当前位置:网站首页>越来越火的图数据库到底能做什么?
越来越火的图数据库到底能做什么?
2022-08-04 15:58:00 【CSDN资讯】

【CSDN 编者按】图数据库像新一代的关系型数据库,取代传统关系型数据库在诸多领域大展拳脚、高歌猛进。图数据库较传统关系型数据库有何优势?适用于哪些技术领域?未来是何态势,有何机遇?《新程序员002》特邀Neo4j亚太地区售前和技术总监俞方桦为大家解读图数据库。
作者 | 俞方桦 责编 | 张红月
出品 | 《新程序员》编辑部
随着大数据时代的到来,传统的关系型数据库由于其在数据建模和存储方面的限制,变得越来越难以满足大量频繁变化的需求。关系型数据库,尽管其名称中有“关系”这个词,却并不擅长处理复杂关系的查询和分析。另外,关系型数据库也缺乏在多服务器之上进行水平扩展的能力。基于此,一类非关系型数据库,统称“NoSQL”存储应运而生,并且很快得到广泛研究和应用。NoSQL(Not Only SQL,非关系型数据库)是一类范围广泛、类型多样的数据持久化解决方案。它们不遵循关系型数据库模型,也不使用SQL作为查询语言。其数据存储不需要固定的表格模式,也经常会避免使用SQL的JOIN操作,一般都有水平可扩展的特征。
简言之,NoSQL数据库可以按照它们的数据存储模型分4类:
键值存储库(Key-Value-stores)
列存储 (Column-based-stores)
文档库(Document-stores)
图数据库(Graph Database)
从DB-Engines发布的数据库技术类别变化趋势图(见图1)中,不难看出图数据库在近十年受到广泛关注、是发展趋势最迅猛的数据库类型。
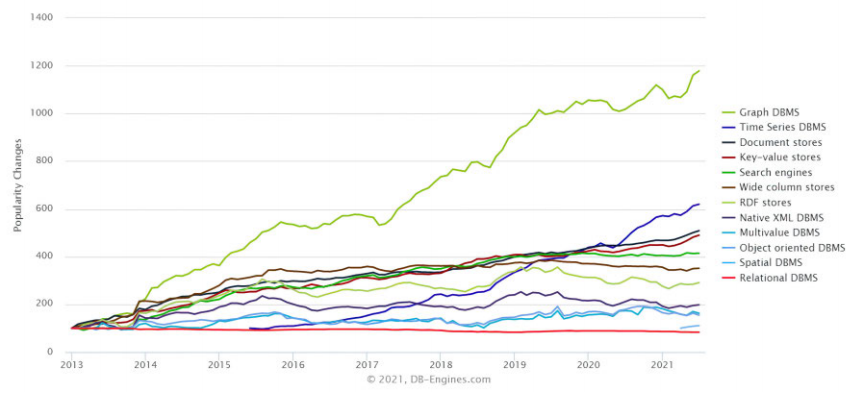
图1 数据库技术发展趋势(截至2021年6月)来源:DB-Engines
那么,到底什么是“图数据库”?相比关系型数据库,图数据库又有哪些优势呢?

