当前位置:网站首页>FCN中制作自己的数据集并进行训练
FCN中制作自己的数据集并进行训练
2022-07-31 10:09:00 【Keep_Trying_Go】
目录
2.FCN项目实战(使用PASCAL VOC 2012数据集)
1.FCN论文详解
https://mydreamambitious.blog.csdn.net/article/details/125966298
2.FCN项目实战(使用PASCAL VOC 2012数据集)
https://mydreamambitious.blog.csdn.net/article/details/125774545
注:
深度学习领域语义分割常用数据集:深度学习领域语义分割常用数据集:PASCAL VOC 2007 ,2012 NYUDv2 SUNRGBD CityScapes CamVid SIFT-Flow 7大数据集介绍_Keep_Trying_Go的博客-CSDN博客
3.图像数据集的收集
这里提供自己通过下载的图片制作的训练数据集,只有39张图片,读者首先可以使用这份数据集进行训练,没有问题之后跟着这个再制作自己的数据集(数据集的收集自己也可以从生活中收集,也不一定非要从网上下载,这样也许更有意义)。
链接:https://pan.baidu.com/s/1hUZYmy0iQ5dG4dbDD69ZwA
提取码:25d6
4.工具的选择
(1)工具一
labelme是一种多边形标注工具,可以准确的将轮廓标注出来,常用于分割。
labelme:这个款工具我没有使用过,其实这个使用方式和下面要介绍的labelImg使用方式一样。
安装:pip install labelme
打开:直接在下载的环境中输入:labelme参考链接:https://blog.csdn.net/weixin_44245653/article/details/119150966
