当前位置:网站首页>Oracle concept II
Oracle concept II
2022-06-27 16:37:00 【_ Become popular_】

There are two kinds of people in the world
Those who are brave and responsible and those who look for support
The backer is better
----《Scent of a Woman》
Catalog
5、 ... and .connect by recursive
1、rank()/dense_rank() over(partition by ...order by ...)
2、min()/max() over(partition by ...)
3、lead()/lag() over(partition by ... order by ...)
lead() It's after taking N Row data
lag() It's before taking N Row data
One .pivot function
Transfer line column .
I met a business in my work , A column of data is required ( This column usually has different types , For example, county , Subjects, etc ) Convert to multiple columns to display , It can also be said to be row to column .
quote : Blog
Student transcript , The original data :
select class_name, student_name, course_type, result, created_date
from class_tmp_2;
Each student's two grades , There are two pieces of data , Because business requires , When showing it to the user , The user wants only one piece of data for each student , And show all the results , such as

In this case, the row specific column function is required PIVOT.
SELECT class_name, student_name, Chinese language and literature , mathematics , created_date
FROM (SELECT CLASS_NAME, STUDENT_NAME, COURSE_TYPE, RESULT, CREATED_DATE
FROM CLASS_TMP_2) T
PIVOT(SUM(RESULT)
FOR COURSE_TYPE IN(' Chinese language and literature ' AS Chinese language and literature , ' mathematics ' AS mathematics ));Light gray sql And the original data above sql equally , Mainly look at the back PIVOT part .
sum(result): Sum of achievements (PIVOT The aggregate function is required )
for course_type in (' Chinese language and literature ' as Chinese language and literature , ' mathematics ' as mathematics ): take course_type Column Field values are converted to column names , among , The field value is ' Chinese language and literature ', Convert to language column , The field value is ' mathematics ', Convert to mathematical column , The field values of these two columns , I.e. the one in front sum(result).
This example belongs to the same class , Therefore, you can also use the following sub query to realize
select t1.class_name,
t1.student_name,
t1.result Chinese language and literature ,
t2.result mathematics ,
t1.created_date
from (select a.class_name,
a.student_name,
a.course_type,
a.result,
a.created_date
from class_tmp_2 a
where a.course_type = ' Chinese language and literature ') t1,
(select a.class_name,
a.student_name,
a.course_type,
a.result,
a.created_date
from class_tmp_2 a
where a.course_type = ' mathematics ') t2
where t1.class_name = t2.class_name
and t1.student_name = t2.student_name;Two .unpivot function
Column turned .
The original data are as follows :

The desired results are as follows

in other words , If there are multiple columns to be found in the database, they will be displayed in multiple rows according to the fact that they are all placed in the same column , Their corresponding data is put into another category , That is, below result, Use this function .
select class_name, student_name, course_type, result, created_date
from class_tmp
unpivot(result for course_type in(chinese_result,math_result));explain :
Original data chinese_result Column sum math_result The column name of the column ( Light grey ), Convert to new column course_type The field values of the , Indicates the class type .
Original data chinese_result Column sum math_result Column's field value , Convert to new column result The field values of the , It's a score .
3、 ... and .with as
with as The phrase , Also called subquery part , Is to define a sql fragment , This piece is in the whole big sql It is often used in sentences , Then its use is limited to --- Used multiple times , Business scenarios with a small amount of data , increase sql Readability , Reduce the number of meter scanning ( This one uses F5 You can directly see whether it is the base table or the temporary table in memory ), Reduce code rewriting ;with as Is equivalent to a temporary table in memory , So he quickly , He has good performance , So the amount of data cannot be very large ;
grammar :
The main way of writing :
with query1 AS
(select ...from ....where ..),
query2 AS
(select...from ...where..),
query3 AS
(select...from ...where..)