本文节选自《新程序员002:新数据库时代&软件定义汽车》

图数据库与关系型数据库的比较
图数据库(Graph Database)是指以图表示、存储和查询数据的一类数据库。这里的“图”,与图片、图形、图表等没有关系,而是基于数学领域的“图论”概念,通常用来描述某些事物之间的某种特定关系。比如在我们的日常生活中:
社交网络是图。每个社交网络的参与者是节点,我们在社交网络中的交互,例如“加好友”“点赞”就是连接节点的边。
城市交通是图。每个路口、门牌号、公交站点等都是节点,街道或者公交线路是边,将可以到达的地方连接起来。
知识也是图。每个名称、概念、人物、事件等都是节点,而类属关系、分类关系、因果关系等是边,将节点连接起来,形成庞大、丰富并且随时在演变的知识图谱。
可以说,“图无处不在”(Graphs are everywhere),也正因如此,传统关系型数据库不擅长处理关系的问题,能够被图数据库很好地解决,图数据库正是为解决这一问题而生。
其实,在某些方面,图数据库就像新一代的关系数据库,区别在于图数据库不仅存储实体,还存储实体之间的关系。关系型数据库通过“主键-外键”表示隐含的“关系”连接,但实际上这里的“关系”是关系代数中的概念,与我们现实世界中的“关系”不同。
通过将关系预先物理存储在数据库中(我们称之为“原生”),图数据库将查询性能由原先的数分钟提高到数毫秒,特别是对于JOIN频繁查询,这种优势更加明显。图2中比较了在社交网络数据集上搜索朋友圈的查询,在原生的图数据库和关系数据库的查询执行效率。显然,使用图数据库比使用传统关系数据库效率有极大提升。
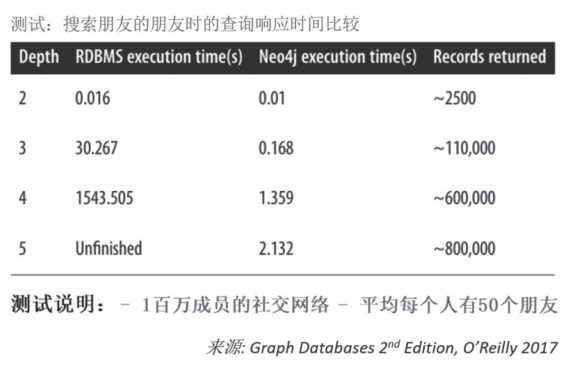
图2 比较图数据库和关系数据库的查询性能
作为NoSQL数据库的一种,图数据库通常不需要先定义严格的数据模式,以及强制的字段类型,这使其在处理结构化和半结构化的数据时同样得心应手。
除了存储和查询效率方面的优势,图数据库也拥有更加丰富的分析能力,我们通过比较这四类主要的非关系型数据库特点(见表1),就可以得知。
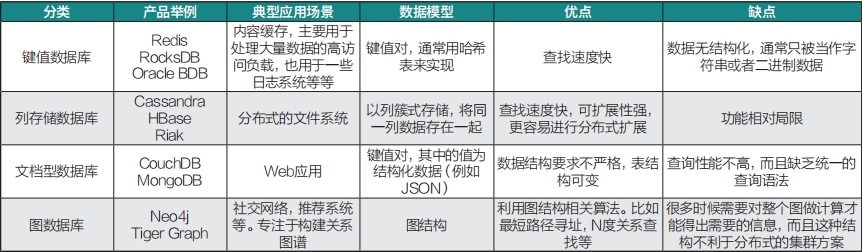
表1 四类主要非关系型数据库特点

图数据库的主要技术领域
既然图数据库有诸多优势且发展迅速,那它主要涉及哪些技术领域呢?我们用图3来描述。具体来讲,图数据库的主要技术领域包括存储模式、图模型、图查询语言、图分析以及图可视化。
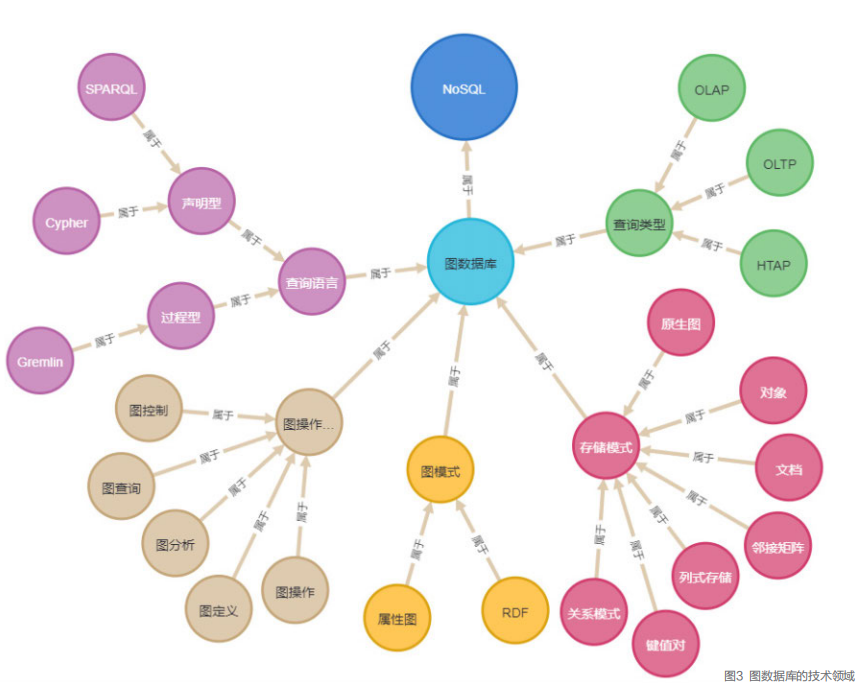
存储模式
原生图vs非原生图
图数据库以节点和边来对现实世界进行数据建模。对于实际的底层物理存储技术,目前主流有两大类方法:
原生(Native),即按照节点、边和属性组织数据存储。典型代表有Neo4j、JanusGraph、TigerGraph等。
非原生,使用其他存储类型。例如基于列式存储的DataStax、基于键值对的OrientDB以及基于文档的MongoDB。部分关系型数据库也在关系存储之上提供类似图的操作。
