含在下面的路径变量中。
# # 导入嵌入
path = 'Full path to your glove file (with the dimensions)'
embeddings = dict()
with open(path, 'r', encoding = 'utf-8') as f:
for line in f:
# 文件中的每一行都是一个单词外加50个数(表示这个单词的向量)
values = line.split()
# 每一行的第一个元素是一个单词,其余的50个是它的向量
embeddings[values[0]] = np.array(values[1:], 'float32')
# 设置一些参数
vocab_size = 2100
glove_dim = 50
sequence_length = 200
# 从语料库中的单词构建嵌入矩阵
embedding_matrix = np.zeros((vocab_size, glove_dim))
for word, index in word_index.items():
if index < vocab_size:
try:
# 如果给定单词的嵌入存在,检索它并将其映射到单词。
embedding_matrix[index] = embeddings[word]
except:
pass
构建和训练嵌入层和神经网络的代码应该稍作修改,以允许将嵌入矩阵用作权重。
# 神经网络
from keras.models import Sequential
from keras.layers import Embedding, Dense, Flatten
model = Sequential()
model.add(Embedding(input_dim = vocab_size,
output_dim = glove_dim,
input_length = sequence))
model.add(Flatten())
model.add(Dense(units = 3, activation = 'softmax'))
model.compile(optimizer = 'adam', metrics = ['accuracy'], loss = 'categorical_crossentropy')
# 加载我们预训练好的嵌入矩阵到嵌入层
model.layers[0].set_weights([embedding_matrix])
model.layers[0].trainable = False # 训练时权重不会被更新
# 训练模型
history = model.fit(X_train_seq, y_train, epochs = 20, batch_size = 512, verbose = 1)
下面是我们预训练的模型在测试集中的性能指标。

结论
从两个模型的性能指标来看,训练嵌入层似乎更适合这个数据集。
一些原因可能是
1) 关于堆栈溢出的大多数问题都与IT和编程有关,也就是说,这是一个特定领域的场景。
2) 45000个样本的大型训练数据集为我们的嵌入层提供了一个很好的学习场景。
希望本教程对你有帮助,谢谢你的阅读,下一篇文章再见。
原文链接:https://towardsdatascience.com/a-guide-to-word-embeddings-8a23817ab60f
欢迎关注磐创AI博客站: http://panchuang.net/
sklearn机器学习中文官方文档: http://sklearn123.com/
欢迎关注磐创博客资源汇总站: http://docs.panchuang.net/
版权声明
本文为[人工智能遇见磐创]所创,转载请带上原文链接,感谢
https://my.oschina.net/u/4253699/blog/4700265
边栏推荐
猜你喜欢




随机推荐
滴滴 Elasticsearch 集群跨版本升级与平台重构之路
Jumpserver高可用集群部署:(六)SSH代理模块koko部署并实现系统服务管理
Probabilistic linear regression with uncertain weights
从零学习人工智能,开启职业规划之路!
计组-字长
面经手册 · 第14篇《volatile 怎么实现的内存可见?没有 volatile 一定不可见吗?》
es5 类和es6中class的区别
WeihanLi.Npoi 1.11.0/1.12.0 Release Notes
给萌新HTML5 入门指南(二)
技术总监,送给刚毕业的程序员们一句话——做好小事,才能成就大事
用TensorFlow预测纽约市AirBnB租赁价格
Using class weight to improve class imbalance
mac 安装hanlp,以及win下安装与使用
通用的底层埋点都是怎么做的?
PMP考试心得
7.3.2 File Download & big file download
刚毕业不久,接私活赚了2万块!
VUEJS开发规范
JUC 包下工具类,它的名字叫 LockSupport !你造么?
十二因子原则和云原生微服务 - DZone