当前位置:网站首页>链表实现及任务调度
链表实现及任务调度
2022-07-31 06:08:00 【南波儿万】
链表实现
1.概述
第一次接触链表的时候是大学的数据结构课上,当时设计的链表就是针对某种数据结构的链表。后来学习了C++,由于C++支持泛型编程所以链表可以被设计成可以应用在任意的数据类型中。但是,如何能将C语言的链表应用在任意数据类型的应用场景下是一直困扰我的问题。直到我接触了Linux的内核链表,它的设计思想直接惊艳到了我。
下面我们先从使用者的角度去试着理解其内部设计的精妙之处。
2.既然链表不能包含所有数据类型那就让所有数据类型都可以包含链表
标题既是Linux内核设计链表的核心思想,Linux内核链表是一个双向循环链表。它被设计为只有链表指针,用户如果想使用链表就在自己的数据结构中包含链表。
struct list_head{
struct list_head *next, *prev;
};
3.使用步骤
1.在自己的数据结构中包含链表头
下面以bcos中tasklet链表为例:
typedef struct bcos_tasklet_s
{
/* 链表头 */
struct list_head list;
/* 回调函数 */
void (*handler)(void *ptr);
void *ptr;
BC_OS_TICK stamp;
}bcos_tasklet_t;
2.初始化、插入、删除
这是链表使用过程中最基本的三个操作,下面看看Linux内核链表是如何实现的:
1)初始化:
static inline void INIT_LIST_HEAD(struct list_head *list){
list->next = list;
list->prev = list;
}
链表在初始化时将next和prev指针指向链表头,这样既方便判断链表是否为空,也方便遍历和插入。
当然判断链表是否为空也是根据链表头的两个指针是否指向自己判断的:
static inline int list_empty(const struct list_head *head){
return head->next == head;
}
2)插入:
插入操作很简单,就是传入新节点、新节点的前驱和后继即可将新节点串入链表:
static inline void __list_add(struct list_head *new_,
struct list_head *prev,
struct list_head *next){
next->prev = new_;
new_->next = next;
new_->prev = prev;
prev->next = new_;
}
上图把插入的过程已经画的很清楚了,这里就不再赘述。另外,基于上面的函数我还提供了两个额外的函数,他们分别时将新节点插入到链表的头和尾。

static inline void list_add(struct list_head *new_,
struct list_head *head){
__list_add(new_, head, head->next);
}
static inline void list_add_tail(struct list_head *new_,
struct list_head *head){
__list_add(new_, head->prev, head);
}
3)删除
删除的过程也很容易理解,都是对链表指针的操作,这里就不再赘述。
static inline void __list_del(struct list_head *prev,
struct list_head *next){
next->prev = prev;
prev->next = next;
}
static inline void list_del(struct list_head *entry){
__list_del(entry->prev, entry->next);
entry->next = NULL;
entry->prev = NULL;
}
static inline void list_del_init(struct list_head *entry){
__list_del(entry->prev, entry->next);
INIT_LIST_HEAD(entry);
}
4)如何从list_head的指针获取链表节点的数据域?
