当前位置:网站首页>【GPU并行计算】利用OpenCL&OpenCLUtilty进行GPU并行计算
【GPU并行计算】利用OpenCL&OpenCLUtilty进行GPU并行计算
2022-07-30 02:57:00 【JinSu_】
问题背景介绍

CPU:运算核心较少,在大规模并行计算能力上极受限制,擅长流程控制和逻辑处理
GPU:运算核心较多,适合数据并行的计算密集型任务
异构计算:CPU处理复杂的逻辑运算和流程控制,当需要处理大量类型统一的数据时,再调用GPU进行并行计算
OpenCL和CUDA的区别&下载
OpenCL(Open Computing Langugae,开放运算语言)是第一个面向异构系统(此系统中可由CPU,GPU或其它类型的处理器架构组成)的并行编程的跨平台的开放式标准。
CUDA(Compute Unified Device Architecture,统一计算架构),是显卡厂商NVIDIA推出的运算平台。 该架构使GPU能够解决复杂的计算问题。 它包含了CUDA指令集架构(ISA)以及GPU内部的并行计算引擎。 开发人员可以使用C、 C++和FORTRAN(或者是OpenCL)来为CUDA架构编写程序,所编写出的程序可以在支持CUDA的处理器上以超高性能运行。
CUDA和OpenCL,前者是配备完整工具包、针对单一供应商(NVIDIA)的成熟的开发平台,后者是一个开放的标准。OpenCL是一个API,在第一个级别,CUDA架构是更高一个级别,在这个架构上不管是OpenCL还是DX11这样的API,还是像C语言、Fortran、DX11计算,都可以支持。

Choose & Download Intel SDK for OpenCL Applications

CUDA Toolkit Archive | NVIDIA Developer
OpenCL的基本概念
platform & device
平台(platform)可被认为是不同厂商提供的OpenCL API的实现。如果一个平台选定之后一般只能运行该平台所支持的设备。就当前的情况来看,如果选择了Intel的OpenCL SDK就只能使用Intel的CPU来进行计算了,如果选择AMD的APP SDK则能进行AMD的CPU和AMD的GPU来进行计算。
一般而言,A公司的平台选定之后不能与B公司的平台进行通信。
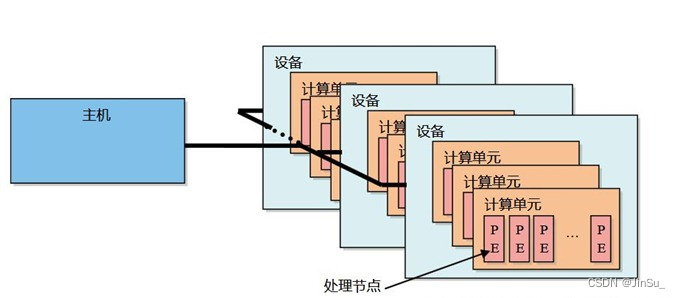
平台由两部分组成,宿主机和设备:
宿主机Host :宿主机一般为CPU,扮演组织者的角色。
设备Device :通常称为计算设备,设备有一个或多个计算单元,计算单元又包含一个或多个处理单元。在设备上运行的程序被称为核函数 (对于核函数的编写,CUDA一般直接写在程序内,OpenCL是写在一个独立的文件中,并且文件后缀是.cl,由主机代码读入后执行)
上下文context
定义了整个OpenCL的运行环境,包括设备device、内核kernel、程序对象program、内存对象memory和命令队列CommandQueue :
设备 device : OpenCL程序调用的计算设备。
内核 kernel : 在设备程序上执行运算的入口函数,在主机上调用。
程序对象 program : 内核程序的源代码(.cl文件)和可执行文件。
内存对象 memory : 计算设备执行OpenCL程序所需的变量。
命令队列 CommandQueue : 队列控制着kernel如何执行以及何时执行等细节。
内核kernel & 程序对象program
工作项(Work-item): 跟CUDA中的线程(Threads)是同一个概念,
N多个工作项(线程)执行同样的核函数,每个Work-item都有一个唯一固定的ID号,一般通过这个ID号来区分需要处理的数据。work-item是抽象的计算单元,和物理层面分配的计算单元不完全对应,一个实际物理计算单元也可以分别计算多个work-item。
工作组(Work-group):跟CUDA中的线程块(Block)是同一个概念,
N多个工作项组成一个工作组,Work-group内的这些Work-item之间可以通信和协作。

