当前位置:网站首页>10. Gradient, activation function and loss
10. Gradient, activation function and loss
2022-07-27 05:59:00 【Pie star's favorite spongebob】
List of articles
gradient
The core concept of neural network , gradient .
Gradient is a vector ,
First of all , The length of the gradient expresses a certain trend , second , The direction of the gradient represents growth ( Great value ) The direction of , Go in the direction of larger and larger functions .
Find the minimum 

αt Generally, the setting is relatively small , The minimum value can be found better .
Except the saddle point of the saddle affects the optimizer , That is, outside the search process , also :
1. The initial state

If your initial value is A spot , Most likely when you arrive x1 when , Stop after getting the local minimum .
2. Learning rate
When our learning rate is relatively large , The step size will be larger , Maybe the next point directly crosses the minimum value to the other side , For some better functions , It may vibrate left and right , Finally, it will converge to the minimum point . But most of the time , Finally, it cannot converge . At first, it's best to set the learning rate lower , for example 0.01,0.001, If it converges , Slowly increase the learning rate , The speed of training will be faster , If it doesn't converge , Continue to reduce the learning rate . Learning rate will also affect the accuracy of training , sometimes , It will constantly vibrate around the minimum , Just can't reach the minimum point , At this time, we need to slowly reduce the learning rate .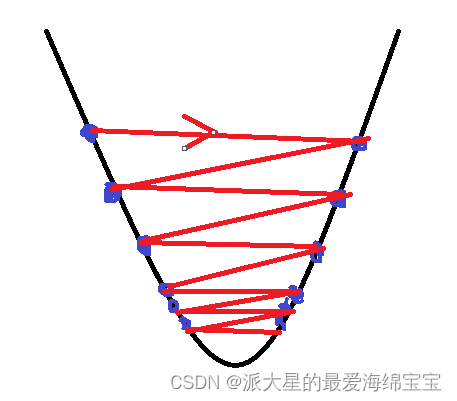
3. momentum ( How to escape the local minimum )
We will add a momentum , This momentum can be understood as an inertia , Help get out of this local minimum .
4.stochastic gradient descent
Change the original mean of all gradients in all data sets into one batch The mean of all gradients on
stochastic
There is a certain randomness , But not really random, Give me a x, Its corresponding f(x) According to a distribution
deterministic
x And f(x) One to one .
Common function gradients
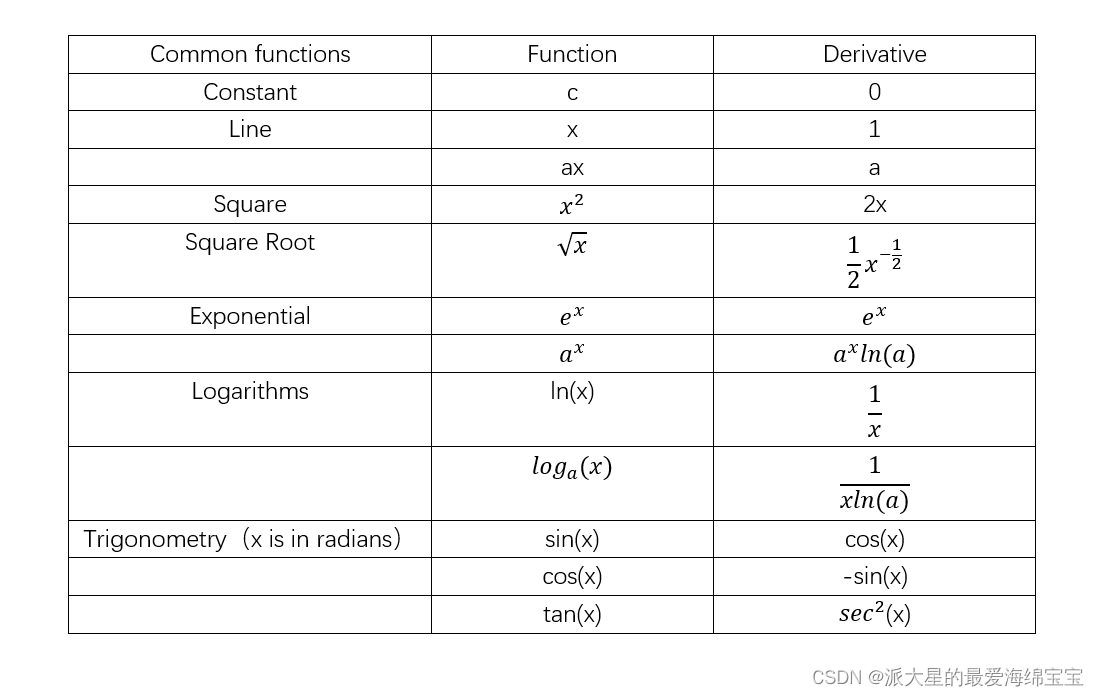
gradient API
Find gradient
1.torch.autograd.gard(loss[w1,w2,…])
loss Yes w Derivation
2.loss.backward()
Go straight ahead w1.grad
Activation function and its gradient
Activation means in x Must be greater than a certain number , Will activate , Output a level value .
There is an important concept of activation function , It's just not derivable . Gradient descent method cannot be used for optimization . Use heuristic search to solve the optimal solution .
1.torch.sigmoid()
It is more suitable to simulate the mechanism of neurons in Biology .Sigmod It's derivable ,
Sigmod derivative =Sigmod(1-Sigmod)
Sigmod The function is continuous and smooth , And the function value is compressed in 0 To 1 Between , probability 、RGB You can use Sigmod function .
shortcoming : Gradient dispersion phenomenon , When seeking the optimal solution , because x Approaching infinity equals 0,loss remain unchanged , So that our optimal solution can not be updated .