(2)工具二
labelimg,是一种矩形标注工具,常用于目标识别和目标检测,可直接生成yolo读取的txt标签格式,但其只能进行矩形框标注。既然这个工具主要用于图像识别和目标检测,那么为什么可以用来制作分割数据集呢,主要是这里可以制作PASCAL VOC数据集,但是在最后不会生成标签文件,所以这款工具主要用于我们这个实战项目中生成.xml文件。
安装:pip install labelImg打开:直接在下载的环境中输入:labelImg首先打开工具:



点击保存之后会产生.xml 文件:

关于这款工具的简单使用就是这样,更多的可以参考B站视频学习。
(3)工具三
安装:
第一步:pip install paddlepaddle -i https://pypi.tuna.tsinghua.edu.cn/simple
第二步:pip install eiseg -i https://pypi.tuna.tsinghua.edu.cn/simple打开:eiseg也许在安装完成之后打开会报这个错。
AttributeError: module 'cv2' has no attribute 'gapi_wip_gst_GStreamerPipeline'
解决方法:
pip install --user --upgrade opencv-python -i https://pypi.tuna.tsinghua.edu.cn/simple
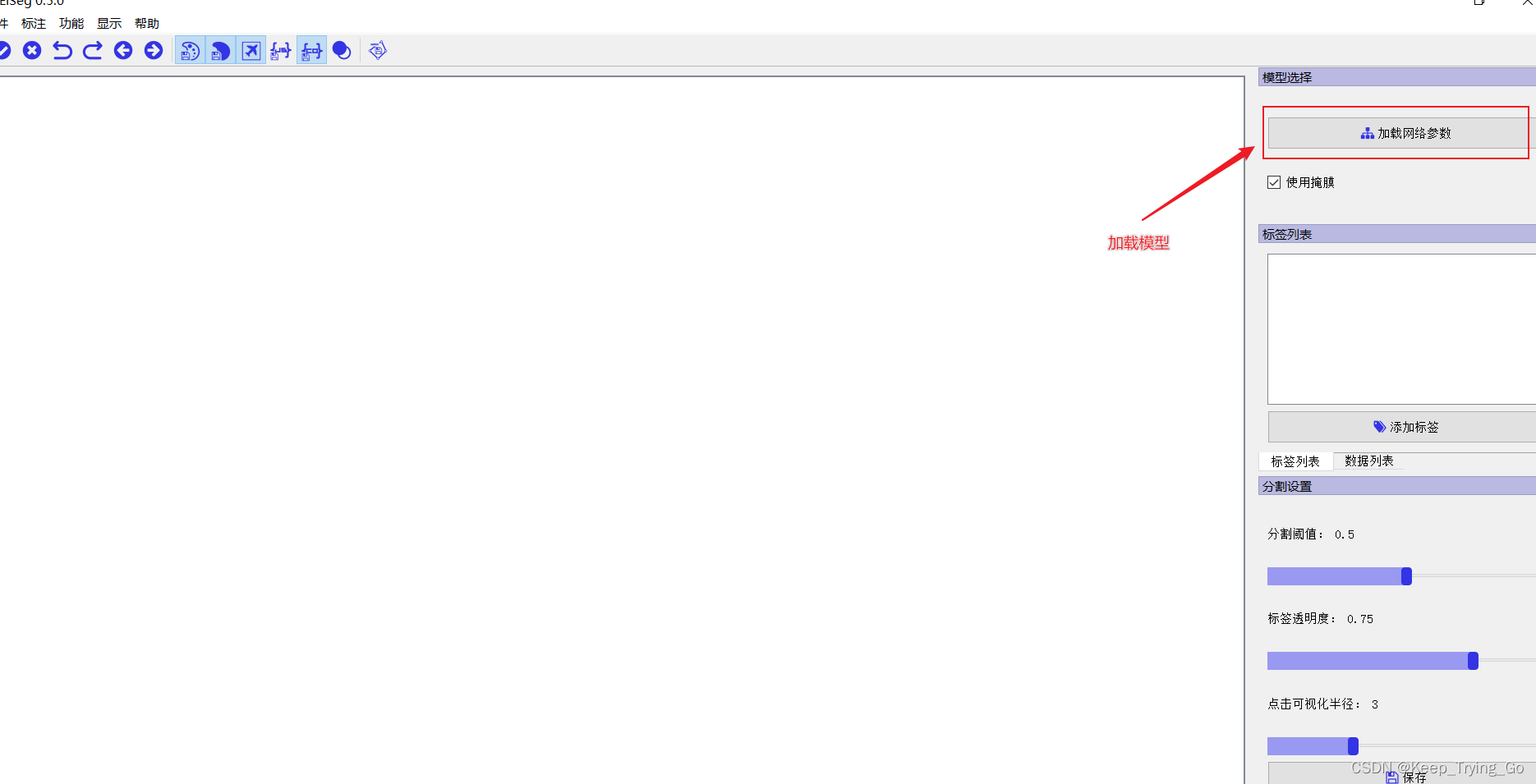
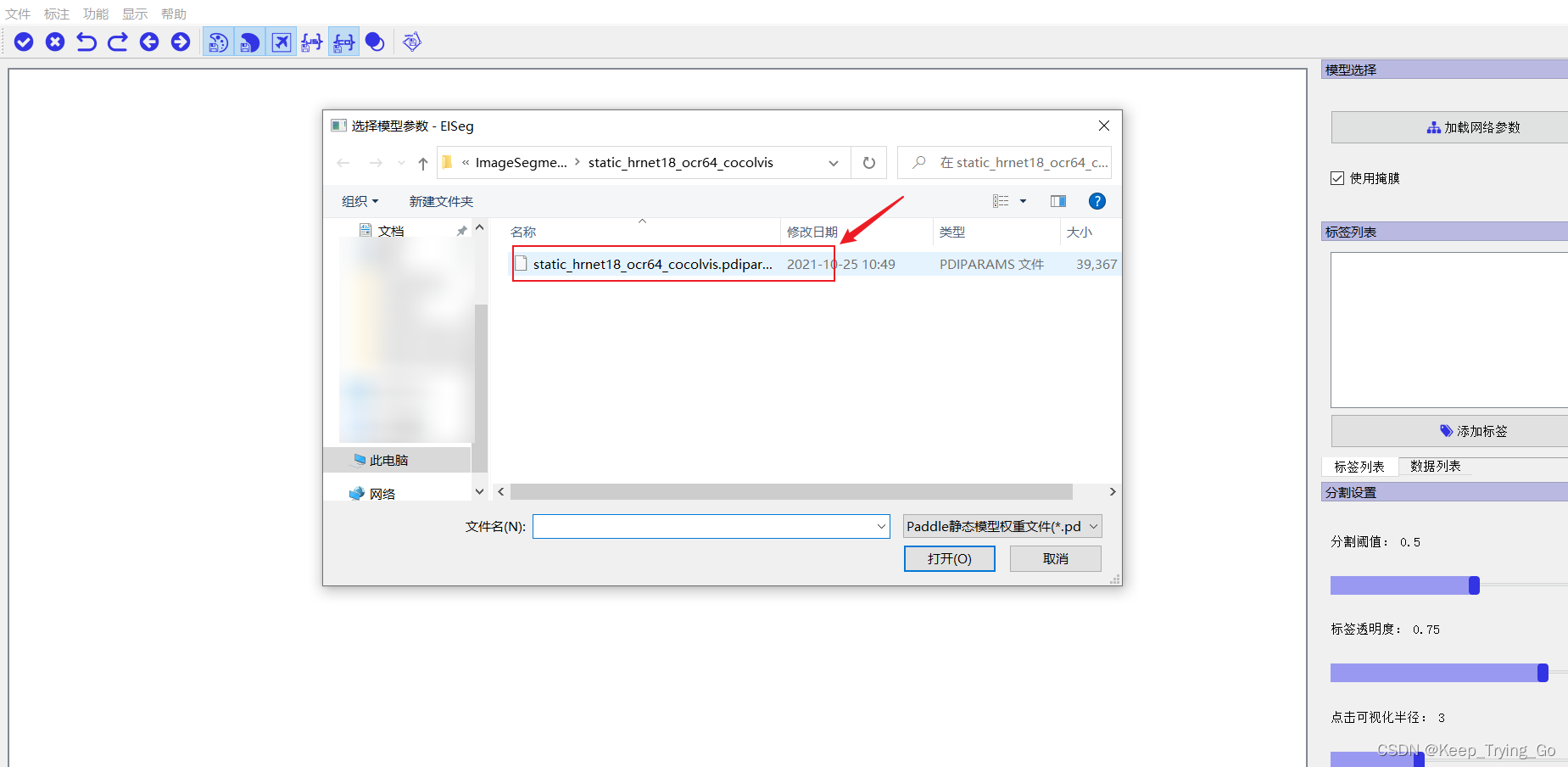
第一步首先加载模型参数:
| 模型类型 | 适用场景 | 模型结构 | 模型下载地址 |