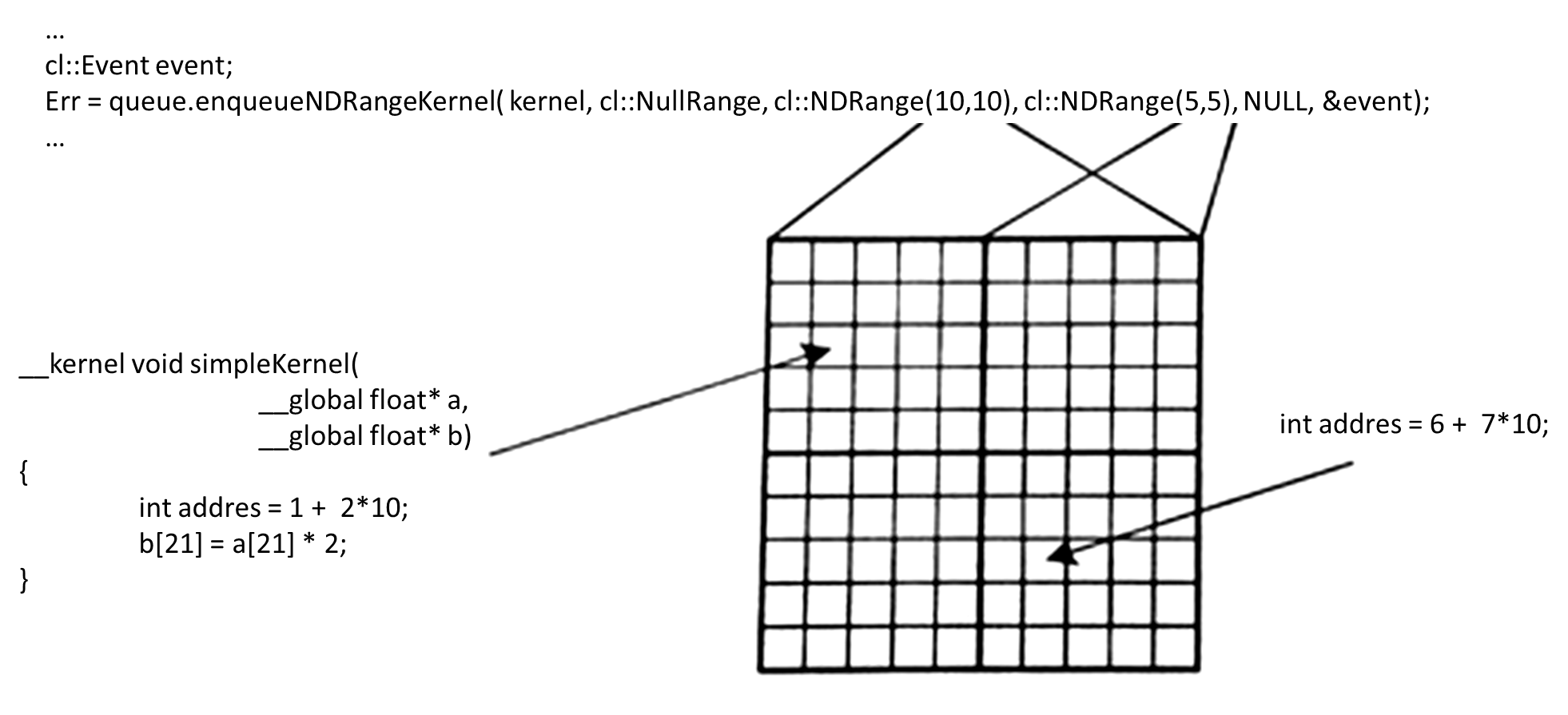
内核启动接口clEnqueueNDRangeKernel

跟CUDA中的 “<<<block,threads >>>来指定kernel要调度的线程数量” 是同一个概念,定义了Work-group的组织形式。
其中,三个重要参数:
global_work_offset: global_id的偏移量
global_work_size: 总的work-item数量
local_work_size: 虚拟的分区,定义work-group的中包含的work-item数量
举个例子:获取当前坐标x
get_global_id(0) = get_group_id(0) * get_local_size(0) + get_local_id(0) + get_global_offset(0) ;
核函数 & 内核 & 内核启动
一个简单的内核,将输入的二维数组中的数据乘以2后,放入输出数组中

OpenCL的封装库: OpenCLUtilty


https://registry.khronos.org/OpenCL/specs/opencl-cplusplus-1.2.pdf
https://github.com/smistad/OpenCLUtilityLibrary
举例:A + B = C
这里基于OpenCLUtilty开发opencl运行程序,A + B = C。流程类似上图。





举例:3维数据的一阶特征计算

![]()
一个开源的python包,用于从医学成像中提取放射组学特征
Radiomic Features — pyradiomics v3.0.1.post15+g2791e23 documentation

边栏推荐
猜你喜欢

VMware disk expansion record

代码可读性,前置检查、注释及总结

解决:npm ERR code ELIFECYCLE npm ERR errno 1(安装脚手架过程中,在npm run dev 时发生错误)

群论-Burnside引理与Polya定理 三千字

1050 graphics card, why is the graphics card usage ranking on Steam always the top five

WebSocket在线通信
Open address method hash implementation - secondary detection method

答对这3个面试问题,薪资直涨20K

centOS安装MySQL详解
Oracle 迁移至Mysql
随机推荐
QT基础第三天(3)widget,dialog和mainwindow
B. Different Divisors- Codeforces Round #696 (Div. 2)
ESP8266 +0.96" I2C OLED Dial Clock
【C语言刷LeetCode】592. 分数加减运算(M)
1050的显卡,为何在Steam上的显卡使用率排行榜一直都是前五
复旦-华盛顿大学EMBA科创的奥E丨《神奇的材料》与被塑造的我们
开放地址法哈希实现——线性探测法
Solve The problem of Google browser cross-domain has had been blocked by CORS policy: The request The client is not a secure context and The resou
Not enough information to list load addresses in the image map. (STM32 compilation error)
Oracle 进程数和会话数的关系
票房破7.9亿美元,最近这部恐龙爽片你看了吗?
厉害,腾讯技术专家手撸Redis技术笔记,下载量已突破30W
解决:npm ERR code ELIFECYCLE npm ERR errno 1(安装脚手架过程中,在npm run dev 时发生错误)
1050 graphics card, why is the graphics card usage ranking on Steam always the top five
固体火箭发动机三维装药逆向内弹道计算
力扣(LeetCode)210. 课程表 II(2022.07.29)
nrm ls 为什么前面不带 *了
Unity Editor自定义一个记录Bug的窗口
A transaction is in Mysql?What's the use?
Not enough information to list load addresses in the image map.(STM32编译报错)