当前位置:网站首页>机器学习文本分类
机器学习文本分类
2022-08-01 23:42:00 【东方】
机器学习文本分类~
这个是 贝叶斯的,
之前在B站学过knn的,
联想之前自己的毕设 所有的机器学习模型都用到过。
参考自己以前写过各种机器学习算法的优缺点
然后把原理弄懂,都做一个文本分类模型。
具体的代码在知乎
知乎大佬一步到位给出了多种机器学习方法
手把手教你在Python中实现文本分类(附代码、数据集) - 清华大学大数据研究中心的文章 - 知乎
https://zhuanlan.zhihu.com/p/37157010
但是这个是英文的数据集,唉就非常遗憾 ,本来都准备复现了来着。。。郁闷
。
所以说我决定先把这个搞懂,之后再去看知乎那一篇,试着换成中文看看。
接下来复现 这个大佬的,私聊要到了源码(数据放在百度网盘了)。
有部分看不懂的结合B站的视频,明天互补一下弄懂。
他的代码
#!D:/workplace/python
# -*- coding: utf-8 -*-
# @File : TFIDF_svm_wy.py
# @Author: WangYe
# @Date : 2020/11/29
# @Software: PyCharm
# 机器学习之文本分类(附带训练集+数据集+所有代码)
# 博客链接:https://blog.csdn.net/qq_28626909/article/details/80382029
from sklearn.multiclass import OneVsRestClassifier #结合SVM的多分类组合辅助器
import sklearn.svm as svm #SVM辅助器
import jieba
from numpy import *
import os
from sklearn.feature_extraction.text import TfidfTransformer # TF-IDF向量转换类
from sklearn.feature_extraction.text import CountVectorizer #词频矩阵
def readFile(path):
with open(path, 'r', errors='ignore',encoding='gbk') as file: # 文档中编码有些问题,所有用errors过滤错误
content = file.read()
file.close()
return content
def saveFile(path, result):
with open(path, 'w', errors='ignore',encoding='gbk') as file:
file.write(result)
file.close()
def segText(inputPath):
data_list = []
label_list = []
fatherLists = os.listdir(inputPath) # 主目录
for eachDir in fatherLists: # 遍历主目录中各个文件夹
eachPath = inputPath +"/"+ eachDir + "/" # 保存主目录中每个文件夹目录,便于遍历二级文件
childLists = os.listdir(eachPath) # 获取每个文件夹中的各个文件
for eachFile in childLists: # 遍历每个文件夹中的子文件
eachPathFile = eachPath + eachFile # 获得每个文件路径
content = readFile(eachPathFile) # 调用上面函数读取内容
result = (str(content)).replace("\r\n", "").strip() # 删除多余空行与空格
cutResult = jieba.cut(result) # 默认方式分词,分词结果用空格隔开
# print( " ".join(cutResult))
label_list.append(eachDir)
data_list.append(" ".join(cutResult))
return data_list,label_list
def getStopWord(inputFile):
stopWordList = readFile(inputFile).splitlines()
return stopWordList
def getTFIDFMat(train_data,train_label, stopWordList): # 求得TF-IDF向量
class0 = ''
class1 = ''
class2 = ''
class3 = ''
for num in range(len(train_label)):
if train_label[num]=='体育':
class0 = class0 + train_data[num]
elif train_label[num]=='女性':
class1 = class1 + train_data[num]
elif train_label[num]=='文学出版':
class2 = class2+ train_data[num]
elif train_label[num]=='校园':
class3 = class3 + train_data[num]
train = [class0,class1,class2,class3]
vectorizer = CountVectorizer(stop_words=stopWordList, min_df=0.5) # 其他类别专用分类,该类会将文本中的词语转换为词频矩阵,矩阵元素a[i][j] 表示j词在i类文本下的词频
transformer = TfidfTransformer() # 该类会统计每个词语的tf-idf权值
cipin = vectorizer.fit_transform(train)
tfidf = transformer.fit_transform(cipin) # if-idf中的输入为已经处理过的词频矩阵
model = OneVsRestClassifier(svm.SVC(kernel='linear'))
train_cipin = vectorizer.transform(train_data)
train_arr = transformer.transform(train_cipin)
clf = model.fit(train_arr, train_label)
while 1:
print('请输入需要预测的文本:')
a = input()
sentence_in = [' '.join(jieba.cut(a))]
b = vectorizer.transform(sentence_in)
c = transformer.transform(b)
prd = clf.predict(c)
print('预测类别:',prd[0])
#
if __name__ == '__main__':
data,label = segText('data')
stopWordList = getStopWord('stop/stopword.txt') # 获取停用词表
getTFIDFMat(train_data=data,train_label=label,stopWordList=stopWordList)
下面这些不是很懂,仔细研究一下。
vectorizer = CountVectorizer(stop_words=stopWordList, min_df=0.5) # 其他类别专用分类,该类会将文本中的词语转换为词频矩阵,矩阵元素a[i][j] 表示j词在i类文本下的词频
transformer = TfidfTransformer() # 该类会统计每个词语的tf-idf权值
cipin = vectorizer.fit_transform(train)
tfidf = transformer.fit_transform(cipin) # if-idf中的输入为已经处理过的词频矩阵
model = OneVsRestClassifier(svm.SVC(kernel='linear'))
train_cipin = vectorizer.transform(train_data)
train_arr = transformer.transform(train_cipin)
clf = model.fit(train_arr, train_label)
还有一些需要研究一下第三方的库的方法,然后逐行解释。
里面用到的两个主要的类详细讲解。
这篇很详细了,
但是有个小问题,我要编码的文本动词非常重要,默认单个字不会切分出来。
这篇很好的解决了问题
边栏推荐
猜你喜欢

