当前位置:网站首页>干货!生成模型的评价与诊断
干货!生成模型的评价与诊断
2022-08-05 09:02:00 【AITIME论道】
点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!

深度生成模型的巨大成功需要量化工具来衡量它们的统计性能。Divergence frontiers 最近被提议作为生成模型的评估框架,因为它们能够衡量深度生成模型固有的质量与多样性权衡。
我们对divergence frontiers的样本复杂度做出了非渐进的分析。我们还引入了frontier integral,它提供了divergence frontier的 summary statistic。
我们展示了诸如 Good-Turing 或 Krichevsky-Trofimov 之类的平滑估计器如何克服质量缺失问题,从而拥有更快的收敛速度。我们用自然语言处理和计算机视觉的数据来验证我们的理论结果。
本期AI TIME PhD直播间,我们邀请到美国华盛顿大学博士生——刘浪,为我们带来报告分享《生成模型的评价与诊断》。

刘浪:
美国华盛顿大学统计博士在读,主要研究方向是最优传输距离和信息散度在生成模型和统计推断中的应用。
Image and Text Generation
在生成模型之中,有两个比较常见的失败情况。一种是生成的数据High quality but low variety,即每一张生成的人脸都非常像真正的人,但是互相之间又非常相似。另一种情况是Low quality but high variety,即看每一张图片可能不会感觉有多逼真,但是却能组成一个diverse的数据集。
Type I and Type II Costs in Generative Modeling
为了描述这两种失败情况,我们引入了两类损失。
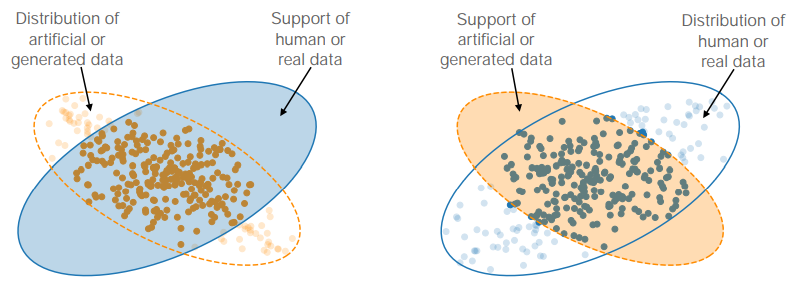
其中,上图中的左图,蓝色区域表示真实数据的分布,橙色椭圆表示的是生成数据的分布。对于每一个生成的数据点,如果它不在真实数据分布上,就表示这些点没有那么逼真,也被称作一类损失。对于上图中的右图,如果真实数据没有在生成数据的分布上,就会被称作二类损失,因为他们一定不会被我们的模型生成。
有了两类损失的概念,我们就能够用来描述之前失败的案例。比如High quality ,就表示大部分生成的数据点都在真实数据分布上,即一类损失比较小。如果是low variety,就表示生成的数据只能cover一小部分真实数据,即二类损失比较大。
下一个问题就是如何量化这两类损失?假设P是真实数据分布,Q是生成数据分布,那么KL(Q||P)会在Q大P小的时候比较大,所以可以作为第一类损失的量化,而KL(P||Q)用于量化第二类损失。
这其中也隐藏着问题,如果Q和P没有相同的support,那么结果可能是无穷大。
Divergence Frontiers for Generative Models
为了解决上述问题,我们考虑采用混合分布R,比如P<<r and="" q<<r<="" span="">。