想必到这里很多读者会有这样的疑问,而这个疑问恰恰时Linux内核链表设计与实现过程中的高明之处。C语言的寻址方式是基地址加偏移地址。在一个结构体中如果我们知道了某一个元素在结构体中的偏移地址,那我们就可以根据该元素的地址找到对应的结构体变量的基地址。
typedef struct bcos_tcb_s {
/* Pointer to current top of stack */
BC_OS_STK *OSTCBStkPtr;
/* 链表头 */
struct list_head list;
/* 优先级 */
uint8_t priority;
/* 延时时间戳 */
BC_OS_TICK delay_stamp;
} bcos_tcb_t;
上面是bcos任务控制块的结构体定义,我们发现链表头不是在结构体的最前面定义的,由于栈指针在结构体中占4个字节,所以链表头在结构体中的offset = 4,如果知道此时list元素的地址,在该地址的基础上减4就得到了结构体变量的指针。这样我们就获得到了链表节点对应的数据域。我不知道我描述的是否清晰,下面给出我实际调试过程中的截图,方便读者理解。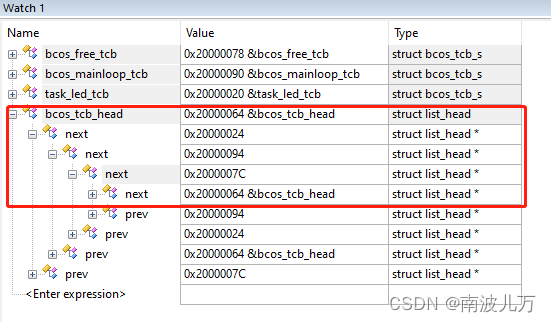
从图中可以看到我的任务就绪链表中有三个节点,其链表头的地址分别是0x20000024、0x20000094、0x2000007C,细心的读者可能已经观察到了,在红框的上面有三个bcos_tcb_t的结构体变量task_led_tcb(0x20000020)、bcos_mainloop_tcb(0x20000090)、bcos_free_tcb(0x20000078)。图中的各变量的类型也很清晰,我们如何通过链表节点找到对应数据结构体的指针就一目了然了。具体如何实现,其关键就是这个offset的计算:
//技术结构体元素相对与结构体首地址的offset
#define offsetof(TYPE, MEMBER) ((size_t) &((TYPE *)0)->MEMBER)
#define container_of(ptr, type, member) ({
\ const typeof( ((type *)0)->member) *__mptr = (ptr); \ (type *)( (char *)__mptr - offsetof(type, member) );})
上面两个宏的实现是整个链表实现过程中的精髓,他们实现了从链表节点获取数据域的方法。上面这两个宏的实现有很多文章对其分析的非常详细,感兴趣的读者可以再深入研究。
5)遍历
/** * list_entry - get the struct for this entry. * @ptr: the &struct list_head pointer. * @type: the type of the struct this is embedded in. * @member: the name of the list_head within the struct. */
#define list_entry(ptr, type, member) container_of(ptr, type, member)
/** * list_for_each_entry_safe - iterate over list of given type safe against * removal of list enty. * @pos: the type * to use as a loop sursor. * @n: another type * to use as temporary storage. * @head: the head for your list. * @member: the name of the list_struct within the strut. */
#define list_for_each_entry_safe(pos, n, head, member) \ for (pos = list_entry((head)->next, typeof(*pos), member), \ n = list_entry(pos->member.next, typeof(*pos), member); \ &pos->member != (head); \ pos = n, n = list_entry(n->member.next, typeof(*n), member))
/** * list_for_each_entry_reverse - iterate backwards over list of given type. * @pos: the type * to use as a loop cursor. * @head: the head for your list. * @member: the name of the list_struct within the struct. */
#define list_for_each_entry_reverse(pos, head, member) \ for(pos = list_entry((head)->prev, typeof(*pos), member);\ prefetch(pos->member.prev), &pos->member != (head); \ pos = list_entry(pos->member.prev, typeof(*pos), member))
