当前位置:网站首页>程序环境和预处理
程序环境和预处理
2022-07-25 23:46:00 【一只大喵咪1201】
作者:一只大喵咪1201
专栏:《C语言学习》
格言:你只管努力,剩下的交给时间!

程序环境和预处理
程序的翻译环境和执行环境
在标准C语言实现过程中,都存在着俩个环境:
- 翻译环境:将源文件翻译成计算机可以执行的二进制机器码
- 执行环境:执行实际的代码
翻译环境
C语言的翻译环境中包括编译和链接俩个大的环节,接下来本喵给大家详细介绍一下源文件是怎么成为可执行文件的。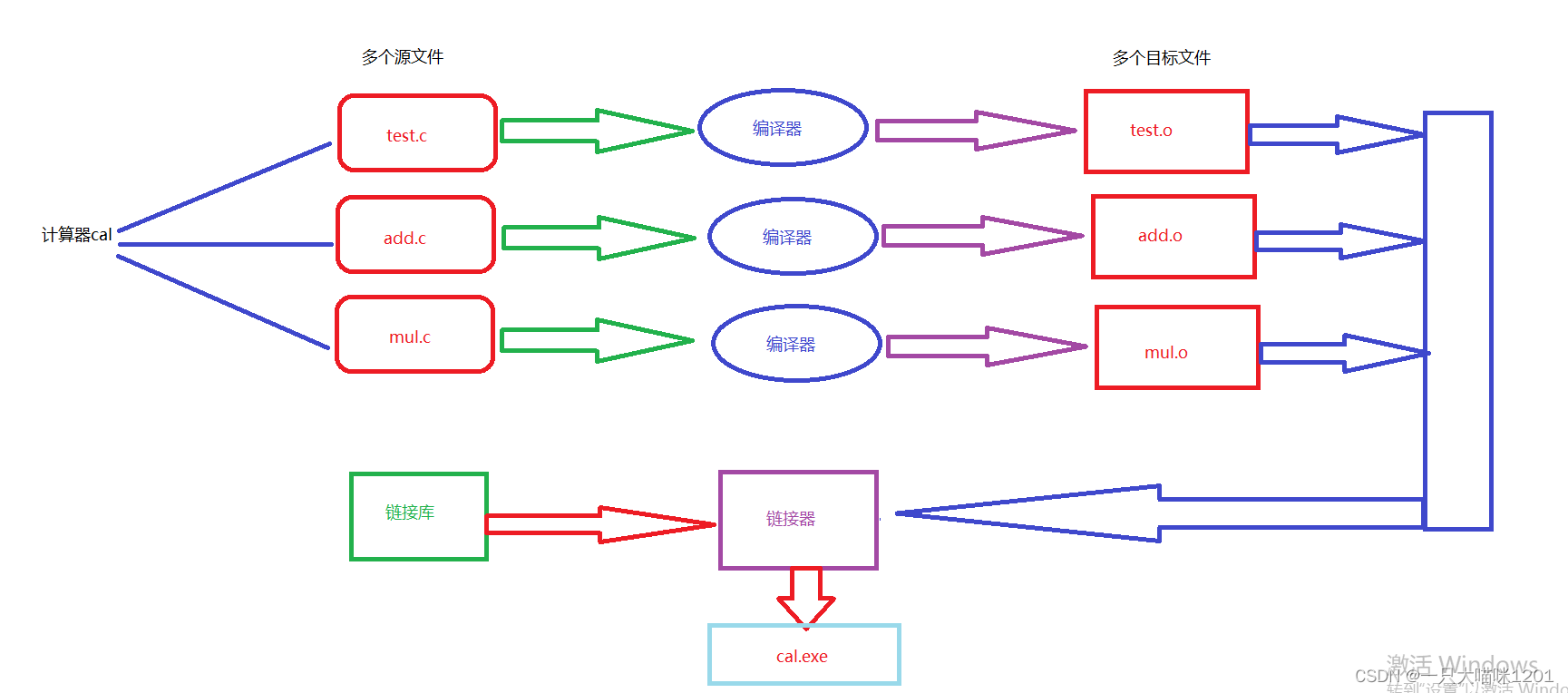
假设我们现在要实现一个计算器,它有加减乘除等功能,参照上图中
- 源文件test.c:包含主要逻辑代码,通过编译器生成目标文件test.o类型的文件。
- 源文件add.c:包含加法功能的代码,通过编译器生成目标文件add.o类型的文件。
