当前位置:网站首页>MySQL读写分离与主从延迟
MySQL读写分离与主从延迟
2022-08-02 08:07:00 【苦 糖 果】
1. 读写分离方案
客户端(client)主动做负载均衡 带proxy的读写分离架构
带proxy的读写分离架构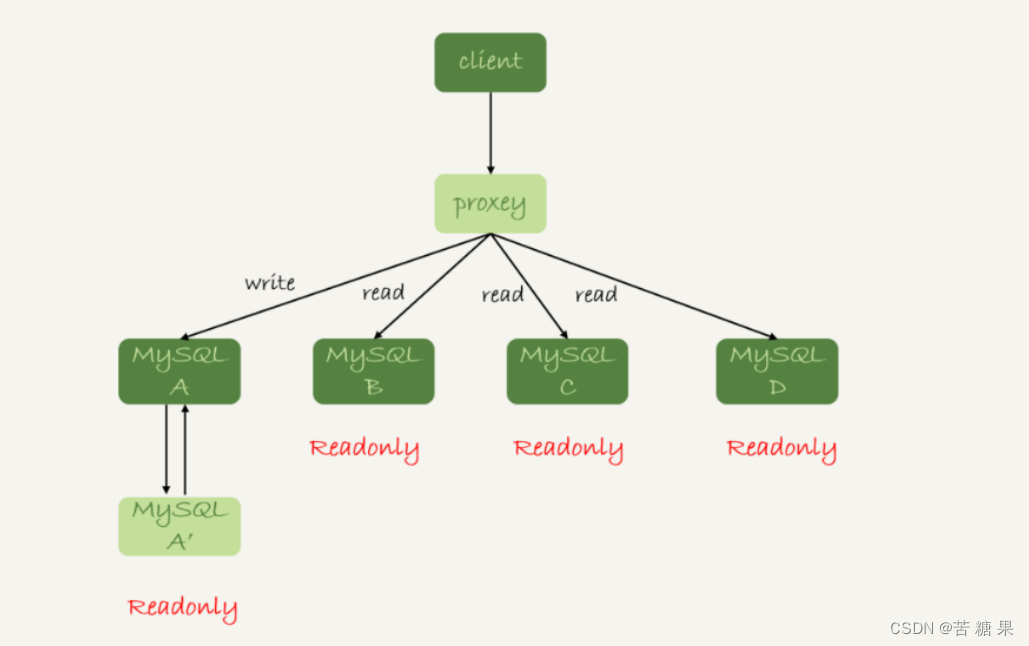 客户端直连和带proxy的读写分离架构比较:
客户端直连和带proxy的读写分离架构比较:
a. 客户端直连方案,因为少了一层proxy转发,所以查询性能稍微好一点儿,并且整体架构简单,排查问题更方便。但是这种方案,由于要了解后端部署细节,所以在出现主备切换、库迁移等操作的时候,客户端都会感知到,并且需要调整数据库连接信息。
你可能会觉得这样客户端也太麻烦了,信息大量冗余,架构很丑。其实也未必,一般采用这样的架构,一定会伴随一个负责管理后端的组件,比如Zookeeper,尽量让业务端只专注于业务逻辑开发。
b. 带proxy的架构,对客户端比较友好。客户端不需要关注后端细节,连接维护、后端信息维护等工作,都是由proxy完成的。但这样的话,对后端维护团队的要求会更高。而且,proxy也需要有高可用架构。因此,带proxy架构的整体就相对比较复杂。
与架构无关:由于主从可能存在延迟,客户端执行完一个更新事务后马上发起查询,如果查询选择的是从库的话,就有可能读到刚刚的事务更新之前的状态。
这种“在从库上会读到系统的一个过期状态”的现象,在这篇文章里,我们暂且称之为“过期读”。
前面我们说过了几种可能导致主备延迟的原因,以及对应的优化策略,但是主从延迟还是不能100%避免的。
2.处理过期读的方案:
强制走主库方案;
sleep方案;
判断主备无延迟方案;
配合semi-sync方案;
等主库位点方案;
等GTID方案。
2.1 强制走主库方案(用得最多)
强制走主库方案其实就是,将查询请求做分类。通常情况下,我们可以将查询请求分为这么两类:
对于必须要拿到最新结果的请求,强制将其发到主库上。
对于可以接受读到旧数据的请求,才将其发到从库上。
2.2 Sleep 方案(不太靠谱)
主库更新后,读从库之前先sleep一下。具体的方案就是,类似于执行一条select sleep(1)命令。
如果这个查询请求本来0.5秒就可以在从库上拿到正确结果,也会等1秒;
如果延迟超过1秒,还是会出现过期读。
2.3 判断主备无延迟方案(可能出现过期读)
要确保备库无延迟,通常有三种做法。
a. 第一种确保主备无延迟的方法是,每次从库执行查询请求前,先判断seconds_behind_master是否已经等于0。如果还不等于0 ,那就必须等到这个参数变为0才能执行查询请求。
show slave status结果里的seconds_behind_master参数的值,可以用来衡量主备延迟时间的长短。
seconds_behind_master的单位是秒,如果你觉得精度不够的话,还可以采用对比位点和GTID的方法来确保主备无延迟,也就是我们接下来要说的第二和第三种方法。
现在,我们就通过这个结果,来看看具体如何通过对比位点和GTID来确保主备无延迟。
b.第二种方法,对比位点确保主备无延迟:
Master_Log_File和Read_Master_Log_Pos,表示的是读到的主库的最新位点;
Relay_Master_Log_File和Exec_Master_Log_Pos,表示的是备库执行的最新位点。
如果Master_Log_File和Relay_Master_Log_File、Read_Master_Log_Pos和Exec_Master_Log_Pos这两组值完全相同,就表示接收到的日志已经同步完成。