有的图计算平台底层支持各类存储技术,包括图存储,称作“多模式”,例如百度HugeGraph。
原生的图存储由于针对图数据和图操作的特点进行了优化,并且从物理存储到内存中的图处理,都采用一致的模型而无需进行“模式转换”,在大数据量、深度复杂查询以及高并发情况下,性能普遍优于非原生的图存储。
图的分布式存储
为了支持大规模的图存储和查询,需要对图进行分布式存储。这里有两类分布式的实现方法:
1、分片(Sharding)。分片就是根据某一原则(例如根据节点的ID随机分布)将数据分布存储在多个存储实例中。根据切分规则,又可以分为:
按点切分。每条边只保存一次,并且出现在同一个分区上。如果处于不同分区的两条边有共同的点,那么点会在各自的分区中复制。这样,邻居多的点(繁忙节点)会被分发到多个分区上,增加了存储空间,并且有可能产生同步问题。这种方法的好处是减少了网络通信。
按边切分。通过边切分之后,顶点只保存一次,切断的边会打断保存在不同分区上。在基于边的操作时,对于两个顶点分到两个不同分区的边来说,需要通过网络传输数据。这增加了网络传输的数据量,但好处是节约了存储空间。
出于优化性能的考虑,目前按点切分的分布式图更加常见。
2、分库(Partitioning)。由于现实世界中的图往往遵循“幂律分布”,即少数节点拥有大量的边,而多数节点拥有很少的边。分片存储不可避免地会造成大量数据冗余复制,或增加分区间网络通信的负担。因此,另外一种分布式的方法是分库。这是借助图建模的方法,将节点按照业务需求、根据查询类型分布在不同库中,是最小化跨库的网络传输。不同库中的数据则通过联邦式查询(Federated Query)实现。
图模型
在基于图的数据模型中,最常见的两种方法是资源描述框架(Resource Description Framework,RDF)和标签属性图(Labelled Property Graph,LPG)。
RDF
RDF是W3C组织指定的标准,它使用Web标识符(URI)来标识事物,并通过属性和属性值来描述资源。根据RDF的定义:
资源是可拥有URI的任何事物,比如 "http://www.w3school.com.cn/rdf";
属性是拥有名称的资源,比如"author"或"homepage";
属性值是某个属性的值,比如"David"或"http://www.w3school.com.cn"(请注意一个属性值可以是另外一个资源)。
我们来看看RDF是怎样描述 “西湖是位于杭州的一个旅游景点”这个事实的(见图4)。
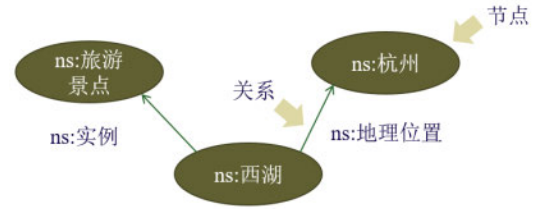
图4 RDF举例
RDF图的查询语言是SPARQL。如果要询问“位于杭州的旅游节点有哪些?”,使用SPARQL的查询如下:
PREFIX ns: <http://kg.com/ns/travel#>
SELECT ?place
WHERE {
?place ns:地理位置 ns:杭州 .
?place ns:实例 ns:旅游景点 .