SELECT ...FROM query1,quer2,query3
where ....;such as :
with
e as
(select * from scott.emp),
d as
(select * from scott.dept)
select * from e, d where e.deptno = d.deptno;Another example is multiple union all:
with
sql1 as
(select to_char(a) s_name from test_tempa),
sql2 as
(select to_char(b) s_name
from test_tempb
where not exists (select s_name from sql1 where rownum = 1))
select * from sql1
union all
select * from sql2
union all .. .. ..Four .leading function
/*+LEADING(TABLE)*/ /*+LEADING(table1,table2....)*/
Make the specified table the first table in the link order ,leading Prompt can be followed by multiple table names , It is used to represent in related table associations , Which table is used as the driving table . Use leading After the prompt , The optimizer will no longer consider from The order of the following table .
Simply put, it specifies which is the driver table , It is usually a small watch ; sometimes oracle The optimizer will specify the large table as the driving table , This increases the number of scans ;
For example, I met a business recently , Due to confidentiality requirements , Similar statements are as follows
select a...
from A a
left join B b
on a.id = b.id
inner join C c
on a.id = c.id
inner join D d
on a.id = d.idid yes ABCD The primary keys of the four tables , So this means that there are indexes , So, after looking at the scanning plan, I found A And B All tables are full table scanning ,B surface cost Longer time consuming , The total time is 45 Seconds or so ,A The table data has 100 strip ,B Table has 30 Ten thousand ;
In view of the above phenomenon , The first optimization direction is to make B Table mandatory index , So the optimization is as follows :
select /*+index(B)*/ a...
from A a
left join B
on a.id = b.id
inner join C c
on a.id = c.id
inner join D d
on a.id = d.idLooking at the implementation plan, we find that B The table is indexed , So the speed suddenly reached 0.2 second .
Continue with the example above , In fact, the final optimization is like this :
select /*+leading(A B) index(B)*/ a...
from A a
left join B
on a.id = b.id
inner join C c
on a.id = c.id
inner join D d
on a.id = d.idBe careful : If ⼀ Tables have indexes ,⼀ Tables have no indexes ,ORACLE The table without index will be used as the driving table . If both tables have indexes , The outer surface is used as the driving table . If both are not indexed , Is also the appearance of the driving table . Consider using... At this time leading Function to specify according to the scan plan .
5、 ... and .connect by recursive
Basic grammar
select t.*,level from table t [start with condition1]
connect by [prior] id=parentidThis function is generally used to find data with parent-child relationship , Tables with hierarchical relationships ;
start with condition1 It is used to limit the data of the first layer , Or root node data ; Based on this part of data, find the second layer data , Then use the second layer data to find the third layer data, and so on .
and connect by prior id=parentid perhaps connect by id=prior parentid What's the difference ?
Let's give you an example :
Make a data , Take Naoki hamazawa as an example :
-- Create table
create table BANK
(
id NUMBER(8) not null,
funcid NUMBER(8),
parentid NUMBER(8),
funcname VARCHAR2(20),
parentname VARCHAR2(20)
);
insert into BANK (FUNCID, PARENTID, FUNCNAME, PARENTNAME)
values (1001, 0, ' President Nakano Watanabe ', null);
insert into BANK (FUNCID, PARENTID, FUNCNAME, PARENTNAME)
values (1002, 1001, ' Sanli, vice president ', ' President Nakano Watanabe ');
insert into BANK (FUNCID, PARENTID, FUNCNAME, PARENTNAME)
values (1003, 1002, ' Executive of Ohata ', ' Sanli, vice president ');
insert into BANK (FUNCID, PARENTID, FUNCNAME, PARENTNAME)
values (1005, 1003, ' Minister izoshan ', ' Executive of Ohata ');
insert into BANK (FUNCID, PARENTID, FUNCNAME, PARENTNAME)
values (1006, 1005, ' Hanzawa Naoki ', ' Minister izoshan ');
insert into BANK (FUNCID, PARENTID, FUNCNAME, PARENTNAME)
values (1007, 1003, ' Duzhen Li Ren ', ' Executive of Ohata ');
insert into BANK (FUNCID, PARENTID, FUNCNAME, PARENTNAME)
values (1004, 1002, ' The chronicle is standing ', ' Sanli, vice president ');
commit;The query is shown in the figure , The hierarchical relationship is : governor - Vice President of the - Standing - The minister - Worker

This is often used at work , For example, some tables store data about organizational relationships , Some of them are the menu on the left , If you need to use the organization table in a complex business, you will usually use this .