2022 6th Strong Net Cup Part WP

使用Jenkins做持续集成,这个知识点必须要掌握

UML diagram of soft skills

cmd command
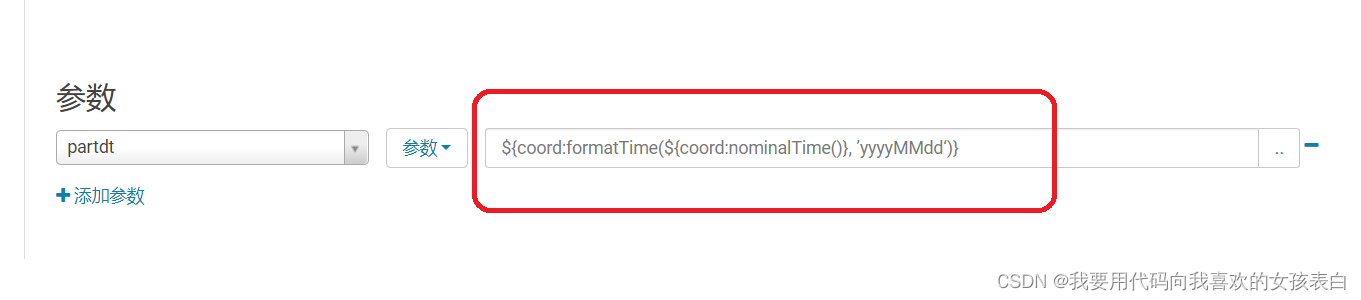
Appears in oozie on CDH's hue, error submitting Coordinator My Schedule

sys_kill系统调用

oozie startup error on cdh's hue, Cannot allocate containers as requested resource is greater than maximum allowed
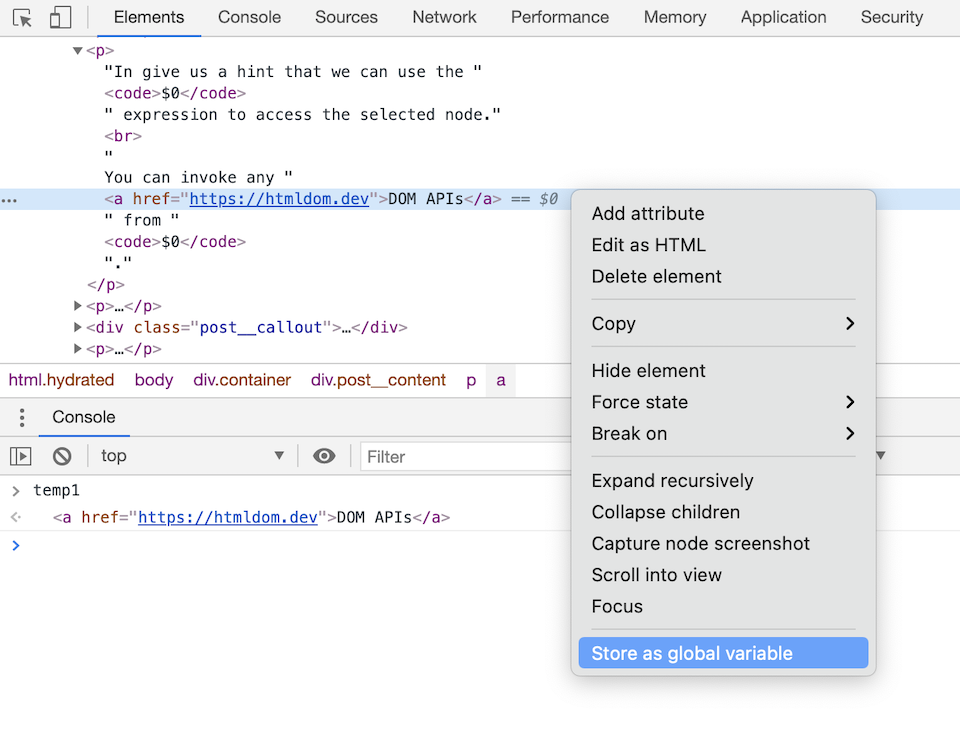
访问控制台中的选定节点

CDH6的Hue打开出现‘ascii‘ codec can‘t encode characters
CDH6 Hue to open a "ASCII" codec can 't encode characters
随机推荐
Department project source code sharing
ELK log collection
解决端口占用
计算两点之间的中点
斜堆、、、
访问控制台中的选定节点
【C语言进阶】文件操作(二)
论文理解【RL - Exp Replay】—— Experience Replay with Likelihood-free Importance Weights
软技能之UML图
@WebServlet注解(Servlet注解)
DRF generating serialization class code
加载字体时避免隐藏文本
Appears in oozie on CDH's hue, error submitting Coordinator My Schedule
Chapter 11 Working with Dates and Times
sys_kill system call
计算由两点定义的线的角度
ICLR 2022最佳论文:基于对比消歧的偏标签学习
cdh6 opens oozieWeb page, Oozie web console is disabled.
Loading configuration of Nacos configuration center
分享一份接口测试项目(非常值得练手)