}LPG
在LPG属性图模型中,数据对象被表示成节点(拥有一个或多个标签)、关系和属性。我们用下面的例子来说明(见图5)。
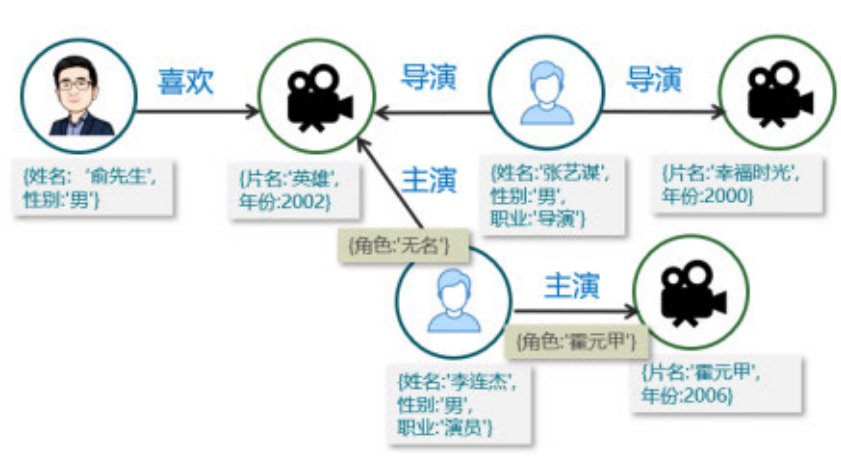
图5 关于电影的个人偏好的属性图
在图5中:
节点/顶点是事物(Object)或者实体(Entity)的抽象,可以是“人”“导演”“电影”“演员”等抽象。节点可以拥有一个或多个标签,例如代表“张艺谋”的节点可以有“个人”“导演”“演员”等标签。
节点的属性。节点的属性为节点提供丰富的语义,根据顶点代表的类型不同,每个顶点可以有不同的属性,比如以“人”作为顶点,属性可以是“姓名”“性别”等。
边/关系。边连接两个节点或同一个节点(指向自己的边),边可以有向或无向。边可以有类型,比如连接“李连杰”和“英雄”的边的类型是“主演”。
边的属性。和顶点的属性类似,每条边上也可以有属性。比如连接“李连杰”和“英雄”的边有属性“角色”,其值是“无名”。
相比RDF,LPG由于可以在节点和边上定义丰富的属性,更加易于我们理解,建模也更加灵活。
图查询语言
应该说,关系型数据库在过去半个世纪的成功离不开SQL查询语言标准化。目前,图查询语言的标准化(GQL)工作还在进行当中,其核心语法和特性基于Neo4j的Cypher、Oracle的PGQL和GCORE框架。
从查询语言本身来说,主要有两类:
声明型(Declarative)。声明型查询语言只要求使用者描述要实现的目标,由查询引擎分析查询语句、生成查询计划然后执行。SQL是声明型查询语言。在图数据库领域,Cypher是最流行的声明型查询语言。
命令型(Imperative)。命令型查询语言要求使用者描述具体执行的操作步骤,然后由数据库执行。在图数据库领域,Gremlin是最流行的(近似)命令型的查询语言。
从未来的发展趋势来看,声明型查询语言由于其易于理解、学习门槛低、便于推广等特性,将成为主流的图查询语言。智能、优化的查询执行引擎将成为衡量图数据库技术优势的关键。
图分析
在计算机科学领域,图算法是一个重要的算法类别,经常用于解决复杂的问题。大家应该还能记得在《数据结构》或者软件开发相关课程中都会学到的“树的遍历”(前序、中序、后序等),这就是典型的图算法。部分成熟的图数据库内置了这些图算法,以提供对图数据的高级分析功能。
最短路径搜索
最短路径是图计算中一类最常见的问题,通常见于解决下面的应用场景:
在两个地理位置之间寻找导航路径;
在社交网络分析中,计算人们之间相隔的距离,“最短”则基于路径上边的距离和成本,例如:最少跳转次数;
Dijkstra算法:边带权重的最短路径;
A*算法:基于启发式规则的最短路径;
k条最短路径。
计算范围则包括:
节点对之间;
单一起点到图中其他所有节点;
全图中所有节点对之间。
除此之外,最小生成树、随机游走等图遍历算法也属于这一类。
社团检测
“物以类聚,人以群分”,这句话非常形象地描述了网络的一个重要特征:聚集成群。群也称作“社区”“团体”“群组”。社区的形成和演变是图分析和研究的又一个重要领域,因为它帮助我们理解和评估群体行为、研究新兴现象。
社区检测算法就是在图中对节点进行分组和集合(见图6):在同一集合中的节点之间的边(代表交互/连接)比分属不同集合的节点之间更多。从这一意义上,我们认为它们有更多共同点。社区检测可以揭示节点集群、隔离的群组和网络结构。在社交网络分析中,这种信息有助于推断拥有共同兴趣的人群。在产品推荐中,可以用来发现相似产品。在自然语言处理/理解中(NLP/NLU),可以用来对文本内容自动分类。社区检测算法还用于生成网络的可视化展现。
