当前位置:网站首页>Interviewer: how to solve the problem of massive requests for data that does not exist in redis, which affects the database?
Interviewer: how to solve the problem of massive requests for data that does not exist in redis, which affects the database?
2022-06-30 00:38:00 【Zhuxiaosi】
Click on the above “ Zhu Xiaosi's blog ”, choice “ Set to star ”
The background to reply " book ", obtain
The background to reply “k8s”, Can claim k8s Information
Everybody knows , In the computer ,IO It has always been a bottleneck , Many frameworks, technologies and even hardware are designed to reduce IO Born from operation , Let's talk about filters today , Let's start with a scene :
Our business backend involves databases , When a request message queries for some information , You may first check whether there is relevant information in the cache , If so, return to , If not, you may have to query in the database , There is a problem at this time , If many requests are for data that does not exist in the database , Then the database must respond frequently to this unnecessary IO Inquire about , If more , Most databases IO Are responding to such meaningless requests .
So how to keep these requests out ? The filter was born !
The bloon filter
The bloon filter (Bloom Filter) The general idea is , When the information you requested comes , First check the data you queried. Do I have , If so, push the request to the database , If not, go back to , how ?

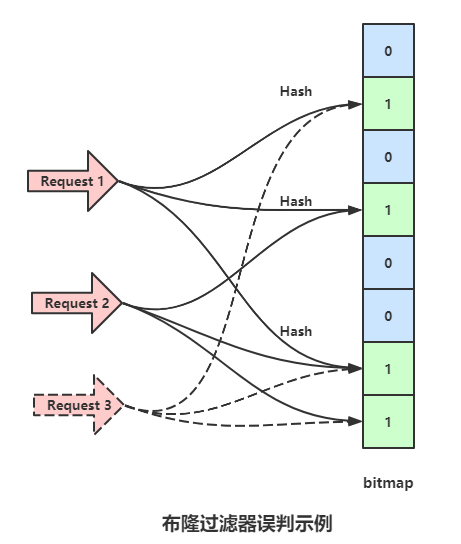
Pictured , One bitmap Used to record ,bitmap The original values are all 0, When a data is saved , With three Hash The function is calculated three times Hash value , And will bitmap The corresponding position is set to 1.
Above picture ,bitmap Of 1,3,6 The location is marked as 1, At this time, if a data request comes , Still use the previous three Hash Function calculation Hash value , If it's the same data , It must still be mapped to 1,3,6 position , Then it can be judged that the data has been stored before , If the three locations of the new data map , One doesn't match , If mapped to 1,3,7 position , because 7 Is it 0, That is, this data has not been added to the database before , So go straight back .
The problem with the bloom filter
This way up here , You should have found out , There are some problems with the bloom filter :
The first on the one hand, , The bloom filter may misjudge :
If there is such a scenario , Put the packet 1 when , take bitmap Of 1,3,6 Bit set to 1, Put the packet 2 When will bitmap Of 3,6,7 Bit set to 1, At this point, a packet request that has not been saved 3, After hashing three times , Corresponding bitmap The loci are 1,6,7, This data has not been saved before , But because of the packet 1 and 2 When saving, set the corresponding point to 1, So request 3 It will also overwhelm the database , This situation , It will increase with the increase of stored data .
In the second , The bloom filter cannot delete data , There are two difficulties in deleting data :
One is , Due to the possibility of misjudgment , Not sure if the data exists in the database , For example, packets 3.
Two is , When you delete the flag on the bitmap corresponding to a packet , May affect other packets , For example, in the example above , If you delete a packet 1, It means that bitmap1,3,6 Bit is set to 0, At this point, the packet 2 To request , Does not exist , because 3,6 The two bits have been set to 0.
Bloom filter plus
In order to solve the problem of Bloom filter above , An enhanced bloom filter appears (Counting Bloom Filter), The idea of this filter is to combine the bitmap Replace with array , When a position in the array is mapped once +1, When deleted -1, This avoids the need to recalculate the remaining packets after the data is deleted by the ordinary bloom filter Hash The problem of , But there is still no way to avoid misjudgment .