For the above Syntax , There's a keyword in it prior, This can be on the left and right of the equal sign ,level You can have it or not , It is only used to indicate which level the row data belongs to .
select t.*,level from tablename t
start with Conditions 1
connect by prior Subfield id= Parent field id
where Conditions 3;If it's on the left , The query is the leaf node based on condition one ;
If it's on the right , The upper nodes based on condition one are checked .
On the left
from 1001 Start , Query its child nodes ;
select t.*,level from bank t
start with t.funcid=1001
connect by prior t.funcid=t.parentid
order by funcid;
On the right
check 1001 The parent node of the start , So there's only one piece of data ;
select t.*, level
from bank t
start with t.funcid = 1001
connect by t.funcid = prior t.parentid
order by funcid;
6、 ... and .keep function
keep yes oracle An analysis function under ,Oracle In order to solve the problem of querying the maximum value in the subset , Put forward KEEP() grammar , That is to say Take the same group and sort by a certain field , Take the minimum or maximum value for the specified field .
The grammar is as follows :
min | max(column1) keep (dense_rank first | last order by column2) over (partion by column3);
Examples are as follows : Build a watch , Use the top with as Create a temporary table as follows :
WITH workers AS(
SELECT 'DOM1' dept, 'zhangsan' names , 23 age, 4000 salaries FROM dual UNION ALL
SELECT 'DOM1' dept, 'lisi' names , 35 age, 9000 salaries FROM dual UNION ALL
SELECT 'DOM2' dept, 'wangwu' names , 26 age, 6500 salaries FROM dual UNION ALL
SELECT 'DOM2' dept, 'maliu' names , 28 age, 6000 salaries FROM dual UNION ALL
SELECT 'DOM2' dept, 'zhaoqi' names , 26 age, 5000 salaries FROM dual UNION ALL
SELECT 'DOM1' dept, 'liba' names , 23 age, 3000 salaries FROM dual
)
select * from workers;Enquiries are as follows

Business objectives : Get the youngest person in the Department , A record of highest wages ;
Then you can use keep(dense_rank first/last) To deal with it , Replace the above sf..works, such as
SELECT w.dept,
max(w.salaries) KEEP(dense_rank first order by w.age) max_salary
FROM workers w
GROUP BY dept;
intend Check the largest salary by age , Because this is the youngest , So use the first, If the oldest , use last;
explain
1.keep It means “ keep ”, Records that meet the conditions in parentheses will be maintained , use order by There will naturally be first and last 了 , This is also a fixed way of writing ;
2.dense_rank It is a sort policy , This is generally the default ;
3.first/last Is to filter the data , Here we sift age Minimum record ;
4. Due to the use of aggregate functions , So finally we need to have group by;
7、 ... and .over function
grammar :rank()/dense_rank over(partition by A order by B)
over Is an analytic function , According to the fields A Partition the results , Sort by field within each partition ;
over Not to be used alone , Need and row_number(),rank() and dense_rank,lag() and lead(),sum() And so on
explain :
- over() On what conditions ;
- partition by Group by which field ;
- order by Sort by which field ;
Be careful :
- Use rank()/dense_rank() when , You have to bring order by Otherwise it's illegal ;
- rank(): Jump order , If there are two first levels , Next is the third level .