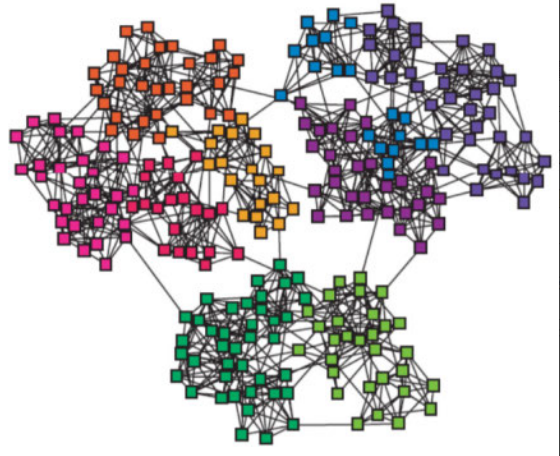
图6 图中节点之间边的密集程度反映了节点之间的相关性
有助于推断拥有共同兴趣的人群。在产品推荐中,可以用来发现相似产品。在自然语言处理/理解中(NLP/NLU),可以用来对文本内容自动分类。社区检测算法还用于生成网络的可视化展现。
中心性算法
在图论和网络分析中,中心性指标识别图中最重要的顶点。其应用广泛,包括识别社交网络中最有影响力的人、互联网或城市网络中的关键基础设施节点,以及疾病的超级传播者。
最成功的中心度算法当属“页面排行”(PageRank)。这是谷歌搜索引擎背后的网页排序算法的核心。页面排行除了计算页面本身的连接,同时评估链接到它的其他页面的影响力。页面的重要性越高,信息来源的可靠度也越高。应用到社交网络中,这一方法可以简单地解释成“认识我的人越重要,我也越重要”。是不是挺有道理?
相似度算法
相似度描述两个节点以及更加复杂的子图结构是否在何等程度上属于同一类别,或者有多相似。
图/网络相似性度量有三种基本方法:
结构等价(Structural Equivalence);
自同构等价(Automorphic Equivalence);
正则等价(Regular Equivalence)。
还有一类是先将节点转换成N维向量(x 1,x 2,…x n)并“投射”到一个N维空间中,然后计算节点之间的夹角或者距离来衡量相似度。这个转换的方法叫作“嵌入”(Embedding),转换的过程叫作“图的表示”,如果是由算法自动得到最佳的转换结果,那么该过程叫作“图的表示学习”。基于图的学习是近年来在人工智能领域非常热门的一个方向,被广泛应用到欺诈检测、智能推荐、自然语言处理等多个领域。
图可视化
“一图胜万言”这句话是对图可视化最恰当的描述。图可视化直观、智能地展现数据之间的结构和关联,能看到从前在表格或者图表中看不到的内容。
2019年,当新冠病毒开始在全球肆虐时,来自Neo4j图数据库社区的一群成员集成了多个异构生物医学和环境数据集(https://github.com/covid-19-net/covid-19-community),建立了关于新冠病毒的知识图谱,以帮助研究人员分析宿主、病原体、环境和病毒之间的相互作用。图7是该知识图谱的部分可视化结果,图中最左边的部分是病毒暴发的地理位置子图,包含国家、地区、城市;中间绿色的部分是流行病学子图,包括有关病毒株、病原体和宿主生物的信息,病例和菌株分别与报告和发现它们的位置相关联;右边紫色的部分是生物学子图,代表生物体、基因组、染色体、变异体等等。
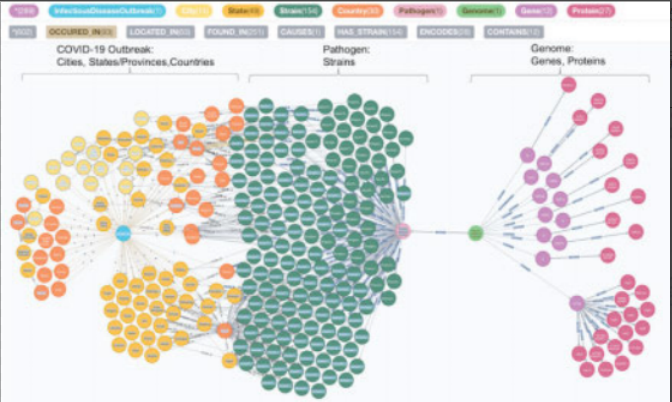
图7 新冠病毒知识图谱
图数据的可视化建立了关于事物之间关联的最直观的展现,并且使得原本并不明显、甚至于淹没在数据汪洋中的重要特征得以显现出来,成为新的认知。
图数据库的未来展望
在图数据库出现并兴起的十余年间,它在各个领域都得到了成功的应用,并且产生了众多创新性的解决方案。
在社交平台的“网络水军”识别方面,通过分析用户的关系图特征、结合传统的基于用户行为和用户内容的发现方法,可以有效提高预测的准确性和鲁棒性。
在金融领域,图和图分析帮助机构更高效地发现异常的关联交易,以赢得反洗钱战争。
在电力、电信行业,图数据库帮助管理复杂庞大的设备和线路网络,并及时为故障分析根源、估算影响。
在制造、科研、医药等领域,图数据库广泛用于存储和查询知识图谱,成为大数据管理、数据分析和价值挖掘乃至人工智能技术领域的重要支撑。
在可预见的未来内,图数据库与人工智能技术的结合应用将会带来更多创新和飞跃。图数据库至少能在以下四个领域帮助提升AI能力。