- 源文件mul.c:包含乘法功能的代码,通过编译器生成目标文件mul.o类型的文件。
上面的三个源文件分别通过编译器在同时生成目标文件。
- 生成的全部目标文件与使用到的各种库函数捆绑在一起通过链接器生成可执行文件cal.exe
以上便是一个C程序生成可执行程序的大致过程
编译的几个环节
编译同时也被分为几个环节,包括预处理,编译,汇编三个环节,接下来本喵给大家讲解一下在这几个环节中分别干了什么事情。
预处理/预编译
在预处理过后会生成一个test.i的文件,我们来对比一下一段程序的test.c源文件和test.i中有什么不同?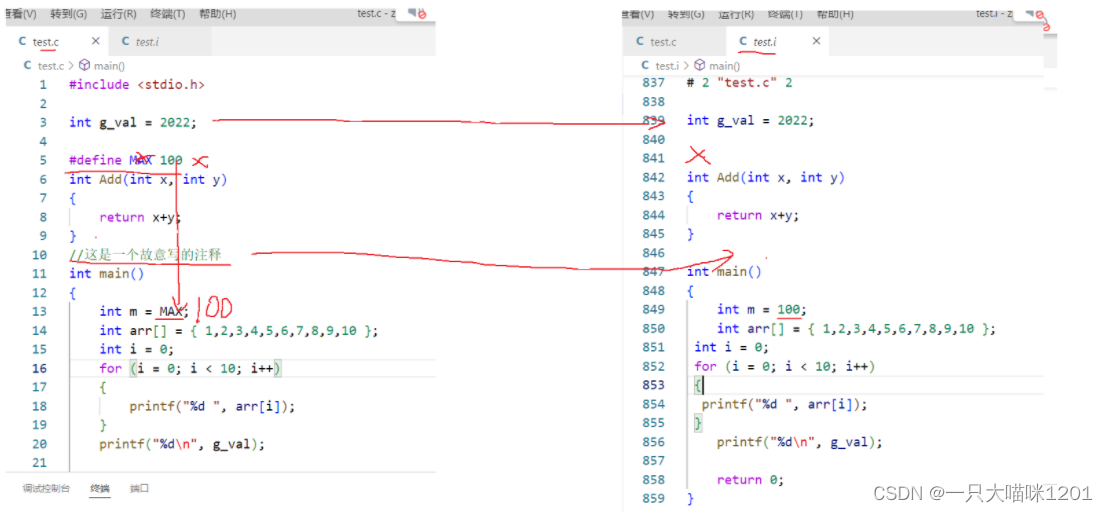
可以看到,我们原本的程序成了这样
- 少了包含的头文件
- 少了define定义的标识符常量
- 少了注释
那么我们少的东西去哪例去了呢?

