当前位置:网站首页>Spark Learning: how to choose different association forms and mechanisms?
Spark Learning: how to choose different association forms and mechanisms?
2022-07-24 09:35:00 【I love evening primrose a】
Spark Sql in join There are many kinds of , Here, it is divided into correlation form and time mechanism
One 、 Data preparation
eg:
import spark.implicits._
import org.apache.spark.sql.DataFrame
// Create an employee table
val seq = Seq((1,"li",20,"Male"),(2,"shi",22,"Female"),(3,"ming",24,"Female"))
val employees:DataFrame = seq.toDF("id","name","age","gender")
// Create salary table
val seq2 = Seq((1,20000),(2,26000),(3,24000),(4,30000))
val salaries:DataFrame = seq2.toDF("id","salary")
Two 、 Association form
| Association form | keyword |
|---|---|
| Internal connection | inner |
| Left outer connection | left/leftouter/left_outer |
| Right external connection | right/rightouter/right_outer |
| All external connections | outer/full/fullouter/full_outer |
| Left half Association | leftsemi/left_semi |
| Left inverse association | leftanti/left_anti |
Internal connection 、 Left outer connection 、 Right external connection 、 External connection and sql The same in grammar , I won't elaborate here
1、 Left half Association :
The result set of left semi association is actually a subset of inner Association , It will only keep those data records that meet the association conditions in the left table
eg:
val leftsemijoinDF:DataFrame = salaries.join(employees,salaries("id") === employees("id"),"leftsemi")
leftsemijoinDF.show
As shown in the figure ,salaries There are three pieces of data and employees It matches , The left outer Association will only retain the data matching the left table and the right table
2、 Left inverse association
After understanding the left half Correlation , Left inverse correlation is also easy to understand , Similarly, only the left data is retained , But only keep the unmatched data
eg:
val leftantijoinDF:DataFrame = salaries.join(employees,salaries("id") === employees("id"),"leftanti")
leftantijoinDF.show
3、 ... and 、 Implementation mechanism
1、NLJ(Nested Loop Join) Nested loop connection
- For the two tables involved in association , Such as salaries and employees, In the order in which the codes appear , Generally put salaries Called drive table ,employees Called the base table , stay NLJ Under the implementation mechanism of , The algorithm can be used outside 、 Two nested for loop , To scan the data records of the drive table and the base table in turn , While scanning , It also determines whether the correlation condition is true , As the example above shows , On the outside floor for Cycle first scan the drive table , Scan to id by 1 One hour of , The nested inner loop is also scanning , When the internal circulation is also scanned 1 when , Will match the output , And so on , Judge the recorded in turn id Whether the field meets the conditions
Suppose the drive table has m Bar record , The base table has n Bar record , that NLJ The computational complexity of the algorithm is O(mn), Poor execution efficiency *
2、SMJ(Sort Merge Join) Sort merge connections
- SMJ Will sort the two tables first , Then use a separate cursor , Merge and associate the two sorted tables The specific calculation process :
At first , The cursors of the drive table and the base table will be on their first record , Then, by comparing the record where the cursor is located id value , To determine the next step
a、 Satisfy the correlation conditions , On both sides id The values are equal , At this time, the data records on both sides are spliced and output , Then slide the cursor of the drive table to the next record
b、 The association condition is not satisfied , The driver table id The value is less than the base table id value , Now slide the cursor of the drive table to the next record
c、 The association condition is not satisfied , The driver table id The value is greater than the base table id value , Now slide the cursor of the base table to the next record
therefore ,SMJ The computational complexity of the algorithm is O(m+n), But the computational complexity is reduced , It depends on arranging the order first , This is a time-consuming operation , You can sort by indexing
3、HJ(Hash Join) Hash join ( Space for time )
HJ The calculation is divided into two stages , Namely Bulid Phase and Probe Stage
- a、 stay Bulid Stage , Above the base table , The algorithm uses the established hash function to build a hash table , In the hash table key yes id Field applies the hash value of the hash function , And hash table value It also includes the original Join
Key and Payload, As shown in the figure below
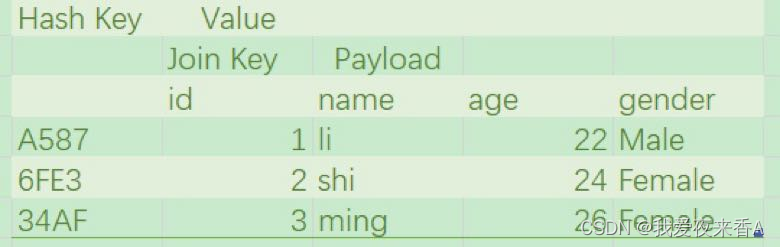
- b、 stay Probe Stage , The algorithm traverses each data record of the driving table in turn , First use the same Hash function , Calculate in a dynamic manner Join
Key Hash value of , then , The algorithm then uses the hash value to query just in Bulid Hash table created in phase , If the query fails , This indicates that there is no association between this record and the data in the base table ; contrary , If the query is successful , Then continue to compare the two sides Join
Key, If Join Key Agreement , Just splice the records on both sides for output , So as to carry out data association
Four 、NLJ/SMJ/HJ The advantages and disadvantages of
1、hash join The most efficient execution , however , stay Probe Stage before enjoying performance bonus ,Bulid Stage I have to build a hash table in memory , therefore hash join High memory requirements , It is suitable for computing scenarios where the memory can hold base table data
2、sort merge join There is no memory limitation , Disk can be used for sorting or merging , The applicable scenario is participation join The table of is an ordered table
3、nested loop join Poor efficiency , But it can deal with unequal Correlation , and hash join and sort merge join Can only handle equivalent connections
5、 ... and 、 Form of association in distributed environment ???
Form of association in distributed environment
边栏推荐
- Account 1-2
- Gnuplot software learning notes
- PHP caching system - PHP uses Memcache
- Description of MATLAB functions
- Jenkins post build script does not execute
- The difference between & &, | and |
- One click openstack single point mode environment deployment - preliminary construction
- 来阿里一年后我迎来了第一次工作变动....
- [don't bother with reinforcement learning] video notes (I) 1. What is reinforcement learning?
- PHP debugging tool - how to install and use firephp
猜你喜欢