之后,我们可以用KL(Q||R)和KL(P||R)替代KL(Q||P)和KL(P||Q)来进行量化损失。
在选择R上,我们可以考虑如下优化问题,我们考虑对两类损失进行线性组合,然后选择R使得这个线性组合的结果最小。
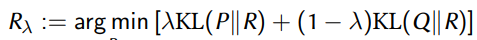
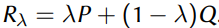
在有了上述理论基础之后,我们可以考虑去定义Divergence Frontiers,如下图所示:
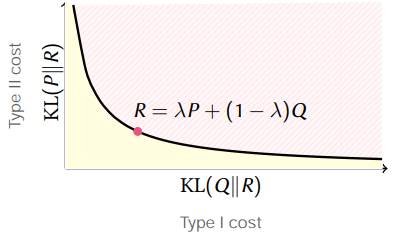
如果我们考虑P和Q的线性组合,便可以得到上图的曲线。其他R都是在曲线之上,这个曲线的概念就叫做Divergence Frontiers。
而在本研究中,我们想解决的问题是在用数据估计 Divergence Frontiers的时候,怎样才能做的更好?我们是否可以对估计的精度进行理论的刻画。
Statistical Summary of Divergence Frontiers
第一步,我们先提出一个summary statistic,考虑两类损失的线性组合。
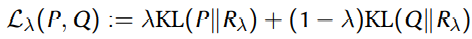
然后对线性组合的cost做积分。我们把这个积分就叫做Frontier integral。
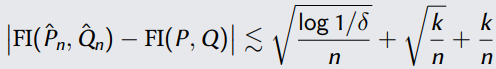
● FI(P, Q) = FI(Q, P) and FI(P, Q) = 0 iff P = Q.
● Frontier integral的取值一定会在[0,1]
Estimation Procedure of Divergence Frontiers
我们接下来看一下实际工作中,研究者们都是如何估计Divergence Frontiers的。
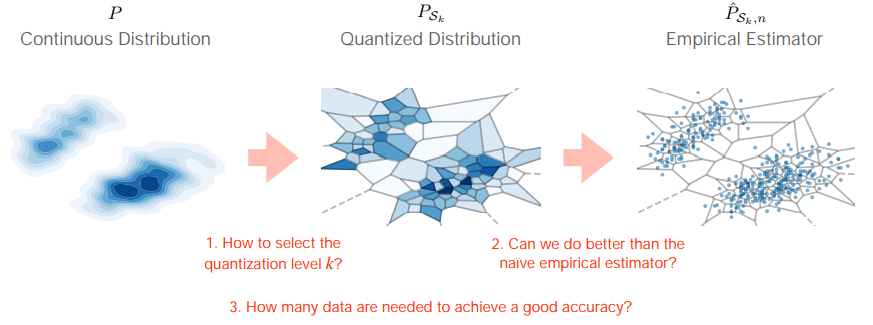
首先,假设P是一个连续分布,然后经quantization处理使其分成不同的k个组并得到Quantized Distribution。接下来,我们会用数据处理得到Empirical Estimator。整个过程之中,我们提出了上图中三个问题:
1. How to select the quantization level k?
2. Can we do better than the naïve empirical estimator?
3. How many data are needed to achieve a good accuracy?
接下来,我们将对以上三个问题进行解答。
Main Results
● Theorem (Statistical Error)
假设我们的分布P和Q都是离散的,他们落在
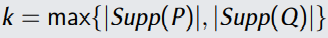
个点上。这个假设的有效性,在于之前我们进行了quantization操作。在这种情况下,我们可以证明,在至少1 − δ概率时,有以下公式成立:

如上图所示,如果这个分布具有较长的tail,那么也有可能在尾部的一些mass是不会出现在sample中的。这样就会对我们的分析产生很大的挑战,这也就要求我们单独去考虑missing mass。如果我们不单独考虑它,得到的rate就会更慢。
● Theorem (Total Error)
第二个结果是对于任意的分布P和Q,可以是连续或离散的。对于任意一个正整数k,我们可以证明一定存在一个partition Sk使得以下公式成立:
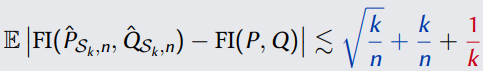
我们选择k,使得上式左面的式子上限最小,也就是我们理论上推荐的k选择。这样就回答了问题1。同时,不等式右边的上限也可以作为目标精度来回答问题3。
● Theorem (Smoothed Distribution Estimators)
Add-constant estimator:
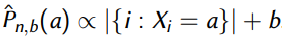
对于每个a,我们会数一数这个a在我们的样本中出现了多少次,然后加上一个小的常数b。对于这样的estimator,可以证明存在更好的上界。
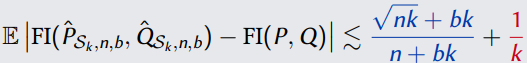

如果我们取b=1/2,我们每一个a都会有positive的mass,这样missing mass'的问题也就不会存在。这也就是为什么我们可以得到一个更优的上界。
Experimental Results
接下来,我们来看两组实验。
目标:Investigate smoothed distribution estimators on image and text data。
● Train a StyleGAN on CIFAR-10.
● Train a GPT-2 on Wikitext-103.
下图中,我们比较了三个不同的distribution estimators。
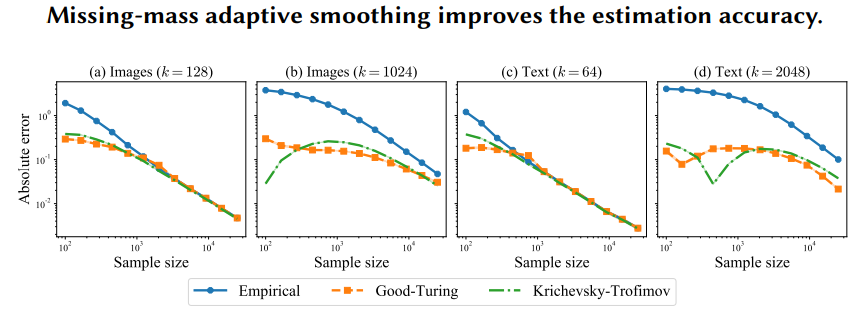
可以看到在4种情况下,smoothed distribution estimators确实会表现更好。
在第二组实验中,我们研究推荐的The quantization level k ∝ n^{1/3}是否在实践中也表现较好。
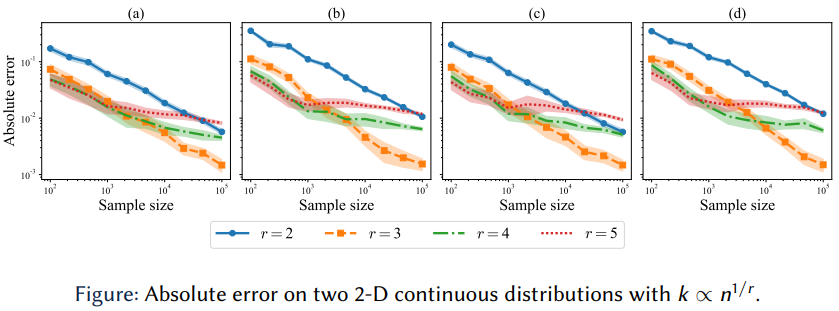
为了解决这个问题,我们选择了两个二维的连续分布,选择的quantization level是正比于k∝n1/r。r可以从2取到5,发现r=3的时候表现最好,而此时也恰好是我们推荐的k的选法。
提
醒
论文题目:
Divergence Frontiers for Generative Models: Sample Complexity, Quantization Effects, and Frontier Integrals
论文链接:
https://arxiv.org/abs/2106.07898
点击“阅读原文”,即可观看本场回放
整理:林 则
作者:刘 浪
往期精彩文章推荐

记得关注我们呀!每天都有新知识!
关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了700多位海内外讲者,举办了逾300场活动,超260万人次观看。

我知道你
在看
哦
~

点击 阅读原文 查看回放!
边栏推荐
猜你喜欢
只有一台交换机,如何实现主从自动切换之nqa
How to replace colors in ps, self-study ps software photoshop2022, replace one color of a picture in ps with another color
Creo 9.0 基准特征:基准坐标系

国际原子能机构总干事称乌克兰扎波罗热核电站安全形势堪忧
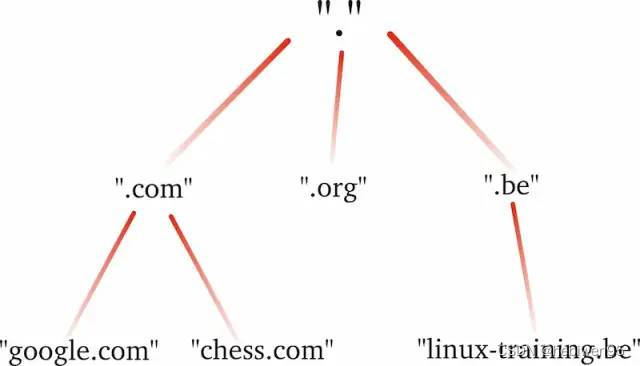
Detailed explanation of DNS query principle
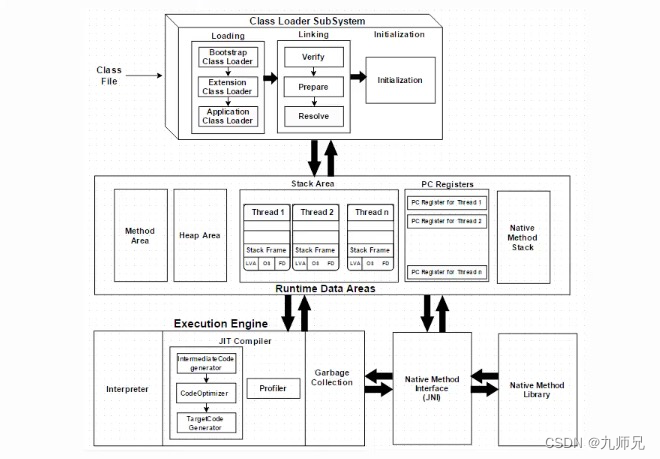
【ASM】字节码操作 方法的初始化 Frame