我们对比一下stdio.h中的内容和test.i文件中我们写的程序上面的内容,如上图中的的一笔我们发现,stido.h中的内容和test.i中我们写的程序之上的内容是相同的,所以
- 在预处理阶段,编译器将头文件中的内容复制到了test.i文件中。
- 仔细观察上面test.c和test.i俩个文件的对比图,我们发现,define定义的M在程序中直接变成了100,所以
- 在预处理阶段,编译器将define定义的标识符常量以及宏定义进行了替换
- 注释是直接消失的,因为注释对我们有用,但是对电脑而言是没有用的,所以
- 在预处理阶段,编译器将注释删除
在预处理阶段发生的事情还有很多,但是最为重要的就是这几条。
编译
预处理进行完后会生成test.i文件,对该文件进行编译会生成.s文件,该文件中的内容是汇编指令,也就是将我们的预处理后的程序转换成了更接近底层的汇编语言。
如上图所示,我们所写的语句都会被转换成对应的汇编代码。
汇编是一个非常复杂的过程,这其中包含很多的过程,比如
- 语法分析
- 词法分析
- 语义分析
- 符号汇总
- …
这些过程全部交给编译器处理就可以,我们一般不需要关心它们是怎么实现的。
这里本喵介绍一下符号汇总:
在test.c和add.c经过编译器编译的时候,会汇总源文件中出现的符号,如上图中画圈的部分就是符号,主函数中的变量名是在函数栈帧中创建和销毁的,这里并不进行处理。
- 编译器每发现一个符号就会给它一个地址,假设在编译add.c源文件的时候发现了符号Add,并且将它放在地址为0x100的位置
- 在编译test.c源文件的时候又发现了符号Add,但是此时并不知道这俩个Add是一个,所以将这里的Add放在地址为0x000的位置
- 接着又发现了符号main,将它放在了地址为0x200的位置
经过这样一个过程,就将我们用户所写的符号汇总完成了。在接下来的链接过程中会合并符号表。
汇编
在经过预处理,编译过程以后,将生成的.s文件进行汇编,如此就生成了.o的文件类型,有的编译器中后缀是.obj,这就是目标文件,里面的内容是将上一步生成的汇编码转换成机器可以看懂的二进制机器码。

