当前位置:网站首页>The Impossible Triangle of NLP?
The Impossible Triangle of NLP?
2022-06-22 04:46:00 【kaiyuan_ sjtu】

author | Prince Changqin
Arrangement | NewBeeNLP
Come and have a look today NLP The Impossible Triangle of the model , And based on this, some future research directions .
Paper: Impossible Triangle: What's Next for Pre-trained Language Models?[1]
PLM The Impossible Triangle of means :
Medium model size (1B following )
SOTA few-shot Ability
SOTA Fine tuning capability
At present all PLM One or more of them are missing . A lot of knowledge is injected into distillation 、 Data to enhance 、Prompt To mitigate these deficiencies , But it brings new workload in practice . This paper provides a future research direction , Break down the task into several key phases to achieve the Impossible Triangle .
The pre training model is well known , But people have not found in small and medium-sized models few-shot even to the extent that zero-shot The ability of , The big model does , But because it is too big, it is very inconvenient in actual use . But the reality is that many times we don't label too much data , Need this kind of few-shot The ability of .
Impossible Triangle
As shown in the figure below :
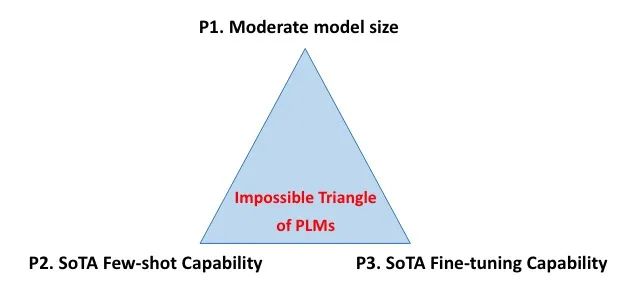
P1 It is used for efficient deployment with reasonable computing resources
P2 Used in scenes with no or a small amount of annotation data
P3 It is used in scenes with relatively large amount of annotation data
A good evidence is Google Recently published PaLM, The paper found that , Model size and few/zero-shot There is a difference between performance Discontinuous The promotion of . for instance , And 8B and 62B Model comparison ,PaLM Of 540B Show breakthrough improvement in many tasks .
For the Impossible Triangle , Actually PLM Can often achieve 1-2 individual :
medium-sized PLM(1B following ):P1+P3
in super-large scale PLM:P2. It is worth noting that :zero/few-shot The effect is still not as good as that of supervision ; In addition, most of the fine-tuning is not as good as the medium size PLM The result of fine tuning ( The reason is probably that the model is too big ).
Current strategy
For model size ( Lack of P1):
In general, the super large model shows excellent zero/few-shot Ability and powerful performance after fine tuning occurs .
The common method is 「 Distillation of knowledge 」.
There are two questions : The student model can hardly achieve the effect of the teacher model ; Too many models hinder effective reasoning , Make it inconvenient as a teacher model .
For the poor zero/few-shot Ability ( Lack of P2):
This is common in medium models : It can be achieved through fine adjustment SOTA, but zero/few-shot Relatively inadequate capacity .
The method is 「 Generate pseudo tags and samples from other models , Or noise injection expansion data 」.
however , The change of pseudo data quality and the diversity of data types in different tasks pose challenges to universally applicable solutions .
Poor supervised training performance ( Lack of P3):
This is typical in the fine-tuning of oversized models , The computing resources are limited or the amount of training data is not enough to fine tune it .
The typical strategy is 「Prompt Study 」, You can use hard prompts ( Discrete text template ) Or soft tips ( Continuous formwork ), So that only the parameters of the hard prompt word or the soft prompt are updated during tuning .
however , The method is right Prompt The selection and training data are particularly sensitive , Still not as good as medium size PLM + Supervised .
Future approaches
This paper presents a multi-stage method .
Stage 1: The goal is to achieve something ( Impossible in the triangle ) Properties needed , Improve missing attributes . such as ,SOTA A supervised medium model can improve few-shot Learning performance ,SOTA few-shot Large models of capabilities are compressed to smaller models with better supervised performance .
Stage 2: Implementation of three attributes PLM Developed for a few tasks . You can take advantage of the unique characteristics of the target task , For example, performance is less dependent on the scale of training data ,zero/few-shot And have a supervised performance gap Smaller, etc .
Stage 3: Based on stage 1 And stages 2, In general NLP Implement three properties on the task . Possible methods include : Pre train a medium-sized model with a large amount of data , Better knowledge distillation , General data enhancement methods, etc .
Although this article is not long , But the entry point is quite interesting , Mitigation strategies for each attribute are also analyzed : Distillation of knowledge 、 Data to enhance 、Prompt Learning, etc. , Based on this, the future research direction , In fact, it seems to be a very natural idea . But this impossible triangle is really interesting .
Communicate together
I want to learn and progress with you !『NewBeeNLP』 At present, many communication groups in different directions have been established ( machine learning / Deep learning / natural language processing / Search recommendations / Figure network / Interview communication / etc. ), Quota co., LTD. , Quickly add the wechat below to join the discussion and exchange !( Pay attention to it o want Notes Can pass )