| 高精度模型 | 通用场景的图像标注 | HRNet18_OCR64 | static_hrnet18_ocr64_cocolvis |
| 轻量化模型 | 通用场景的图像标注 | HRNet18s_OCR48 | static_hrnet18s_ocr48_cocolvis |
| 高精度模型 | 通用图像标注 | EdgeFlow | static_edgeflow_cocolvis |
| 高精度模型 | 人像场景标注 | HRNet18_OCR64 | static_hrnet18_ocr64_human |
| 轻量化模型 | 人像场景标注 | HRNet18s_OCR48 | static_hrnet18s_ocr48_human |
注:这里加载的模型根据自己标注的数据集情况来,比如适用的是什么场景的。
 第二步打开文件:
第二步打开文件:
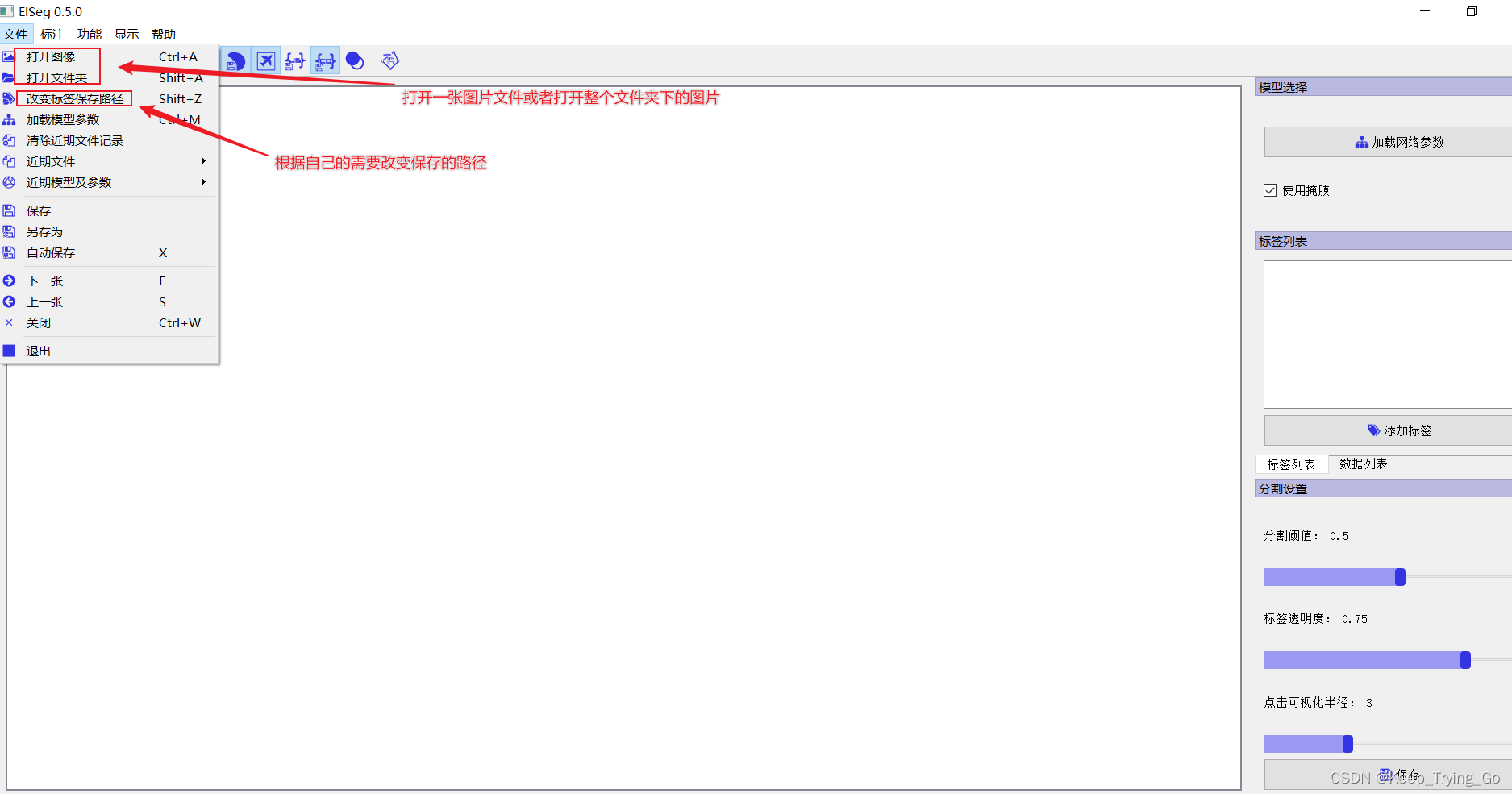

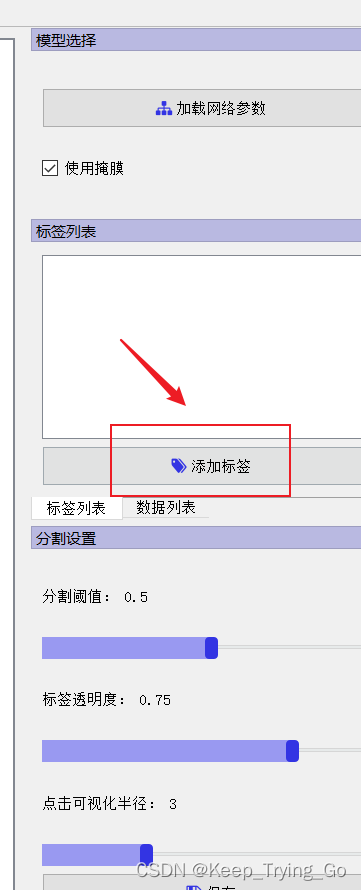
第三步添加标签:
 第四步选择保存的数据格式:JSON或者COCO
第四步选择保存的数据格式:JSON或者COCO
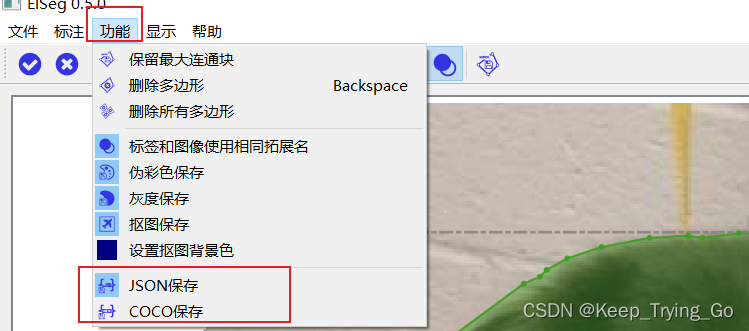 选择JSON就会每一张图片保存一个JSON文件,COCO数据格式只会保存在一个JSON文件中。
选择JSON就会每一张图片保存一个JSON文件,COCO数据格式只会保存在一个JSON文件中。
第五步点击目标即可进行图像标注(只需点击图像中的目标即可):

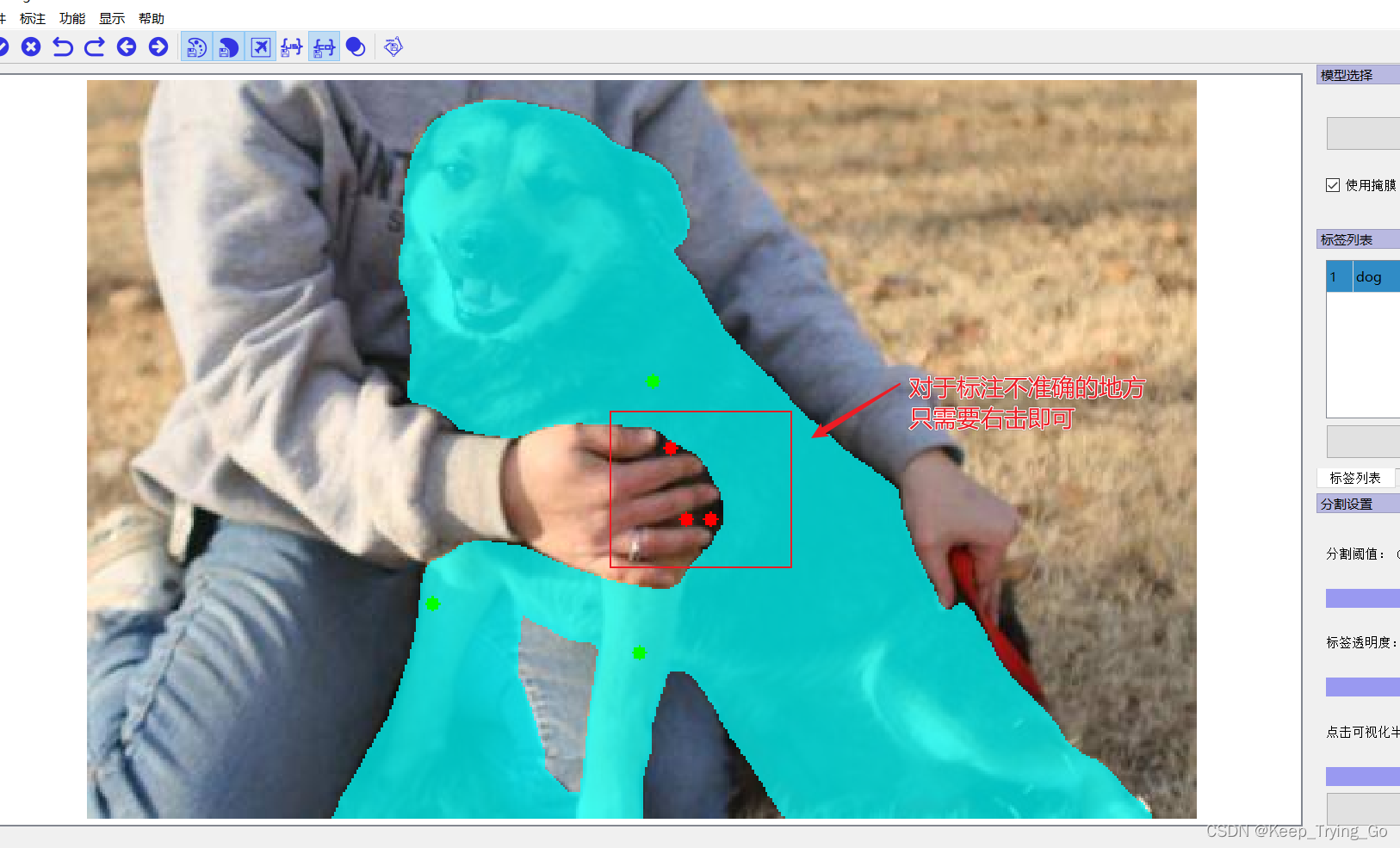
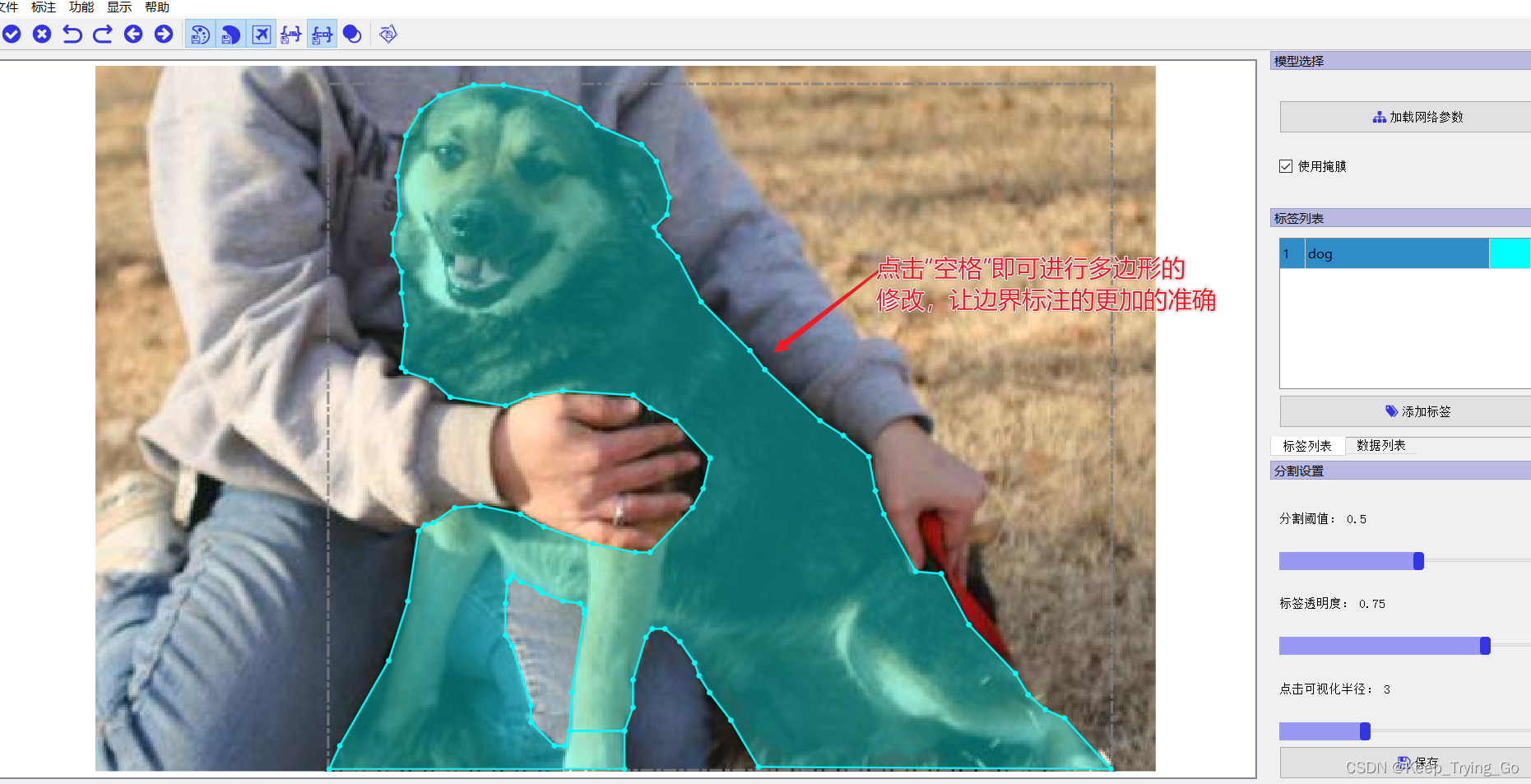


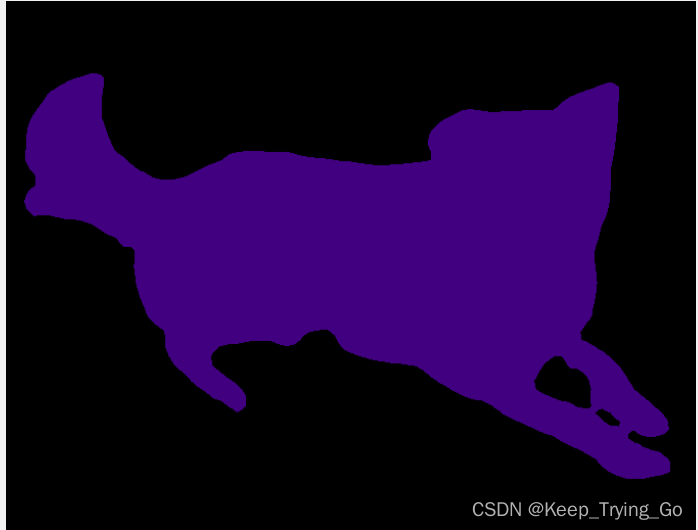