如图中所示,生成的二进制机器码我们是完全看不懂什么意思的,只有机器可以知道它要代表的意义。
在这个过程中,会将在编译阶段汇总的符号生成符号表,每一个源文件都会生成一个符号表,最后在链接过程中进行符号表的合并。
以上便是编译过程中的预处理,编译,汇编三个阶段的大致过程。
链接
就像我们在开头所画的图中所示那样,除了编译还有链接环节,其中包括合并段表,合并符号表等过程,这里本喵给大家介绍一下符号表的合并。

还是上面的程序,在上面编译过程中的汇编中会生成俩个符号表,如上图所示,而在链接的时候,会将这俩个符号表合并。
我们可以看到,俩个符号表中都有符号Add,那么合并的时候按照哪个来呢?
- test.c中的符号Add只是一个函数声明中的符号,所以在地址0x000处的符号是没有实际意义的
- 而add.c中的符号Add是函数定义中的符号,其所在的地址0x100处的符号才是函数定义,具有实际的意义
- 所以在符号表的合并中,俩个符号Add会合并到有真正意义的那个地址中。
合并后的结果就是
运行环境
程序执行的过程:
- 程序必须载入内存中。在有操作系统的环境中:一般这个由操作系统完成。在独立的环境中,程序的载入必须由手工安排,也可能是通过可执行代码置入只读内存来完成。
- 程序的执行便开始。接着便调用main函数。
- 开始执行程序代码。这个时候程序将使用一个运行时堆栈(stack),存储函数的局部变量和返回地址。程序同时也可以使用静态(static)内存,存储于静态内存中的变量在程序的整个执行过程一直保留他们的值。
- 终止程序。正常终止main函数;也有可能是意外终止。
预处理详解
上面部分只是对程序执行的整体流程做了大致的介绍,接下来本喵给大家详细讲讲和预处理有关的知识。
预定义符号
C语言中有许多的内置符号,如下
__FILE__ //进行编译的源文件
__LINE__ //文件当前的行号
__DATE__ //文件被编译的日期
__TIME__ //文件被编译的时间
__STDC__ //如果编译器遵循ANSI C,其值为1,否则未定义
这些符号代表的意义就如同注释中所说,它们也有一定的应用场景
注意:下划线是俩个英文下划线
#include <stdio.h>
int main()
{
int i = 0;
FILE* pf = fopen("test.txt", "w");
if (pf == NULL)
{
perror("fopen");
return 1;
}
for (i = 0; i++; i < 10)
{
fprintf(pf, "源文件:%s 行数:%d 日期:%s 时间:%s i=%d\n", __FILE__, __LINE__, __DATE__, __TIME__, i);
}
fclose(pf);
pf = NULL;
return 0;
}
#define
#define定义的标识符
语法:
#define name stuff
在程序中可以使用name来代替stuff
如
#define MAX 1000
#define reg register //为 register这个关键字,创建一个简短的名字
#define do_forever for(;;) //用更形象的符号来替换一种实现
#define CASE break;case //在写case语句的时候自动把 break写上。
// 如果定义的 stuff过长,可以分成几行写,除了最后一行外,每行的后面都加一个反斜杠(续行符)。
#define DEBUG_PRINT printf("file:%s\tline:%d\t \ date:%s\ttime:%s\n" ,\ __FILE__,__LINE__ , \ __DATE__,__TIME__ )
根据我们上面对预处理的详细分析,我们知道,在预处理过程中,define定义的标识符会被原封不动的替换掉。
#define 定义宏
#define name( parament-list ) stuff
其中的parament-list是一个由逗号隔开的符号表,被叫做宏参,它们可能出现在stuff中,被叫做宏体。
注意:
- 括号必须和宏名紧挨在一起
- 如果宏名和括号直接有任何空格,就会讲括号认为是宏体的一部分
我们用宏实现一个数平方的计算
#define SQRT(n) (n*n)
int main()
{
int a = 5;
int ret = SQRT(a + 1);
printf("%d\n", ret);
return 0;
}
你觉得它的结果是什么呢?是36吗?
结果是11,和我们所想的不一样,这是什么原因呢?
宏在预处理时仅发生替换,而不发生计算
在预处理中,这个代码的实际情况是
#define SQRT(n) n*n
int main()
{
int a = 5;
int ret = 5 + 1 * 5 + 1;
printf("%d\n", ret);
return 0;
}
宏中的n被替换成了5+1,并不是6,所以最后的结果是11。
为了达到我们的目标,需要加几个括号
#define SQRT(n) (n)*(n)
此时的结果就是36了。
再看一个例子
#define DOUBLE(n) (n)+(n)
int main()
{
int a = 5;
int ret = 10 * DOUBLE(a);
printf("%d\n", ret);
return;
}
此时的结果会是10吗?
答案又成了55.
这是因为,发生的替换是这样的
int ret = 10 * (5) + (5);
所以结果是55
为了避免这样的情况,还需要加括号
#define DOUBLE(n) ((n)+(n))
这样的宏定义就不会出现歧义。
所以用于对数值表达式进行求值的宏定义都应该用这种方式加上括号,避免在使用宏时由于参数中的操作符或邻近操作符之间不可预料的相互作用。
#define替换的规则
在程序中扩展#define定义符号和宏时,需要涉及几个步骤。
- 在调用宏时,首先对参数进行检查,看看是否包含任何由#define定义的符号。如果是,它们首先被替换。
- 替换文本随后被插入到程序中原来文本的位置。对于宏,参数名被他们的值所替换。
- 最后,再次对结果文件进行扫描,看看它是否包含任何由#define定义的符号。如果是,就重复上述处理过程。
注意:
- 宏参数和#define 定义中可以出现其他#define定义的符号。但是对于宏,不能出现递归。
- 当预处理器搜索#define定义的符号的时候,字符串常量的内容并不被搜索。
如#define M 100 char arr[] = "MAX";这里的M不会被替换,因为它是在字符串中的。
#和##
一个#号
int main()
{
char arr[] = "hello ""world";
printf("hello ""world\n");
printf("%s\n", arr);
return 0;
}

这样写的结果仍然是hello world
- 俩个字符串紧挨着是可以合并成一个字符串的。
#define PRINT(FORMAT,VAL) printf("the value is "FORMAT"\n",VAL)
int main()
{
PRINT("%d", 10);
return 0;
}

- 宏参分别是"%d"和10,将宏参替换到宏体中便成了
printf("the value is ""%d""\n",VAL);合并后成了
printf("the value is %d\n",VAL);这里宏参以字符串“%d”的形式进行了替换才达到了合并的效果
我们可以使用#将宏参转变成字符串
#define PRINT(FORMAT,VAL) printf("the value of "#VAL" is "FORMAT"\n",VAL)
int main()
{
int i = 10;
PRINT("%d", i + 3);
return 0;
}

