当前位置:网站首页>Paper recommendation: relicv2, can the new self supervised learning surpass supervised learning on RESNET?
Paper recommendation: relicv2, can the new self supervised learning surpass supervised learning on RESNET?
2022-06-11 04:55:00 【Shenlan Shenyan AI】
Self supervision ResNets Can it be in ImageNet Go beyond supervised learning without labels ?
This paper will introduce a recent paper promoting the development of self-regulated learning , The paper was written by DeepMind publish , Nicknamed ReLICv2.
Tomasev Papers of others “Pushing the limits of self-supervised ResNets: Can we outperform supervised learning without labels on ImageNet?”. Put forward the right ReLIC The technical improvement of the paper , The paper is called “Representation learning via invariant causal mechanisms”. The core of their method is to add Kullback-Leibler-Divergence Loss , This is calculated by using the probability formula of classical comparative learning objectives . In addition, a novel enhancement scheme is introduced , And learn from the experience of other relevant papers .
Keep this article as simple as possible , So that even readers without prior knowledge can follow up .

01 Self supervised and unsupervised pre training of computer vision
Before delving into the paper , It is necessary to quickly review the whole content of self-monitoring pre training . If you know something about self supervised learning , Or be familiar with self-monitoring pre training , You can skip this part .
Generally, computer vision models have been trained by supervised learning . This means that humans view images and create various labels for them , The model can learn the patterns of these tags . for example , Human annotators assign class labels to images or draw bounding boxes around objects in images . But anyone who has been in contact with the tag task knows , Creating enough training data sets is a lot of work .
by comparison , Self supervised learning does not require any manually created tags , The model supervises its own learning . In computer vision , The most common way to model this self-monitoring is to cut the image differently or apply different enhancements to it , And pass the modified input to the model . In this way, even if the image contains the same visual information, it will look different , That is, let the model know that these images still contain the same visual information , That is, the same object , This allows the model to learn similar potential representations of the same object ( Output vector ).
Then, we can carry out transfer learning on this pre training model . These models will be in 10% Training on tagged data , To perform downstream tasks such as target detection and semantic segmentation .
02 Contribution of the paper
As is the case with many other self supervised pre training techniques ,ReLICv2 The first step in the training process is also about data enhancement . In the paper , The author first mentioned the use of previously successful enhancement schemes .
The first is SwAV Enhancements used in . Contrary to previous work ,SwAV Not only create two different input image clipping , And it can be cut at most 6 Time . These can be made in different sizes , for example 224x244 and 96x96, The most successful numbers are two large sizes and 6 A small size . If you want to know more about SwAV Information about the enhancement scheme , Please read the original paper .
The second set of enhancements previously described comes from SimCLR. This scheme is now used by almost all papers in this field . By applying a random horizontal flip 、 Color distortion 、 Gaussian blur and overexposure to process images . If you want to know about SimCLR For more information , Please read the original paper .
however ReLICv2 A novel enhancement technology is also provided : Remove the background from the object in the image . To achieve this , They are in some... In an unsupervised way ImageNet Train a background removal model on the data . The authors found this enhancement in 10% The most effective application of probability .

Once the image is enhanced and cropped many times , The output will pass through the encoder network and the target network . When the encoder network updates using back propagation , The target network passes through a network similar to MoCo The momentum calculation of the frame receives updates .
ReLICv2 The overall goal of is to learn encoder , To generate a consistent output vector for the same class . The author formulates a novel loss function . They start with the standard contrast negative log likelihood , Its core has similarity function , Anchor image ( Mainly input image ) With the positive example ( An enhanced version of the image ) And negative examples ( Other images in the same image ) Compare .

ReLICv2 The loss function consists of negative log likelihood and the sum of anchor view and positive view Kullback-Leibler Divergence composition .
This loss is extended by comparing the probability formula of the target : The relationship between the possibility of anchor image and the possibility of positive image Kullback-Leibler The divergence . This forces the network to learn similar images not too close , Dissimilar images can be far away , Avoid extreme clustering that can lead to learning collapse , And create a more balanced distribution between clusters . So this additional loss item can be seen as similar to a self-monitoring model . For this loss function, we include alpha and beta Two hyperparameters , The two loss items can be weighted separately .
The addition of all these methods has proved successful , Let's take a closer look at the results presented in the paper .
03 Result display
As the title of the paper states ,ReLICv2 The point of trying to prove is , The self supervised pre training method is comparable only when the encoder networks all use the same network architecture . For their work , Choose to use the classic ResNet-50.

stay ImageNet Use different pre training ResNet-50 Result .
When using the same ResNet-50 And in ImageNet-1K When training its linear layer on while freezing all other weights ,ReLICv2 It has considerable advantages over existing methods . With primordial ReLIC Comparison of papers , The introduced improvements even bring performance advantages .