虽然我们要的是这样灰度的图,但是直接这样看不是很好,所以我们将其添加调色板:
import os
import cv2
import numpy as np
from PIL import Image
def palette():
#获取当前目录
root=os.getcwd()
#灰度图的位置
imgFile=root+'\\img'
#将所有的灰度图添加调色板
for i,img in enumerate(os.listdir(imgFile)):
filename, _ = os.path.splitext(img)
#这个地方需要将图片路径添加完整,不然后面读取图片文件不存在
img='img/'+img
img = cv2.imread(img, cv2.IMREAD_GRAYSCALE)
save_path=root+'\\imgPalette\\'+filename+'.png'
img = Image.fromarray(img) # 将图像从numpy的数据格式转为PIL中的图像格式
palette = []
for i in range(256):
palette.extend((i, i, i))
#这里设置21个颜色,其中背景为黑色,总共21个类别(包括背景)
palette[:3 * 21] = np.array([[0, 0,0],[0,255,255],[0, 128, 0],[128, 128, 0],[0, 0, 128],
[128, 0, 128],[0, 128, 128],[128, 128, 128],[64, 0, 0],[192, 0, 0],
[64, 128, 0],[192, 128, 0],[64, 0, 128],[192, 0, 128],[64, 128, 128],
[192, 128, 128],[0, 64, 0],[128, 64, 0],[0, 192, 0],[128, 192, 0],[0, 64, 128]
], dtype='uint8').flatten()
img.putpalette(palette)
# print(np.shape(palette)) 输出(768,)
img.save(save_path)
if __name__ == '__main__':
print('Pycharm')
palette()
代码参考:https://blog.csdn.net/weixin_39886251/article/details/111704330
工具选择的同时数据集的标注也完成了,即可进行下面的数据集存放的文件位置。
5. 数据集文件的位置
反正数据集不管怎么存放,都要根据程序的操作来,并不是说一定要和我的这个一样,你可以对程序进行修改(如果有什么报错,不要害怕,跟着错误的提示继续修改)。
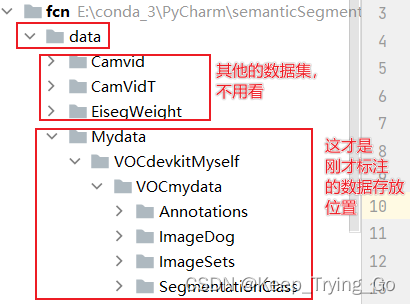
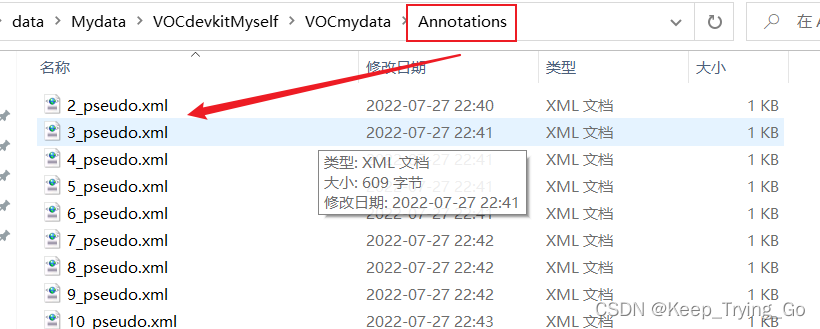


注:如果对于上面的文件放置位置不是很明白,可以自己下载那个PASCAL VOC 2012数据集,自己查看一下这个数据集的文件位置是怎么放的(其实自己可以修改程序,不一定非要按这样的格式来做)。
深度学习领域语义分割常用数据集:深度学习领域语义分割常用数据集:PASCAL VOC 2007 ,2012 NYUDv2 SUNRGBD CityScapes CamVid SIFT-Flow 7大数据集介绍_Keep_Trying_Go的博客-CSDN博客

6.训练数据集
train.py文件中的一些地方需要修改:数据集的位置,类别数。其他的根据自己的需要进行修改。
#数据集文件的位置