- 这里我们将形参i + 3加上一个#号,它便当成一个字符串和原字符串结合了
- 加一个#号就不用写成"i + 3"的形式了
两个#号
#define ADD_TO_SUM(num, value) \ sum##num += value
int main()
{
int sum5 = 10;
ADD_TO_SUM(5, 10);
printf("%d\n", sum5);
return 0;
}
- 通过俩个#号将sum和num拼接在了一起
- 当宏参为5的时候,两个#拼接后的结果是sum5
- 而该宏的作用是给sum5再加10
注意:拼接后的变量名必须已经定义过
带副作用的宏参数
#define MAX(a, b) ( (a) > (b) ? (a) : (b) )
int main()
{
int x = 5;
int y = 8;
int z = MAX(x++, y++);
printf("x=%d y=%d z=%d\n", x, y, z);
}
返回的结果是什么?
这是为什么呢?
- 将x++和y++作为宏参a和b,在a和b比较的时候是比较的数组5和8的大小
- 比较完后a和b都发生了自增1,所以变成了6和9,也就是x和y
- 上面比较的结果返回的是b,所以返回的结果是9
- 返回以后b还会自增1,所以就变成了10
- 所以最后的结果是x=6,y=10,z=9
这样就是将x++作为宏参所带来的副作用,如何避免呢?
- 将x++和y++改成x+1和y+1就没有副作用了
- 此时单纯的进行x和y的比较,结果就是8,并不会发生自增
宏和函数对比
宏通常被应用于执行简单的运算。
比如在两个数中找出较大的一个。
#define MAX(a, b) ((a)>(b)?(a):(b))
那为什么不用函数来完成这个任务?
原因有俩个
- 用于调用函数和从函数返回的代码可能比实际执行这个小型计算工作所需要的时间更多。
所以宏比函数在程序的规模和速度方面更胜一筹。- 更为重要的是函数的参数必须声明为特定的类型。所以函数只能在类型合适的表达式上使用。反之宏可以适用于整形、长整型、浮点型等各种类型。
宏是与类型无关的。
但是宏也存在一定的缺点
- 每次使用宏的时候,一份宏定义的代码将插入到程序中。除非宏比较短,否则可能大幅度增加程序的长度。
- 宏是没法调试的
- 宏由于类型无关,也就不够严谨
- 宏可能会带来运算符优先级的问题,导致程容易出现错。
宏也可以实现函数完全无法做到的事情,比如
- 宏的参数可以出现类型,但是函数做不到
#define MALLOC(num,type) (type*)malloc(num*sizeof(type))
int main()
{
int* p = MALLOC(10, int);
if (p == NULL)
{
perror("malloc");
return 1;
}
//使用
free(p);
p = NULL;
return 0;
}
这里就将int类型作为了宏参,这样的方式函数就做不到。
来总结一下,看下表
| 属性 | #define定义宏 | 函数 |
|---|---|---|
| 代码长度 | 每次使用时,宏代码都会被插入到程序中。除了非常小的宏之外,程序的长度会大幅度增长 | 函数代码只出现于一个地方;每次使用这个函数时,都调用那个地方的同一份代码 |
| 执行速度 | 更快 | 存在函数的调用和返回的额外开销,所以相对慢一些 |
| 操作符优先级 | 宏参数的求值是在所有周围表达式的上下文环境里,除非加上括号,否则邻近操作符的优先级可能会产生不可预料的后果,所以建议宏在书写的时候多些括号。 | 函数参数只在函数调用的时候求值一次,它的结果值传递给函数。表达式的求值结果更容易预测。 |
| 带有副作用的参数 | 参数可能被替换到宏体中的多个位置,所以带有副作用的参数求值可能会产生不可预料的结果。 | 函数参数只在传参的时候求值一次,结果更容易控制。 |
| 参数类型 | 宏的参数与类型无关,只要对参数的操作是合法的,它就可以使用于任何参数类型。 | 函数的参数是与类型有关的,如果参数的类型不同,就需要不同的函数,即使他们执行的任务是不同的。 |
| 调试 | 宏是不方便调试的 | 函数是可以逐语句调试的 |
| 递归 | 宏是不能递归的 | 函数是可以递归的 |
命名约定
一般来讲函数和宏的使用语法很相似,所以语言本身没法帮我们区分二者。那我们平时的一个习惯是:
- 把宏名全部大写
- 函数名不要全部大写
#undef
我们使用#define定义的标识符或者是宏,都可以通过#undef来取消。
#undef NAME
//如果现存的一个名字需要被重新定义,那么它的旧名字首先要被移除。
条件编译
我们在写程序的时候,尤其是在调试的时候,有些代码留着碍事,但是删了又可惜,还有在嵌入式中固件库中的架构都是通过条件编译来实现的。
例如
#include <stdio.h>
#define __DEBUG__
int main() {
int i = 0; int arr[10] = {
0 }; for (i = 0; i < 10; i++) {
arr[i] = i;
#ifdef __DEBUG__
printf("%d\n", arr[i]);//为了观察数组是否赋值成功。
#endif //__DEBUG__
} return 0;
}
