当前位置:网站首页>【翻译】关于扩容一个百万级别用户系统的六个课程
【翻译】关于扩容一个百万级别用户系统的六个课程
2022-08-03 15:58:00 【sean.liu】
翻译自: Six Lessons Learned The Hard Way About Scaling A Million User System
每个人都会到一个点,那时,你觉得你学习的东西足够去分享你的经验,并希望帮助那些和你走相似的路的人?这就是为什么 Martin Kleppmann精心编写了 Six things I wish we had known about scaling,一个值得你花费时间的文章。
这不是一个扩展Twitter的建议,而是构架一个百万级用户系统,这是一个大量项目中的甜点。它的结论听起来像是真的。
建立一个可伸缩系统并不总是有趣的,这是大量的管道和多如牛毛的细节。很多黑客工具必然存在了很久,但是很多开源解决方案太糟糕了(你的最终也失败了,但是它至少能解决你的问题)。
这是一个注释,关于六个课程(附带赠送一个)
- 实际负载测试是困难的。测试一个大型分布式系统并不像一个科学实验,它能在理想的条件下进行。这是一个很难接受的科学思想。了解实际访问模式是很困难的。测试所需的合成数据集合大于你需要的,这是很困难的。对比新的和老的系统的正确性是艰难的。所以随时准备滚回,如果新的代码在实践中不工作。
- 数据演变是困难的。你的数据到处都是,在你的数据库,日志,以及二进制数据块。随着它们改变更新数据格式是一个巨大的时间开销。大公司往往在自动化以及编排流程上更有优势。
- 数据库连接是一个真正的限制。数据库链接增长令人惊讶,它几乎随着系统在服务和节点的数量一起。每个链接吃掉的资源包括你的机器以及你的开发人员,因他他们必须找出如何他们的方法。是用链接池,或者写一个数据存取层包装数据库,通过后面的一个API。
- 阅读副本是一个痛苦的操作。阅读副本,从主分支卸载数据库入口是一个常见的扩展策略。它还需要很多工作去设置以及维护这些系统。故障处理是一个常有的问题来源。
- 考虑内存效率。延迟的峰值往往是由内存引起的。有效的使用内存是困难的,因为很难找出内存是如何被使用的。很多性能问题通过购买更多的内存来解决。有可能的话在内存中建立合式的索引,使用hash索引,而不是采用字符串本身。
- 改变的捕捉是被低估的。像系统中的数据改变,它必然伴随着很多服务,像数据库,搜索索引,图表,索引,读取副本,缓存失效等。你可以使用应用程序写入到多个位置,当更新时,但是这个从来都没有付诸实践。你可以让应用读取数据库日志,但是这不可能实现在所有的系统上。一个好的方案是使用变化捕捉系统,接受并存储所有的数据,写入数据库。应用程序可以实时接收这些更新,随着历史的变化流淌。这个变化捕捉系统成为所有应用程序的数据正确性的单一来源。一个大的优势关于这个途径就是数据的产生和消费是分离的,它提供了“你可以自由的实验,而不担心拖累主站”的承诺。
- 缓存和缓存失效。这是一个额外课程来自mysteriousllama对这篇文章的一个评论,没有适当的缓存以及好的缓存失效的策略 ,你的数据库会崩溃。使用redis和memcache去缓存一切可能。不要经常链接数据库除非你必须这样。确保你可以轻松的使任何缓存条目失效,并且保持原子性,因此你不能在竞争条件下运行。使用锁来确保当缓存到期,数据库不会因为多个相同的查询拷贝而得到大量的dog-pile。你需要考虑查询还存,在你的数据库中选择可能依然有效的。但是请相信我,这并不是结束。你还是可以缓存高水平对象,而不仅仅是简单的查询。 根据你的可靠性要求,你甚至可以考虑处理你的缓存,作为回显,以及在后台进行数据库的批量写入。这些通常会比因各种因素产生的个别写入要高效得多。我工作在诺干排名前200的站点,这一直是首选的扩展策略。数据库的麻烦-避免查询它们。
边栏推荐
- Some optional strategies and usage scenarios for PWA application Service Worker caching
- Leetcode76. Minimal Covering Substring
- MySQL性能优化_小表驱动大表
- Ruoyi Ruoyi framework @DataScope annotation use and some problems encountered
- STM32 GPIO LED and buzzer implementation [Day 4]
- ReentrantLock详解
- CopyOnWriteArrayList详解
- 【Unity入门计划】基本概念(8)-瓦片地图 TileMap 01
- 【899. 有序队列】
- 泰山OFFICE技术讲座:段落边框的绘制难点在哪里?
猜你喜欢
Fortinet产品导入AWS AMI操作文档

