当前位置:网站首页>21 Days of Deep Learning - Convolutional Neural Networks (CNN): Weather Recognition (Day 5)
21 Days of Deep Learning - Convolutional Neural Networks (CNN): Weather Recognition (Day 5)
2022-08-05 09:13:00 【Qingyuan Warm Song】
目录
2.1.1 image_dataset_from_directory()
活动地址:CSDN21天学习挑战赛
学习:深度学习100例-卷积神经网络(CNN)天气识别 | 第5天_K同学啊的博客-CSDN博客
一、前期准备
1.1 设置GPU
import tensorflow as tf
gpus = tf.config.list_physical_devices("GPU")
if gpus:
gpu0 = gpus[0] #如果有多个GPU,仅使用第0个GPU
tf.config.experimental.set_memory_growth(gpu0, True) #设置GPU显存用量按需使用
tf.config.set_visible_devices([gpu0],"GPU")
1.2 导入数据
import matplotlib.pyplot as plt
import os,PIL
# 设置随机种子尽可能使结果可以重现
import numpy as np
np.random.seed(1)
# 设置随机种子尽可能使结果可以重现
import tensorflow as tf
tf.random.set_seed(1)
from tensorflow import keras
from tensorflow.keras import layers,models
import pathlib
# Write to the path where the data folder is located
data_dir = "D:/jupyter notebook/DL-100-days/datasets/weather_photos/"
data_dir = pathlib.Path(data_dir) # 创建了pathpath object相关资料:Python 的 os.path() 和 pathlib.Path()_Looooking的博客-CSDN博客
1.2.1 np.random.seed( i )
参考:np.random.seed()Random number seed study notes_Occasionally lay flat salted fish blog-CSDN博客
①随机数种子相当于给我们一个初值,之后按照固定顺序生成随机数(该随机数种子对应的list);如果使用相同的seed( )值,则每次生成的随机数列表都相同;
②如果不设置这个值,则系统根据时间来自己选择这个值,此时每次生成的随机数因时间差异而不同.
③设置seed()的时,可以调用多次random()向该随机数的列表中添加信息;而再次使用设置的seed()值时,仅一次有效,也就是说调用第二次random()时则脱离该随机数的列表.
④seed方法设立的目的是为了能够实现实验的可重复进行,得到相同的随机值结果.
The initial value of this setting has no practical significance
np.random.seed(0) # 先定义一个随机数种子
print(np.random.rand(2, 3)) # 随机生成1个 2×3 的矩阵所以,np.random.seed(0) Each time only works on the random number generated next time,Different initial values generate different random numbers,Call the same initial value,生成的随机数是相同的
如
np.random.seed(0) # 先定义一个随机数种子
print(np.random.rand(2, 3)) # 随机生成1个 2×3 的矩阵
np.random.seed(0) # 先定义一个随机数种子
print(np.random.rand(2, 3)) # 随机生成1个 2×3 的矩阵输出的两个结果相同
1.2.2 tf.random.set_seed()
上面写法是tensorflow2.0的写法,如果是tensorflow1.0则为:set_random_seed()
#tensorflow2.0
tf.random.set_seed(
seed
)
#tensorflow1.0
tf.set_random_seed(
seed
)下面以 tf.set_random_seed(i)为例,用法一致
参考:
tf.random.set_seed用法_A blog of benevolence, righteousness, courtesy, wisdom, and integrity-CSDN博客_tf.set_random_seed 和TensorflowSeed for random number generationtf.set_random_seed()_qq_31878983的博客-CSDN博客_tensorflow 随机种子
用法与 np.random.seed(0) 相近,但分 全局种子 和 操作种子 两种
1.3 查看数据
# 返回 data.dir All suffixes in the folder and all subfolders are .jpgThe length of the formed list
image_count = len(list(data_dir.glob('*/*.jpg')))
print("图片总数为:",image_count)
图片总数为: 1125
# Return to all under this folder sunrise +后面任意 且后缀为.jpg的列表
roses = list(data_dir.glob('sunrise/*.jpg'))
PIL.Image.open(str(roses[0])) # Open the first picture
All returned are paths,因为PIL.Image.open()Dedicated image path,Used to directly read the image pointed to by this path.The required path must specify which graph to go to,It can't just be the folder where all the graphs are;