- dense_rank(): Sequential order , If there are two first levels , Next is still the second level .
for instance :
Create a table and insert data :
create table EMP
(
empno NUMBER(4) not null,
ename VARCHAR2(10),
job VARCHAR2(9),
mgr NUMBER(4),
hiredate DATE,
sal NUMBER(7,2),
comm NUMBER(7,2),
deptno NUMBER(2)
)
alter table EMP
add constraint PK_EMP primary key (EMPNO);
insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7369, 'SMITH', 'CLERK', 7902, to_date('17-12-1980', 'dd-mm-yyyy'), 800, null, 20);
insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7499, 'ALLEN', 'SALESMAN', 7698, to_date('20-02-1981', 'dd-mm-yyyy'), 1600, 300, 30);
insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7521, 'WARD', 'SALESMAN', 7698, to_date('22-02-1981', 'dd-mm-yyyy'), 1250, 500, 30);
insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7566, 'JONES', 'MANAGER', 7839, to_date('02-04-1981', 'dd-mm-yyyy'), 2975, null, 20);
insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7654, 'MARTIN', 'SALESMAN', 7698, to_date('28-09-1981', 'dd-mm-yyyy'), 1250, 1400, 30);
insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7698, 'BLAKE', 'MANAGER', 7839, to_date('01-05-1981', 'dd-mm-yyyy'), 2850, null, 30);
insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7782, 'CLARK', 'MANAGER', 7839, to_date('09-06-1981', 'dd-mm-yyyy'), 2450, null, 10);
insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7788, 'SCOTT', 'ANALYST', 7566, to_date('19-04-1987', 'dd-mm-yyyy'), 3000, null, 20);
insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7839, 'KING', 'PRESIDENT', null, to_date('17-11-1981', 'dd-mm-yyyy'), 5000, null, 10);
insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7844, 'TURNER', 'SALESMAN', 7698, to_date('08-09-1981', 'dd-mm-yyyy'), 1500, 0, 30);
insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7876, 'ADAMS', 'CLERK', 7788, to_date('23-05-1987', 'dd-mm-yyyy'), 1100, null, 20);
insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7900, 'JAMES', 'CLERK', 7698, to_date('03-12-1981', 'dd-mm-yyyy'), 950, null, 30);
insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7902, 'FORD', 'ANALYST', 7566, to_date('03-12-1981', 'dd-mm-yyyy'), 3000, null, 20);
insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7934, 'MILLER', 'CLERK', 7782, to_date('23-01-1982', 'dd-mm-yyyy'), 1300, null, 10); The query is shown in the figure :

1、rank()/dense_rank() over(partition by ...order by ...)
Business one : Ask for information about the highest paid employees in each department
The common expression is :
select *
from (select ename full name ,
job occupation ,
hiredate Date of entry ,
e.sal Wages ,
e.deptno department
from emp e,
(select deptno, max(sal) sal from emp group by deptno) t
where e.deptno = t.deptno
and e.sal = t.sal)
order by department ; 
Use over Function is :
select empno, ename, job, hiredate, sal, deptno
from (select empno,
ename,
job,
hiredate,
sal,
deptno,
rank() over(partition by deptno order by sal desc) r
from emp)
where r = 1;
select empno, ename, job, hiredate, sal, deptno
from (select empno,
ename,
job,
hiredate,
sal,
deptno,
dense_rank() over(partition by deptno order by sal desc) r
from emp)
where r = 1 The results of these two operations are consistent with the above ,
By Department (deptno) After partition, according to the salary (sal) Sort from top to bottom , Then each district only takes one result, that is, the maximum wage ;
another : If you want to inquire about the minimum wage ,desc Change it to asc that will do ;
2、min()/max() over(partition by ...)
Business II : Query employee information and calculate employee salary and department maximum / The difference in the minimum wage
Be careful :min/max no need order by
The common expression is :
select ename full name ,
job occupation ,
hiredate Date of entry ,
e.deptno department ,
e.sal Wages ,
e.sal - me.min_sal Minimum difference ,
me.max_sal - e.sal Maximum difference
from emp e,
(select deptno, min(sal) min_sal, max(sal) max_sal
from emp
group by deptno) me
where e.deptno = me.deptno
order by e.deptno, e.sal;
Use over by :
select ename full name ,
job occupation ,
hiredate Date of entry ,
deptno department ,
sal Wages ,
min(sal) over(partition by deptno) Departmental minimum wage ,
max(sal) over(partition by deptno) The highest salary in the Department ,
nvl(sal - min(sal) over(partition by deptno), 0) Departmental minimum wage difference ,
nvl(max(sal) over(partition by deptno) - sal, 0) The maximum wage difference of the Department
from emp
order by deptno, sal; 
Inquire about Difference The results are consistent with the common , And less than the code above ;
If you look at the code scanning results on both sides ? As shown in the figure below :

And the bottom only went through a full table scan

So to sum up the comparison , It can be optimized according to business requirements .