Compared with the supervised pre training model on different data sets , Accuracy has improved .
When comparing migration learning performance on other data sets ,ReLICv2 And other methods ( Such as NNCLR and BYOL) comparison , Continue to show impressive performance . This further shows that ReLICv2 It's a new one 、 Advanced self-monitoring pre training methods . The evaluation of other data sets is not often mentioned in other papers .

ReLICv2 and BYOL Visualization of learning clusters . Point bluer , The closer to the corresponding class cluster .
This chart shows ReLICv2 The analogy of learning other frameworks ( Such as BYOL) Closer to the . This again shows that compared with other methods , These techniques make it possible to create finer grained clusters .
04 summary
In this article, I introduce ReLICv2, This is a new self supervised pre training method and shows very good experimental results .
By combining the probability formula of comparative learning objectives , And by adding a proven novel enhancement scheme , This technology can push forward the space of visual self-monitoring pre training .
I hope this article can make you right ReLICv2 Have a good preliminary understanding , But there's still a lot to discover . Therefore, it is recommended to read the original paper , Even if you are new to the field . You have to start somewhere ;) I hope you like the explanation of this paper . If you have any comments on the article or find any mistakes , Please feel free to comment .
reference
[1] Mitrovic, Jovana, et al. “Representation learning via invariant causal mechanisms.” arXiv preprint arXiv:2010.07922 (2020).
[2] Tomasev, Nenad, et al. “Pushing the limits of self-supervised ResNets: Can we outperform supervised learning without labels on ImageNet?.” arXiv preprint arXiv:2201.05119 (2022).
The author of this article :Leon Sick
| About Deep extension technology |
Shenyan technology was founded in 2018 year 1 month , Zhongguancun High tech enterprise , It is an enterprise with the world's leading artificial intelligence technology AI Service experts . In computer vision 、 Based on the core technology of natural language processing and data mining , The company launched four platform products —— Deep extension intelligent data annotation platform 、 Deep extension AI Development platform 、 Deep extension automatic machine learning platform 、 Deep extension AI Open platform , Provide data processing for enterprises 、 Model building and training 、 Privacy computing 、 One stop shop for Industry algorithms and solutions AI Platform services .
边栏推荐
- [aaai 2021 timing action nomination generation] detailed interpretation of bsn++ long article
- 力扣(LeetCode)161. 相隔为 1 的编辑距离(2022.06.10)
- Hiredis determines the master node
- Split all words into single words and delete the product thesaurus suitable for the company
- What is the difference between gigabit network card and 10 Gigabit network card?
- lower_ bound,upper_ Bound, two points
- Lianrui: how to rationally see the independent R & D of domestic CPU and the development of domestic hardware
- Cartographer learning records: 3D slam part of cartographer source code (I)
- Network security construction in 5g Era
- 【Markdown语法高级】 让你的博客更精彩(三:常用图标模板)
猜你喜欢

Huawei equipment configures local virtual private network mutual access
华为设备配置本地虚拟专用网互访

Check the digital tube with a multimeter

华为设备配置通过GRE隧道接入虚拟专用网

Differences between the four MQ
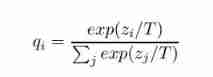
Simple knowledge distillation

Best practices and principles of lean product development system

Mindmanager22 professional mind mapping tool

An adaptive chat site - anonymous online chat room PHP source code

Paper reproduction: expressive body capture
随机推荐
Powerful new UI installation force artifact wechat applet source code + multiple templates support multiple traffic main modes
PCB ground wire design_ Single point grounding_ Bobbin line bold
Simple linear regression of sklearn series
codesys 获取系统时间
Electrolytic solution for ThinkPad X1 carbon battery
[Transformer]Is it Time to Replace CNNs with Transformers for Medical Images?
【Markdown语法高级】 让你的博客更精彩(三:常用图标模板)
DL deep learning experiment management script
四大MQ的区别
tensorflow1. X and tensorflow2 Conversion of X
Database introduction
Chia Tai International; What does a master account need to know
Target detection - personal understanding of RCNN series
华为设备配置本地虚拟专用网互访
The solution "no hardware is configured for this address and cannot be modified" appears during botu simulation
Relational database system
Go unit test example; Document reading and writing; serialize
Huawei equipment is configured with cross domain virtual private network
Tianchi - student test score forecast
Huawei equipment configures local virtual private network mutual access