import torch
a=torch.linspace(-100,50,10)
print(a)
print(torch.sigmoid(a))

2.torch.tanh()
stay RNN Commonly used .
tanh The derivative of =1-tanh**2
shortcoming : Gradient dispersion phenomenon 

a=torch.linspace(-10,10,10)
print(a)
print(torch.tanh(a))

3.torch.relu()
ReLU(Rectified Linear Unit) It is the activation function of the foundation stone of deep learning , Use the most .
do research First of all relu.
advantage : To some extent, it solved sigmod Gradient discretization of function .
When x Less than 0 Not active when , And the gradient is 0, When x Greater than 0 when , Linear activation , And the gradient is 1. Derivative calculation is very simple , And will not enlarge or shrink .x be equal to 0 when , Generally, the gradient is understood as 0 or 1.

a=torch.linspace(-10,10,10)
print(a)
print(torch.relu(a))

4.softmax
And Cross Entropy Loss Combined activation function .
First , The probability value of each interval is 0 To 1 Between , And the sum of probabilities is equal to 1, Suitable for multi classification problems .
pi Yes aj Derivation , When i=j when , have to pi(1-pj), When i≠j when , have to -pipj.
At first 2 yes 1 Of 2 times , The probability of two values is greater than 2 times , That is, the big one will be bigger , Put the small ones more densely , Make the gap bigger .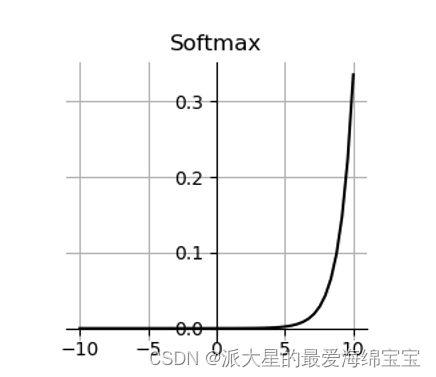
a=torch.rand(3)
p=torch.softmax(a,dim=0)
print(p)
Must write dim.

5.Leaky ReLU
solve :ReLU stay x Less than 0 Time gradient is 0 The situation of 
∝ Very small , And can be in pytorch Set up .
6.SELU
SELU(x)=scale*(max(0,x)+min(0,∝*(exp(x)-1)))
relu=max(0,x)
7.softplus
yes relu Function smooth version , stay 0 The neighborhood is continuous and smooth .

