当前位置:网站首页>Computer vision (AI) interview
Computer vision (AI) interview
2022-06-11 03:18:00 【Great black mountain monastic】
Target detection algorithm
1. The difference between single-stage and two-stage target detection algorithms ? With yolo and RCNN For example
Single stage : High speed but low accuracy ;
Two stages : High accuracy and slow speed ;
Single stage one-stage:
one-stage The algorithm will directly extract features from the network to predict the features and positions of objects , One step in place . Representative work :YOLO,SSD.
Two stages two-stage:
The first stage : Focus on finding out where the target object appears , Get advice box , Ensure sufficient accuracy and recall ;
The second stage : Focus on classifying suggestion boxes , Find a more precise location
Representative work :R-CNN,Fast R-CNN ,Faster R-CNN.
one-stage representative yolo Algorithm
yolo Creatively treat the object detection task as a regression problem (regression problem), Combine the two stages of candidate region and detection into one .
yolov1:
In this paper, we turn detection into regression problem ,yolo From input image , Just through one neural network, Directly get the probability of the detection frame and the category to which each detection frame belongs . Because the whole process is just a network , Therefore, end-to-end optimization can be carried out directly .
Loss Loss function
1. Yes focal loss Understanding
Problems caused by imbalance of positive and negative samples :
A simple sample with a large number of negative samples , This will make a large number of simple negative sample pairs loss Make a major contribution , The update direction of the dominant gradient , The network is unable to object Make precise classification .
Focal loss Mainly to solve one-stage In target detection, the proportion of positive and negative samples is seriously unbalanced . The loss function reduces the weight of a large number of simple negative samples in training , It can also be understood as a kind of difficult sample mining .
1.1 First, face the problem of imbalance between positive and negative samples , Add a weight to the cross entropy alpha, It is used to balance the uneven proportion of positive and negative samples , The more negative samples, the less proportion ;
original :
It is amended as follows :
1.2 Aiming at the imbalance between simple negative samples and complex negative samples , increase gamma factor , among gamma>0 It can reduce the loss of simple samples , To focus more on losses and more on difficulties 、 Misclassified samples .( Because the proportion of simple samples is very large , Assuming that 0.9, that 1-0.9 The value of will be very small , The final impact on the loss is also very small , This can also amplify the impact of difficult samples )
Define the loss function :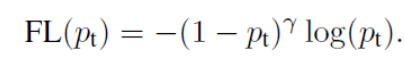
Final ,focal loss In the form of :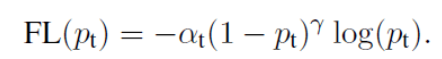
2. What are the loss functions of target detection ?
The loss function in target detection usually consists of two parts :classification loss ( Classified loss ) and bounding box regression loss( Positioning loss ).
classification loss ( Classified loss )
2.1.1 Cross entropy

The cross entropy loss function reduces the difference between the two distributions , Make the prediction result more reliable .
Based on cross entropy, Google proposed Label Smoothing( Label smoothing ), solve over-confidence The problem of .
Label Smoothing In fact, the original label Value range from [0,1] Change it to [ε,1-ε]
2.1.2 focal loss
Mainly to solve one-stage The proportion of positive and negative samples in the target detection algorithm is seriously unbalanced , It reduces the proportion of a large number of simple negative samples in training .
focal loss In the form of :
First, face the problem of imbalance between positive and negative samples , Add a weight to the cross entropy alpha, It is used to balance the uneven proportion of positive and negative samples , The more negative samples, the less proportion ;
Aiming at the imbalance between simple negative samples and complex negative samples , increase gamma factor , among gamma>0 It can reduce the loss of simple samples , To focus more on losses and more on difficulties 、 Misclassified samples .( Because the proportion of simple samples is very large , Assuming that 0.9, that 1-0.9 The value of will be very small , The final impact on the loss is also very small , This can also amplify the impact of difficult samples );
2.2.1 Target location loss —IoU
The main index to measure the performance of target detection and location is the intersection and combination ratio IoU. In the past, when designing the loss function, we usually used mse Equal loss function is used to optimize the positioning result of the model , But it can not reflect the positioning accuracy well ;
Use it directly Iou Measure the target location loss function :
advantage : Scale invariance
Existing problems : same IOU It does not mean that the positioning effect of the detection box is the same ; When two boxes do not intersect , be IOU=0 Can't reflect the distance between two boxes , There is no gradient in the loss function , You can't train through gradient descent
2.2.2 Target location loss —GIoU
GIOU The proposed :