parser.add_argument("--data-path", default="data/Mydata/", help="VOCdevkit root")
#数据集的类别数
parser.add_argument("--num-classes", default=1, type=int)
#是否使用辅助分支
parser.add_argument("--aux", default=True, type=bool, help="auxilier loss")
#默认使用CPU设备
parser.add_argument("--device", default="cuda", help="training device")
#使用的batchsize大小
parser.add_argument("-b", "--batch-size", default=4, type=int)
#迭代的数量
parser.add_argument("--epochs", default=30, type=int, metavar="N",
help="number of total epochs to train")
#训练的学习率
parser.add_argument('--lr', default=0.0001, type=float, help='initial learning rate')
#训练的动量
parser.add_argument('--momentum', default=0.9, type=float, metavar='M',
help='momentum')
#权重延迟
parser.add_argument('--wd', '--weight-decay', default=1e-4, type=float,
metavar='W', help='weight decay (default: 1e-4)',
dest='weight_decay')
#训练多少个epoch打印一次
parser.add_argument('--print-freq', default=10, type=int, help='print frequency')
#当训练出现中断时,重新加载从上一次中断的权重文件开始训练
parser.add_argument('--resume', default='', help='resume from checkpoint')
#开始训练的epoch
parser.add_argument('--start-epoch', default=0, type=int, metavar='N',
help='start epoch')
# Mixed precision training parameters
parser.add_argument("--amp", default=False, type=bool,
help="Use torch.cuda.amp for mixed precision training")
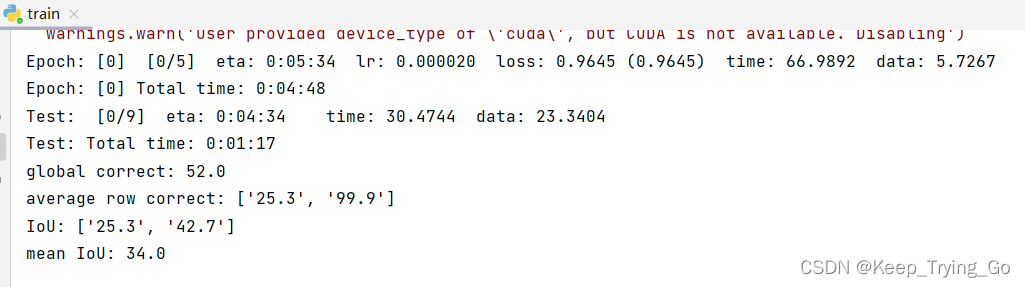

进行预测的文件predict.py:

边栏推荐
- 【职场杂谈】售前工程师岗位的理解杂谈
- Module eight
- Are postgresql range queries faster than index queries?
- 细讲DDD领域驱动设计
- Flink1.15 source code reading flink-clients - flink command line help command
- Binary tree search and backtracking problem (leetcode)
- Canvas particles change various shapes js special effects
- 如何将亚马逊广告添加到您的 WordPress 网站(3 种方法)
- 【GORM】存取数组/自定义类型数据
- loadrunner-controller-view script与load generator
猜你喜欢






随机推荐
loadrunner-controller-手动场景Schedule配置
NowCoderTOP23-27 Binary tree traversal - continuous update ing
win10镜像下载
[NLP] Interpretation of Transformer Theory
loadrunner-Controller负载测试-各模块功能记录01测试场景设计
模块八
Add a shuffling effect to every pie
Gradle series - Groovy overview, basic use (based on Groovy document 4.0.4) day2-1
NowCoderTOP17-22 Binary search/sort - continuous update ing
ReentrantLock
loadrunner-controller-场景执行run
Are postgresql range queries faster than index queries?
怎样使用浏览器静默打印网页
踩水坑2 数据超出long long
【LeetCode】118.杨辉三角
我们能做出来数据库吗?
第二十三课,抗锯齿(Anti Aliasing)
WEB核心【记录网站登录人数,记录用户名案例】Cookie技术实现
比较并交换 (CAS) 原理
Dart Log工具类