在这里,如果我们定义了标识符__DEBUG__才会执行打印这条语句,如果没有定义那么在预处理过程中会直接删掉这条语句。
常用的条件编译语句有
- 单分支条件编译
#if 常量表达式
//...
#endif
//常量表达式由预处理器求值。
这里的常量表达式会由预处理器求值,如果非0则为真,下面的代码就会被编译。
如:
#define __DEBUG__ 1
#if __DEBUG__
//..
#endif
其中有开始判断就得有判断结束
- 多个分支的条件编译
#if 常量表达式
//...
#elif 常量表达式
//...
#else
//...
#endif
和if和else语句一样,只是这里要加#号,并且else变成了elif,最后要写上判断结束语句#endif
- 判断是否被定义
#if defined(symbol)//或者
#ifdef symbol
//。。。
#endif
//俩条语句是相互等价的
#if !defined(symbol)//或者
#ifndef symbol
//。。
#endif
判断前面是否定义过相关的标识符,不论真假,只管是否有定义,有就执行,没有就不执行。
- 嵌套指令
#if defined(OS_UNIX)
#ifdef OPTION1
unix_version_option1();
#endif
#ifdef OPTION2
nix_version_option2();
#endif
#elif defined(OS_MSDOS)
#ifdef OPTION2
msdos_version_option2();
#endif
#endif
类似与条件语句中的嵌套,但是每一层都要有判断结束语句#endif
文件包含
<font color = red size 4>本地文件包含:
#include "filename"
用双引号括起来的头文件被叫做本地头文件。
查找策略:
- 先在源文件所在目录下查找,如果该头文件未找到,编译器就像查找库函数头文件一样在标准位置查找头文件。
- 如果找不到就提示编译错误。
<font color = red size 4>库文件包含:
#include "filename"
用尖括号括起来的头文件被叫做库文件。
查找策略:
- 查找头文件直接去标准路径下去查找,如果找不到就提示编译错误。
标准路径是我们在安装编译器时库文件所在的位置
- 库文件也可以用双引号引用吗?
- 答案是可以的,因为先会在源文件所在的目录下寻找,找不到还是会去库中寻找,只不过这样的效率比较低。
- 为了提高效率,我们应该明确告诉编译器要包含的头文件在哪里
<font color = red size 4>嵌套文件包含
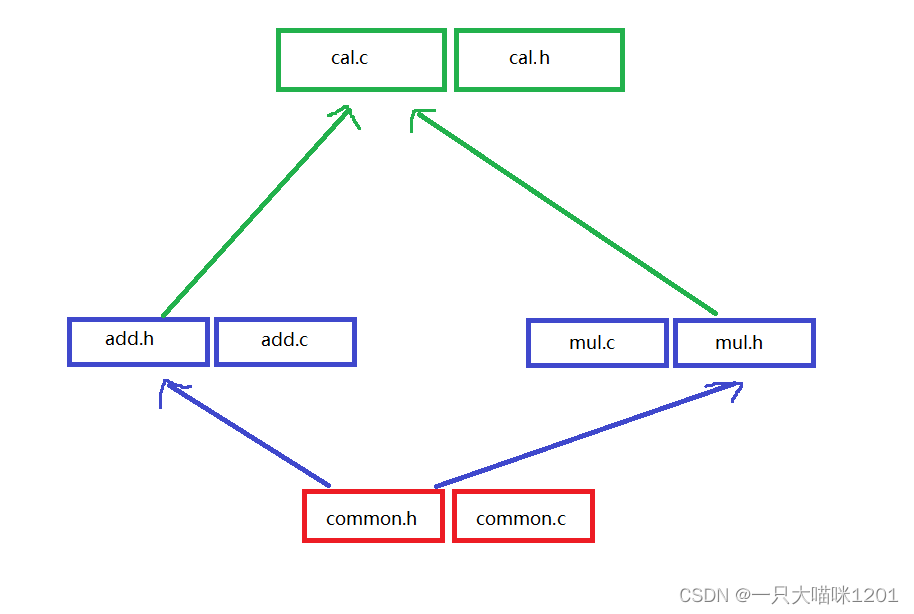
有时一个头文件会被多次引用,如上图所示的情况中,
- commno.h被add.h和mul.h引用
- 而add.h和mul.h又被cal.c引用
- 此时common.h在cal.c中被引用了俩次
在前面预处理阶段本喵说过,头文件的引用的实质就是将头文件中的内容复制过来,那么此时引用同一个头文件俩次,复制也会复制俩次,既多余而且占内存,有什么办法解决吗?
这时就要用到我们的条件编译了,让编译器条件性的进行编译,避免多次复制同一个头文件
在每一个头文件中写下面的代码
#ifndef __TEST_H__
#define __TEST_H__
//头文件的内容
#endif //__TEST_H__
如果没有定义这样一个标识符,那么就执行条件编译内的程序,由于在执行的时候会定义一次标识符__TEST_H__,所以在后面对同一个头文件进行编译的时候,编译器就检测到这样的一个标识符,便不会再进行编译了,此时无论同一个头文件被重复引用了多少次,它只会被复制一次,也就是只会被预处理一次。
或者在一些编译器中,如VS2019中,可以在头文件中写
#pragma once
它的作用和条件编译是一样的。
总结
上面便是我们在写好程序以后,点运行后发生的过程,以及通过一些条件编译等指令对这个过程进行一定控制。希望对各位有所帮助。
边栏推荐
- 死信队列 和消息TTL过期代码
- 【ManageEngine】ServiceDesk Plus荣获2022安全样板工程数据安全奖
- Data intensive application system design - Application System Overview
- What is the difference between'1 and'b1 when assigning values
- Release of v6.5.1/2/3 series of versions of Xingyun housekeeper: the ability of database OpenAPI continues to be strengthened
- [Database Foundation] summary of MySQL Foundation
- [nodejs] nodejs create a simple server
- Taobao Search case
- 2022牛客多校第二场
- How does JS judge whether the current date is within a certain range
猜你喜欢