Cuckoo filter
In order to solve the problem that the bloom filter cannot delete elements , The paper 《Cuckoo Filter:Better Than Bloom》 The author proposes a cuckoo filter . Compared to the cuckoo filter , The bloom filter has the following shortcomings : Poor query performance 、 The efficiency of space utilization is low 、 Reverse operation is not supported ( Delete ) And it doesn't support counting .
Poor query performance Because the bloom filter needs to use multiple hash Function to detect multiple different sites in a bitmap , These sites span a wide range of memory , It can lead to CPU Cache row hit rate is low .
Space efficiency is low Because at the same misjudgment rate , The space utilization rate of cuckoo filter is significantly higher than that of bloom , Space can probably be saved 40% many . However, the bloom filter does not require that the length of the bitmap must be 2 The index of , The cuckoo filter must have this requirement . From this point of view , It seems that bloom filter has more spatial scalability .
Reverse delete operation is not supported This problem really hit the soft rib of Bloom filter . In a dynamic system, elements always come and go . The bloom filter is like an imprint , Come here, there will be traces , Even if you leave, you can't clean it up . For example, your system only left 1kw Elements , But on the whole, there are hundreds of millions of water elements , Bloom filter is helpless , It will store the imprints of these lost elements there forever . As time goes by , This filter will get more and more crowded , Until one day you find that its misjudgment rate is too high , Have to rebuild .
Cuckoo filter claims to have solved this problem , It can effectively support reverse deletion . And make it an important selling point , Tempt you to give up the bloom filter and switch to the cuckoo filter .
Why is it called cuckoo ?
There is an idiom ,「 Dog in the manger 」, So are cuckoos , Cuckoos never build their own nests . It lays its eggs in other people's nests , Let others help hatch . After the little cuckoo broke its shell , Because cuckoos are relatively large , It will be the adoptive mother's other children ( Or eggs ) Squeeze out of the nest —— Fell from a high altitude and died .
Cuckoo
The simplest cuckoo hash structure is a one-dimensional array structure , There will be two. hash The algorithm maps the new element to two positions in the array . If one of the two positions is empty , Then you can put the elements directly in .
But if both positions are full , It has to 「 Dog in the manger 」, Kick one at random , Then he occupied this position .
p1 = hash1(x) % l
p2 = hash2(x) % lUnlike cuckoos , The cuckoo hash algorithm will help these victims ( Squeezed eggs ) Look for other nests . Because each element can be placed in two places , As long as any free position , You can put it in .
So the sad egg will see if his other position is free , If it is empty , Move over and everyone will be happy . But what if this position is occupied by others ? good , Then it will do it again 「 Dog in the manger 」, Transfer the victim's role to others . Then the new victim will repeat the process until all the eggs find their nests .
Cuckoo hash problem
But there's a problem , That is, if the array is too crowded , Kicking around hundreds of times without stopping , This will seriously affect the insertion efficiency . At this time, cuckoo hash will set a threshold , When the continuous nesting behavior exceeds a certain threshold , I think this array is almost full . At this time, it needs to be expanded , Repositioning all elements .
There will be another problem , That is, there may be a run cycle . For example, two different elements ,hash The next two positions are exactly the same , At this time, they have no problem in one position . But here comes the third element , it hash Then the position is the same as them , Obviously , There will be a run cycle . But let three different elements go through twice hash The back position is the same , This probability is not very high , Unless it's yours hash The algorithm is too frustrating .
Cuckoo hash algorithm's attitude towards this run cycle is that the array is too crowded , Need to expand ( It's not like that ).
Optimize
The average space utilization of the cuckoo hash algorithm above is not high , Perhaps only 50%. At this percentage , The number of consecutive runs will soon exceed the threshold . The value of such a hash algorithm is not obvious , So it needs to be improved .
One of the improvements is to increase hash function , Let each element have more than two nests , But three nests 、 Four nests . This can greatly reduce the probability of collision , Increase space utilization to 95% about .
Another improvement is to hang multiple seats in each position of the array , So even if the two elements are hash In the same position , You don't have to 「 Dog in the manger 」, Because there are multiple seats here , You can sit anywhere you like . Unless there are more seats , A run is needed .
Obviously, this will also significantly reduce the number of runs . The space utilization of this scheme is only 85% about , But the query efficiency will be very high , Multiple seats in the same memory space , Can be used effectively CPU Cache .
Therefore, a more efficient solution is to integrate the above two improved solutions , For example, use 4 individual hash function , On each position 2 A seat . In this way, we can get time efficiency , You can also get space efficiency . Such a combination can even increase the space utilization 99%, This is a great space efficiency .
Cuckoo filter
The cuckoo filter is the same as the cuckoo hash structure , It's also a one-dimensional array , But unlike cuckoo hash , Cuckoo hashes store the entire element , The cuckoo filter only stores the fingerprint information of the element ( How many? bit, Similar to bloom filter ). Here, the filter sacrifices the accuracy of the data for spatial efficiency . It is precisely because the fingerprint information of the element is stored , So there will be a misjudgment rate , This is the same as the bloom filter .
First of all, cuckoo filter will only use two hash function , But each position can hold multiple seats . these two items. hash The function selection is special , Because only fingerprint information can be stored in the filter . When the fingerprints in this position are run , It needs to calculate another dual position . The calculation of this dual position requires the element itself , Let's recall the previous hash position calculation formula .
fp = fingerprint(x)
p1 = hash1(x) % l
p2 = hash2(x) % lWe know p1 and x The fingerprints of , There is no way to directly calculate p2 Of .
special hash function
The clever thing about cuckoo filter is that it designs a unique hash function , So that it can be based on p1 and Elemental fingerprints Calculate directly p2, Without the need for a complete x Elements .
fp = fingerprint(x)
p1 = hash(x)
p2 = p1 ^ hash(fp) // Exclusive or As can be seen from the above formula , When we know fp and p1, You can directly calculate p2. Similarly, if we know p2 and fp, It can also be calculated directly p1 —— Duality .
p1 = p2 ^ hash(fp)So we don't need to know the current position is p1 still p2, Just put the current location and hash(fp) The dual position can be obtained by XOR calculation . And just make sure hash(fp) != 0 To make sure p1 != p2, In this way, there will be no problem that kicking yourself leads to a dead cycle .
Maybe you'll ask why it's here hash The function does not need to modulo the length of the array ? It's actually needed , However, the cuckoo filter forces that the length of the array must be 2 The index of , So modulo the length of an array is equivalent to modulo hash At the end of the value n position . During XOR operation , Ignore the low n position Just other bits . The calculated position p Keep it low n Bit is the final dual position .
link :www.cnblogs.com/Courage129/p/14337466.html
Want to know more ? Scan the QR code below and follow my background reply " technology ", Join the technology group
The background to reply “k8s”, Can claim k8s Information
【 Highlights 】ClickHouse What is it ? Why is it so cool !
original ElasticSearch That's understandable
interviewer :InnoDB One of them B+ How many rows of data can a tree hold ?
The way of Architecture : Separate business logic from technical details
Starbucks doesn't use two-phase commit
interviewer :Redis The new version begins to introduce multithreading , Tell me what you think ?
Himalaya self research gateway architecture evolution process
Collection : A comprehensive summary of storage knowledge
Microblog tens of millions of scale, high performance and high concurrency network architecture design
边栏推荐
- @Bugs caused by improper use of configurationproperties
- 出门在外保护好自己
- 字节面试惨遭滑铁卢:一面就被吊打,幸得华为内推,三面拿到offer
- 云呐|固定资产系统管理的优势,固定资产管理系统有何特点
- Yunna | advantages of fixed assets system management, what are the characteristics of fixed assets management system
- 炒股开户选择哪家证券公司比较好哪家平台更安全
- 中小企业签署ERP合同时,需要注意这几点
- Stream collectors usage
- Which direction of network development is better? Data communication engineer learning path sharing
- 简单的页面
猜你喜欢