二、数据预处理
2.1 加载数据
使用 image_dataset_from_directory() 方法将磁盘中的数据加载到 tf.data.Dataset 中
batch_size = 32
img_height = 180
img_width = 180
"""
关于image_dataset_from_directory()的详细介绍可以参考文章:https://mtyjkh.blog.csdn.net/article/details/117018789
"""
train_ds = tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="training",
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)
Found 1125 files belonging to 4 classes.
Using 900 files for training.
"""
关于image_dataset_from_directory()的详细介绍可以参考文章:https://mtyjkh.blog.csdn.net/article/details/117018789
"""
val_ds = tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="validation",
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)
Found 1125 files belonging to 4 classes.
Using 225 files for validation.
2.1.1 image_dataset_from_directory()
tf.keras.preprocessing.image_dataset_from_directory(
directory,
labels="inferred",
label_mode="int",
class_names=None,
color_mode="rgb",
batch_size=32,
image_size=(256, 256),
shuffle=True,
seed=None,
validation_split=None,
subset=None,
interpolation="bilinear",
follow_links=False,
)
See the big guy article for details:tf.keras.preprocessing.image_dataset_from_directory() 简介_K同学啊的博客-CSDN博客_tf.keras.preprocessing.image
Only the parameters used are shown here:
- directory: 数据所在目录.如果标签是
inferred(默认),则它应该包含子目录,每个目录包含一个类的图像.否则,将忽略目录结构.
- validation_split: 0和1之间的可选浮点数,可保留一部分数据用于验证.That is, the proportion of the selected test set to the total number of data sets
- subset:
training或validation之一.仅在设置validation_split时使用.
- seed: 用于shuffle和转换的可选随机种子.
- image_size: 从磁盘读取数据后将其重新调整大小.默认:
(256,256).由于管道处理的图像批次必须具有相同的大小,因此该参数必须提供.
- batch_size: 数据批次的大小.默认值:
32
2.1.2 batch_size
表示The number of parameters passed to the program for training at a time.比如我们的训练集有1000个数据.这是如果我们设置batch_size=100,那么程序首先会用数据集中的前100个参数,即第1-100个数据来训练模型.当训练完成后更新权重,再使用第101-200的个数据训练,直至第十次使用完训练集中的1000个数据后停止.
其他参考:机器学习中的batch_size是什么?_Diligent panda blog-CSDN博客_batch size是什么意思
2.2 可视化数据
plt.figure(figsize=(20, 10))
for images, labels in train_ds.take(1):
for i in range(20):
ax = plt.subplot(5, 10, i + 1)
plt.imshow(images[i].numpy().astype("uint8"))
plt.title(class_names[labels[i]])
plt.axis("off")
2.3 再次检查数据
for image_batch, labels_batch in train_ds:
print(image_batch.shape)
print(labels_batch.shape)
break
Image_batch是形状的张量(32,180,180,3).这是一批形状180x180x3的32张图片(最后一维指的是彩色通道RGB).
Label_batch 是形状(32,)的张量,这些标签对应32张图片
2.4 配置数据集
shuffle():打乱数据,关于此函数的详细介绍可以参考:https:llzhuanlan.zhihu.com/p/42417456
prefetch():预取数据,加速运行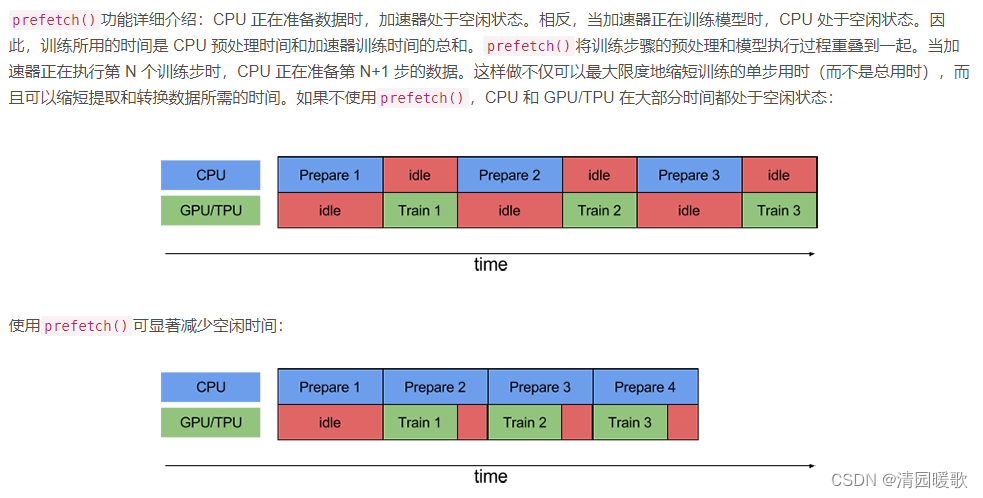
cache():将数据集缓存到内存当中,加速运行
AUTOTUNE = tf.data.AUTOTUNE
train_ds = train_ds.cache().shuffle(1000).prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
三、构建CNN、编译、训练、评估
Because it's not much different from before,所以直接放代码了
3.1 构建CNN
num_classes = 4
"""
If you don't understand the calculation of the convolution kernel, you can refer to the article:https://blog.csdn.net/qq_38251616/article/details/114278995
layers.Dropout(0.4) 作用是防止过拟合,提高模型的泛化能力.
In the previous article Flower Identification,The huge difference between training accuracy and validation accuracy is due to model overfitting
关于Dropout层的更多介绍可以参考文章:https://mtyjkh.blog.csdn.net/article/details/115826689
"""
model = models.Sequential([
layers.experimental.preprocessing.Rescaling(1./255, input_shape=(img_height, img_width, 3)),
layers.Conv2D(16, (3, 3), activation='relu', input_shape=(img_height, img_width, 3)), # 卷积层1,卷积核3*3
layers.AveragePooling2D((2, 2)), # 池化层1,2*2采样
layers.Conv2D(32, (3, 3), activation='relu'), # 卷积层2,卷积核3*3
layers.AveragePooling2D((2, 2)), # 池化层2,2*2采样
layers.Conv2D(64, (3, 3), activation='relu'), # 卷积层3,卷积核3*3
layers.Dropout(0.3),
layers.Flatten(), # Flatten层,连接卷积层与全连接层
layers.Dense(128, activation='relu'), # 全连接层,特征进一步提取
layers.Dense(num_classes) # 输出层,输出预期结果
])
model.summary() # 打印网络结构
Dropout层 tf.keras.layers.Dropout() 介绍_K同学啊的博客-CSDN博客_keras.layers.dropout
关于 layers.experimental.preprocessing.Rescaling 查看官方文档tf.keras.layers.Rescaling | TensorFlow Core v2.9.1,A preprocessing layer that rescales the input values to the new range
The pooling layer is adjusted from the previous max pooling layer to an average pooling layer
3.2 编译
# 设置优化器
opt = tf.keras.optimizers.Adam(learning_rate=0.001)
model.compile(optimizer=opt,
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
还是 adam 优化器,However, the learning rate is set
3.3 训练模型
epochs = 10
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=epochs
)
3.4 模型评估
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs_range = range(epochs)
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
边栏推荐
- Neuron Newsletter 2022-07|新增非 A11 驱动、即将支持 OPC DA
- 国际原子能机构总干事称乌克兰扎波罗热核电站安全形势堪忧
- Creo 9.0 基准特征:基准点
- 请问大佬们 ,使用 Flink SQL CDC 是不是做不到两个数据库的实时同步啊
- sql server收缩日志的作业和记录,失败就是因为和备份冲突了吗?
- Pagoda measurement - building small and medium-sized homestay hotel management source code
- Creo 9.0 基准特征:基准坐标系
- 让程序员崩溃的N个瞬间(非程序员误入)
- Comprehensively explain what is the essential difference between GET and POST requests?Turns out I always misunderstood
- C语言-数组
猜你喜欢
只有一台交换机,如何实现主从自动切换之nqa