S4/hana ME21N create Po output control message button missing solution (switch EDI output mode brf+ to Nast mode)
VSCode格式化Json文件

Ratio of learning_ add,ratio_ subtract,ratio_ multiply,ratio_ Use of divide

【代码案例】博客页面设计(附完整源码)

redis-扩展数据类型(跳跃表/BitMaps/HyperLogLog/GeoSpatial)

Node Foundation

红娘的话

【MUDUO】EventLoop事件循环

Release of v6.5.1/2/3 series of versions of Xingyun housekeeper: the ability of database OpenAPI continues to be strengthened

Loading process such as reflection
随机推荐
redis-基本数据类型(String/list/Set/Hash/Zset)
[code case] blog page design (with complete source code)
赋值时'1和'b1有什么区别
热部署和热加载有什么区别?
[nodejs] nodejs create a simple server
[Muduo] EventLoop event cycle
Why are there many snapshot tables in the BI system?
A long detailed explanation of C language operators
Practical skills of easyexcel
Promise asynchronous callback function
SAP Message No. VG202 IDoc E1EDK18 中付款条款已经转移:检查数据
How to solve cross domain problems
从哪些维度评判代码质量的好坏?如何具备写出高质量代码的能力?
反射之类加载过程
Macro task, micro task and event cycle mechanism
Good news under the epidemic
【代码案例】博客页面设计(附完整源码)
抽丝剥茧C语言(高阶)程序环境和预处理
意向不到的Dubug妙招
initializer_list工具库学习