IoU It reflects the overlap of the two boxes , When the two boxes do not overlap ,IoU Equal to 0, here IoU loss Equal to 1. In the bounding box regression of target detection , This is obviously not appropriate . therefore ,GIoU loss stay IoU loss The loss of two frames without overlapping area is considered . The specific definitions are as follows :
among ,C Represents the smallest bounding rectangle of two boxes ,R(P,G) It's a penalty . It can be seen from the formula that , When two boxes have no overlapping area ,IoU by 0, but R There will still be losses . In extreme cases , When two frames are infinitely far away ,R→1
I o U = ∣ A ∩ B ∣ ∣ A ∪ B ∣ IoU=\frac{|A\cap B|}{|A\cup B|} IoU=∣A∪B∣∣A∩B∣
G I o U = I o U − ∣ C \ ( A ∪ B ) ∣ ∣ C ∣ GIoU=IoU-\frac{|C\backslash(A\cup B)|}{|C|} GIoU=IoU−∣C∣∣C\(A∪B)∣
GIOU The advantages of :
1. First, you can implement a more comprehensive scenario to IoU Loss Optimize directly for the goal , Make the optimization goal consistent with the final evaluation goal . because IoU Loss The key problem is when two objects do not intersect , It degenerates into a constant 1, Loss of optimization objectives
2. Compared with the traditional return loss, It has a scale that does not deform
3. In extreme cases ,GIoU(A,B) = IoU(A, B)
2.2.3 DIoU Loss
IoU loss and GIoU loss Only the overlap of the two boxes is considered , But with the same degree of overlap , We actually want the two frames to be close enough , That is, the center of the frame should be as close as possible to . therefore ,DIoU stay IoU loss The distance between the center points of the two frames is considered , The specific definitions are as follows :
among ,ρ Indicates the distance between the prediction box and the center end of the dimension box ,p and g Is the center point of the two boxes .c Represents the diagonal length of the smallest bounding rectangle of two boxes . When two boxes are infinitely far away , The distance between the center point and the length of the diagonal of the circumscribed rectangular box approximates infinitely ,R→1
The following figure visually shows the... In different cases IoU loss、GIoU loss and DIoU loss result :
among , The green box indicates the callout box , The red box indicates the prediction box , It can be seen that , The result of the last group is that the center points of the two boxes coincide , The detection effect is due to the first two groups .IoU loss and GIoU loss The results are 0.75, There is no distinction between the three situations , and DIoU loss The three cases are well distinguished .
2.2.4 CIoU Loss
DIoU loss The distance between the center points of two frames is considered , and CIoU loss stay DIoU loss On the basis of the above, it makes a more detailed measurement , Specific include :
Overlap area
Distance from the center
Aspect ratio
therefore , Further in DIoU On the basis of that, the paper puts forward CIoU. The penalty term is shown in the following formula :
among ɑ It's a weight function :
and v Used to measure the similarity of aspect ratio , Defined as :
2.2.5 L1(MAE)
L1 Loss function :
L1 Loss function pair x The derivative of is a constant , There's no gradient explosion problem , But in the 0 You can't lead , When the loss value is small , The gradient obtained is also relatively large , It may cause model oscillation, which is not conducive to convergence .
2.2.6 L2(MSE)
L2 Loss function :

L2 The loss function is everywhere derivable , But because of the square operation , When the difference between the predicted value and the real value is greater than 1 when , Will magnify the error . Especially when the input value of the function is far from the central value , When using the gradient descent method, the gradient is very large , May cause gradient explosion . At the same time, when there are multiple outliers , These points may occupy Loss Major part , It needs to sacrifice many effective samples to compensate for it , therefore L2 loss Affected by outliers .
2.2.7 smooth L1 Loss function