Loss
1.MSE( priority of use )
Mean Square Erro
use torch.norm solve MSE, be torch.norm(y-pred,2)*pow(2), first 2 representative L2.
2.Cross Entropy Loss Cross entropy
1.Cross Entropy Loss
entropy entropy Definition in informatics :
a=torch.full([4],1/4.)
print(a)
print(a*torch.log2(a))
print(-(a*torch.log2(a)).sum())
b=torch.tensor([0.1,0.1,0.1,0.7])
print(-(b*torch.log2(b)).sum())
c=torch.tensor([0.001,0.001,0.001,0.999])
print(-(c*torch.log2(c)).sum())
about a, The growth of these four numbers is the same , The entropy is high , More stable .
about b, The growth of the first three numbers is small , The growth of the last number is relatively high , Entropy is about 1.3568, Unstable .
about c, The first three numbers represent extremely low probability of occurrence , The last one is extremely high , Finally, entropy is 0.0313, If you are the lucky one in these four scores , Is more surprising , Because the probability of this happening is very low .
From top to bottom, it's getting better , Make us move towards our goal .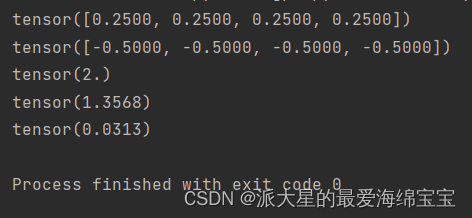

Dkl Find divergence , Judge the overlap of the two .
p=q
When p and q When equal , The cross entropy will be equal to the entropy of a certain distribution
for one-hot encoding
If the distribution is [0,1,0,0], The probability of only this one is 1, be 1log1=0, be H(p)=0.
example
import torch
import torch.nn.functional as F
x=torch.randn(1,784)
w=torch.randn(10,784)
logits=[email protected].t()
print('logits shape',logits.shape)
pred=F.softmax(logits,dim=1)
print('pred shape',pred.shape)
pred_log=torch.log(pred)
print('cross entropy:',F.cross_entropy(logits,torch.tensor([3])))
print('nll_loss after :',F.nll_loss(pred_log,torch.tensor([3])))
logits=xw+b
logits after softmax After the function , obtain pred
pred after log function , obtain pred_log
Use cross entropy, You must use logits,cross entropy hold softmax and log Together .
cross entropy=softman+log+nll_loss,cross entropy It is equivalent to these three operations together .
2.binary classification
f:x->p(y=1|x)
If p(y=1|x)>0.5( Thresholds that have been established ), Forecast as 1, Other conditions are predicted as 0
seek entropy
The objective function is -[ylog(p+(1-y)log(1-p))]
3.muti-class classification
f:x->p(y=y|x)
Multi class :p(y=0|x),p(y=1|x),…,p(y=9|x), The probability of each is 0 To 1, And the total probability value is 1. It can be done by softmax Realization .
3.Hinge Loss
4. Why not choose MSE
On some frontier issues , If cross entropy When you can't , You can choose to use MSE Try
- sigmoid+MSE It is easy to appear gradient dispersion
- cross entropy Bigger , Gradient information is larger , Convergence is faster .
边栏推荐
猜你喜欢

Emoji表情符号用于文本情感分析-Improving sentiment analysis accuracy with emoji embedding

Okaleido launched the fusion mining mode, which is the only way for Oka to verify the current output

Digital image processing Chapter 5 - image restoration and reconstruction

1.PyTorch简介

新冠时空分析——Global evidence of expressed sentiment alterations during the COVID-19 pandemic

Digital image processing -- Chapter 9 morphological image processing
数字图像处理——第九章 形态学图像处理

【好文种草】根域名的知识 - 阮一峰的网络日志

12. Optimization problem practice
Emoji Emoji for text emotion analysis -improving sentimental analysis accuracy with Emoji embedding
随机推荐
12. Optimization problem practice
西瓜书学习笔记---第一、二章
Jenkins build image automatic deployment
GBASE 8C——SQL参考6 sql语法(7)
3. Classification problems - initial experience of handwritten digit recognition
GBASE 8C——SQL参考6 sql语法(15)
Day 8.Developing Simplified Chinese Psychological Linguistic Analysis Dictionary for Microblog
If you encounter oom online, how to solve it?
Digital image processing Chapter 5 - image restoration and reconstruction
GBASE 8C——SQL参考6 sql语法(2)
18.卷积神经网络
Digital image processing -- Chapter 9 morphological image processing
Gbase 8C - SQL reference 4 character set support
视觉横向课题bug1:FileNotFoundError: Could not find module ‘MvCameraControl.dll‘ (or one of it
The LAF protocol elephant of defi 2.0 may be one of the few profit-making means in your bear market
leetcode系列(一):买卖股票
go通过channel获取goroutine的处理结果
GBASE 8C——SQL参考6 sql语法(12)
If the interviewer asks you about JVM, the extra answer of "escape analysis" technology will give you extra points
Day 11. Evidence for a mental health crisis in graduate education