当前位置:网站首页>Mysql索引相关的知识复盘一
Mysql索引相关的知识复盘一
2022-08-01 10:00:00 【Drgom】
索引的作用和分类
索引的优缺点
优点:
- 加快数据检索速率
- 排序分组时候,使用索引将降低资源的消耗
缺点:
- 增加了索引维护的成本
- 降低了更新的速度
- 提高了数据维护的成本
- 索引会占据更多的磁盘的空间
索引的一般分类
从 功能逻辑上说,索引主要有4种,分别是普通索引、唯一索引、主键索引、全文索引。 按照 物理实现方式 ,索引可以分为2种:聚簇索引和非聚簇索引。 按照 作用字段个数 进行划分,分成单列索引和联合索引 索引的分类如下:
- 普通索引
- 唯一性索引
- 主键索引
- 单列索引
- 多列(组合、联合)索引
- 全文索引
- 空间索引
索引创建规范
CREATE TABLE table_name [col_name data_type] [UNIQUE | FULLTEXT | SPATIAL] [INDEX | KEY] [index_name] (col_name [length]) [ASC | DESC]
- UNIQUE 、 FULLTEXT 和 SPATIAL 为可选参数,分别表示唯一索引、全文索引和空间索引;
- INDEX 与 KEY 为同义词,两者的作用相同,用来指定创建索引;
- index_name 指定索引的名称,为可选参数,如果不指定,那么MySQL默认col_name为索引名;
- col_name 为需要创建索引的字段列,该列必须从数据表中定义的多个列中选择;
- length 为可选参数,表示索引的长度,只有字符串类型的字段才能指定索引长度;
- ASC 或 DESC 指定升序或者降序的索引值存储
索引的数据结构和IO流程
Mysql的索引使用B+树结构,树的节点不止保存了主键数据还保存了其他字段,好处在于可以减少IO操作,也导致了索引占用了大量的磁盘空间,增加了索引的维护的难度

索引的IO操作流程
仍以下图为例(record_type :记录头信息的一项属性,表示记录的类型, 0 表示普通记录、 2 表示最小记录、3 表示最大记录) 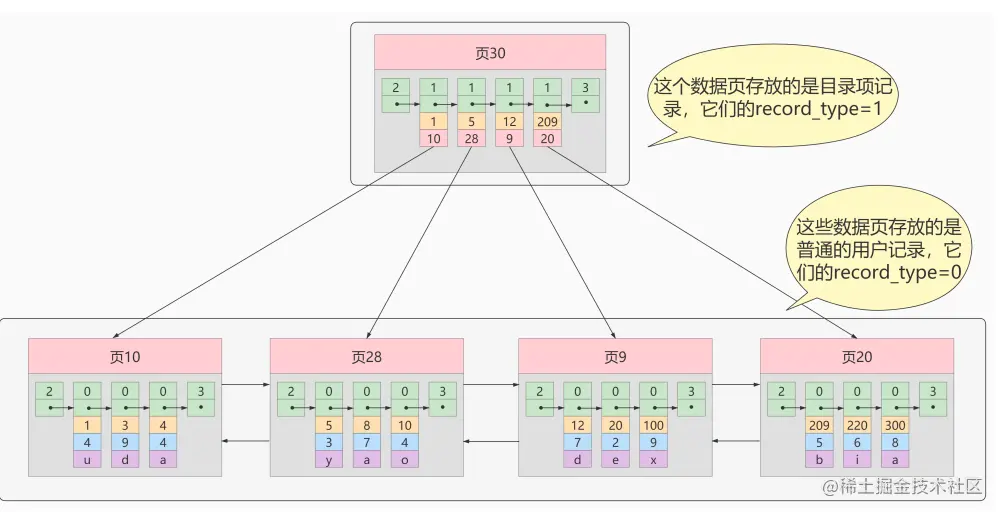
数据的新增操作
前面可以看到页的数据已经满了,如果需要插入新的数据,需要重新生成新的一页,如下,不仅需要生成新的页32,还需要生成新的页31保存数据(因为页32是作为目录项存在的)

索引的数据的查找
以查找主键值为5的数据为例 一 确认目录项
索引会按照目录,通过的目录保存的最大和最小的主键值,确认所在目录在页30
二 根据目录的记录查找
目录保存了每个页的数据的最小值,通过最小值可以确定数据在页28
三 在页内查找
在页28内查找数据,可获得主键值为5的全部数据
页分裂的操作
Mysql的索引数据是按页(聚簇索引)的存储,索引不仅保存了用户的数据,而且维护索引结构,保证新的页数据的主键索引比前面的大,当发现不满足条件时候,会触发分页操作,调整数据分布,为了提高数据的插入速度,也为了降低数据的维护成本,建议每次插入时候,保持主键的递增