施一公:科学需要想象,想象来自阅读
Example of Noise Calculation for Amplifier OPA855
How to make a puzzle in PS, self-study PS software photoshop2022, PS make a puzzle effect
XCODE12 在使用模拟器(SIMULATOR)时编译错误的解决方法

科普大佬说 | 港大黄凯斌老师带你解锁黑客帝国与6G的关系

动态内存开辟(C语言)
express hot-reload

Comprehensively explain what is the essential difference between GET and POST requests?Turns out I always misunderstood
Spark cluster deployment (third bullet)
随机推荐
干货!生成模型的评价与诊断
DPU — 功能特性 — 管理系统的硬件卸载
my journal link
DPU — 功能特性 — 安全系统的硬件卸载
上海控安技术成果入选市经信委《2021年上海市网络安全产业创新攻关成果目录》
The color of life divine
sphinx匹配指定字段
eKuiper Newsletter 2022-07|v1.6.0:Flow 编排 + 更好用的 SQL,轻松表达业务逻辑
512-color chromatogram
Excuse me, guys, is it impossible to synchronize two databases in real time using Flink SQL CDC?
画法几何及工程制图考试卷A卷
只有一台交换机,如何实现主从自动切换之nqa
DPU — 功能特性 — 存储系统的硬件卸载
Detailed explanation of DNS query principle
love is a sad song
k-nearest neighbor fault monitoring based on multi-block information extraction and Mahalanobis distance
网页直接访问链接不让安全中心拦截
我的杂记链接
Assembly language (8) x86 inline assembly
seata源码解析:TM RM 客户端的初始化过程