遍历接口的实现其实是用宏对for循环的封装,使用户不必关心遍历结束的条件、数据域的获取等问题。这里给一个插入、删除、遍历的例子:
/** * 在列表中升序插入,值更小的靠近链表头 */
#define list_ascending_order_add(new_, pos, n, head, member, condition_member) \ do{
\ if(!list_empty(head)) \ {
\ list_for_each_entry_safe(pos, n, head, member) \ {
\ if(pos->condition_member > new_->condition_member) \ {
\ list_add_tail(&new_->member, &pos->member); \ break; \ } \ } \ } \ /* 如果节点没有被插入队列,则empty检查为空,前提是对节点进行初始化 */ \ if(list_empty(&new_->member)) \ {
\ list_add_tail(&new_->member, head); \ } \ }while(0)
总结
该链表的实现方案的高明之处就是将链表的操作跟数据域完全分开了,通过一套接口可以适用于所有类型的数据。当然同样的思路也可以应用在许多其他的程序设计方案中。在应用篇中的单向循环链表的实现原理也是一样的,另外详细的使用示例可以参考应用篇。
任务调度
1.概述
任务调度是实现一个多任务操作系统的核心目标,系统中有多个任务有的执行的时间长有的执行的时间短。我们应该让那个任务先执行让那个任务后执行?让一个任务执行多长时间?这是任务调度需要解决的问题。bcos实时操作系统在设计的过程中参考了ucos的调度算法,是一个基于优先级的调度过程。简单点说是如下过程:
1.系统中有多个待执行的任务,每个任务有一个优先级。系统会根据任务的优先级进行排序,然后首先执行优先级最高的任务。
2.每个任务必须要有一段时间的延时,在该任务延时的过程中系统会将该任务放入等待队列,并调度执行系统中优先级最高的任务。
3.任务延时超时后,该任务会被重新放入就绪队列中进行调度执行。
2.任务的调度策略
这一部分的内容注定是枯燥无味的,我将尽力将其原理描述清楚。其实在概述里已经简单的描述了bcos的调度策略,这是我经过很长时间的摸索及深思熟虑后做出的选择。其实,在现在已经存在的嵌入式操作系统中大家的调度策略虽然各有不同但总结起来无非就那么几种。
- 基于时间片的调度;
- 基于优先级的调度;
- 以上两种方式相结合;
由于作者第一次接触的嵌入式操作系统是ucos,所以对ucos的调度策略非常熟悉。所以在bcos的设计过程中有意无意的借鉴了ucos的调度策略。在bcos中的任务有三种状态:就绪态、运行态和等待态,处于就绪态的任务会按照任务优先级在就绪队列中排队等待执行,处于等待态的任务会按照等待时间的长短在等待队列中排队等到其超时后被加入到就绪队列中等待执行。系统每次调度会从就绪队列中取出排在队头优先级最高的任务执行,如果就绪队列中没有比空闲任务优先级更高的任务时,系统会在空闲任务中空转。文字描述可能不好理解,下面给出任务状态切换图:
从上面的任务状态转换图可以看出,触发任务切换的条件只有两种:任务延时和任务挂起,而这两个条件最终的表现都是当前执行任务主动放弃CPU的控制权进而实现任务的切换。所以,在bcos中的每一个用户任务都必须在合适的时候进行任务延时或将任务挂起。否则,该任务将独占CPU执行权而其他任务将无限期的等待也无法得到执行。
3.空闲任务
空闲任务是bcos中的一个特殊的任务,它在bcos系统初始化时系统会主动的建立一个空闲任务。由于bcos在任何时刻都必须有一个任务供CPU执行,所以当系统中没有用户任务可执行时系统只能执行空闲任务。正常情况下空闲任务只负责CPU的空转,但实际上在bcos中空闲任务还有别的工作要做。这将在后面的章节中进行描述,另外空闲任务是系统中优先级最低的任务(优先级为0xFF,在bcos中优先级数值越小优先级越高),所以当系统中有其他任务时空闲任务将被抢占。
4.任务的管理
bcos用两个双向循环链表来管理系统中的任务,就绪任务被就绪任务链表管理,挂起和等待任务被任务等待链表管理。其中就绪任务按照任务优先级在就绪链表中排序,等待任务按照等待时间戳的大小在等待链表中排序,另外,挂起任务的等待时间戳被设置为0xFFFFFFFFFFFFFFFF(tick数用一个64为的整数存储)。这样,当任务需要放弃cpu控制权进行任务等待或任务挂起时,系统将当前任务从就绪任务队列中移动到等待任务队列中,然后再从就绪任务队列中选择队首的任务(优先级最高的就绪任务)执行。当任务延时超时时,系统会将该任务根据优先级添加到就绪队列中等待系统调度执行。任务管理的实现如下:
/*
* 系统调度
*/
void bcos_scheduing(void)
{
uint32_t cpu_sr;
bcos_tcb_t *first, *pos, *n;
/* 屏蔽中断 */
OS_ENTER_CRITICAL();
/* 任务等待队列不为空 */
if (!list_empty(&bcos_waiting_tcb_head))
{
/* 从任务等待队列中检查是否有超时任务 */
first = list_first_entry(&bcos_waiting_tcb_head, bcos_tcb_t, list);
if (first->delay_stamp <= bcos_ticks)
{
/* 任务等待超时,从等待队列中删除任务并添加到就绪队列中 */