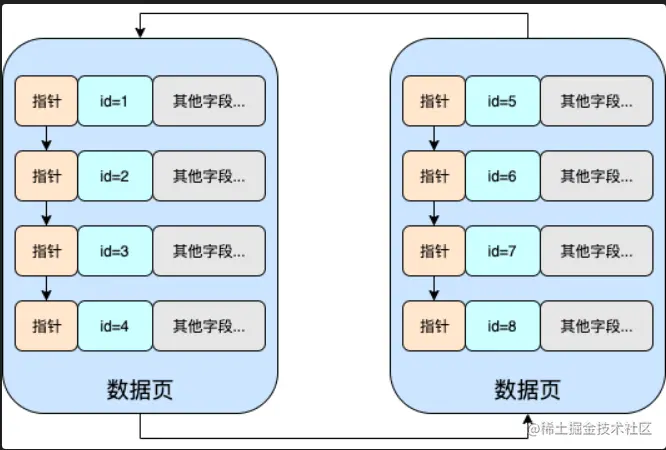
聚簇索引和非聚簇索引的区别
聚簇索引在叶子节点保存了数据,而非聚簇索引只保存主键值和完整数据的物理地址,当非聚簇索引需要使用非主键字段时候,在查找一次非聚簇索引的数据后,按照其获得的物理地址,在对应的数据也查找,获得全部的字段,这就是回表
索引的设计准则
索引适合的场景
- 索引的字段具有唯一性
- 需要频繁过过滤的字段
- 需要频繁分组排序的字段
- 表连接的字段需要建立索引
- 有条件的更新操作
- 需要去重的字段
建议:索引的字段需要具有散列性,重复度太高的字段,没必要做索引,若使用前缀索引,需要截取字段的时候,可以使用参考规则
如一下建表语法
create table shop(address varchar(120) not null); 使用类似的语法,使用选择度较高,字段较少的字段,建立索引,

索引的不适合的场景
- 数据重复多
- 数据量小
- 经常药更新的字段
- 字段无序
- 索引冗余的字段
索引的性能测试
使用orderinfo表,数据大小为1110368条数据,建表语句如下:
CREATE TABLE orderinfo( user_id` bigint DEFAULT NULL,
order_id bigint NOT NULL,
item_id bigint DEFAULT NULL,
flag bigint DEFAULT NULL,
times bigint DEFAULT NULL,
price float DEFAULT NULL,
num int DEFAULT NULL,
PRIMARY KEY (order_id) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;`
分组测试
select item_id,count(*) from orderinfo group by item_id 无索引为0.63秒
有索引为0.41秒
去重测试
select distinct(user_id) from orderinfo
有索引 0.47s 无索引 0.56s
排序测试
select distinct item_id from orderinfo order by item_id desc limit 10;
有索引 0.01s
无索引 0.56s
复杂的聚合排序
select item_id,sum(price) as price from orderinfo where flag=4 group by item_id order by price desc limit 100;
无索引 2.58s
有索引 2.57s 没有优势
主要是使用order by语句需要进行filesort文件排序和临时表保存数据,时间延长了
explain
explain语句可以用来分析sql语句的执行状态以以下语句为例:
explain select item_id,sum(price) as price from orderinfo where flag=4 group by item_id order by price desc limit 100;
执行结果如以下所示:

Mysql8索引新特性
索引隐藏
mysql8引入了不可见索引,用于验证删除索引后,对sql查询的影响,语法如下
alter table tablename alter index indexname invisible/visible;
索引函数化
索引函数就是字段加了函数的索引,这里的函数也可以是表达式。所以也叫表达式索引 例子如下:
create index price_function_index on orderinfo((from_unixtime(times,'%Y-%m-%d')))

边栏推荐
猜你喜欢
还在纠结报表工具的选型么?来看看这个
![[Software Architecture Mode] The difference between MVVM mode and MVC mode](/img/37/8470ff9267752d4ca26a6b54ec0b50.png)
[Software Architecture Mode] The difference between MVVM mode and MVC mode
Parsing MySQL Databases: "SQL Optimization" vs. "Index Optimization"
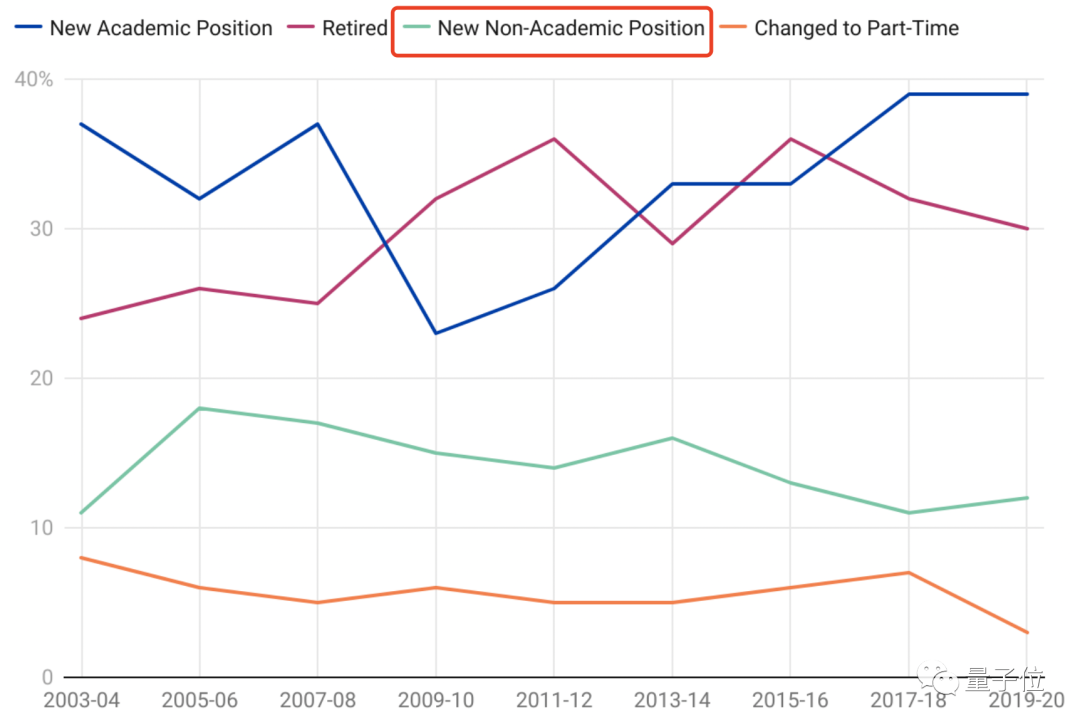
报告:想学AI的学生数量已涨200%,老师都不够用了