“充钱”也难治快手的“亏亏亏”?
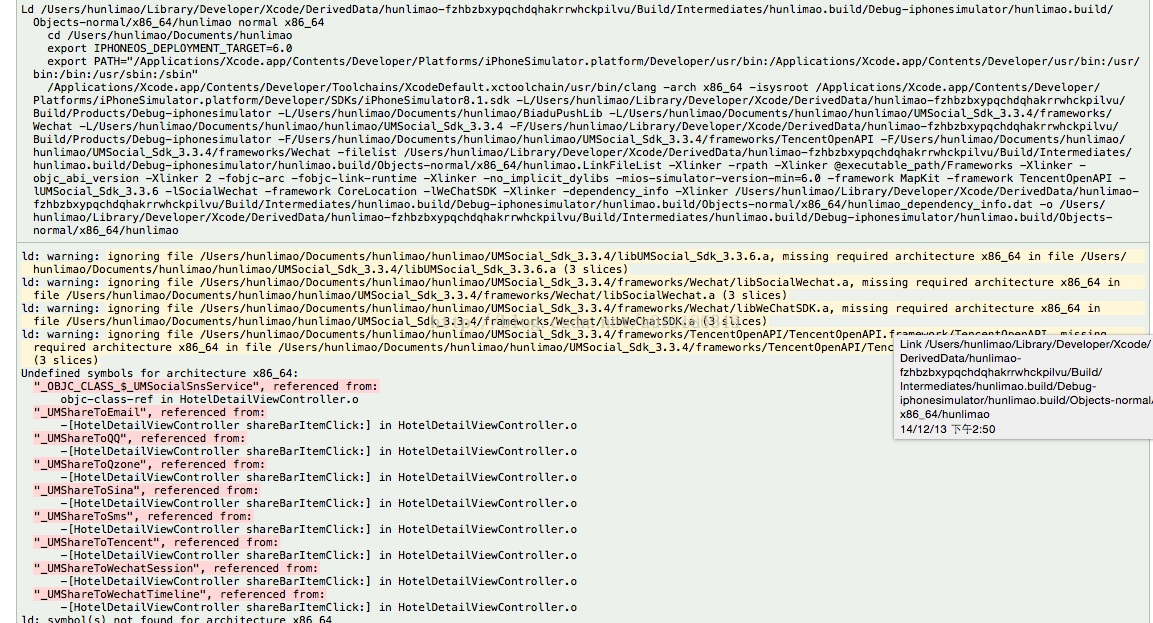
Undefined symbols for architecture arm64解决方案
ps怎么替换颜色,自学ps软件photoshop2022,ps一张图片的一种颜色全部替换成另外一种颜色
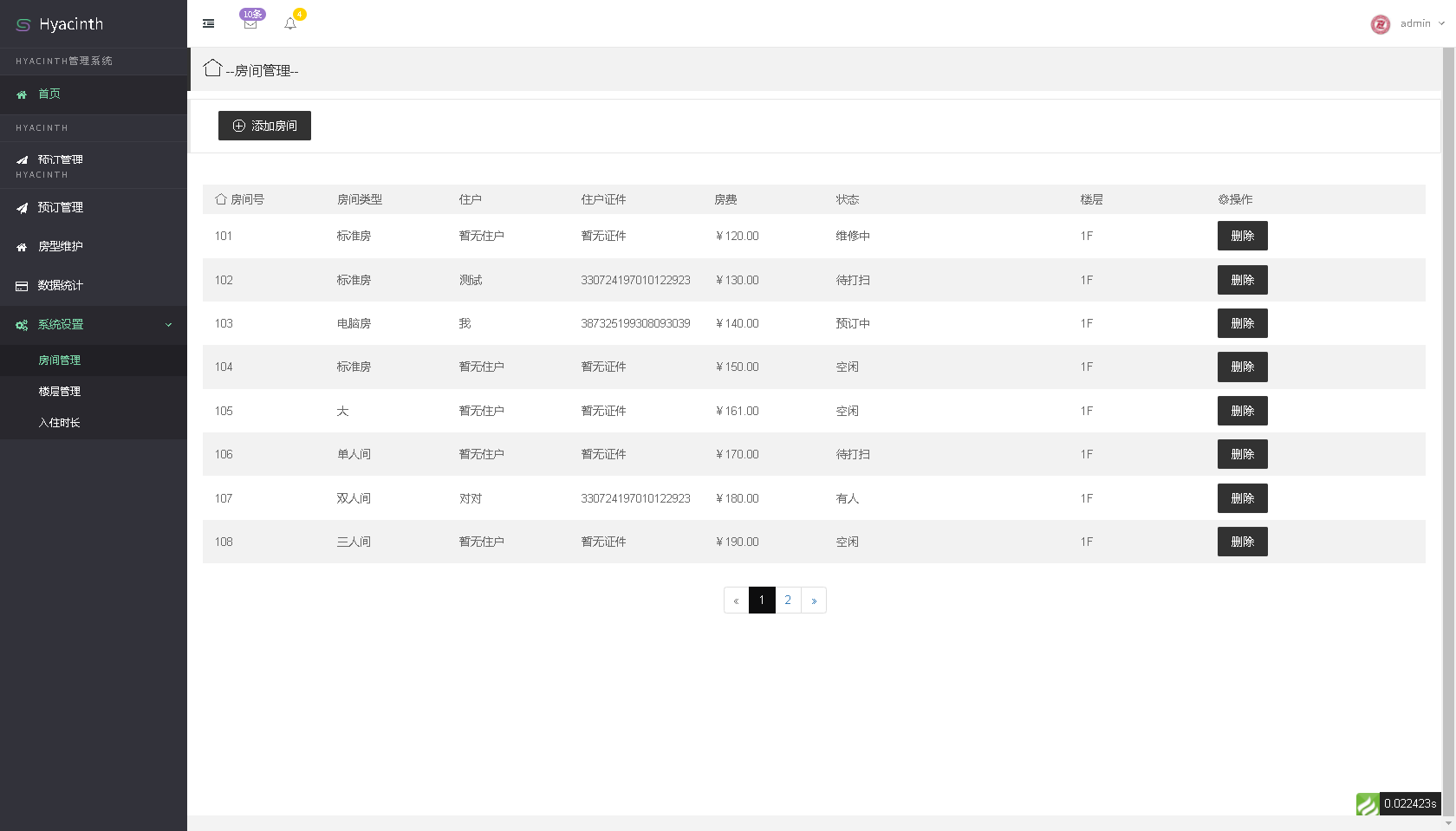
宝塔实测-搭建中小型民宿酒店管理源码
随机推荐
【Excel实战】--图表联动demo_001
树状数组模版+例题
Redis cache and existing problems--cache penetration, cache avalanche, cache breakdown and solutions
让硬盘更快,让系统更稳定
Luogu P3368: 【模板】树状数组 2
随机码的生成
Overall design and implementation of Kubernetes-based microservice project
DPU — 功能特性 — 安全系统的硬件卸载
How to replace colors in ps, self-study ps software photoshop2022, replace one color of a picture in ps with another color
基于 Kubernetes 的微服务项目整体设计与实现
16种香饭做法全攻略
pnpm 是凭什么对 npm 和 yarn 降维打击的
按钮上显示值的轮流切换
Three solutions to solve cross-domain in egg framework
Moonbeam团队发布针对整数截断漏洞的紧急安全修复
Why is pnpm hitting npm and yarn dimensionality reduction?
leetcode points to Offer 10- I. Fibonacci sequence
Hbuilder 学习使用中的一些记录
ps怎么替换颜色,自学ps软件photoshop2022,ps一张图片的一种颜色全部替换成另外一种颜色
【无标题】目录