c. 第三种方法,对比GTID集合确保主备无延迟:
Auto_Position=1 ,表示这对主备关系使用了GTID协议。
Retrieved_Gtid_Set,是备库收到的所有日志的GTID集合;
Executed_Gtid_Set,是备库所有已经执行完成的GTID集合。
如果这两个集合相同,也表示备库接收到的日志都已经同步完成。
可见,对比位点和对比GTID这两种方法,都要比判断seconds_behind_master是否为0更准确。
在执行查询请求之前,先判断从库是否同步完成的方法,相比于sleep方案,准确度确实提升了不少,但还是没有达到“精确”的程度。为什么这么说呢?
我们现在一起来回顾下,一个事务的binlog在主备库之间的状态:
主库执行完成,写入binlog,并反馈给客户端;
binlog被从主库发送给备库,备库收到;
在备库执行binlog完成。
我们上面判断主备无延迟的逻辑,是“备库收到的日志都执行完成了”。但是,从binlog在主备之间状态的分析中,不难看出还有一部分日志,处于客户端已经收到提交确认,而备库还没收到日志的状态。
如果这时候你在从库上执行查询请求,从库认为已经没有同步延迟,但还是查不到数据的。严格地说,就是出现了过期读。
2.4 配合semi-sync(只适用于一主一从,持续延迟问题)
要解决这个问题,就要引入半同步复制,也就是semi-sync replication。
semi-sync做了这样的设计:
事务提交的时候,主库把binlog发给从库;
从库收到binlog以后,发回给主库一个ack,表示收到了;
主库收到这个ack以后,才能给客户端返回“事务完成”的确认。
也就是说,如果启用了semi-sync,就表示所有给客户端发送过确认的事务,都确保了备库已经收到了这个日志。
但是,semi-sync+位点判断的方案,只对一主一备的场景是成立的。在一主多从场景中,主库只要等到一个从库的ack,就开始给客户端返回确认。这时,在从库上执行查询请求,就有两种情况:
如果查询是落在这个响应了ack的从库上,是能够确保读到最新数据;
但如果是查询落到其他从库上,它们可能还没有收到最新的日志,就会产生过期读的问题。
其实,判断同步位点的方案还有另外一个潜在的问题,即:如果在业务更新的高峰期,主库的位点或者GTID集合更新很快,那么上面的两个位点等值判断就会一直不成立,很可能出现从库上迟迟无法响应查询请求的情况。
到这里,我们小结一下,semi-sync配合判断主备无延迟的方案,存在两个问题:
一主多从的时候,在某些从库执行查询请求会存在过期读的现象;
在持续延迟的情况下,可能出现过度等待的问题。
2.5 等主库位点方案
要理解等主库位点方案,我需要先和你介绍一条命令:
select master_pos_wait(file, pos[, timeout]);
这条命令的逻辑如下:
它是在从库执行的;
参数file和pos指的是主库上的文件名和位置;
timeout可选,设置为正整数N表示这个函数最多等待N秒。
这个命令正常返回的结果是一个正整数M,表示从命令开始执行,到应用完file和pos表示的binlog位置,执行了多少事务。
当然,除了正常返回一个正整数M外,这条命令还会返回一些其他结果,包括:
如果执行期间,备库同步线程发生异常,则返回NULL;
如果等待超过N秒,就返回-1;
如果刚开始执行的时候,就发现已经执行过这个位置了,则返回0。
对于图5中先执行trx1,再执行一个查询请求的逻辑,要保证能够查到正确的数据,我们可以使用这个逻辑:
trx1事务更新完成后,马上执行show master status得到当前主库执行到的File和Position;
选定一个从库执行查询语句;
在从库上执行select master_pos_wait(File, Position, 1);
如果返回值是>=0的正整数,则在这个从库执行查询语句;
否则,到主库执行查询语句。
这里我们假设,这条select查询最多在从库上等待1秒。那么,如果1秒内master_pos_wait返回一个大于等于0的整数,就确保了从库上执行的这个查询结果一定包含了trx1的数据。
步骤5到主库执行查询语句,是这类方案常用的退化机制。因为从库的延迟时间不可控,不能无限等待,所以如果等待超时,就应该放弃,然后到主库去查。
2.6 GTID方案
如果你的数据库开启了GTID模式,对应的也有等待GTID的方案。
MySQL中同样提供了一个类似的命令:
select wait_for_executed_gtid_set(gtid_set, 1);
这条命令的逻辑是:
等待,直到这个库执行的事务中包含传入的gtid_set,返回0;
超时返回1。
在前面等位点的方案中,我们执行完事务后,还要主动去主库执行show master status。而MySQL 5.7.6版本开始,允许在执行完更新类事务后,把这个事务的GTID返回给客户端,这样等GTID的方案就可以减少一次查询。
这时,等GTID的执行流程就变成了:
trx1事务更新完成后,从返回包直接获取这个事务的GTID,记为gtid1;
选定一个从库执行查询语句;
在从库上执行 select wait_for_executed_gtid_set(gtid1, 1);
如果返回值是0,则在这个从库执行查询语句;
否则,到主库执行查询语句。
跟等主库位点的方案一样,等待超时后是否直接到主库查询,需要业务开发同学来做限流考虑。
边栏推荐
猜你喜欢
![Three types of [OC learning notes] Block](/img/40/edf59e6e68891ea7c9ab0481fe7bfc.png)



随机推荐
【开源项目】X-TRACK源码分析
EPSANet: An Efficient Pyramid Split Attention Block on Convolutional Neural Network
BGP通过MPLS解决路由黑洞
cas:139504-50-0 美登素DM1|Mertansine|
The crawler video crawl tools you get
@PostConstruct注解详解
工程师如何对待开源 --- 一个老工程师的肺腑之言
Mysql各个大版本之间的区别
uni.navigateBack 中的坑
Biotin-EDA|CAS:111790-37-5| 乙二胺生物素
Database triggers and transactions
etcd implements large-scale service governance application combat
MySQL Workbench 安装及使用
OneNote 教程,如何在 OneNote 中创建更多空间?
MFC最详细入门教程[转载]
小说里的编程 【连载之二十三】元宇宙里月亮弯弯
设置 height: auto 却无法触发 transition 动画的解决方案
基于PyTorch的flappy bird游戏
【电子电路】长按键拉低电平,适用在有休眠机制的MCU但是没有看门狗,一个按键多个功能场景下使用
Biotin-C6-amine|N-biotinyl-1,6-hexanediamine|CAS: 65953-56-2