sqlserver怎么查询一张表中同人员的交叉日期

shell脚本------条件测试 if语句和case分支语句
【应用推荐】常见资源管理器整理,含个人使用体验和产品选型推荐

Explain / Desc 执行计划分析
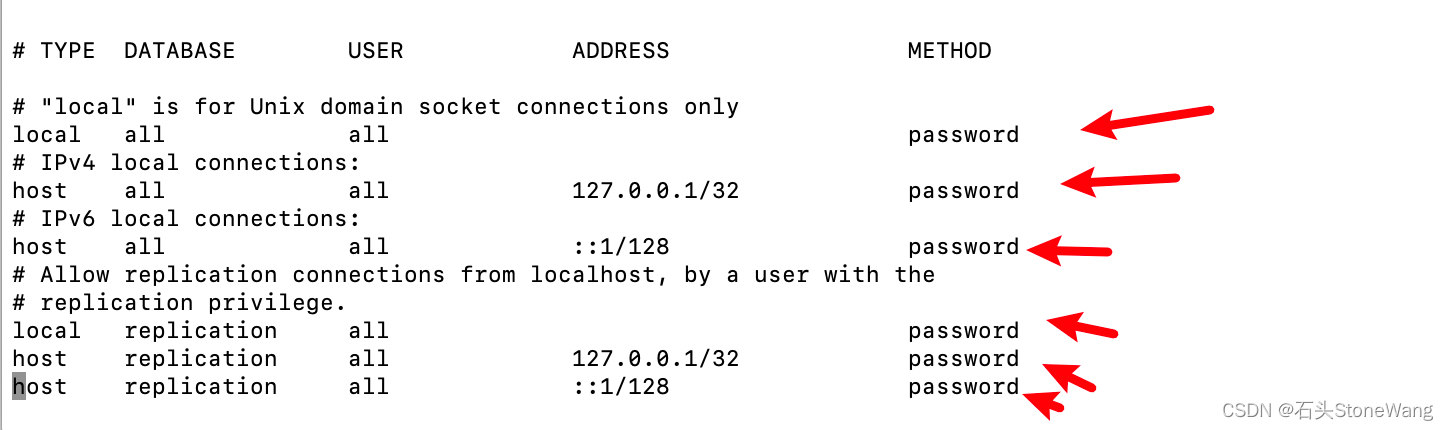
MacOS下postgresql(pgsql)数据库密码为什么不需要填写或可以乱填写

node 格式化时间的传统做法与高级做法(moment)
随机推荐
Google Earth Engine APP——15行代码搞定一个inspector高程监测APP
可视化——Superset安装与部署
SkiaSharp's WPF self-painted five-ring bouncing ball (case version)
sql server, FULL mode, dbcc shrinkfile(2,1) can not shrink the transaction log, or the original size, why?
node 格式化时间的传统做法与高级做法(moment)
笔记。。。。
基于ModelArts的物体检测YOLOv3实践【玩转华为云】
杨辉三角(c语言实现)
数仓分层简介(实时数仓架构)
Lsky Pro 企业版手动升级、优化教程
SkiaSharp 之 WPF 自绘 五环弹动球(案例版)
2022年7月31日--使用C#迈出第一步--使用 C# 创建具有约定、空格和注释的易读代码
50.【Application of dynamic two-dimensional array】
Analysis of High Availability Solution Based on MySql, Redis, Mq, ES
STM32个人笔记-嵌入式C语言优化
MySQL 必现之死锁
微信公众号授权登录后报redirect_uri参数错误的问题
C语言程序设计50例(三)(经典收藏)
Three chess (C language implementation)
高级驾驶辅助系统ADAS简介