当前位置:网站首页>实时计算框架:Flink集群搭建与运行机制
实时计算框架:Flink集群搭建与运行机制
2022-06-24 00:33:00 【知了一笑】
一、Flink概述
1、基础简介
Flink是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算。Flink被设计在所有常见的集群环境中运行,以内存执行速度和任意规模来执行计算。主要特性包括:批流一体化、精密的状态管理、事件时间支持以及精确一次的状态一致性保障等。Flink不仅可以运行在包括YARN、Mesos、Kubernetes在内的多种资源管理框架上,还支持在裸机集群上独立部署。在启用高可用选项的情况下,它不存在单点失效问题。

这里要说明两个概念:
- 边界:无边界和有边界数据流,可以理解为数据的聚合策略或者条件;
- 状态:即执行顺序上是否存在依赖关系,即下次执行是否依赖上次结果;
2、应用场景
Data Driven

事件驱动型应用无须查询远程数据库,本地数据访问使得它具有更高的吞吐和更低的延迟,以反欺诈案例来看,DataDriven把处理的规则模型写到DatastreamAPI中,然后将整个逻辑抽象到Flink引擎,当事件或者数据流入就会触发相应的规则模型,一旦触发规则中的条件后,DataDriven会快速处理并对业务应用进行通知。
Data Analytics

和批量分析相比,由于流式分析省掉了周期性的数据导入和查询过程,因此从事件中获取指标的延迟更低。不仅如此,批量查询必须处理那些由定期导入和输入有界性导致的人工数据边界,而流式查询则无须考虑该问题,Flink为持续流式分析和批量分析都提供了良好的支持,实时处理分析数据,应用较多的场景如实时大屏、实时报表。
Data Pipeline
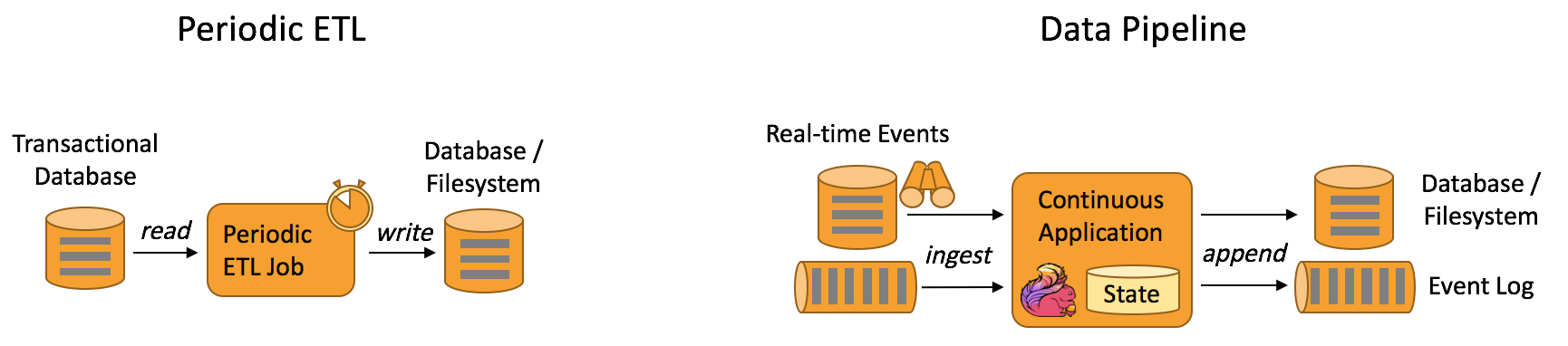
与周期性的ETL作业任务相比,持续数据管道可以明显降低将数据移动到目的端的延迟,例如基于上游的StreamETL进行实时清洗或扩展数据,可以在下游构建实时数仓,确保数据查询的时效性,形成高时效的数据查询链路,这种场景在媒体流的推荐或者搜索引擎中十分常见。
二、环境部署
1、安装包管理
[[email protected] opt]# tar -zxvf flink-1.7.0-bin-hadoop27-scala_2.11.tgz
[[email protected] opt]# mv flink-1.7.0 flink1.7
2、集群配置
管理节点
[[email protected] opt]# cd /opt/flink1.7/conf
[[email protected] conf]# vim flink-conf.yaml
jobmanager.rpc.address: hop01
分布节点
[[email protected] conf]# vim slaves
hop02
hop03
两个配置同步到所有集群节点下面。
3、启动与停止
/opt/flink1.7/bin/start-cluster.sh
/opt/flink1.7/bin/stop-cluster.sh
启动日志:
[[email protected] conf]# /opt/flink1.7/bin/start-cluster.sh
Starting cluster.
Starting standalonesession daemon on host hop01.
Starting taskexecutor daemon on host hop02.
Starting taskexecutor daemon on host hop03.
4、Web界面
访问:http://hop01:8081/