leetcode:899. 有序队列【思维题】

出海季,互联网出海锦囊之本地化
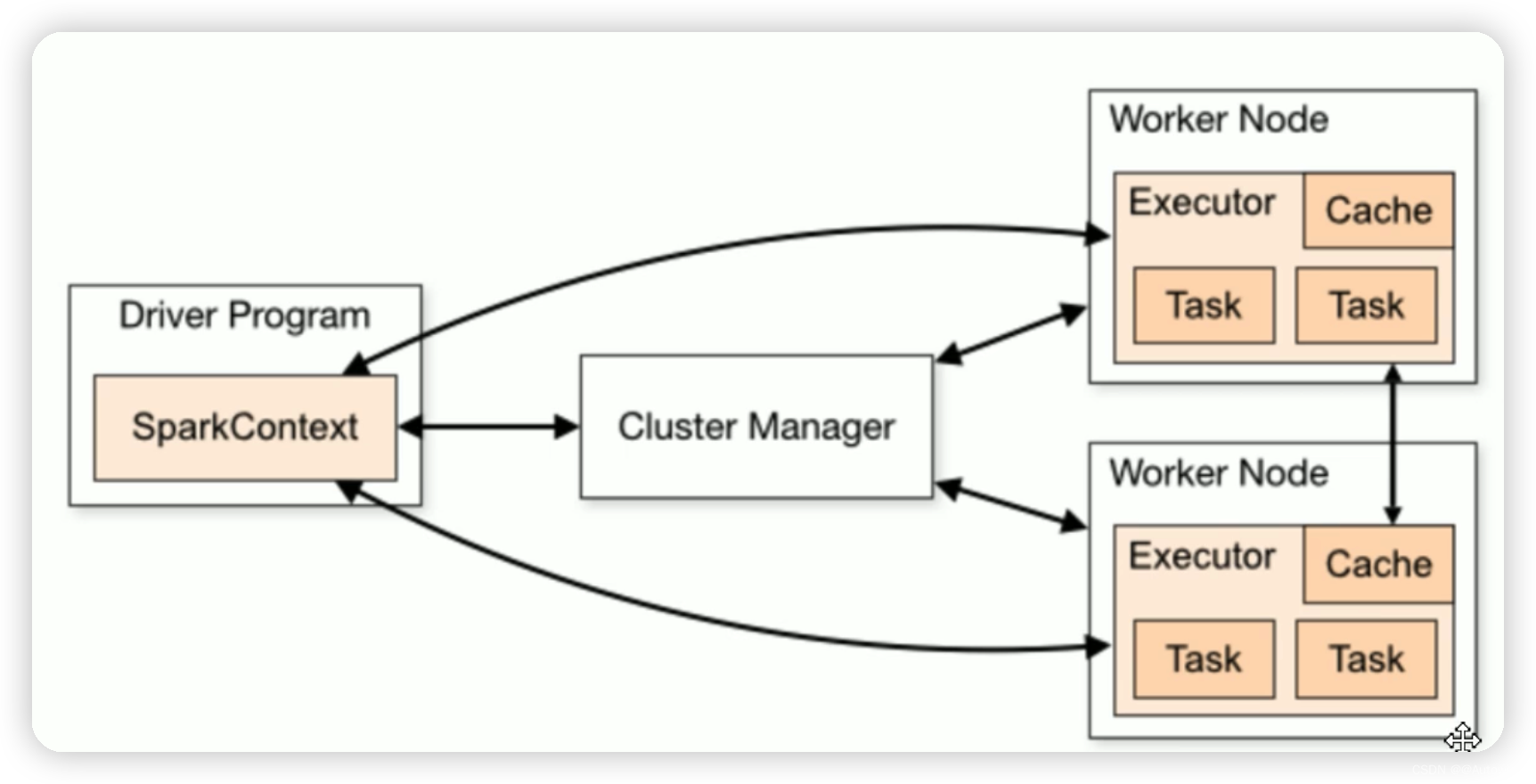
spark入门学习-2

Yii2安装遇到Loading composer repositories with package information
![[微信小程序开发者工具] × #initialize](/img/38/ea90525f53de3933a808f0d75028b0.png)
[微信小程序开发者工具] × #initialize
AWS China SDN Connector
![STM32 GPIO LED and buzzer implementation [Day 4]](/img/13/dbfed5a207e97ba0b78c1f63712e16.png)
STM32 GPIO LED and buzzer implementation [Day 4]
DataGrip:非常好用的数据库工具,安装与使用教程,亮点介绍

一文看懂推荐系统:召回01:基于物品的协同过滤(ItemCF),item-based Collaboration Filter的核心思想与推荐过程
随机推荐
spark入门学习-2
【数据库数据恢复】SqlServer数据库无法读取的数据恢复案例
【Unity入门计划】基本概念(6)-精灵渲染器 Sprite Renderer
我在滴滴做开源
下午见!2022京东云数据库新品发布会
《安富莱嵌入式周报》第276期:2022.07.25--2022.07.31
爬虫注意
我写了个”不贪吃蛇“小游戏
MarkDown常用代码片段和工具
Tolstoy: There are only two misfortunes in life
出海季,互联网出海锦囊之本地化
【码蹄集新手村600题】将一个函数定义宏
详谈RDMA技术原理和三种实现方式
参与便有奖,《新程序员》杂志福利来袭!
MPLS的wpn实验
Spark entry learning-2
劲爆!协程终于来了!线程即将是过去式
DC-DC 2C(40W/30W) JD6606SX2退功率应用
Ruoyi Ruoyi framework @DataScope annotation use and some problems encountered
微电网和直流电网中最优潮流(OPF)的凸优化(Matlab代码实现)