Aruba learning notes 06 wireless control AC basic configuration (CLI)

【基于ROS的URDF练习实例】四轮机器人与摄像头的使用
Gin framework uses session and redis to realize distributed session & Gorm operation mysql
Getting started with web security - open source firewall pfsense installation configuration

Detailed sequence traversal of leetcode102 binary tree

来阿里一年后我迎来了第一次工作变动....

& 和 &&、| 和 || 的区别

One click openstack single point mode environment deployment - preliminary construction

Leetcode skimming: dynamic planning 03 (climb stairs with minimum cost)
Cloud primordial (12) | introduction to kubernetes foundation of kubernetes chapter
随机推荐
Getting started with web security - open source firewall pfsense installation configuration
2021 robocom world robot developer competition - undergraduate group (Preliminary) problem solution
Hands on deep learning (VII) -- bounding box and anchor box
SQL 优化原则
PHP Basics - PHP magic method
FreeRTOS - use of software timer
[don't bother with reinforcement learning] video notes (I) 3. Why use reinforcement learning?
RxJS Beginner Guide
分类与回归的区别
JS locate Daquan to get the brother, parent and child elements of the node, including robot instances
科目1-2
What if path is deleted by mistake when configuring system environment variables?
Gnuplot software learning notes
Getting started with identityserver4
Learning transformer: overall architecture and Implementation
Description of MATLAB functions
来阿里一年后我迎来了第一次工作变动....
Makefile variables and dynamic library static library
Get the historical quotation data of all stocks
PHP debugging tool - how to install and use firephp