三、开发入门案例
1、数据脚本
分发一个数据脚本到各个节点:
/var/flink/test/word.txt
2、引入基础依赖
这里基于Java写的基础案例。
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.7.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.11</artifactId>
<version>1.7.0</version>
</dependency>
</dependencies>
3、读取文件数据
这里直接读取文件中的数据,经过程序流程分析出每个单词出现的次数。
public class WordCount {
public static void main(String[] args) throws Exception {
// 读取文件数据
readFile () ;
}
public static void readFile () throws Exception {
// 1、执行环境创建
ExecutionEnvironment environment = ExecutionEnvironment.getExecutionEnvironment();
// 2、读取数据文件
String filePath = "/var/flink/test/word.txt" ;
DataSet<String> inputFile = environment.readTextFile(filePath);
// 3、分组并求和
DataSet<Tuple2<String, Integer>> wordDataSet = inputFile.flatMap(new WordFlatMapFunction(
)).groupBy(0).sum(1);
// 4、打印处理结果
wordDataSet.print();
}
// 数据读取个切割方式
static class WordFlatMapFunction implements FlatMapFunction<String, Tuple2<String, Integer>> {
@Override
public void flatMap(String input, Collector<Tuple2<String, Integer>> collector){
String[] wordArr = input.split(",");
for (String word : wordArr) {
collector.collect(new Tuple2<>(word, 1));
}
}
}
}

4、读取端口数据
在hop01服务上创建一个端口,并模拟一些数据发送到该端口:
[[email protected] ~]# nc -lk 5566
c++,java
通过Flink程序读取并分析该端口的数据内容:
public class WordCount {
public static void main(String[] args) throws Exception {
// 读取端口数据
readPort ();
}
public static void readPort () throws Exception {
// 1、执行环境创建
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
// 2、读取Socket数据端口
DataStreamSource<String> inputStream = environment.socketTextStream("hop01", 5566);
// 3、数据读取个切割方式
SingleOutputStreamOperator<Tuple2<String, Integer>> resultDataStream = inputStream.flatMap(
new FlatMapFunction<String, Tuple2<String, Integer>>()
{
@Override
public void flatMap(String input, Collector<Tuple2<String, Integer>> collector) {
String[] wordArr = input.split(",");
for (String word : wordArr) {
collector.collect(new Tuple2<>(word, 1));
}
}
}).keyBy(0).sum(1);
// 4、打印分析结果
resultDataStream.print();
// 5、环境启动
environment.execute();
}
}
四、运行机制

FlinkClient
客户端用来准备和发送数据流到JobManager节点,之后根据具体需求,客户端可以直接断开连接,或者维持连接状态等待任务处理结果。
JobManager
在Flink集群中,会启动一个JobManger节点和至少一个TaskManager节点,JobManager收到客户端提交的任务后,JobManager会把任务协调下发到具体的TaskManager节点去执行,TaskManager节点将心跳和处理信息发送给JobManager。
TaskManager
任务槽(slot)是TaskManager中最小的资源调度单位,在启动的时候就设置好了槽位数,每个槽位能启动一个Task,接收JobManager节点部署的任务,并进行具体的分析处理。
五、源代码地址
GitHub·地址
https://github.com/cicadasmile/big-data-parent
GitEE·地址
https://gitee.com/cicadasmile/big-data-parent
大数据系列
Hadoop框架
基础组件
实时计算框架
OLAP分析引擎
边栏推荐
- Tiktok practice ~ one click registration and login process of mobile phone number and password (restrict mobile terminal login)
- 飞桨产业级开源模型库:加速企业AI任务开发与应用
- Pure JS implementation determines whether the IP is pinged
- Vs2022 save formatting plug-in
- 超标量处理器设计 姚永斌 第3章 虚拟存储器 --3.1~3.2 小节摘录
- What should I pay attention to in the interview of artificial intelligence technology?
- 牛学长周年庆活动:软件大促限时抢,注册码免费送!
- 使用worker报错:Uncaught DOMException: Failed to construct ‘Worker’: Script at***
- [technique of planting grass] spit blood and clean up, and take you to collect goose feathers in a fancy way! Do not spread!!!
- ==What is the difference between and equals?
猜你喜欢

Expander+listbox of WPF effect

数字化工厂可以分为哪两类

Dependency Inversion Principle

Use of reverse tools IDA and GDB
Detailed process from CPU fetching to sending control and microprogram control principle
![[applet] realize the effect of double column commodities](/img/e3/b72955c1ae67ec124520ca46c22773.png)
[applet] realize the effect of double column commodities
![[FreeRTOS] 07 binary semaphore and count semaphore](/img/9c/a3e4b9e02f754c5d3a54d94b7b4e35.png)
[FreeRTOS] 07 binary semaphore and count semaphore

Interview notes for Android outsourcing workers for 3 years. You still need to go to a large factory to learn and improve when you have the opportunity. Interview questions for Android Development Int

Usage of go in SQL Server
数据管理:业务数据清洗,落地实现方案
随机推荐
【小程序】编译预览小程序时,出现-80063错误提示
How much business do you need to know to do data analysis
[leetcode notes] no118 Yanghui triangle
【虹科案例】3D数据如何成为可操作的信息?– 对象检测和跟踪
Shutter control layout
[FreeRTOS] 07 binary semaphore and count semaphore
【红绿灯识别】基于matlab GUI红绿灯识别【含Matlab源码 1908期】
Android App Bundle探索,客户端开发面试题目
version `ZLIB_ 1.2.9‘ not found (required by /lib64/libpng16.so.16)
Android 72021 latest Android interview written test questions sharing
Building a digital software factory -- panoramic interpretation of one-stop Devops platform
超标量处理器设计 姚永斌 第3章 虚拟存储器 --3.1~3.2 小节摘录
All 32 keyword classifications of C language C89 (C90)
Principles and differences between hash and history
【图像检测显著图】基于matlab失真提示鱼眼图显著图计算【含Matlab源码 1903期】
Complete collection of development environment configuration -- Visual Studio 2022 installation
数字化工厂可以分为哪两类
kubernetes之常用核心资源对象
Skywalking installation and deployment practice
数据管理:业务数据清洗,落地实现方案