当前位置:网站首页>ML - natural language processing - Basics
ML - natural language processing - Basics
2022-07-25 15:24:00 【sword_ csdn】
Catalog
Reference resources
Huawei cloud College
https://www.cnblogs.com/pinard/p/7160330.html
Language model
Language model is a language abstract modeling based on the objective facts of language , It's a correspondence , Suppose there are the following problems :
(1) Machine translation (I have a dream):P( I have a dream )>P( I have a dream )
(2) Spelling correction :P(about fifteen minutes from)>P(about fifteenminuets from)
(3) speech recognition :P( You look like your mother )>P( You look like your mother )
(4) Phonetic conversion :P( What are you doing now? |nixianzaiganshenme)>P( What are you doing in Xi'an |nixianzaiganshenme)
If we formalize the above problem , The chain rule can be expressed as follows 
Neural network language model


N - gram Language model
utilize n Metamodel (n-gram model) Estimate conditional probability , That is, ignore the distance greater than or equal to n The influence of the above words , Therefore, if the ratio of frequency counting is used to calculate n The meta conditional probability can be expressed as :
NN The relationship between language model and statistical language model
The same thing : They regard a sentence as a sequence of words , Then calculate the probability of the sentence
Difference :
(1) How to calculate probability :N-gram Based on Markov hypothesis, only the former n Word ,NNLM Consider the context of the whole sentence .
(2) How to train the model :N-gram Calculate parameters based on maximum likelihood estimation , It is based on the word itself ;NNLM be based on RNN Optimization method training model .
(3) The cyclic neural network can store any length of context information in the hidden state , Not limited to N-gram Window restrictions in the model .
Text vectorization
Express the text as a series of vectors that can express the semantics of the text . Commonly used vectorization algorithms are :one-hot,TF-IDF,word2vec(CBOW,Skip-gram),doc2vec/str2vec(DM,DBOW).
word2vec - CBOW Model
CBOW The training input of the model is the word vector corresponding to the context related word of a characteristic word , And the output is the word vector of this particular word .
For example, the following paragraph , Our context size is 4, The specific word is "Learning", That is, the output word vector we need , The words corresponding to the context are 8 individual , Before and after 4 individual , this 8 One word is the input of our model . because CBOW The word bag model is used , So this 8 All words are equal , That is, regardless of the distance between them and the words we focus on , As long as it's within our context .
word2vec - Skip-gram Model
Skip-Gram Models and CBOW On the contrary , That is, the input is a specific word vector , The output is the context word vector corresponding to a specific word . Or the example above , Our context size is 4, The specific word "Learning" It's our input , And this 8 A contextual word is our output .
doc2vec - DM Model
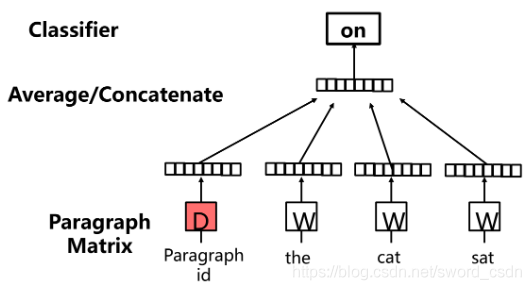
Each paragraph is represented as a vector , The corresponding matrix D A column vector in , Each word is represented as a vector , The corresponding matrix W A column vector in . Paragraph vectors and word vectors are averaged or connected to the context (context) Predict the next word in .
doc2vec - DBOW Model

The model samples a text window in each iteration of random gradient descent (text window), Then randomly sample a word from the text window , So as to form a multi classification task for word prediction with a given paragraph vector . The model and Skip-gram The model is similar .
边栏推荐
- 如何解决Visual Stuido2019 30天体验期过后的登陆问题
- Rediscluster setup and capacity expansion
- Spark SQL UDF function
- Implementation of asynchronous FIFO
- JVM-参数配置详解
- 剑指Offer | 二进制中1的个数
- 如何解决Visual Studio中scanf编译报错的问题
- Browser workflow (Simplified)
- C language function review (pass value and address [binary search], recursion [factorial, Hanoi Tower, etc.))
- Sublimetext-win10 cursor following problem
猜你喜欢
Idea remotely submits spark tasks to the yarn cluster

Yan required executor memory is above the max threshold (8192mb) of this cluster!
Spark AQE

Introduction to raspberry Pie: initial settings of raspberry pie
Debounce and throttle

Spark submission parameters -- use of files

Overview of JS synchronous, asynchronous, macro task and micro task
Outline and box shadow to achieve the highlight effect of contour fillet

ML - 语音 - 深度神经网络模型

异步fifo的实现
随机推荐
SublimeText-win10光标跟随问题
Spark SQL common time functions
Is it safe to open futures online? Which company has the lowest handling charge?
Spark DF增加一列
海缆探测仪TSS350(一)
Idea远程提交spark任务到yarn集群
Application of object detection based on OpenCV and yolov3
Promise object and macro task, micro task
oracle_ 12505 error resolution
ES5写继承的思路
图论及概念
Implementation of asynchronous FIFO
Reflection - Notes
记一次redis超时
LeetCode第 303 场周赛
Remember that spark foreachpartition once led to oom
Rediscluster setup and capacity expansion
JVM garbage collector details
Args parameter parsing
如何解决Visual Studio中scanf编译报错的问题