list_del_init(&first->list);
list_ascending_order_add(first, pos, n, &bcos_tcb_head, list, priority);
}
}
first = list_first_entry(&bcos_tcb_head, bcos_tcb_t, list);
/* 比较任务优先级,判断是否可以抢占 */
if(first->priority < OSTCBCur->priority)
{
OSTCBHighRdy = first;
OSCtxSw();
}
OS_EXIT_CRITICAL();
}
该函数再SYSTICK中断中执行,主要负责检查任务等待队列中的任务是否有等待超时的任务,如果有就将等待超时任务移出任务等待队列并添加到就绪任务中等待调度。在函数返回前检查了一下是否需要进行任务切换。
任务是何时被放到任务等待队列的?有人可能会有这样的疑问。其实,在嵌入式系统运行的过程中每一个任务的执行总是需要一定时间的延时等待,比如等待串口数据发送完成、等待用户数据的到达等。任务在等待的这段时间可以让CPU去执行其他有意义的操作而不是空转浪费CPU时间。当然,这就是开发操作系统的意义所在。所以,bcos提供了系统延时函数来实现任务的调度和切换。
void bcos_delay_ms(BC_OS_TICK tick)
{
uint32_t cpu_sr = 0;
bcos_tcb_t *pos, *n;
BC_OS_TICK stamp = bcos_ticks + tick;
OS_ENTER_CRITICAL();
/* 如果当前任务是空闲任务则直接返回 */
if(OSTCBCur->priority == BCOS_FREE_TASK_PRO)
goto exit;
list_del_init(&OSTCBCur->list);
OSTCBCur->delay_stamp = stamp;
/* 将任务加入到等待队列中 */
list_ascending_order_add(OSTCBCur, pos, n, &bcos_waiting_tcb_head, list, delay_stamp);
OSTCBHighRdy = list_first_entry(&bcos_tcb_head, bcos_tcb_t, list);
OSCtxSw();
exit:
OS_EXIT_CRITICAL();
}
从上面的代码实现可以看出,任务延时函数的实现非常简单,就是设置任务超时的时间戳后将任务从就绪任务队列中移除并将任务添加到等待任务队列中,并进行任务切换,将CPU切换到当前最高优先级的任务上运行。
边栏推荐
- 【并发编程】ReentrantLock的lock()方法源码分析
- R——避免使用 col=0
- CHI论文阅读(1)EmoGlass: an End-to-End AI-Enabled Wearable Platform for Enhancing Self-Awareness of Emoti
- 【科普向】5G核心网架构和关键技术
- Some derivation formulas for machine learning backpropagation
- Moment.js common methods
- 2022.07.18_每日一题
- [PSQL] 复杂查询
- 04-SDRAM: Read Operation (Burst)
- Automatic translation software - batch batch automatic translation software recommendation
猜你喜欢







随机推荐
Log4net 思维导图
Gradle剔除依赖演示
【C语言项目合集】这十个入门必备练手项目,让C语言对你来说不再难学!
tidyverse笔记——dplyr包
[PSQL] SQL基础教程读书笔记(Chapter1-4)
强化学习科研知识必备(数据库、期刊、会议、牛人)
Analysis of the implementation principle and detailed knowledge of v-model syntactic sugar and how to make the components you develop support v-model
opencv、pil和from torchvision.transforms的Resize, Compose, ToTensor, Normalize等差别
【并发编程】ReentrantLock的lock()方法源码分析
单点登录 思维导图
Zero-Shot Learning & Domain-aware Visual Bias Eliminating for Generalized Zero-Shot Learning
iOS大厂面试查漏补缺
Jobject 使用
PCB抄板
【编程题】【Scratch三级】2022.03 冬天下雪了
Difficulty comparison between high concurrency and multithreading (easy to confuse)
Third-party library-store
项目 - 如何根据最近30天、最近14天、最近7天、最近24小时、自定义时间范围查询MySQL中的数据?
科普 | “大姨太”ETH 和 “小姨太”ETC的爱恨情仇
【云原生】3.3 Kubernetes 中间件部署实战