Say something else :
Why not order by sal 了 ?
order by The default is asc Sort from small to large , Write the query as follows
select ename full name ,
job occupation ,
hiredate Date of entry ,
deptno department ,
sal Wages ,
min(sal) over(partition by deptno order by sal) Departmental minimum wage ,
max(sal) over(partition by deptno order by sal) The highest salary in the Department ,
nvl(sal - min(sal) over(partition by deptno order by sal), 0) Departmental minimum wage difference ,
nvl(max(sal) over(partition by deptno order by sal) - sal, 0) The maximum wage difference of the Department
from emp
order by deptno, sal; 
The personal salary is actually the same as the maximum salary of the Department , Then the difference is 0, The reason is not clear , Remember to use min/max Wait for the aggregate function over The field of this aggregation cannot be used in order by, That means you don't have to write order by 了 .
3、lead()/lag() over(partition by ... order by ...)
First of all lead function , No leading;
These two functions , Is an offset function ;
Its purpose is : You can find out the next or previous value corresponding to each line of records in the same field .
lead() It's after taking N Row data
select ename full name ,
job occupation ,
hiredate Date of entry ,
deptno department ,
sal Wages ,
lead(sal) over(order by deptno) Offset 1,
lead(sal,2) over(order by deptno) Offset 2
from emp
order by deptno, sal;
Pictured , For example, the offset is 1 It's from The first 2 OK, we're going to start with 14 That's ok this N Row data , So it is called after taking N That's ok ;
- lead(column,num,flag)
- col_name Is the column name ;num Is the value below the orientation ;flag It's a sign , That is, if the lower value is null, it will be taken as flag;
- for example lead(column,1,null) This is to take a value down , If this value is empty, it will be calculated as null , Of course, you can also replace with other values .
lag() It's before taking N Row data
select ename full name ,
job occupation ,
hiredate Date of entry ,
deptno department ,
sal Wages ,
lag(sal) over(order by deptno) Offset 1,
lag(sal,2,0) over(order by deptno) Offset 2
from emp
order by deptno, sal;
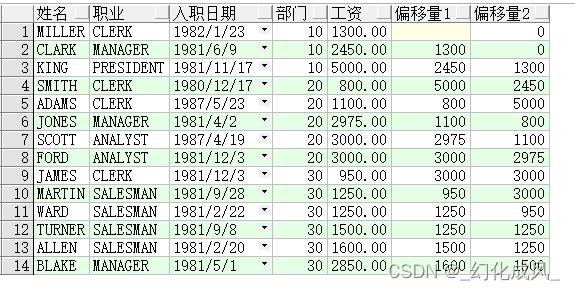
Pictured , For example, the offset is 1 It's from The first 13 OK, we're going to start with 1 That's ok this N Row data , So it's called "before taking" N That's ok ;
Okay , Now let's explain the business problem :
Business three : Calculate the personal salary under the same department and one higher than yourself / The difference of one lower salary
select ename full name ,
job occupation ,
sal Wages ,
deptno department ,
lead(sal, 1, 0) over(partition by deptno order by sal) The last person whose salary is higher than his own ,
lag(sal, 1, 0) over(partition by deptno order by sal) The last person whose salary is lower than his own ,