Resources for this article
[1]
Impossible Triangle: What's Next for Pre-trained Language Models?: https://arxiv.org/abs/2204.06130

边栏推荐
- Accurate identification of bank card information - smart and fast card binding
- How much does it cost to buy a fixed-term life insurance with an insured amount of 500000 at the age of 42? Is there any product recommendation
- fc2新域名有什么价值?如何解析到网站?
- Postman document parameterization
- 爬梯子&&卖卖股份的最佳时期(跑路人笔记)
- Lua exports as an external link library and uses
- 网页设计与制作期末大作业报告——小众音乐网站
- Is the Guoyuan futures account reliable? How can a novice safely open an account?
- 商汤智慧医疗团队研究员解读智慧医疗下的器官图像处理
- Daily question: the difference between ArrayList and LinkedList
猜你喜欢

Windows10 cannot access LAN shared folder

With these websites, do you still worry about job hopping without raising your salary?

How much does it cost to buy a fixed-term life insurance with an insured amount of 500000 at the age of 42? Is there any product recommendation

《数据库原理》期末考试题
ORA-15063: ASM discovered an insufficient number of disks for diskgroup 恢複---惜分飛

厉害了!淮北两企业获准使用地理标志产品专用标志
Postman uses (reads) JSON files for batch testing

cadence allegro 17. X conversion tool for downgrading to 16.6

Lua exports as an external link library and uses

It is easy to analyze and improve R & D efficiency by understanding these five figures
随机推荐
How much does it cost to buy a fixed-term life insurance with an insured amount of 500000 at the age of 42? Is there any product recommendation
Use putty to configure port mapping to realize the access of the external network to the server
The best time to climb a ladder & sell shares (notes of the runner)
Circuit board layout and wiring precautions for analog / digital mixed signals
Interaction between C language and Lua (practice 3)
Mongo fuzzy query, with special characters that need to be escaped, and then query
QML控件类型:SwipeView、PageIndicator
torch DDP Training
爬梯子&&卖卖股份的最佳时期(跑路人笔记)
Golang為什麼不推薦使用this/self/me/that/_this
Disturbed when programmers are programming? Daily anecdotes
【sdx62】QCMAP_ CLI manual dialing instructions
Go 学习笔记
mongo模糊查詢,帶有特殊字符需要轉義,再去查詢
【故障诊断】CUDA kernel errors might be asynchronously reported at some other API call,so the stacktrace b
How to deal with too small picture downloaded from xuexin.com
Es cannot work, circuitbreakingexception
Ora-15063: ASM discovered an insufficient number of disks for diskgroup
Web page design and production final assignment report - College Students' online flower shop
Digital economy Wang Ning teaches you how to correctly choose short-term investment