初始I/O及其基本操作
![[MRCTF2020]Ezpop-1|php序列化](/img/f8/6164b4123e0d1f3b90980ebb7b4097.png)
[MRCTF2020]Ezpop-1|php序列化

传统微服务框架如何无缝过渡到服务网格 ASM

Sword finger offer II 035 Minimum time difference

网工常见面试题分享:Telnet、TTL、路由器与交换机

Mysql Duplicate entry ‘xxx‘ for key ‘xxx‘

面试官:为什么数据库连接很消耗资源?我竟然答不上来。。一下懵了!

What is the essential difference between get and post requests?

Sofaregistry source code | data synchronization module analysis
Initial i/o and its basic operations
随机推荐
云呐|如何利用系统管理固定资产?如何进行固定资产管理?
How to write controller layer code gracefully?
Findbugs modification summary
YuMinHong: my retreat and advance; The five best software architecture patterns that architects must understand; Redis kills 52 consecutive questions | manong weekly VIP member exclusive email weekly
I / o initial et son fonctionnement de base
[uitableview] Pit 1: tableview:heightforheaderinsection: method does not execute
[MySQL basic] general syntax 2
云呐|固定资产系统管理的优势,固定资产管理系统有何特点
Sofaregistry source code | data synchronization module analysis
TwinCAT 3 EL7211模塊控制倍福伺服
股票网上开户及开户流程怎样?还有,在线开户安全么?
Which securities company is better and which platform is safer for stock speculation account opening
MySQL foundation 2
Database learning notes (sql03)
Time flies that year
Applying for let's encrypt SSL certificate with certbot
[qnx hypervisor 2.2 user manual]6.2.2 communication between guest and host
中小企业签署ERP合同时,需要注意这几点
MySQL高级篇2
SOFARegistry 源码|数据同步模块解析