nvl(lead(sal) over(partition by deptno order by sal) - sal, 0) A difference higher than one's salary ,
nvl(sal - lag(sal) over(partition by deptno order by sal), 0) A difference lower than one's salary
from emp;
The function has been described , Do not explain ;
Then list some common ways to write collocation aggregate functions
select ename full name , job occupation , sal Wages , deptno department ,
first_value(sal) over(partition by deptno) first_sal,
last_value(sal) over(partition by deptno) last_sal,
min(sal) over(partition by deptno) min_sal,
max(sal) over(partition by deptno) max_sal,
sum(sal) over(partition by deptno) Total Department salary ,
avg(sal) over(partition by deptno) Department average wage ,
count(1) over(partition by deptno) Total number of departments ,
row_number() over(partition by deptno order by sal) Serial number
from emp; 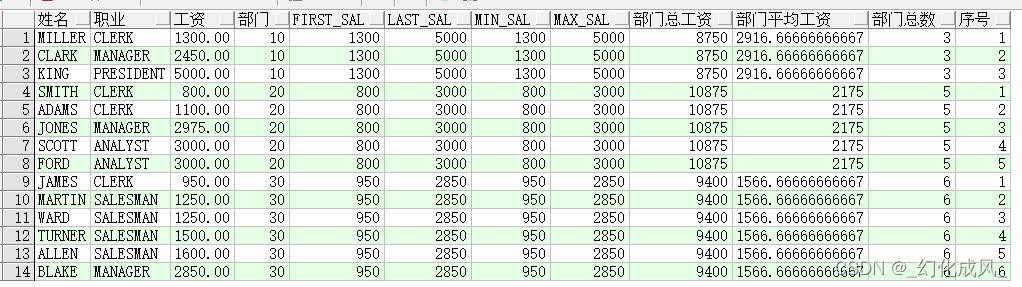
Excerpt from Blog And made a more detailed description
边栏推荐
- Mode setting of pulseaudio (21)
- [pyGame games] this "eat everything" game is really wonderful? Eat them all? (with source code for free)
- The two trump brand products of Langjiu are resonating in Chengdu, continuously driving the consumption wave of bottled liquor
- 泰山OFFICE技术讲座:第一难点是竖向定位
- Four characteristics of transactions
- LeetCode每日一练(杨辉三角)
- #yyds干货盘点# 解决剑指offer:二叉树中和为某一值的路径(三)
- Oracle概念三
- 基于 Nebula Graph 构建百亿关系知识图谱实践
- Smart wind power | Tupu software digital twin wind turbine equipment, 3D visual intelligent operation and maintenance
猜你喜欢










随机推荐
tensorflow求解泊松方程
Jialichuang EDA professional edition all offline client release
Cesium realizes satellite orbit detour
A robot is located in the upper left corner of an M x n grid. The robot can only move down or right one step at a time. The robot attempts to reach the lower right corner of the grid. How many differe
Google Earth Engine(GEE)——Export. image. The difference and mixing of toasset/todrive, correctly export classification sample data to asset assets and references
P. Simple application of a.r.a method in Siyuan (friendly testing)
Raspberry pie preliminary use
Use redis to automatically cancel orders within 30 minutes
【Pygame小遊戲】這款“吃掉一切”遊戲簡直奇葩了?通通都吃掉嘛?(附源碼免費領)
The role of the symbol @ in MySQL
LeetCode每日一练(无重复字符的最长子串)
Leetcode daily practice (main elements)
国家食品安全风险评估中心:不要盲目片面追捧标签为“零添加”“纯天然”食品
字节跳动埋点数据流建设与治理实践
Can polardb-x be accessed through the client of related tools as long as the client supporting JDBC / ODBC protocol is afraid?
#yyds干货盘点# 解决剑指offer:二叉树中和为某一值的路径(三)
Array represents a collection of several intervals. Please merge all overlapping intervals and return a non overlapping interval array. The array must exactly cover all the intervals in the input. 【Le
Autodesk Navisworks 2022软件安装包下载及安装教程
Leetcode daily practice (Yanghui triangle)
QT5.5.1桌面版安装配置过程中的疑难杂症处理(配置ARM编译套件)