smooth L1 Perfect to avoid L1 and L2 The disadvantages of loss :
stay [-1,1] Between is L2 Loss , solve L1 stay 0 There is a break point at
stay [-1, 1] Beyond the range is L1 Loss , Solve the problem of outlier gradient explosion
When the error between the predicted value and the real value is too large , The gradient is not too large
When the error between the predicted value and the real value is very small , The gradient is small enough
The above three loss functions (L1(MAE),L2(MSE),smooth L1 Loss function ) In the calculation bounding box regression loss when , It is an independent demand 4 Point loss, Then add them together to get the final loss value , The premise of this approach is that the four points are independent of each other , In fact, there is a certain correlation
The actual indicators for evaluating the test results are IoU, The two are not equivalent , Multiple check boxes may have the same loss, but IoU Difference is very big .
Training strategy
1. What should I do if the categories are unbalanced during the training ? How? ?
1. From the sampling strategy : The unbalanced data set is changed into a balanced data set by sampling method , The advantage is simple and convenient . It can be divided into oversampling and undersampling .
Oversampling : Make multiple copies of a small sample .
This may cause the trained model to have a certain degree of over fitting .
Undersampling : Select a part of a large sample as a data set , It is equal to discarding the data of part of the training set , It may also cause over fitting .
May adopt 3 There are three ways to reduce the loss caused by under sampling .
1.1 EasyEnsemble : Using the method of model fusion , Multiple undersampling produces multiple datasets , So as to train multiple models , Integrate the results of multiple models as the final result
1.2 BalanceCascade: Using the idea of incremental training , First, a classifier is trained by using the training set generated by under sampling , Then the samples with correct classification are screened out from the total training set , Again, the second classifier is trained with undersampling in the remaining data sets , Finally, all the classifier results are combined as the final result .
1.3 NearMiss: utilize KNN Try to select the most representative public samples .
2. Image enhancement : By some means , Use the existing samples to synthesize a few kinds of samples , So as to achieve the goal of category balance .
Conventional image enhancement methods include : The zoom , rotate , Flip , Offset, etc .
There are also some image enhancement methods customized according to the scene : Increase noise , Filtering operation ( Fuzzy ), Adjust the brightness / Contrast
3. Weighting operation : Solve the problem of data imbalance by weighting , When designing the loss function , Give more weight to a few samples , Assign smaller weights to most class samples .
for example : focal loss
4. Adjust the output threshold : When categories are unbalanced , Using the default classification threshold may cause the output to be all counterexamples , Produce virtual high accuracy , Cause classification failure . therefore , You can choose to adjust the threshold , Make the model more sensitive to fewer categories .
2. What to pay attention to when collecting data sets
2.1 Pay attention to avoid imbalance between positive and negative samples
2.2 Note that there is a quantitative balance between multiple classes
2.3 Scene diversity : Collect data under various scenarios within the scope of requirements as much as possible
for example : The detector is tested outdoors , The collected data shall include the daytime as much as possible , evening , rain , Sunny days and other scenes ;
2.4 Diversity of goals : As far as possible, collect the objectives under various states within the scope of requirements
2.4 The equipment for collecting data shall be the same as the equipment for later detection , Or the image input size should be consistent , Avoid big differences ;
2.5 Grasp the marking quality , In the end, there can be a strict quality control for the manual annotation of data sets ;
2.6 In difficult circumstances , The data set of the Internet and the data set collected manually on site can be combined for training , Can reduce labor costs ;
Reference blog :
https://blog.csdn.net/weixin_41665360/article/details/100126744
https://blog.csdn.net/weixin_43750248/article/details/116656242
https://blog.csdn.net/a264672/article/details/122952162
边栏推荐
- Resolved: JDBC connection to MySQL failed with an error:'The last packet sent successfully to the server was 0 milliseconds ago. '
- B_QuRT_User_Guide(19)
- Helm deploy traifik ingress
- org. apache. solr. common. SolrException:Could not load core configuration for core hotel
- Android P SoftAP start process
- 第七章 常用的协议简介(1)
- File file = new file ("test.txt") file path
- Pyqt5:slider slider control
- In June, 2022, China Database ranking: tidb made a comeback to win the crown, and Dameng was dormant and won the flowers in May
- Forest v1.5.22 release! Kotlin support
猜你喜欢

Operations on annotation and reflection

SQL | 游戏行业部分指标
Chapter VII introduction to common protocols (1)

MySQL学习笔记:JSON嵌套数组查询

ThoughtWorks. QRcode full-featured generator

Troubleshooting of single chip microcomputer communication data delay
postgresql源码学习(22)—— 故障恢复③-事务日志的注册
Graphacademy course explanation: Fundamentals of neo4j graph data science
Solr initialization failure: requesthandler INIT failure

postgresql源码学习(二十)—— 故障恢复①-事务日志格式
随机推荐
C语言数组的简单认识
SQL | 游戏行业部分指标
B_ QuRT_ User_ Guide(19)
Chapter VII introduction to common protocols (1)
反射三种方式
富络经典源码富络经典系统开发原理分享
Stringutils string tool class used by FreeMarker to create templates
Hough transform of image
B_QuRT_User_Guide(17)
Basic use of sonarqube platform
Determine whether a string of numbers is the result of a quick sort
LVGL中文字体制作
postgresql源码学习(十八)—— MVCC③-创建(获取)快照
Unity之数据持久化——Json
二叉树最小最低公共祖先
Troubleshooting of single chip microcomputer communication data delay
[safety science popularization] have you been accepted by social workers today?
第七章 常用的协议简介(1)
数据库唯一索引和普通索引的区别?
ASLR