第一,知识图谱,它为决策支持提供领域相关知识/上下文,并且帮助确保答适合于该特定情况。
第二,图提供更高的处理效率,因此借助图来优化模型并加速学习过程,可以有效地增强机器学习的效率。
第三,基于数据关系的特征提取分析可以识别数据中最具预测性的元素。基于数据中发现的强特征所建立的预测模型拥有更高的准确性。
第四,图提供了一种保证AI决策透明度的方法,这使得通过AI得到的结论更加具有可解释性。AI和机器学习具有很大的应用潜力,而图解锁了这种潜力。这是因为图数据库技术支持领域相关知识和关联数据,使AI变得更广泛适用。
除此以外,近年来,云端部署的图数据库(SaaS/DaaS)成为了又一个发展趋势。国内的众多大厂纷纷推出自研的云端图数据库产品,例如百度的HugeGraph、阿里的GDB、腾讯的TGDB、华为的GES图计算引擎。
就总体趋势而言,我们能够预见,大数据时代,数据缺失不再是最大的挑战,我们渴求的是挖掘数据价值的能力,而数据的价值很大一部分在于数据之间的关联。图数据库和图分析作为处理关联数据最有效的技术和方法,一定会继续大放异彩,书写数据库应用的新篇章。
作者简介:
Neo4j亚太地区售前和技术总监,有二十余年IT从业经验。PMP、IEEE和ACS会员,PMP认证专家、欧盟GDPR认证专家、Neo4j数据库和图数据科学认证专家,并拥有金融市场(投资和交易)高级学位。
— 推荐阅读 —
*那天,比尔・盖茨差点“砍掉”了这个 160 亿美元的项目:不运行 Windows,是种侮辱
*“敏捷欺骗了开发人员”
*B站回应HR称核心用户是Loser;微博回应宕机原因;Go 1.19 正式发布|极客头条《新程序员001-004》已全面上市
扫描下方二维码或点击进入立即订阅
边栏推荐
猜你喜欢



随机推荐
Roslyn 在 msbuild 的 target 判断文件存在
Real-Time Rendering 4th related resource arrangement (no credit required)
进程间通信方式
flink cdc怎么指定位点,从某个位点开始消费mysql的Binlog?
功率放大器的设计要点
JVM Tuning-GC Fundamentals and Tuning Key Analysis
多商户商城系统功能拆解24讲-平台端分销会员
皕杰报表配置文件report_config.xml里都配置了什么?
【Go事】一眼看穿 Go 的集合和切片
2022-08-04日报:量化细胞内的信息流:机器学习时代下的研究进展
Pulsar消费者处理不当导致的消息积压问题
MySQL select加锁分析
Typora收费?搭建VS Code MarkDown写作环境
H5 开发内嵌页面跨域问题
开源一夏 | 请你谈谈网站是如何进行访问的?【web领域面试题】
The electromagnetic compatibility EMC protection study notes
【伸手党福利】投影仪初学者入门——投影亮度及幕布选择——从入门到精通
What is the difference between ITSM software and a work order system?
"Research Report on the Development of Global Unicorn Enterprises in the First Half of 2022" released - DEMO WORLD World Innovation Summit ended successfully
C# 写系统日志